
MacOS:Docker搭建Flink叢集
前言:docker環境正常、docker-compose已安裝,這裡使用docker-compose安裝
一、建立docker-compose.yml檔案
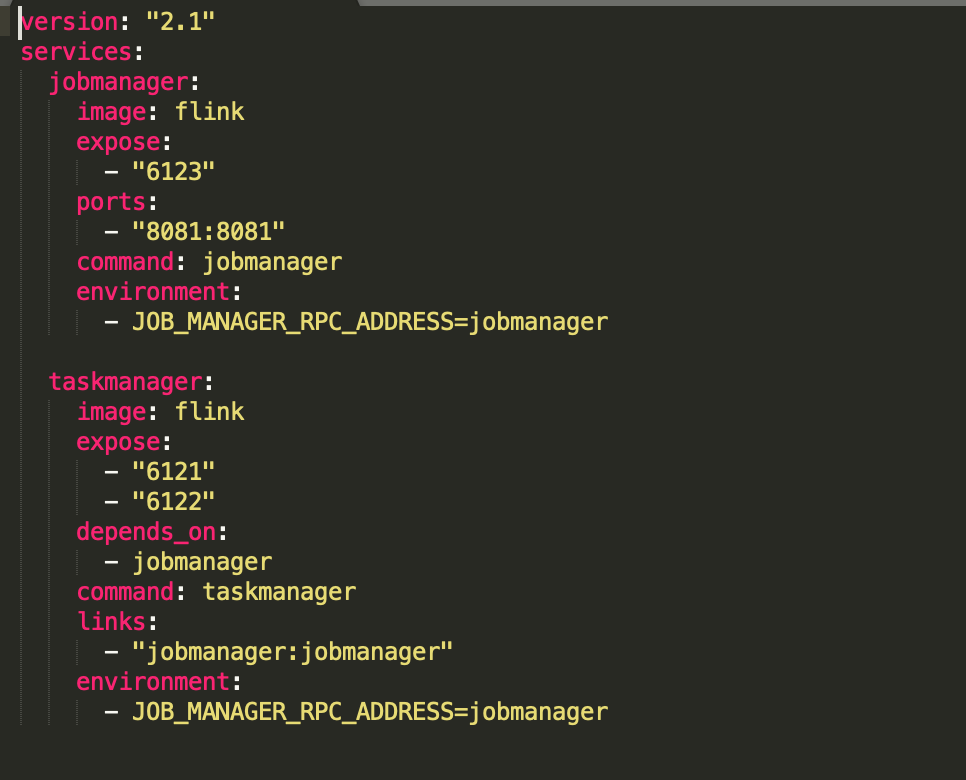
二、在當前檔案目錄下執行docker-compose up -d(-d:後臺執行)
三、這裡flink映象已經下載,檢視容器是否建立:docker ps -a
 四、瀏覽器輸入http://localhost:8081檢視建立是否完成
四、瀏覽器輸入http://localhost:8081檢視建立是否完成
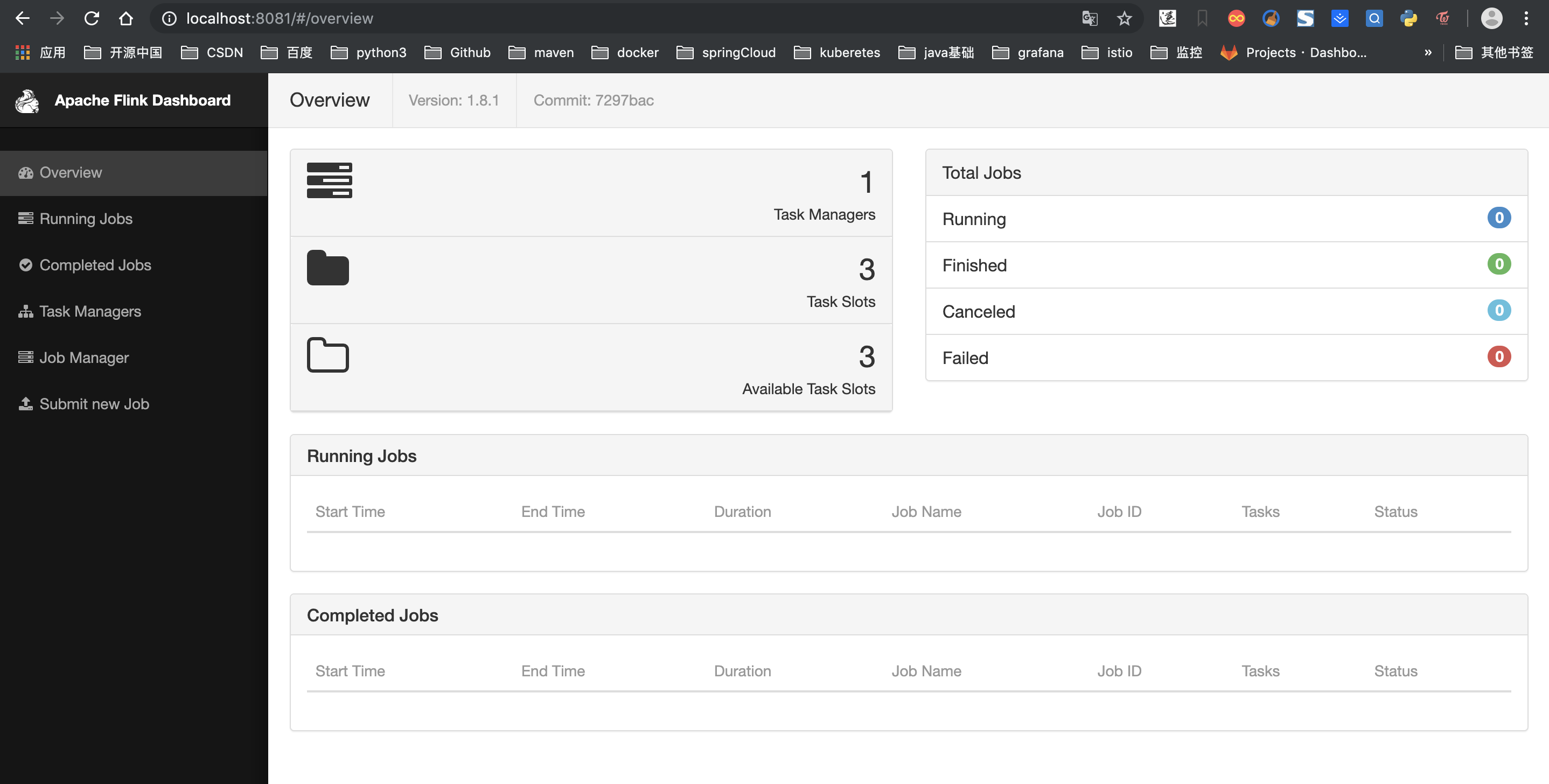
flink環境搭建
相關推薦
MacOS:Docker搭建Flink叢集
前言:docker環境正常、docker-compose已安裝,這裡使用docker-compose安裝 一、建立docker-
MacOS:Docker搭建Hadoop叢集
前言:docker環境正常 一、下載hadoop映象,在啟動指令碼建立容器的時候會用到,也可以後面直接啟動指令碼直接下載,版本可
macOS:Docker搭建Spark單節點叢集
前言:Docker環境正常,docker-compose已安裝 一、下載 git clone https://github.c
基於Centos7+Docker 搭建hadoop叢集
總體流程: 獲取centos7映象 為centos7映象安裝ssh 使用pipework為容器配置IP 為centos7映象配置java、hadoop 配置hadoop 1.獲取centos7映象 $ docker pull centos:7 //檢視當前已下載docke
docker搭建consul叢集
說明 docker版本:18.06.1-ce consul 版本:v1.2.3 系統:ubuntu18 本文將介紹在一臺機器上搭建三個server節點 1個Client節點的consul叢集。 docker安裝 1.解除安裝老版本 sudo apt-get
Docker搭建PXC叢集
如何建立MySQL的PXC叢集 下載PXC叢集映象檔案 下載 docker pull percona/percona-xtradb-cluster 重新命名 [[email protected] ~]# docker tag docker.io/percona/percona-xtradb
