
Flink 靈魂兩百問,這誰頂得住?
Flink 學習
https://github.com/zhisheng17/flink-learning
麻煩路過的各位親給這個專案點個 star,太不易了,寫了這麼多,算是對我堅持下來的一種鼓勵吧!
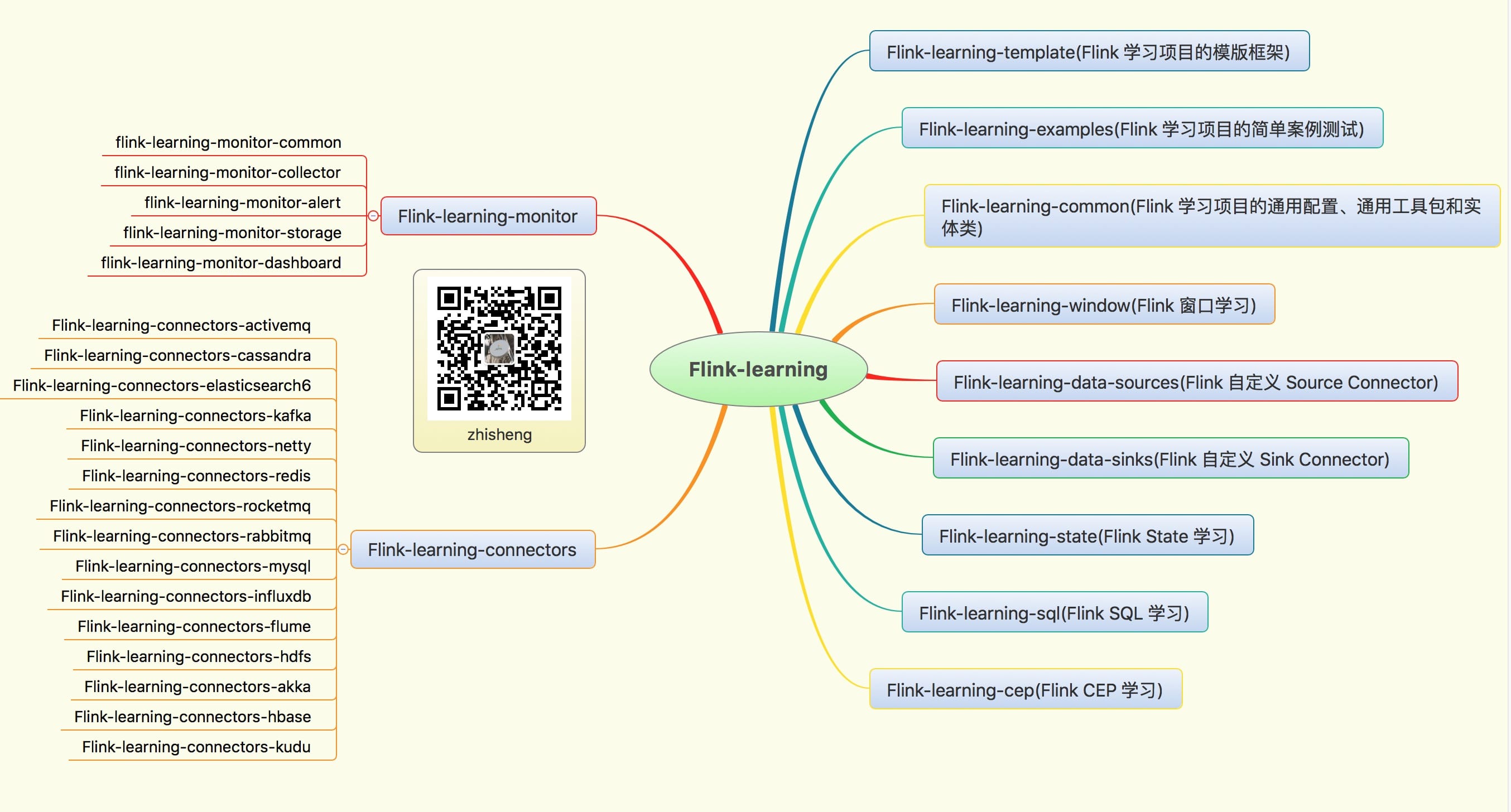
本專案結構
2019/06/08 新增 Flink 四本電子書籍的 PDF,在 books 目錄下:
Introduction_to_Apache_Flink_book.pdf 這本書比較薄,處於介紹階段,國內有這本的翻譯書籍
Learning Apache Flink.pdf 這本書比較基礎,初學的話可以多看看
Stream Processing with Apache Flink.pdf 這本書是 Flink PMC 寫的
Streaming System.pdf 這本書評價不是一般的高
2019/06/09 新增流處理引擎相關的 Paper,在 paper 目錄下:
- 流處理引擎相關的 Paper
部落格
1、Flink 從0到1學習 —— Apache Flink 介紹
2、Flink 從0到1學習 —— Mac 上搭建 Flink 1.6.0 環境並構建執行簡單程式入門
3、Flink 從0到1學習 —— Flink 配置檔案詳解
4、Flink 從0到1學習 —— Data Source 介紹
5、Flink 從0到1學習 —— 如何自定義 Data Source ?
6、Flink 從0到1學習 —— Data Sink 介紹
7、Flink 從0到1學習 —— 如何自定義 Data Sink ?
8、Flink 從0到1學習 —— Flink Data transformation(轉換)
9、Flink 從0到1學習 —— 介紹 Flink 中的 Stream Windows
10、Flink 從0到1學習 —— Flink 中的幾種 Time 詳解
11、Flink 從0到1學習 —— Flink 讀取 Kafka 資料寫入到 ElasticSearch
12、Flink 從0到1學習 —— Flink 專案如何執行?
