
JavaScript深入淺出第4課:V8引擎是如何工作的?
摘要: 效能彪悍的V8引擎。
《JavaScript深入淺出》系列:
- JavaScript深入淺出第1課:箭頭函式中的this究竟是什麼鬼?
- JavaScript深入淺出第2課:函式是一等公民是什麼意思呢?
- JavaScript深入淺出第3課:什麼是垃圾回收演算法?
- JavaScript深入淺出第4課:V8是如何工作的?
最近,JavaScript生態系統又多了2個非常硬核的專案。
大神Fabrice Bellard釋出了一個新的JS引擎QuickJS,可以將JavaScript原始碼轉換為C語言程式碼,然後再使用系統編譯器(gcc或者clang)生成可執行檔案。
Facebook為React Native開發了新的JS引擎
作為JavaScript程式設計師,只有極少數人有機會和能力去實現一個JS引擎,但是理解JS引擎還是很有必要的。本文將介紹一下V8引擎的原理,希望可以給大家一些幫助。
JavaScript引擎
我們寫的JavaScript程式碼直接交給瀏覽器或者Node執行時,底層的CPU是不認識的,也沒法執行。CPU只認識自己的指令集,指令集對應的是彙編程式碼。寫彙編程式碼是一件很痛苦的事情,比如,我們要計算N階乘的話,只需要7行的遞迴函式:
function factorial(N) {
if (N === 1) {
return 1;
} else {
return N * factorial(N - 1);
}
}
程式碼邏輯也非常清晰,與階乘數的學定義完美吻合,哪怕不會寫程式碼的人也能看懂。
但是,如果使用匯編語言來寫N階乘的話,要300+行程式碼n-factorial.s:

這個N階乘的彙編程式碼是我大學時期寫的,已經是N年前的事情了,它需要處理10進位制與2進位制的轉換,需要使用多個位元組儲存大整數,最多可以計算大概500左右的N階乘。
還有一點,不同型別的CPU的指令集是不一樣的,那就意味著得給每一種CPU重寫彙編程式碼,這就很崩潰了。。。
還好,JavaScirpt引擎可以將JS程式碼編譯為不同CPU(Intel, ARM以及MIPS等)對應的彙編程式碼,這樣我們才不要去翻閱每個CPU的指令集手冊。當然,JavaScript引擎的工作也不只是編譯程式碼,它還要負責執行程式碼、分配記憶體以及垃圾回收。
雖然瀏覽器非常多,但是主流的JavaScirpt引擎其實很少,畢竟開發一個JavaScript引擎是一件非常複雜的事情。比較出名的JS引擎有這些:
- V8 (Google)
- SpiderMonkey (Mozilla)
- JavaScriptCore (Apple)
- Chakra (Microsoft)
- IOT:duktape、JerryScript
還有,最近釋出QuickJS與Hermes也是JS引擎,它們都超越了瀏覽器範疇,Atwood's Law再次得到了證明:
Any application that can be written in JavaScript, will eventually be written in JavaScript.
