
SOFAJRaft-RheaKV MULTI-RAFT-GROUP 實現分析 | SOFAJRaft 實現原理
SOFAStack Scalable Open Financial Architecture Stack 是螞蟻金服自主研發的金融級分散式架構,包含了構建金融級雲原生架構所需的各個元件,是在金融場景裡錘鍊出來的最佳實踐。

SOFAJRaft 是一個基於 Raft 一致性演算法的生產級高效能 Java 實現,支援 MULTI-RAFT-GROUP,適用於高負載低延遲的場景。
本文為《剖析 | SOFAJRaft 實現原理》第五篇,本篇作者袖釦,來自螞蟻金服。
《剖析 | SOFAJRaft 實現原理》系列由 SOFA 團隊和原始碼愛好者們出品,專案代號:<SOFA:JRaftLab/>
SOFAJRaft :https://gitee.com/sofastack/sofa-jraft
前言
RheaKV 是首個以 JRaft 為基礎實現的一個原生支援分散式的嵌入式鍵值(key、value)資料庫,現在本文將從 RheaKV 是如何利用 MULTI-RAFT-GROUP 的方式實現 RheaKV 的高效能及容量的可擴充套件性的,從而進行全面的原始碼、例項剖析。
MULTI-RAFT-GROUP
通過對 Raft 協議的描述我們知道:使用者在對一組 Raft 系統進行更新操作時必須先經過 Leader,再由 Leader 同步給大多數 Follower。而在實際運用中,一組 Raft 的 Leader 往往存在單點的流量瓶頸,流量高便無法承載,同時每個節點都是全量資料,所以會受到節點的儲存限制而導致容量瓶頸,無法擴充套件。
MULTI-RAFT-GROUP 正是通過把整個資料從橫向做切分,分為多個 Region 來解決磁碟瓶頸,然後每個 Region 都對應有獨立的 Leader 和一個或多個 Follower 的 Raft 組進行橫向擴充套件,此時系統便有多個寫入的節點,從而分擔寫入壓力,圖如下:
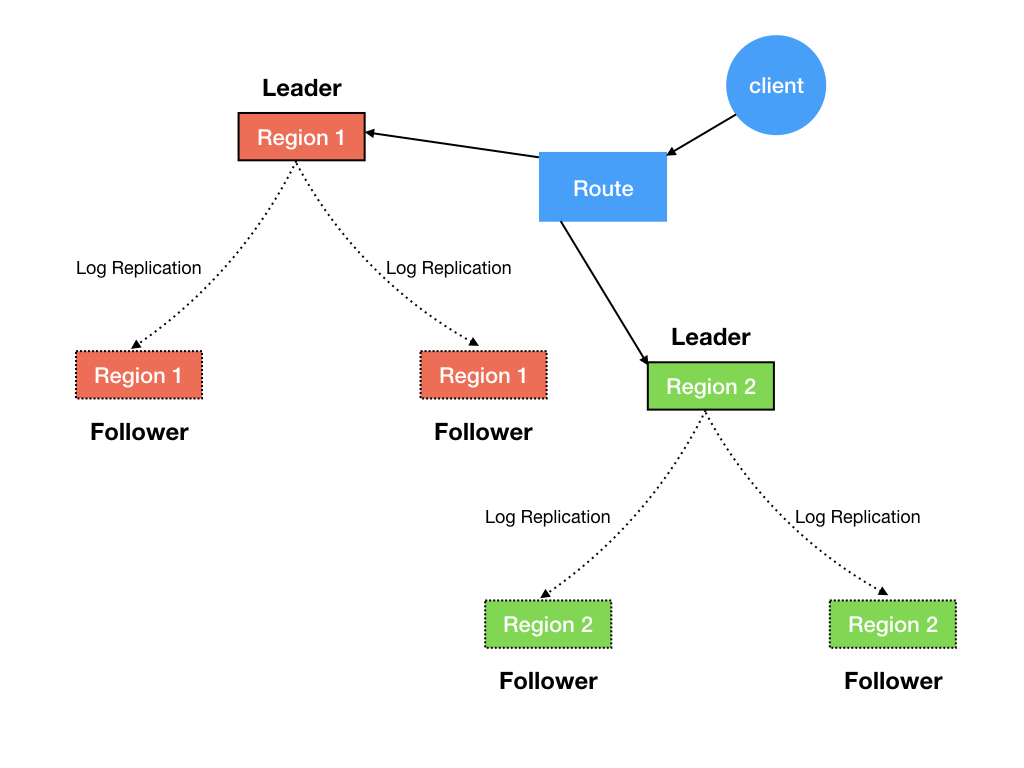
此時磁碟及 I/O 瓶頸解決了,那多個 Raft Group 是如何協作的呢,我們接著往下看。
選舉及複製
RheaKV 主要由 3 個角色組成:PlacementDriver(以下成為 PD) 、Store、Region。由於 RheaKV 支援多組 Raft,所以比單組場景多出一個 PD 角色,用來排程以及收集每個 Store 及 Region 的基礎資訊。
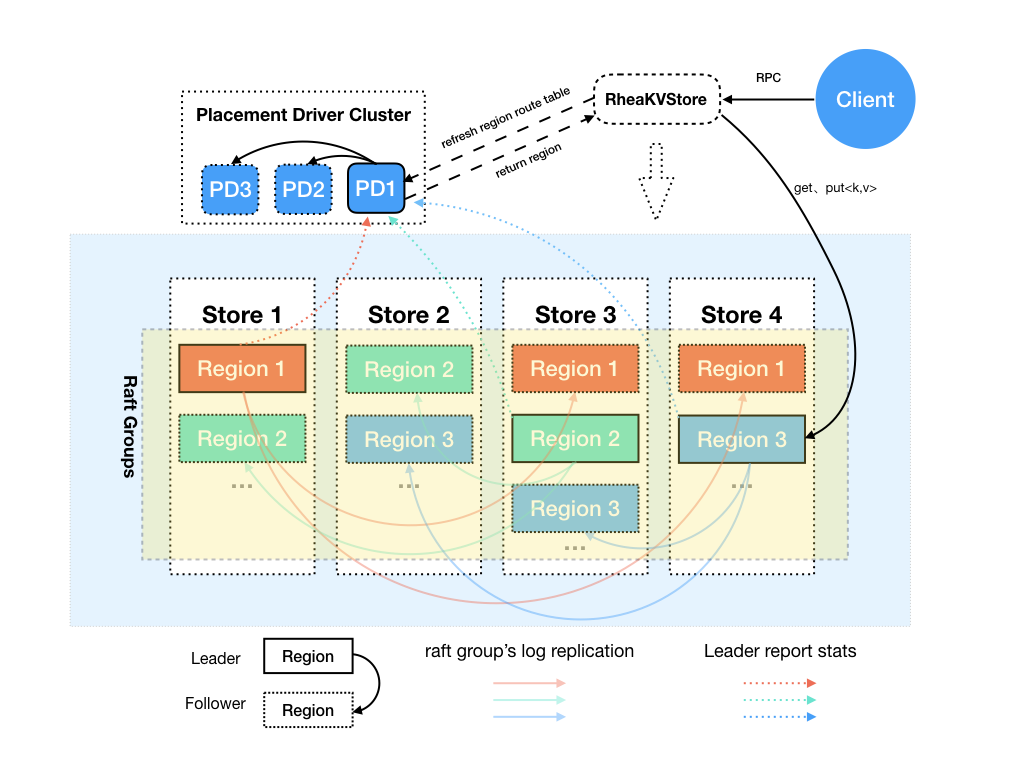
PlacementDriver
PD 負責整個叢集的管理排程、Region ID 生成等。此元件非必須的,如果不使用 PD,設定 PlacementDriverOptions 的 fake 屬性為 true 即可。PD 一般通過 Region 的心跳返回資訊進行對 Region 排程,Region 處理完後,PD 則會在下一個心跳返回中收到 Region 的變更資訊來更新路由及狀態表。
Store
通常一個 Node 負責一個 Store,Store 可以被看作是 Region 的容器,裡面儲存著多個分片資料。Store 會向 PD 主動上報 StoreHeartbeatRequest 心跳,心跳交由 PD 的 handleStoreHeartbeat 處理,裡面包含該 Store 的基本資訊,比如,包含多少 Region,有哪些 Region 的 Leader 在該 Store 等。
Region
Region 是資料儲存、搬遷的最小單元,對應的是 Store 裡某個實際的資料區間。每個 Region 會有多個副本,每個副本儲存在不同的 Store,一起組成一個Raft Group。Region 中的 Leader 會向 PD 主動上報 RegionHeartbeatRequest 心跳,交由 PD 的 handleRegionHeartbeat 處理,而 PD 是通過 Region 的 Epoch 感知 Region 是否有變化。