13、Flink 從0到1學習 —— Flink 讀取 Kafka 資料寫入到 Kafka
14、Flink 從0到1學習 —— Flink JobManager 高可用性配置
15、Flink 從0到1學習 —— Flink parallelism 和 Slot 介紹
16、Flink 從0到1學習 —— Flink 讀取 Kafka 資料批量寫入到 MySQL
17、Flink 從0到1學習 —— Flink 讀取 Kafka 資料寫入到 RabbitMQ
18、Flink 從0到1學習 —— Flink 讀取 Kafka 資料寫入到 HBase
19、Flink 從0到1學習 —— Flink 讀取 Kafka 資料寫入到 HDFS
20、Flink 從0到1學習 —— Flink 讀取 Kafka 資料寫入到 Redis
21、Flink 從0到1學習 —— Flink 讀取 Kafka 資料寫入到 Cassandra
22、Flink 從0到1學習 —— Flink 讀取 Kafka 資料寫入到 Flume
23、Flink 從0到1學習 —— Flink 讀取 Kafka 資料寫入到 InfluxDB
24、Flink 從0到1學習 —— Flink 讀取 Kafka 資料寫入到 RocketMQ
25、Flink 從0到1學習 —— 你上傳的 jar 包藏到哪裡去了
26、Flink 從0到1學習 —— 你的 Flink job 日誌跑到哪裡去了
Flink 原始碼專案結構
學習資料
另外我自己整理了些 Flink 的學習資料,目前已經全部放到微信公眾號了。
你可以加我的微信:zhisheng_tian,然後回覆關鍵字:Flink 即可無條件獲取到,轉載請聯絡本人獲取授權,違者必究。

更多私密資料請加入知識星球!

有人要問知識星球裡面更新什麼內容?值得加入嗎?
目前知識星球內已更新的系列文章:
1、Flink 原始碼解析 —— 原始碼編譯執行
2、Flink 原始碼解析 —— 專案結構一覽
3、Flink 原始碼解析—— local 模式啟動流程
4、Flink 原始碼解析 —— standalonesession 模式啟動流程
5、Flink 原始碼解析 —— Standalone Session Cluster 啟動流程深度分析之 Job Manager 啟動
6、Flink 原始碼解析 —— Standalone Session Cluster 啟動流程深度分析之 Task Manager 啟動
7、Flink 原始碼解析 —— 分析 Batch WordCount 程式的執行過程
8、Flink 原始碼解析 —— 分析 Streaming WordCount 程式的執行過程
9、Flink 原始碼解析 —— 如何獲取 JobGraph?
10、Flink 原始碼解析 —— 如何獲取 StreamGraph?
11、Flink 原始碼解析 —— Flink JobManager 有什麼作用?
12、Flink 原始碼解析 —— Flink TaskManager 有什麼作用?
13、Flink 原始碼解析 —— JobManager 處理 SubmitJob 的過程
14、Flink 原始碼解析 —— TaskManager 處理 SubmitJob 的過程
15、Flink 原始碼解析 —— 深度解析 Flink Checkpoint 機制
16、Flink 原始碼解析 —— 深度解析 Flink 序列化機制
17、Flink 原始碼解析 —— 深度解析 Flink 是如何管理好記憶體的?
18、Flink Metrics 原始碼解析 —— Flink-metrics-core
19、Flink Metrics 原始碼解析 —— Flink-metrics-datadog
20、Flink Metrics 原始碼解析 —— Flink-metrics-dropwizard
21、Flink Metrics 原始碼解析 —— Flink-metrics-graphite
22、Flink Metrics 原始碼解析 —— Flink-metrics-influxdb
23、Flink Metrics 原始碼解析 —— Flink-metrics-jmx
24、Flink Metrics 原始碼解析 —— Flink-metrics-slf4j
25、Flink Metrics 原始碼解析 —— Flink-metrics-statsd
26、Flink Metrics 原始碼解析 —— Flink-metrics-prometheus
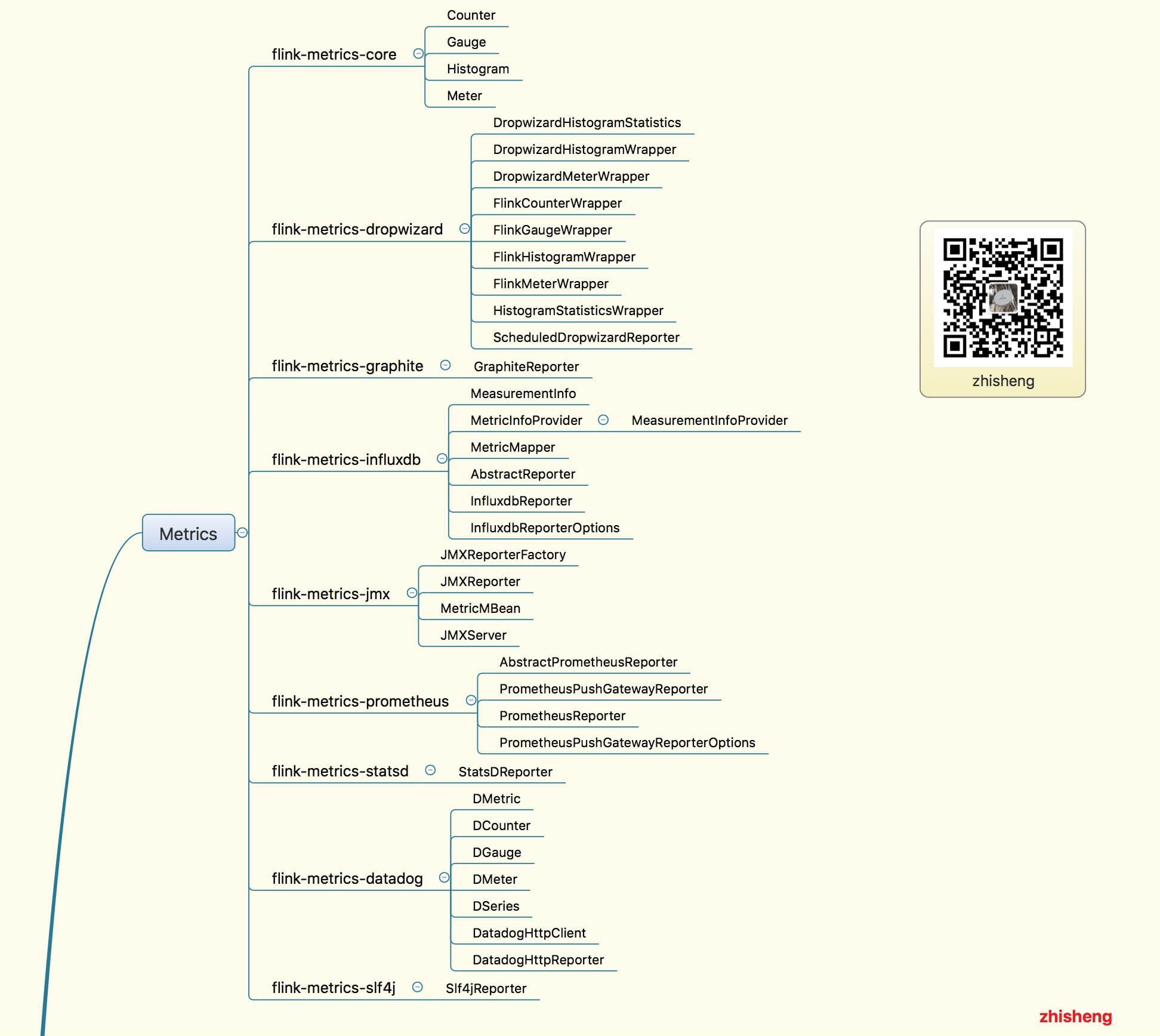
26、Flink Annotations 原始碼解析

除了《從1到100深入學習Flink》原始碼學習這個系列文章,《從0到1學習Flink》的案例文章也會優先在知識星球更新,讓大家先通過一些 demo 學習 Flink,再去深入原始碼學習!