V8:強大的JavaScript引擎
在為數不多JavaScript引擎中,V8無疑是最流行的,Chrome與Node.js都使用了V8引擎,Chrome的市場佔有率高達60%,而Node.js是JS後端程式設計的事實標準。國內的眾多瀏覽器,其實都是基於Chromium瀏覽器開發,而Chromium相當於開源版本的Chrome,自然也是基於V8引擎的。神奇的是,就連瀏覽器界的獨樹一幟的Microsoft也投靠了Chromium陣營。另外,Electron是基於Node.js與Chromium開發桌面應用,也是基於V8的。
V8引擎是2008年釋出的,它的命名靈感來自超級效能車的V8引擎,敢於這樣命名確實需要一些實力,它效能確實一直在穩步提高,下面是使用Speedometer benchmark的測試結果:
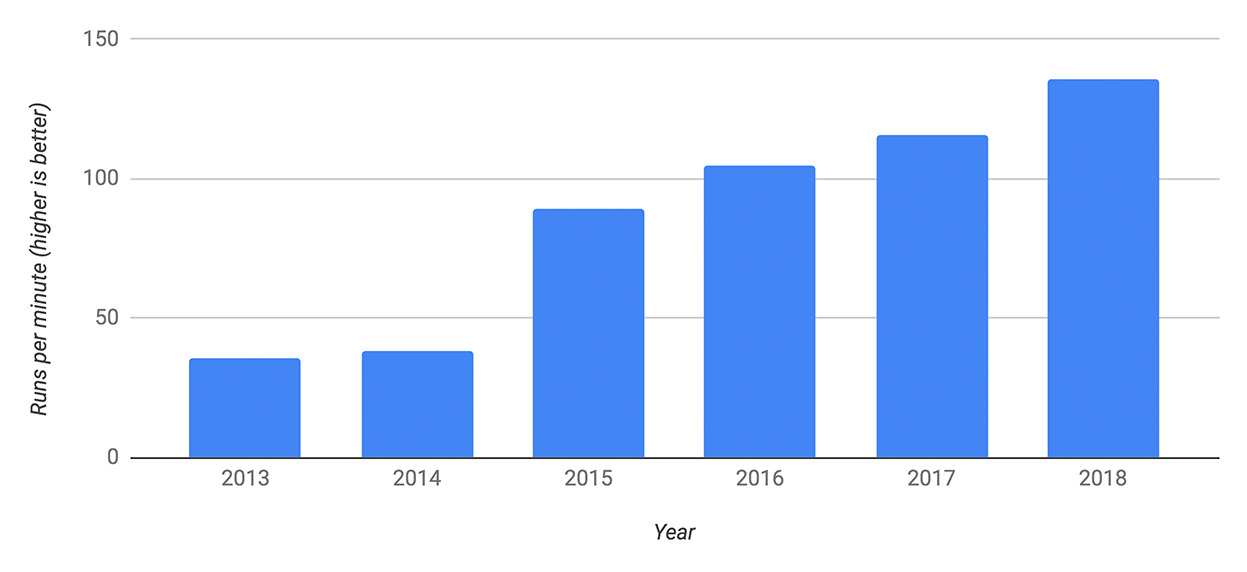
V8在工業界已經非常成功了,同時它還獲得了學術界的肯定,拿到了ACM SIGPLAN的Programming Languages Software Award:
V8's success is in large part due to the efficient machine code it generates. Because JavaScript is a highly dynamic object-oriented language, many experts believed that this level of performance could not be achieved. V8's performance breakthrough has had a major impact on the adoption of JavaScript, which is nowadays used on the browser, the server, and probably tomorrow on the small devices of the internet-of-things.
JavaScript是一門動態型別語言,這會給編譯器增加很大難度,因此專家們覺得它的效能很難提高,但是V8居然做到了,生成了非常高效的machine code(其實是彙編程式碼),這使得JS可以應用在各個領域,比如Web、APP、桌面端、服務端以及IOT。
嚴格來講,V8所生成的程式碼是彙編程式碼而非機器程式碼,但是V8相關的文件、部落格以及其他資料都把V8生成的程式碼稱作machine code。彙編程式碼與機器程式碼很多是一一對應的,也很容易互相轉換,這也是反編譯的原理,因此他們把V8生成的程式碼稱為Machine Code也未嘗不可,但是並不嚴謹。
V8引擎的內部結構
V8是一個非常複雜的專案,使用cloc統計可知,它竟然有超過100萬行C++程式碼。
V8由許多子模組構成,其中這4個模組是最重要的:
- Parser:負責將JavaScript原始碼轉換為Abstract Syntax Tree (AST)
- Ignition:interpreter,即直譯器,負責將AST轉換為Bytecode,解釋執行Bytecode;同時收集TurboFan優化編譯所需的資訊,比如函式引數的型別;
- TurboFan:compiler,即編譯器,利用Ignitio所收集的型別資訊,將Bytecode轉換為優化的彙編程式碼;
- Orinoco:garbage collector,垃圾回收模組,負責將程式不再需要的記憶體空間回收;
其中,Parser,Ignition以及TurboFan可以將JS原始碼編譯為彙編程式碼,其流程圖如下:
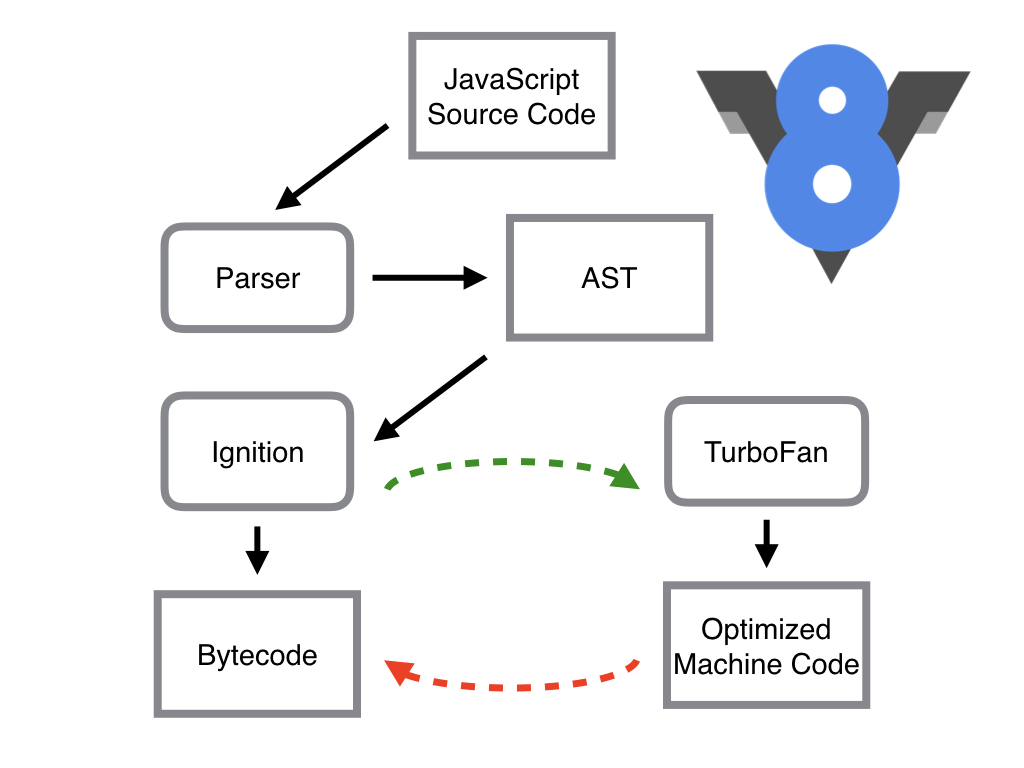
簡單地說,Parser將JS原始碼轉換為AST,然後Ignition將AST轉換為Bytecode,最後TurboFan將Bytecode轉換為經過優化的Machine Code(實際上是彙編程式碼)。
- 如果函式沒有被呼叫,則V8不會去編譯它。
- 如果函式只被呼叫1次,則Ignition將其編譯Bytecode就直接解釋執行了。TurboFan不會進行優化編譯,因為它需要Ignition收集函式執行時的型別資訊。這就要求函式至少需要執行1次,TurboFan才有可能進行優化編譯。
- 如果函式被呼叫多次,則它有可能會被識別為熱點函式,且Ignition收集的型別資訊證明可以進行優化編譯的話,這時TurboFan則會將Bytecode編譯為Optimized Machine Code,以提高程式碼的執行效能。
圖片中的紅線是逆向的,這的確有點奇怪,Optimized Machine Code會被還原為Bytecode,這個過程叫做Deoptimization。這是因為Ignition收集的資訊可能是錯誤的,比如add函式的引數之前是整數,後來又變成了字串。生成的Optimized Machine Code已經假定add函式的引數是整數,那當然是錯誤的,於是需要進行Deoptimization。
function add(x, y) {
return x + y;
}
add(1, 2);
add("1", "2");
在執行C、C++以及Java等程式之前,需要進行編譯,不能直接執行原始碼;但對於JavaScript來說,我們可以直接執行原始碼(比如:node server.js),它是在執行的時候先編譯再執行,這種方式被稱為即時編譯(Just-in-time compilation),簡稱為JIT。因此,V8也屬於JIT編譯器。
Ignition:直譯器

Node.js是基於V8引擎實現的,因此node命令提供了很多V8引擎的選項,使用node的--print-bytecode選項,可以打印出Ignition生成的Bytecode。
factorial.js如下,由於V8不會編譯沒有被呼叫的函式,因此需要在最後一行呼叫factorial函式。