docker 搭建kafka叢集
二當家對這篇文章做了一定修改 因為 原文中 docker-compose scale kafka=3 會啟動3個宿主機上9092的埠的kafka 報錯 仔細可以看下原文和本文進行差異比對 linux發行版 已經安裝好docker 已經安裝好docker-comp
五行命令使用docker搭建hadoop叢集
前言 如果個人想搭建一個hadoop叢集玩玩,之前都是採用虛擬機器的模式,每個節點都要一套配置,非常的複雜,在網上看到有大佬已經做好了映象和指令碼,拿來五行命令就能使用了! 拉取映象 sudo dock
Docker 搭建Spark_hadoop叢集
singularities/spark:2.2版本中 Hadoop版本:2.8.2 Spark版本: 2.2.1 Scala版本:2.11.8 Java版本:1.8.0_151 拉取映象: [[email protected] docker-spar
使用 Docker搭建 ZooKeeper 叢集
備註,此文來源: https://segmentfault.com/a/1190000006907443 防止以後找不到,故記錄一下: 映象下載 hub.docker.com 上有不少 ZK 映象, 不過為了穩定起見, 我們就使用官方的 ZK 映象吧. 首先執行如下
docker搭建redis叢集
序言 在原來VM使用redis的時候,搭建的時候,需要下載redis的原始碼,然後進行編譯
Linux_基於Docker搭建Redis叢集
常用命令:docker images 命令來檢視我們已經安裝映象docker search <name>:查詢映象名稱docker pull <name>:拉取映象docker ps 預設顯示執行的容器,顯示所有容器: docker ps -ado
docker搭建linux叢集,搭建mpi環境,並使用MTT benchmark測試叢集效能
最近在研究docker,早些時候老闆讓做了一個open mpi的image,並在單機環境下,成功使用docker搭建了一個openmpi的叢集,可以跑一些hello world的例子,後來,在ubuntu環境下,使用openvswitch搭建了一個多host的叢
用 Docker 搭建 Spark 叢集