如果學習 Flink 的過程中,遇到什麼問題,可以在裡面提問,我會優先解答,這裡做個抱歉,自己平時工作也挺忙,微信的問題不能做全部做一些解答,
但肯定會優先回復給知識星球的付費使用者的,慶幸的是現在星球裡的活躍氛圍還是可以的,有不少問題通過提問和解答的方式沉澱了下來。
1、為何我使用 ValueState 儲存狀態 Job 恢復是狀態沒恢復?
2、flink中watermark究竟是如何生成的,生成的規則是什麼,怎麼用來處理亂序資料
3、消費kafka資料的時候,如果遇到了髒資料,或者是不符合規則的資料等等怎麼處理呢?
4、在Kafka 叢集中怎麼指定讀取/寫入資料到指定broker或從指定broker的offset開始消費?
5、Flink能通過oozie或者azkaban提交嗎?
6、jobmanager掛掉後,提交的job怎麼不經過手動重新提交執行?
7、使用flink-web-ui提交作業並執行 但是/opt/flink/log目錄下沒有日誌檔案 請問關於flink的日誌(包括jobmanager、taskmanager、每個job自己的日誌預設分別存在哪個目錄 )需要怎麼配置?
8、通過flink 儀表盤提交的jar 是儲存在哪個目錄下?
9、從Kafka消費資料進行etl清洗,把結果寫入hdfs對映成hive表,壓縮格式、hive直接能夠讀取flink寫出的檔案、按照檔案大小或者時間滾動生成檔案
10、flink jar包上傳至叢集上執行,掛掉後,掛掉期間kafka中未被消費的資料,在重新啟動程式後,是自動從checkpoint獲取掛掉之前的kafka offset位置,自動消費之前的資料進行處理,還是需要某些手動的操作呢?
11、flink 啟動時不自動建立 上傳jar的路徑,能指定一個建立好的目錄嗎
12、Flink sink to es 叢集上報 slot 不夠,單機跑是好的,為什麼?
13、Fllink to elasticsearch如何建立索引文件期時間戳?
14、blink有沒有api文件或者demo,是否建議blink用於生產環境。
15、flink的Python api怎樣?bug多嗎?
16、Flink VS Spark Streaming VS Storm VS Kafka Stream
17、你們做實時大屏的技術架構是什麼樣子的?flume→kafka→flink→redis,然後後端去redis裡面撈資料,醬紫可行嗎?
18、做一個統計指標的時候,需要在Flink的計算過程中多次讀寫redis,感覺好怪,星主有沒有好的方案?
19、Flink 使用場景大分析,列舉了很多的常用場景,可以好好參考一下
20、將kafka中資料sink到mysql時,metadata的資料為空,匯入mysql資料不成功???
21、使用了ValueState來儲存中間狀態,在執行時中間狀態儲存正常,但是在手動停止後,再重新執行,發現中間狀態值沒有了,之前出現的鍵值是從0開始計數的,這是為什麼?是需要實現CheckpointedFunction嗎?
22、flink on yarn jobmanager的HA需要怎麼配置。還是說yarn給管理了
23、有兩個資料流就行connect,其中一個是實時資料流(kafka 讀取),另一個是配置流。由於配置流是從關係型資料庫中讀取,速度較慢,導致實時資料流流入資料的時候,配置資訊還未傳送,這樣會導致有些實時資料讀取不到配置資訊。目前採取的措施是在connect方法後的flatmap的實現的在open 方法中,提前載入一次配置資訊,感覺這種實現方式不友好,請問還有其他的實現方式嗎?
24、Flink能通過oozie或者azkaban提交嗎?
25、不採用yarm部署flink,還有其他的方案嗎? 主要想解決伺服器重啟後,flink服務怎麼自動拉起? jobmanager掛掉後,提交的job怎麼不經過手動重新提交執行?
26、在一個 Job 裡將同份資料昨晚清洗操作後,sink 到後端多個地方(看業務需求),如何保持一致性?(一個sink出錯,另外的也保證不能插入)
27、flink sql任務在某個特定階段會發生tm和jm丟失心跳,是不是由於gc時間過長呢,
28、有這樣一個需求,統計使用者近兩週進入產品詳情頁的來源(1首頁大搜索,2產品頻道搜尋,3其他),為php後端提供資料支援,該資訊在端上報事件中,php直接獲取有點困難。 我現在的解決方案 通過flink滾動視窗(半小時),統計使用者半小時內3個來源pv,然後按照日期序列化,直接寫mysql。php從資料庫中解析出來,再去統計近兩週佔比。 問題1,這個需求適合用flink去做嗎? 問題2,我的方案總感覺怪怪的,有沒有好的方案?
29、一個task slot 只能同時執行一個任務還是多個任務呢?如果task slot執行的任務比較大,會出現OOM的情況嗎?
30、你們怎麼對線上flink做監控的,如果整個程式失敗了怎麼自動重啟等等
31、flink cep規則動態解析有接觸嗎?有沒有成型的框架?
32、每一個Window都有一個watermark嗎?window是怎麼根據watermark進行觸發或者銷燬的?
33、CheckPoint與SavePoint的區別是什麼?
34、flink可以在運算元中共享狀態嗎?或者大佬你有什麼方法可以共享狀態的呢?