function factorial(N) {
if (N === 1) {
return 1;
} else {
return N * factorial(N - 1);
}
}
factorial(10); // V8不會編譯沒有被呼叫的函式,因此這一行不能省略
使用node命令(node版本為12.6.0)的--print-bytecode選項,打印出Ignition生成的Bytecode:
node --print-bytecode factorial.js
控制檯輸出的內容非常多,最後一部分是factorial函式的Bytecode:
[generated bytecode for function: factorial]
Parameter count 2
Register count 3
Frame size 24
18 E> 0x3541c2da112e @ 0 : a5 StackCheck
28 S> 0x3541c2da112f @ 1 : 0c 01 LdaSmi [1]
34 E> 0x3541c2da1131 @ 3 : 68 02 00 TestEqualStrict a0, [0]
0x3541c2da1134 @ 6 : 99 05 JumpIfFalse [5] (0x3541c2da1139 @ 11)
51 S> 0x3541c2da1136 @ 8 : 0c 01 LdaSmi [1]
60 S> 0x3541c2da1138 @ 10 : a9 Return
82 S> 0x3541c2da1139 @ 11 : 1b 04 LdaImmutableCurrentContextSlot [4]
0x3541c2da113b @ 13 : 26 fa Star r1
0x3541c2da113d @ 15 : 25 02 Ldar a0
105 E> 0x3541c2da113f @ 17 : 41 01 02 SubSmi [1], [2]
0x3541c2da1142 @ 20 : 26 f9 Star r2
93 E> 0x3541c2da1144 @ 22 : 5d fa f9 03 CallUndefinedReceiver1 r1, r2, [3]
91 E> 0x3541c2da1148 @ 26 : 36 02 01 Mul a0, [1]
110 S> 0x3541c2da114b @ 29 : a9 Return
Constant pool (size = 0)
Handler Table (size = 0)
生成的Bytecode其實挺簡單的:
- 使用LdaSmi命令將整數1儲存到暫存器;
- 使用TestEqualStrict命令比較引數a0與1的大小;
- 如果a0與1相等,則JumpIfFalse命令不會跳轉,繼續執行下一行程式碼;
- 如果a0與1不相等,則JumpIfFalse命令會跳轉到記憶體地址0x3541c2da1139
- ...
