
單頁面(如react,vue)網站的伺服器渲染 SSR 之 SEO 大殺器 Rendertron
單頁面網站,比如vue、recat框架的網站,一般都是直接從伺服器推送index.html,再根據自身路由通過js在客戶端瀏覽器渲染出完整的html頁面。
但是搜尋引擎的爬蟲可沒有這麼智慧(實際上google就有這麼智慧,拿到js檔案自動幫你渲染好,但身在CN,將就下百度這個阿斗吧),為了SEO,要想爬蟲爬到你的網站的內容,就得先由伺服器把頁面渲染好後再發送給爬蟲,這就尷尬了,傳統的伺服器渲染是多頁面的,一個請求對應一個頁面,但SPA不是啊,本來就一個單頁面,你叫我寫各種路由對應渲染好了再給你??當然也不是不可以,以下就是幾種方案:
react自帶的renderToString
react自帶的renderToString 和 renderToStaticMarkup 就可以用來將元件(Virtual DOM)輸出成 HTML 字串,看起來不錯,但是要自己配引數啊,webpack不會怎麼辦,原本路由寫在一起怎麼辦,redux要改動怎麼辦,如果這些你都ok的話,react自帶的方案也是一種不錯的選擇,這裡就不多說了,網上相關帖子很多。
nextjs
還有一種方案,就更尷尬了,叫nextjs框架(nextjs是react的,vue的叫nuxtjs),這種框架寫出來直接就是多頁面的,也就是用react的語法和規則,寫出多頁面網站來,每個頁面的入口名字就是路由名字,伺服器也是nextjs自帶的,短短几行就能把單個網頁渲染好並推送出去,是不是看起來棒棒的?!
那為啥說尷尬呢?就是因為他雖說跟react很像,但還是一個新框架,你不得不花時間學一下nextjs;他的路由對應頁面檔案,這種路由看似簡單明瞭,但是一點都不自由;nextjs是多頁面的,好不容易進化到單頁面,你讓我再回到中世紀?原罪啊!所以如果你已經寫好了一個單頁面網站,要改成nextjs框架的話,我只能說呵呵了,這返工返的……
rendertron
我們的主角要出場了!rendertron的由來我不多說了,當初誕生就是為了做SEO的。先說說原理,聽完你就知道是個好東西了。
Rendertron是nodejs框架下的產物,是google-chrome旗下的的配套產品。首先,伺服器上裝有個google-chrome,rendertron把他開啟,然後在伺服器(官方推薦express)中增加中介軟體,先判斷UA(user-agent)裡面有沒有帶有類似Baiduspider(百度爬蟲)等字樣,如果沒有,就像正常的單頁面伺服器那樣,把原始html推送出去,由客戶端瀏覽器完成js、css渲染的工作;如果帶有指定UA頭字樣,就先把網頁推送給本地伺服器那個google-chrome,等他渲染好對應頁面後,把渲染好的html結果推送出去。不就是為了SEO麼,你爬蟲來了我再渲染給你總行了吧,其餘的我還是做我的單頁面,呵呵噠。
下面上一張圖,說明原理。(原理跟rendora的差不多,下圖的rendora你把他換成rendertron就好了)
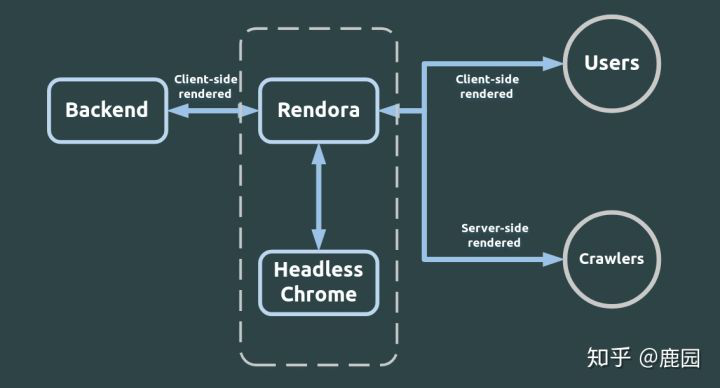
好了,現在講講怎麼用,官網有用法,我給個連結rendertron官網。但是這裡我講一下具體怎麼用的一種無腦方案,你照做就可以了,另外官網demo還有不少的坑和bug,我也挑出來和大家分享一下。
安裝Chromeheadless
先在你的伺服器上安裝Chromeheadless,這是伺服器上的無頭chrome瀏覽器,如果你的伺服器上已經有這個,那恭喜你了,因為安裝過程的坑實在是太多太多了。網上關於安裝Chromeheadless的教學貼很多,在此我貼幾個。
先在你的伺服器上安裝Chromeheadless,這是伺服器上的無頭chrome瀏覽器,如果你的伺服器上已經有這個,那恭喜你了,因為安裝過程的坑實在是太多太多了。網上關於安裝Chromeheadless的教學貼很多,在此我貼幾個:
- 在ubuntu伺服器上使用Chrome Headless
- linux 安裝 Headless Chrome - bambooleaf - CSDN部落格
- Chromeheadless安裝與使用 - 探索技術世界 - CSDN部落格
安裝過程中你會遇到很多坑,不過不要緊,把error複製貼上一下放百度,還是有很多解決方案的,畢竟Chromeheadless不是什麼小眾的東西。
安裝rendertron
直接命令列輸入
npm install -g rendertron
回車,就裝好了。就這麼簡單?呵呵,有greatWall,安裝過程中必需的某個東東下載不了,這時候要用代理,會的同學當然ok,但是不會的同學就沒辦法了,我自己一臺大陸一臺海外,大陸的裝不了就改海外伺服器了。
還有一個方案,也是官方給出的:
git clone https://github.com/GoogleChrome/rendertron.git
cd rendertron
npm install
npm run build
執行:
npm run start
能用第一種安裝方案的推薦用第一種。
在你的express伺服器程式中引入中介軟體rendertron-middleware
進入專案目錄,命令列輸入並回車
npm install --save express rendertron-middleware
在你的express伺服器程式的程式碼中加入幾行:
const express = require('express');const rendertron = require('rendertron-middleware');
const app = express();
app.use(rendertron.makeMiddleware({
proxyUrl: 'http://localhost:3000/render',}));
app.use(express.static('files'));app.listen(8080);
重點是插入的
app.use(rendertron.makeMiddleware({
proxyUrl: 'http://localhost:3000/render',}));