35、執行幾分鐘就報了,看taskmager日誌,報的是 failed elasticsearch bulk request null,可是我程式碼裡面已經做過空值判斷了呀 而且也過濾掉了,flink版本1.7.2 es版本6.3.1
36、這種情況,我們調並行度 還是配置引數好
37、大家都用jdbc寫,各種資料庫增刪查改拼sql有沒有覺得很累,ps.set程式碼一大堆,還要計算每個引數的位置
38、關於datasource的配置,每個taskmanager對應一個datasource?還是每個slot? 實際執行下來,每個slot中datasorce執行緒池只要設定1就行了,多了也用不到?
39、kafka現在每天出現數據丟失,現在小批量資料,一天200W左右, kafka版本為 1.0.0,叢集總共7個節點,TOPIC有十六個分割槽,單條報文1.5k左右
40、根據key.hash的絕對值 對併發度求模,進行分組,假設10各併發度,實際只有8個分割槽有處理資料,有2個始終不處理,還有一個分割槽處理的資料是其他的三倍,如截圖
41、flink每7小時不知道在處理什麼, CPU 負載 每7小時,有一次高峰,5分鐘內平均負載超過0.8,如截圖
42、有沒有Flink寫的專案推薦?我想看到用Flink寫的整體專案是怎麼組織的,不單單是一個單例子
43、Flink 原始碼的結構圖
44、我想根據不同業務表(case when)進行不同的redis sink(hash ,set),我要如何操作?
45、這個需要清理什麼資料呀,我把hdfs裡面的已經清理了 啟動還是報這個
46、在流處理系統,在機器發生故障恢復之後,什麼情況訊息最多會被處理一次?什麼情況訊息最少會被處理一次呢?
47、我檢查點都調到5分鐘了,這是什麼問題
48、reduce方法後 那個交易時間 怎麼不是最新的,是第一次進入的那個時間,
49、Flink on Yarn 模式,用yarn session指令碼啟動的時候,我在後臺沒有看到到Jobmanager,TaskManager,ApplicationMaster這幾個程序,想請問一下這是什麼原因呢?因為之前看官網的時候,說Jobmanager就是一個jvm程序,Taskmanage也是一個JVM程序
50、Flink on Yarn的時候得指定 多少個TaskManager和每個TaskManager slot去執行任務,這樣做感覺不太合理,因為使用者也不知道需要多少個TaskManager適合,Flink 有動態啟動TaskManager的機制嗎。
51、參考這個例子,Flink 零基礎實戰教程:如何計算實時熱門商品 | Jark's Blog, 視窗聚合的時候,用keywindow,用的是timeWindowAll,然後在aggregate的時候用aggregate(new CustomAggregateFunction(), new CustomWindowFunction()),列印結果後,發現視窗中一直使用的重複的資料,統計的結果也不變,去掉CustomWindowFunction()就正常了 ? 非常奇怪
52、使用者進入產品預定頁面(端埋點上報),並填寫了一些資訊(端埋點上報),但半小時內並沒有產生任何訂單,然後給該類使用者傳送一個push。 1. 這種需求適合用flink去做嗎?2. 如果適合,說下大概的思路
53、業務場景是實時獲取資料存redis,請問我要如何按天、按周、按月分別存入redis裡?(比方說過了一天自動換一個位置存redis)
54、有人 AggregatingState 的例子嗎, 感覺官方的例子和 官網的不太一樣?
55、flink-jdbc這個jar有嗎?怎麼沒找到啊?1.8.0的沒找到,1.6.2的有
56、現有個關於savepoint的問題,操作流程為,取消任務時設定儲存點,更新任務,從儲存點啟動任務;現在遇到個問題,假設我中間某個運算元重寫,原先通過state編寫,有用定時器,現在更改後,採用視窗,反正就是實現方式完全不一樣;從儲存點啟動就會一直報錯,重啟,原先的儲存點不能還原,此時就會有很多資料重複等各種問題,如何才能保證資料不丟失,不重複等,恢復到停止的時候,現在想到的是記下kafka的偏移量,再做處理,貌似也不是很好弄,有什麼解決辦法嗎
57、需要在flink計算app頁面訪問時長,消費Kafka計算後輸出到Kafka。第一條log需要等待第二條log的時間戳計算訪問時長。我想問的是,flink是分散式的,那麼它能否保證執行的順序性?後來的資料有沒有可能先被執行?
58、我公司想做實時大屏,現有技術是將業務所需指標實時用spark拉到redis裡存著,然後再用一條spark streaming流計算簡單乘除運算,指標包含了各月份的比較。請問我該如何用flink簡化上述流程?
59、flink on yarn 方式,這樣理解不知道對不對,yarn-session這個指令碼其實就是準備yarn環境的,執行run任務的時候,根據yarn-session初始化的yarnDescription 把 flink 任務的jobGraph提交到yarn上去執行
60、同樣的程式碼邏輯寫在單獨的main函式中就可以成功的消費kafka ,寫在一個spring boot的程式中,接受外部請求,然後執行相同的邏輯就不能消費kafka。你遇到過嗎?能給一些查問題的建議,或者在哪裡打個斷點,能看到為什麼消費不到kafka的訊息呢?
61、請問下flink可以實現一個流中同時存在訂單表和訂單商品表的資料 兩者是一對多的關係 能實現得到 以訂單表為主 一個訂單多個商品 這種需求嘛
62、在用中間狀態的時候,如果中間一些資訊儲存在state中,有沒有必要在redis中再儲存一份,來做第三方的儲存。
63、能否出一期flink state的文章。什麼場景下用什麼樣的state?如,最簡單的,實時累加update到state。
64、flink的雙流join博主有使用的經驗嗎?會有什麼常見的問題嗎
65、視窗觸發的條件問題
66、flink 定時任務怎麼做?有相關的demo麼?
67、流式處理過程中資料的一致性如何保證或者如何檢測
68、重啟flink單機叢集,還報job not found 異常。
69、kafka的資料是用 org.apache.kafka.common.serialization.ByteArraySerialize序列化的,flink這邊消費的時候怎麼通過FlinkKafkaConsumer建立DataStream
70、現在公司有一個需求,一些使用者的支付日誌,通過sls收集,要把這些日誌處理後,結果寫入到MySQL,關鍵這些日誌可能連著來好幾條才是一個使用者的,因為發起請求,響應等每個環節都有相應的日誌,這幾條日誌綜合處理才能得到最終的結果,請問博主有什麼好的方法沒有?