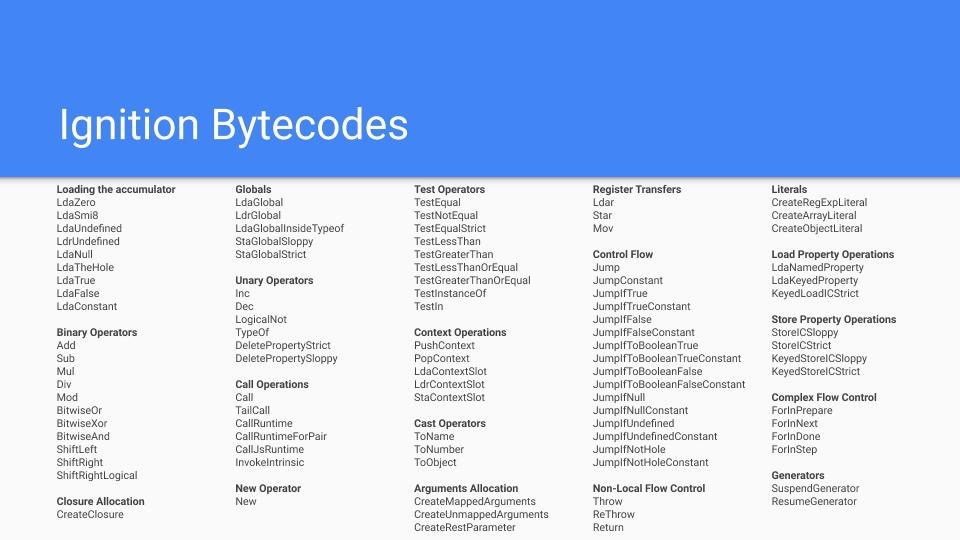
不難發現,Bytecode某種程度上就是組合語言,只是它沒有對應特定的CPU,或者說它對應的是虛擬的CPU。這樣的話,生成Bytecode時簡單很多,無需為不同的CPU生產不同的程式碼。要知道,V8支援9種不同的CPU,引入一箇中間層Bytecode,可以簡化V8的編譯流程,提高可擴充套件性。
如果我們在不同硬體上去生成Bytecode,會發現生成程式碼的指令是一樣的:
TurboFan:編譯器

使用node命令的--print-code以及--print-opt-code選項,打印出TurboFan生成的彙編程式碼:
node --print-code --print-opt-code factorial.js
我是在Mac上執行的,結果如下圖所示:
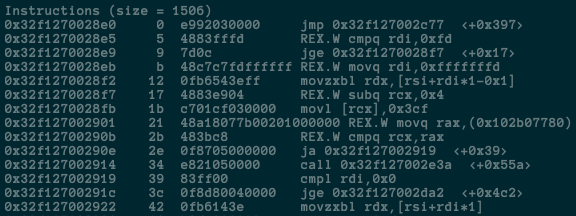
比起Bytecode,正真的彙編程式碼可讀性差很多。而且,機器的CPU型別不一樣的話,生成的彙編程式碼也不一樣。
這些彙編程式碼就不用去管它了,因為最重要的是理解TurboFan是如何優化所生成的彙編程式碼的。我們可以通過add函式來梳理整個優化過程。
function add(x, y) {
return x + y;
}
add(1, 2);
add(3, 4);
add(5, 6);
add("7", "8");
由於JS的變數是沒有型別的,所以add函式的引數可以是任意型別:Number、String、Boolean等,這就意味著add函式可能是數字相加(V8還會區分整數和浮點數),可能是字串拼接,也可能是其他更復雜的操作。如果直接編譯的話,生成的程式碼比如會有很多if...else分支,虛擬碼如下:
if (isInteger(x) && isInteger(y)) {
// 整數相加
} else if (isFloat(x) && isFloat(y)) {
// 浮點數相加
} else if (isString(x) && isString(y)) {
// 字串拼接
} else {
// 各種其他情況
}
我只寫了4個分支,實際上的分支其實更多,比如當引數型別不一致時還得進行型別轉換,大家不妨看看ECMASCript對加法是如何定義的:12.8.3The Addition Operator ( + )。
如果直接按照虛擬碼去生成彙編程式碼,那生成的程式碼必然非常冗長,這樣會佔用很多記憶體空間。
Ignition在執行add(1, 2)時,已經知道add函式的兩個引數都是整數,那麼TurboFan在編譯Bytecode時,就可以假定add函式的引數是整數,這樣可以極大地簡化生成的彙編程式碼,虛擬碼如下:
if (isInteger(x) && isInteger(y)) {
// 整數相加
} else {
// Deoptimization
}
當然這樣做也是有風險的,因為如果add函式引數不是整數,那麼生成的彙編程式碼也沒法執行,只能Deoptimize為Bytecode來執行。
也就是說,如果TurboFan對add函式進行編譯優化的話,則add(3, 4)與add(3, 4)可以執行優化的彙編程式碼,但是add("7", "8")只能Deoptimize為Bytecode來執行。
當然,TurboFan所做的也不只是根據型別資訊來簡化程式碼執行流程,它還會進行其他優化,比如減少冗餘程式碼等更復雜的事情。
由這個簡單的例子可知,如果我們的JS程式碼中變數的型別變來變去,是會給V8引擎增加不少麻煩的,為了提高效能,我們可以儘量不要去改變變數的型別。