簡介 Spark 是 Berkeley 開發的分散式計算的框架,相對於 Hadoop 來說,Spark 可以快取中間結果到記憶體而提高某些需要迭代的計算場景的效率,目前收到廣泛關注。 熟悉 Hadoop 的同學也不必擔心,Spark 很多設計理念和用法都跟 Hado
Docker搭建hadoop叢集
因為之前在VMware上操作Hadoop時發現資源消耗大,配置麻煩,所以思考能不能使用docker搭建Hadoop叢集,感謝上面連結的大神弄的叢集映象,所以很快就能搭建出Hadoop3節點叢集。我使用的是windows下dockerTool安裝啟動vagrant、vitrualbox 3節點Hado
Docker搭建Swarm叢集
非常好的文章,整個複製過來了,覺得好請點連結,原文更精彩! Docker 叢集環境實現的新方式 通過 Docker Swarm 和 Consul 配置叢集並實現各主機上 Docker 容器的互通 近幾年來,Docker 作為一個開源的應用容器引擎,深受廣大開發者的歡迎。
樹莓派3B搭建Flink叢集
今天的實戰是用兩臺樹莓派3B組建Flink1.7叢集環境,模式是獨立叢集(Cluster Standalone); 操作步驟 準備作業系統; 安裝JDK; 配置host; 安裝Flink1.7; 配置引數; 設定兩臺樹莓派相互SSH免密碼登入
【轉】使用Docker搭建hadoop叢集
剛開始搭建Hadoop叢集的時候,使用的是VMware建立的虛擬機器。結果卡到心態爆炸。。。 今天嘗試使用Docker搭建hadoop叢集,發現是如此的好用快捷,也比使用VMware簡單。 在這裡記錄一下防止以後忘記,為以後的學習做準備。 1.獲取映象。 如果是本地使用VMware搭建的話,需
Docker 搭建 ES 叢集並整合 Spring Boot
隨著 Elasticsearch 生態越來越完善,當公司業務的高速發展及資料爆炸式的增長,某些業務場景需要多維度的搜尋時,Elasticsearch 是最適合場景的。 通過本次 Chat 可以帶大家先了解 Elasticsearch 是什麼,以及它的特性和要素。然後通過實戰幫助大家在實踐中解決一些
使用Docker 安裝 Flink 叢集
1:下載 https://github.com/melentye/flink-docker 放到系統的任意目錄 2:進入目錄下 執行 docker-compose up -d 將進行相應的Flink的包的下載 3:設定task Man