71、flink 支援hadoop 主備麼? hadoop主節點掛了 flink 會切換到hadoop 備用節點?
72、請教大家: 實際 flink 開發中用 scala 多還是 java多些? 剛入手 flink 大資料 scala 需要深入學習麼?
73、我使用的是flink是1.7.2最近用了split的方式分流,但是底層的SplitStream上卻標註為Deprecated,請問是官方不推薦使用分流的方式嗎?
74、KeyBy 的正確理解,和資料傾斜問題的解釋
75、用flink時,遇到個問題 checkpoint大概有2G左右, 有背壓時,flink會重啟有遇到過這個問題嗎
76、flink使用yarn-session方式部署,如何保證yarn-session的穩定性,如果yarn-session掛了,需要重新部署一個yarn-session,如何恢復之前yarn-session上的job呢,之前的checkpoint還能使用嗎?
77、我想請教一下關於sink的問題。我現在的需求是從Kafka消費Json資料,這個Json資料欄位可能會增加,然後將拿到的json資料以parquet的格式存入hdfs。現在我可以拿到json資料的schema,但是在儲存parquet檔案的時候不知道怎麼處理。一是flink沒有專門的format parquet,二是對於可變欄位的Json怎麼處理成parquet比較合適?
78、flink如何在較大的資料量中做去重計算。
79、flink能在沒有資料的時候也定時執行運算元嗎?
80、使用rocksdb狀態後端,自定義pojo怎麼實現序列化和反序列化的,有相關demo麼?
81、check point 老是失敗,是不是自定義的pojo問題?到本地可以,到hdfs就不行,網上也有很多類似的問題 都沒有一個很好的解釋和解決方案
82、cep規則如圖,當start事件進入時,時間00:00:15,而後進入end事件,時間00:00:40。我發現規則無法命中。請問within 是從start事件開始計時?還是跟window一樣根據系統時間劃分的?如果是後者,請問怎麼配置才能從start開始計時?
83、Flink聚合結果直接寫Mysql的冪等性設計問題
84、Flink job打開了checkpoint,用的rocksdb,通過觀察hdfs上checkpoint目錄,為啥算副本總量會暴增爆減
85、Flink 提交任務的 jar包可以指定路徑為 HDFS 上的嗎
86、在flink web Ui上提交的任務,設定的並行度為2,flink是stand alone部署的。兩個任務都正常的運行了幾天了,今天有個地方邏輯需要修改,於是將任務cancel掉(在命令列cancel也試了),結果taskmanger掛掉了一個節點。後來用其他任務試了,也同樣會導致節點掛掉
87、一個配置動態更新的問題折騰好久(配置用個靜態的map變數存著,有個執行緒定時去資料庫撈資料然後存在這個map裡面更新一把),本地 idea 除錯沒問題,叢集部署就一直報 空指標異常。下游的運算元使用這個靜態變數map去get key在叢集模式下會出現這個空指標異常,估計就是拿不到 map
88、批量寫入MySQL,完成HBase批量寫入
89、用flink清洗資料,其中要訪問redis,根據redis的結果來決定是否把資料傳遞到下流,這有可能實現嗎?
90、監控頁面流處理的時候這個傳送和接收位元組為0。
91、sink到MySQL,如果直接用idea的話可以執行,並且成功,大大的程式碼上面用的FlinkKafkaConsumer010,而我的Flink版本為1.7,kafka版本為2.12,所以當我用FlinkKafkaConsumer010就有問題,於是改為
FlinkKafkaConsumer就可以直接在idea完成sink到MySQL,但是為何當我把該程式打成Jar包,去執行的時候,就是報FlinkKafkaConsumer找不到呢
92、SocketTextStreamWordCount中輸入中文統計不出來,請問這個怎麼解決,我猜測應該是需要修改一下程式碼,應該是這個例子預設統計英文
93、Flink 應用程式本地 ide 裡面執行的時候並行度是怎麼算的?
94、請問下flink中對於視窗的全量聚合有apply和process兩種 他們有啥區別呢
95、不知道大大熟悉Hbase不,我想直接在Hbase中查詢某一列資料,因為有重複資料,所以想使用distinct統計實際資料量,請問Hbase中有沒有類似於sql的distinct關鍵字。如果沒有,想實現這種可以不?
96、來分析一下現在Flink,Kafka方面的就業形勢,以及準備就業該如何準備的這方面內容呢?
97、大佬知道flink的dataStream可以轉換為dataSet嗎?因為資料需要11分鐘一個批次計算五六個指標,並且涉及好幾步reduce,計算的指標之間有聯絡,用Stream卡住了。
98、1.如何在同一視窗內實現多次的聚合,比如像spark中的這樣2.多個實時流的jion可以用window來處理一批次的資料嗎?
99、寫的批處理的功能,現在本機跑是沒問題的,就是在linux叢集上出現了問題,就是不知道如果通過本地呼叫遠端jar包然後傳引數和拿到結果引數返回本機
100、我用standalone開啟一個flink叢集,上傳flink官方用例Socket Window WordCount做測試,開啟兩個parallelism能正常執行,但是開啟4個parallelism後出現錯誤
101、有使用AssignerWithPunctuatedWatermarks 的案例Demo嗎?網上找了都是AssignerWithPeriodicWatermarks的,不知道具體怎麼使用?
102、有一個datastream(從檔案讀取的),然後我用flink sql進行計算,這個sql是一個加總的運算,然後通過retractStreamTableSink可以把檔案做sql的結果輸出到檔案嗎?這個輸出到檔案的介面是用什麼呢?
103、為啥split這個流設定為過期的
104、需要使用flink table的水印機制控制時間的亂序問題,這種場景下我就使用水印+視窗了,我現在寫的demo遇到了問題,就是在把觸發計算的視窗table(WindowedTable)轉換成table進行sql操作時發現視窗中的資料還是亂序的,是不是flink table的WindowedTable不支援水印視窗轉table-sql的功能
105、Flink 對 SQL 的重視性
106、flink job打開了checkpoint,任務跑了幾個小時後就出現下面的錯,截圖是打出來的日誌,有個OOM,又遇到過的沒?
107、本地測試是有資料的,之前該任務放在叢集也是有資料的,可能提交過多次,現在讀不到資料了 group id 也換過了, 只能重啟叢集解決麼?