對於效能要求比較高的專案,使用TypeScript也是不錯的選擇,理論上,如果嚴格遵守型別化的程式設計方式,也是可以提高效能的,型別化的程式碼有利於V8引擎優化編譯的彙編程式碼,當然這一點還需要測試資料來證明。
Orinoco:垃圾回收

強大的垃圾回收功能是V8實現提高效能的關鍵之一,因為它可以在避免影響JS程式碼執行的情況下,同時回收記憶體空間,提高記憶體利用效率。
關於垃圾回收,我在JavaScript深入淺出第3課:什麼是垃圾回收演算法?中有詳細介紹,這裡就不再贅述了。
JS引擎的未來
V8引擎確實很強大,但是它也不是無所不能的,簡單地分析都可以發現一些可以優化的點。
我有一個新的想法,還沒想好名字,不妨稱作Optimized TypeScript Engine:
- 使用TypeScript程式設計,遵循嚴格的型別化程式設計規則,不要寫成AnyScript了;
- 構建的時候將TypeScript直接編譯為Bytecode,而不是生成JS檔案,這樣執行的時候就省去了Parse以及生成Bytecode的過程;
- 執行的時候,需要先將Bytecode編譯為對應CPU的彙編程式碼;
- 由於採用了型別化的程式設計方式,有利於編譯器優化所生成的彙編程式碼,省去了很多額外的操作;
這個想法其實可以基於V8引擎來實現,技術上應該是可行的:
- 將Parser以及Ignition拆分出來,用於構建階段;
- 刪掉TurboFan處理JS動態特性的相關程式碼;
這樣做,可以將JS引擎簡化很多,一方面不再需要parse以及生成bytecode,另一方面編譯器不再需要因為JavaScript動態特性做很多額外的工作。因此可以減少CPU、記憶體以及電量的使用,優化效能,唯一的問題可能是必須使用嚴格的TS語法進行程式設計。
為啥要這樣做呢?因為對於IOT硬體來說,CPU、記憶體、電量都是需要省著點用的,不是每一個智慧家電都需要裝一個驍龍855,如果希望把JS應用到IOT領域,必然需要從JS引擎角度去進行優化,只是去做上層的框架是沒有用的。
其實,Facebook的Hermes差不多就是這麼幹的,只是它沒有要求用TS程式設計。
這應該是JS引擎的未來,大家會看到越來越多這樣的趨勢。
關於JS,我打算花1年時間寫一個系列的部落格**《JavaScript深入淺出》**,大家還有啥不太清楚的地方?不妨留言一下,我可以研究一下,然後再與大家分享一下。歡迎新增我的個人微信(KiwenLau),我是Fundebug的技術負責人,一個對JS又愛又恨的程式設計師。
參考
- Celebrating 10 years of V8
- Launching Ignition and TurboFan
- JavaScript engines - how do they even?
- An Introduction to Speculative Optimization in V8
- 2018年,JavaScript都經歷了什麼?
- JavaScript深入淺出第3課:什麼是垃圾回收演算法?
- Fabrice Bellard 是個什麼水平的程式設計師?
- 如何評價 Fabrice Bellard 釋出 QuickJS JS 引擎?
關於Fundebug
Fundebug專注於JavaScript、微信小程式、微信小遊戲、支付寶小程式、React Native、Node.js和Java線上應用實時BUG監控。 自從2016年雙十一正式上線,Fundebug累計處理了10億+錯誤事件,付費客戶有陽光保險、核桃程式設計、荔枝FM、掌門1對1、微脈、青團社等眾多品牌企業。歡迎大家免費試用!

版權宣告
轉載時請註明作者 Fundebug以及本文地址: https://blog.fundebug.com/2019/07/16/