其中rendertron.makeMiddleware有好幾個引數,github上說有proxyUrl、userAgentPattern、excludeUrlPattern、injectShadyDom、timeout,也就是有類似以下的設定。
app.use(rendertron.makeMiddleware({
proxyUrl: 'http://localhost:3000/render',
userAgentPattern:****,
excludeUrlPattern:****,
injectShadyDom:true or false, //這個引數一般不用設,用的時候這行刪掉就好了 timeout:11000,//這個timeout超時引數親測已經無效了,尷尬,用的時候也去掉這行就好}));
下面重點講講以上的userAgentPattern和excludeUrlPattern引數的含義和怎麼設定。
userAgentPattern是用來寫清楚哪些UA頭需要伺服器渲染,除此之外的請求都直接單頁面推送。比如說:
const botUserAgents = [
'Baiduspider',
'bingbot',
'Embedly',
'facebookexternalhit',
'LinkedInBot',
'outbrain',
'pinterest',
'quora link preview',
'rogerbot',
'showyoubot',
'Slackbot',
'TelegramBot',
'Twitterbot',
'vkShare',
'W3C_Validator',
'WhatsApp',];//略n行程式碼app.use(rendertron.makeMiddleware({
//其他引數 userAgentPattern: new RegExp(botUserAgents.join('|'), 'i'),}));
把你要的爬蟲UA頭都寫到一個數組裡,然後用new RegExp()正則一下
excludeUrlPattern是指哪些檔案格式需要在chromeheadless中被完全載入,用法如下
const staticFileExtensions = [
'ai', 'avi', 'css', 'dat', 'dmg', 'doc', 'doc', 'exe', 'flv',
'gif', 'ico', 'iso', 'jpeg', 'jpg', 'js', 'less', 'm4a', 'm4v',
'mov', 'mp3', 'mp4', 'mpeg', 'mpg', 'pdf', 'png', 'ppt', 'psd',
'rar', 'rss', 'svg', 'swf', 'tif', 'torrent', 'ttf', 'txt', 'wav',
'wmv', 'woff', 'xls', 'xml', 'zip',];//略n行程式碼app.use(rendertron.makeMiddleware({
//其他引數 userAgentPattern: new RegExp(\\.(${staticFileExtensions.join('|')})$, 'i'),}));
把你需要載入的檔案字尾都寫到一個數組裡,然後用new RegExp()正則一下
至於proxyUrl引數的用法,如果rendertron+chromeheadless在本地伺服器,那就寫'http://localhost:3000/render'(rendertron啟動後預設開啟3000埠),如果是在別的伺服器,那就寫http://www.xxxx.com/render或者http://106.xx.xx.xxx:xxxx/render。
proxyUrl引數設定的就是遇到爬蟲UA頭後、轉到rendertron用本地伺服器上的chromeheadless瀏覽器渲染的地址。
好了,express伺服器改寫好後,正常啟動他,然後再啟動rendertron,方法也很簡單,直接命令列輸入rendertron就行了。
下面測試一下,命令列輸入curl -A “baiduspider” http://你需要測試的網址(就是訪問你的server程式對應的那個網址,即改寫前的那個原來的網址),然後就能看到通過chromeheadless渲染好的html程式碼,大功告成!
rendertron的改進
有沒有發現你每次curl以後都需要10s左右後才能返回資料,這種響應時間怎麼可能用在SEO上呢??!!所以要改進一下咯。
在rendertron的github上有寫到,可以在rendertron的根目錄寫一個config.json,裡面可以設定datastoreCache(是否適用快取,預設false),timeout(渲染超時,過了這個時間還沒有渲染結束就硬性返回已渲染好的html,預設10000ms,即10s),port(埠,預設3000),width和height(渲染用的瀏覽器螢幕寬高,預設1000,這個在rendertron的另一個功能‘截圖’上可以用到)。
然後你很天真的設定了config.json檔案,把timeout改成3000ms——這差不多已經是搜尋引擎認為你是優質網站所要求的響應時間的上限了。再一次curl,什麼!!還是10s!!這個怎麼搞哦!!
又一次大寫的尷尬!下面來公佈答案吧~rendertron的碼源裡面已經沒有引用config.json裡面的timeout引數了,這個引數沒法通過外部設定,呵呵噠,坑。
好了,下面說解決方法。找到rendertron根目錄,裡面有個build資料夾,裡面有個renderer.js檔案,開啟後,搜尋timeout,一共有兩處,後面都跟了10000這個值,把它改成你需要的2000或者之類的(單位ms),然後再次重新啟動rendertron,在命令列輸入
curl -A “baiduspider” http://你需要測試的網址(就是訪問你的server程式對應的那個網址,即改寫前的那個原來的網址)
可以發現只需要2s就有html程式碼返回了,搞定!
注:以上問題是針對npm install -g rendertron方式安裝的rendertron,其他方式安裝後是否有以上問題不一定。
如果你的渲染程式會崩,那就pm2 start rendertron。pm2真的挺好用,不熟悉的同學百度下就好了,滿滿的資料