108、使用flink清洗資料存到es中,直接在flatmap中對處理出來的資料用es自己的ClientInterface類直接將資料存入es當中,不走sink,這樣的處理邏輯是不是會有問題。
108、flink從kafka拿資料(即增量資料)與存量資料進行記憶體聚合的需求,現在有一個方案就是程式啟動的時候先用flink table將存量資料載入到記憶體中建立table中,然後將stream的增量資料與table的資料進行關聯聚合後輸出結束,不知道這種方案可行麼。目前個人認為有兩個主要問題:1是增量資料stream轉化成append table後不知道能與存量的table關聯聚合不,2是聚合後輸出的結果資料是否過於頻繁造成網路傳輸壓力過大
109、設定時間時間特性有什麼區別呢, 分別在什麼場景下使用呢?兩種設定時間延遲有什麼區別呢 , 分別在什麼場景下使用
110、flink從rabbitmq中讀取資料,設定了rabbitmq的CorrelationDataId和checkpoint為EXACTLY_ONCE;如果flink完成一次checkpoint後,在這次checkpoint之前消費的資料都會從mq中刪除。如果某次flink停機更新,那就會出現mq中的一些資料消費但是處於Unacked狀態。在flink又重新開啟後這批資料又會重新消費。那這樣是不是就不能保證EXACTLY_ONCE了
111、1. 在Flink checkpoint 中, 像 operator的狀態資訊 是在設定了checkpoint 之後自動的進行快照嗎 ?2. 上面這個和我們手動儲存的 Keyed State 進行快照(這個應該是增量快照)
112、現在有個實時商品數,交易額這種統計需求,打算用 flink從kafka讀取binglog日誌進行計算,但binglog涉及到insert和update這種操作時 怎麼處理才能統計準確,避免那種重複計算的問題?
113、我這邊用flink做實時監控,功能很簡單,就是每條訊息做keyby然後三分鐘視窗,然後做些去重操作,觸發閾值則報警,現在問題是同一個時間視窗同一個人的告警會觸發兩次,叢集是三臺機器,standalone cluster,初步結果是三個運算元裡有兩個收到了同樣的資料
114、在使用WaterMark的時候,預設是每200ms去設定一次watermark,那麼每個taskmanager之間,由於得到的資料不同,所以往往產生的最大的watermark不同。 那麼這個時候,是各個taskmanager廣播這個watermark,得到全域性的最大的watermark,還是說各個taskmanager都各自用自己的watermark。主要沒看到廣播watermark的原始碼。不知道是自己觀察不仔細還是就是沒有廣播這個變數。
115、現在遇到一個需求,需要在job內部定時去讀取redis的資訊,想請教flink能實現像普通程式那樣的定時任務嗎?
116、有個觸發事件開始聚合,等到數量足夠,或者超時則sink推mq 環境 flink 1.6 用了mapState 記錄觸發事件 1 資料足夠這個OK 2 超時state ttl 1.6支援,但是問題來了,如何在超時時候增加自定義處理?
117、請問impala這種mpp架構的sql引擎,為什麼穩定性比較差呢?
118、watermark跟並行度相關不是,過於全域性了,期望是keyby之後再針對每個keyed stream 打watermark,這個有什麼好的實踐呢?
119、請問如果把一個檔案的內容讀取成datastream和dataset,有什麼區別嗎??他們都是一條資料一條資料的被讀取嗎?
120、有沒有kylin相關的資料,或者調優的經驗?
121、flink先從jdbc讀取配置表到流中,另外從kafka中新增或者修改這個配置,這個場景怎麼把兩個流一份配置流?我用的connect,接著發不成廣播變數,再和實體流合併,但在合併時報Exception in thread "main" java.lang.IllegalArgumentException
122、Flink exactly-once,kafka版本為0.11.0 ,sink基於FlinkKafkaProducer011 每五分鐘一次checkpoint,但是checkpoint開始後系統直接卡死,at-lease-once 一分鐘能完成的checkpoint, 現在十分鐘無法完成沒進度還是0, 不知道哪裡卡住了
123、flink的狀態是預設存在於記憶體的(也可以設定為rocksdb或hdfs),而checkpoint裡面是定時存放某個時刻的狀態資訊,可以設定hdfs或rocksdb是這樣理解的嗎?
124、Flink非同步IO中,下圖這兩種有什麼區別?為啥要加 CompletableFuture.supplyAsync,不太明白?
125、flink的狀態是預設存在於記憶體的(也可以設定為rocksdb或hdfs),而checkpoint裡面是定時存放某個時刻的狀態資訊,可以設定hdfs或rocksdb是這樣理解的嗎?
126、有個計算場景,從kafka消費兩個資料來源,兩個資料結構都有時間段概念,計算需要做的是匹配兩個時間段,匹配到了,就生成一條新的記錄。請問使用哪個工具更合適,flink table還是cep?請大神指點一下 我這邊之前的做法,將兩個資料流轉為table.兩個table over window後join成新的表。結果job跑一會就oom.
127、一個網際網路公司,或者一個業務系統,如果想做一個全面的監控要怎麼做?有什麼成熟的方案可以參考交流嗎?有什麼有什麼度量指標嗎?
128、怎麼深入學習flink,或者其他大資料元件,能為未來秋招找一份大資料相關(計算方向)的工作增加自己的競爭力?
129、oppo的實時數倉,其中明細層和彙總層都在kafka中,他們的關係庫的實時資料也抽取到kafka的ods,那麼在構建數倉的,需要join 三四個大業務表,業務表會變化,那麼是大的業務表是從kafka的ods讀取嗎?實時數倉,多個大表join可以嗎
130、Tuple型別有什麼方法轉換成json字串嗎?現在的場景是,結果在儲存到sink中時希望存的是json字串,這樣應用程式獲取資料比較好轉換一點。如果Tuple不好轉換json字串,那麼應該以什麼資料格式儲存到sink中
140、端到端的資料保證,是否意味著中間處理程式中斷,也不會造成該批次處理失敗的訊息丟失,處理程式重新啟動之後,會再次處理上次未處理的訊息
141、關於flink datastream window相關的。比如我現在使用滾動視窗,統計一週內去重使用者指標,按照正常watermark觸發計算,需要等到當前周的window到達window的endtime時,才會觸發,這樣指標一週後才能產出結果。我能不能實現一小時觸發一次計算,每次統計截止到當前時間,window中所有到達元素的去重數量。
142、FLIP-16 Loop Fault Tolerance 是講現在的checkpoint機制無法在stream loop的時候容錯嗎?現在這個問題解決了沒有呀?
143、現在的需求是,統計各個key的今日累計值,一分鐘輸出一次。如,各個使用者今日累計點選次數。這種需求用datastream還是table API方便點?
144、本地idea可以跑的工程,放在standalone叢集上,總報錯,報錯截圖如下,大佬請問這是啥原因
145、比如現在用k8s起了一個flink叢集,這時候資料來源kafka或者hdfs會在同一個叢集上嗎,還是會單獨再起一個hdfs/kafka叢集
146、flink kafka sink 的FlinkFixedPartitioner 分配策略,在並行度小於topic的partitions時,一個並行例項固定的寫訊息到固定的一個partition,那麼就有一些partition沒資料寫進去?
147、基於事件時間,每五分鐘一個視窗,五秒鐘滑動一次,同時watermark的時間同樣是基於事件事件時間的,延遲設為1分鐘,假如資料流從12:00開始,如果12:07-12:09期間沒有產生任何一條資料,即在12:07-12:09這段間的資料流情況為···· (12:07:00,xxx),(12:09:00,xxx)······,那麼視窗[12:02:05-12:07:05],[12:02:10-12:07:10]等幾個視窗的計算是否意味著只有等到,12:09:00的資料到達之後才會觸發
148、使用flink1.7,當消費到某條訊息(protobuf格式),報Caused by: org.apache.kafka.common.KafkaException: Record batch for partition Notify-18 at offset 1803009 is invalid, cause: Record is corrupt 這個異常。 如何設定跳過已損壞的訊息繼續消費下一條來保證業務不終斷? 我看了官網kafka connectors那裡,說在DeserializationSchema.deserialize(...)方法中返回null,flink就會跳過這條訊息,然而依舊報這個異常
149、是否可以抽空總結一篇Flink 的 watermark 的原理案例?一直沒搞明白基於事件時間處理時的資料亂序和資料遲到底咋回事
150、flink中rpc通訊的原理,與幾個類的講解,有沒有系統詳細的文章樣,如有求分享,謝謝
151、Flink中如何使用基於事件時間處理,但是又不使用Watermarks? 我在會話視窗中使用遇到一些問題,圖一是基於處理時間的,測試結果session是基於keyby(使用者)的,圖二是基於事件時間的,不知道是我用法不對還是怎麼的,測試結果發現並不是基於keyby(使用者的),而是全域性的session。不知道怎麼修改?
152、flink實時計算平臺,yarn模式日誌收集怎麼做,為什麼會checkpoint失敗,報警處理,後需要做什麼嗎?job監控怎麼做
153、有flink與jstorm的在不同應用場景下, 效能比較的資料嗎? 從網路上能找大部分都是flink與storm的比較. 在jstorm官網上有一份比較的圖表, 感覺參考意義不大, 應該是比較早的flink版本.
154、為什麼使用SessionWindows.withGap視窗的話,State存不了東西呀,每次加1 ,拿出來都是null, 我換成 TimeWindow就沒問題。
155、請問一下,flink datastream流處理怎麼統計去重指標? 官方文件中只看到批處理有distinct概念。
156、好全的一篇文章,對比分析 Flink,Spark Streaming,Storm 框架
157、關於 structured_streaming 的 paper
158、zookeeper叢集切換領導了,flink叢集專案重啟了就沒有資料的輸入和輸出了,這個該從哪方面入手解決?
159、我想請教下datastream怎麼和靜態資料join呢
160、時鐘問題導致收到了明天的資料,這時候有什麼比較好的處理方法?看到有人設定一個最大的跳躍閾值,如果當前資料時間 - 歷史最大時間 超過閾值就不更新。如何合理的設計水印,有沒有一些經驗呢?
161、大佬們flink怎麼定時查詢資料庫?
162、現在我們公司有個想法,就是提供一個頁面,在頁面上選擇source sink 填寫上sql語句,然後後臺生成一個flink的作業,然後提交到叢集。功能有點類似於華為的資料中臺,就是頁面傻瓜式操作。後臺能自動根據相應配置得到結果。請問拘你的瞭解,可以實現嗎?如何實現?有什麼好的思路。現在我無從下手
163、請教一下 flink on yarn 的 ha機制
164、在一般的流處理以及cep, 都可以對於eventtime設定watermark, 有時可能需要設定相對大一點的值, 這記憶體壓力就比較大, 有沒有辦法不應用jvm中的記憶體, 而用堆外記憶體, 或者其他快取, 最好有cache機制, 這樣可以應對大流量的峰值.
165、請教一個flink sql的問題。我有兩個聚合後的流表A和B,A和Bjoin得到C表。在設定state TTL 的時候是直接對C表設定還是,對A表和B表設定比較好?
166、spark改寫為flink,會不會很複雜,還有這兩者在SQL方面的支援差別大嗎?
167、請問flink allowedLateness導致視窗被多次fire,最終資料重複消費,這種問題怎麼處理,資料是寫到es中
168、設定taskmanager.numberOfTaskSlots: 4的時候沒有問題,但是cpu沒有壓上去,只用了30%左右,於是設定了taskmanager.numberOfTaskSlots: 8,但是就報錯誤找不到其中一個自定義的類,然後kafka資料就不消費了。為什麼?cpu到多少合適?slot是不是和cpu數量一致是最佳配置?kafka分割槽數多少合適,是不是和slot,parallesim一致最佳?
169、需求是根據每條日誌切分出需要9個欄位,有五個指標再根據9個欄位的不同組合去做計算。 第一個方法是:我目前做法是切分的9個欄位開5分鐘大小1分鐘計算一次的滑動視窗視窗,進行一次reduce去重,然後再map取出需要的欄位,然後過濾再開5分鐘大小1分鐘計算一次的滑動視窗視窗進行計算儲存結果,這個思路遇到的問題是上一個滑動視窗會每一分鐘會計算5分鐘資料,到第二個視窗劃定的5分鐘範圍的資料會有好多重複,這個思路會造成資料重複。 第二個方法是:切分的9個欄位開5分鐘大小1分鐘計算一次的滑動視窗視窗,再pross方法裡完成所有的過濾,聚合計算,但是再高峰期每分鐘400萬條資料,這個思路擔心在高峰期flink計算不過來
170、a,b,c三個表,a和c有eventtime,a和c直接join可以,a和b join後再和c join 就會報錯,這是怎麼回事呢
171、自定義的source是這樣的(圖一所示) 使用的時候是這樣的(圖二所示),為什麼無論 sum.print().setParallelism(2)(圖2所示)的並行度設定成幾最後結果都是這樣的
172、剛接觸flink,如有問的不合適的地方,請見諒。 1、為什麼說flink是有狀態的計算? 2、這個狀態是什麼?3、狀態存在哪裡
173、這邊用flink 1.8.1的版本,採用flink on yarn,hadoop版本2.6.0。程式碼是一個簡單的滾動視窗統計函式,但啟動的時候報錯,如下圖片。 (2)然後我把flink版本換成1.7.1,重新提交到2.6.0的yarn平臺,就能正常運行了。 (3)我們測試叢集hadoop版本是3.0,我用flink 1.8.1版本將這個程式再次打包,提交到3.0版本的yarn平臺,也能正常執行。 貌似是flink 1.8.1版本與yarn 2.6.0版本不相容造成的這個問題
174、StateBackend我使用的是MemoryStateBackend, State是怎麼釋放記憶體的,例如我在函式中用ValueState儲存了歷史狀態資訊。但是歷史狀態資料我沒有手動釋放,那麼程式會自動釋放麼?還是一直駐留在記憶體中
175、請問老師是否可以提供一些Apachebeam的學習資料 謝謝
176、flink 的 DataSet或者DataStream支援索引查詢以及刪除嗎,像spark rdd,如果不支援的話,該轉換成什麼
177、關於flink的狀態,能否把它當做資料庫使用,類似於記憶體資料庫,在處理過程中存業務資料。如果是資料庫可以算是分散式資料庫嗎?是不是使用rocksdb這種儲存方式才算是?支援的單庫大小是不是隻是跟本地機器的磁碟大小相關?如果使用硬碟儲存會不會效率效能有影響
178、我這邊做了個http sink,想要批量傳送資料,不過現在只能用數量控制傳送,但最後的幾個記錄沒法觸發傳送動作,想問下有沒有什麼辦法
179、請問下如何做定時去重計數,就是根據時間分視窗,視窗內根據id去重計數得出結果,多謝。試了不少辦法,沒有簡單直接辦法
180、我有個job使用了elastic search sink. 設定了批量5000一寫入,但是看es監控顯示每秒只能插入500條。是不是bulkprocessor的currentrequest為0有關
181、有docker部署flink的資料嗎
182、在說明KeyBy的StreamGraph執行過程時,keyBy的ID為啥是6? 根據前面說,ID是一個靜態變數,每取一次就遞增1,我覺得應該是3啊,是我理解錯了嗎
183、有沒計劃出Execution Graph的遠碼解析
184、可以分享下物理執行圖怎樣劃分task,以及task如何執行,還有他們之間資料如何傳遞這塊程式碼嘛?
185、Flink原始碼和這個學習專案的結構圖
186、請問flink1.8,如何做到動態載入外部udf-jar包呢?
187、同一個Task Manager中不同的Slot是怎麼互動的,比如:source處理完要傳遞給map的時候,如果在不同的Slot中,他們的記憶體是相互隔離,是怎麼互動的呢? 我猜是通過序列化和反序列化物件,並且通過網路來進行互動的
188、你們有沒有這種業務場景。flink從kafka裡面取資料,每一條資料裡面有mongdb表A的id,這時我會在map的時候採用flink的非同步IO連線A表,然後查詢出A表的欄位1,再根據該欄位1又需要非同步IO去B表查詢欄位2,然後又根據欄位2去C表查詢欄位3.....像這樣的業務場景,如果多來幾種邏輯,我應該用什麼方案最好呢
189、今天本地執行flink程式,消費socket中的資料,連續只能消費兩條,第三條flink就消費不了了
190、源資料經過過濾後分成了兩條流,然後再分別提取事件時間和水印,做時間視窗,我測試時一條流沒有資料,另一條的資料看日誌到了視窗操作那邊就沒走下去,貌似視窗一直沒有等到觸發
191、有做flink cep的嗎,有資料沒?
192、麻煩問一下 BucketingSink跨叢集寫,如果任務執行在hadoop A叢集,從kafka讀取資料處理後寫到Hadoo B叢集,即使把core-site.xml和hdfs-site.xml拷貝到程式碼resources下,路徑使用hdfs://hadoopB/xxx,會提示ava.lang.RuntimeException: Error while creating FileSystem when initializing the state of the BucketingSink.,跨叢集寫這個問題 flink不支援嗎?
193、想諮詢下,如何對flink中的datastream和dataset進行資料取樣
194、一個flink作業經常發生oom,可能是什麼原因導致的。 處理流程只有15+欄位的解析,redis資料讀取等操作,TM配置10g。 業務會在夜間刷資料,qps能打到2500左右~
195、我看到flink 1.8的狀態過期僅支援Processing Time,那麼如果我使用的是Event time那麼狀態就不會過期嗎
196、請問我想每隔一小時統計一個屬性從當天零點到當前時間的平均值,這樣的時間窗該如何定義?
197、flink任務裡面反序列化一個類,報ClassNotFoundException,可是包裡面是有這個類的,有遇到這種情況嗎?
198、在構造StreamGraph,類似PartitionTransformmation 這種型別的 transform,為什麼要新增成一個虛擬節點,而不是一個實際的物理節點呢?
199、flink消費kafka的資料寫入到hdfs中,我採用了BucketingSink 這個sink將operator出來的資料寫入到hdfs檔案上,並通過在hive中建外部表來查詢這個。但現在有個問題,處於in-progress的檔案,hive是無法識別出來該檔案中的資料,可我想能在hive中實時查詢進來的資料,且不想產生很多的小檔案,這個該如何處理呢
200、採用Flink單機叢集模式一個jobmanager和兩個taskmanager,機器是單機是24核,現在做個簡單的功能從kafka的一個topic轉滿足條件的訊息到另一個topic,topic的分割槽是30,我設定了程式預設併發為30,現在每秒消費2w多資料,不夠快,請問可以怎麼提高job的效能呢?
201、Flink Metric 原始碼分析
等等等,還有很多,複製貼上的我手累啊