RegionRouteTable 路由表元件
Muti-Raft-Group 的多 Region 是通過 RegionRouteTable 路由表元件進行管理的,可通過 addOrUpdateRegion、removeRegion 進行新增、更新、移除 Region,也包括 Region 的拆分。目前暫時還未實現 Region 的聚合,後面會考慮實現。
分割槽邏輯與演算法 Shard
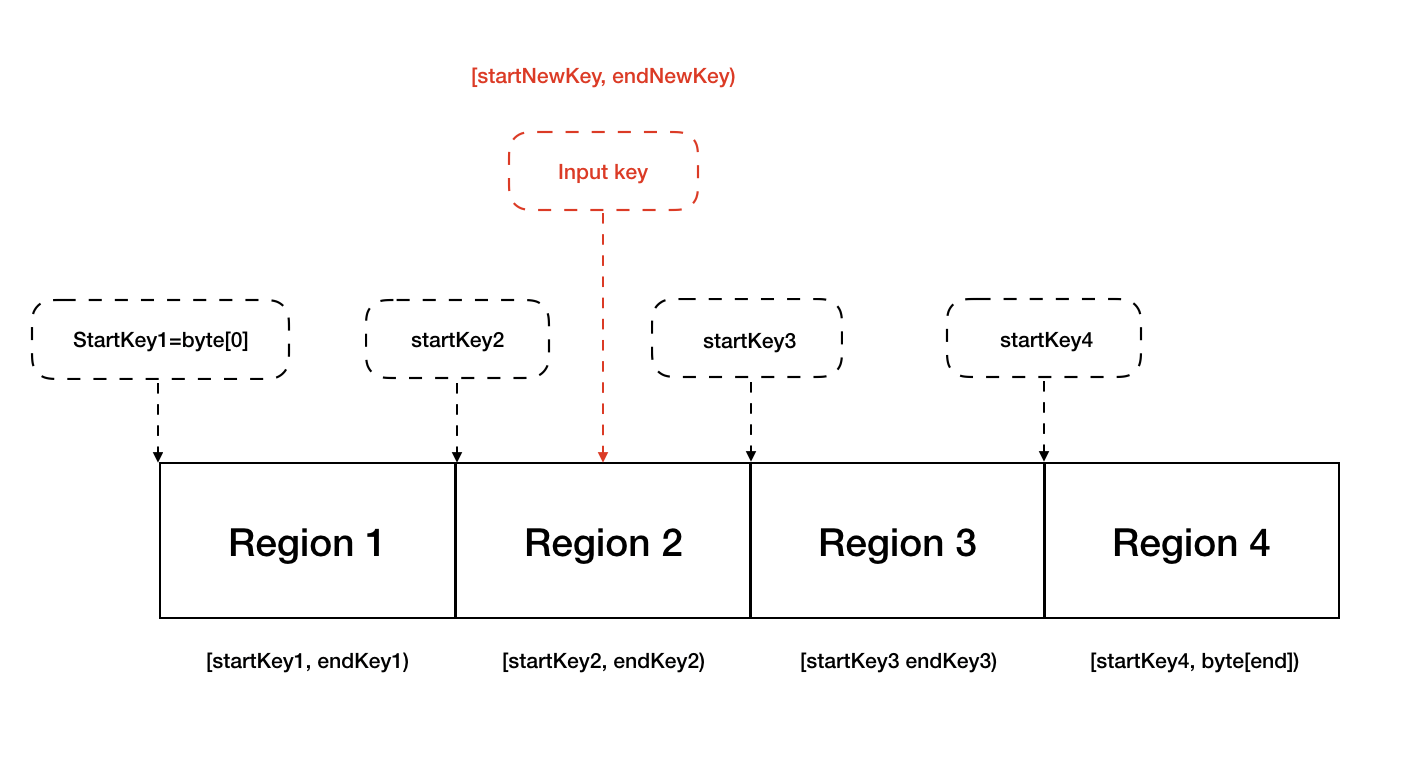
“讓每組 Raft 負責一部分資料。”
資料分割槽或者分片演算法通常就是 Range 和 Hash,RheaKV 是通過 Range 進行資料分片的,分成一個個 Raft Group,也稱為 Region。這裡為何要設計成 Range 呢?原因是 Range 切分是按照對 Key 進行位元組排序後再做每段每段切分,像類似 scan 等操作對相近 key 的查詢會盡可能集中在某個 Region,這個是 Hash 無法支援的,就算遇到單個 Region 的拆分也會更好處理一些,只用修改部分元資料,不會涉及到大範圍的資料挪動。
當然 Range 也會有一個問題那就是,可能會存在某個 Region 被頻繁操作成為熱點 Region。不過也有一些優化方案,比如 PD 排程熱點 Region 到更空閒的機器上,或者提供 Follower 分擔讀的壓力等。
Region 和 RegionEpoch 結構如下:
class Region {
long id; // region id
// Region key range [startKey, endKey)
byte[] startKey; // inclusive
byte[] endKey; // exclusive
RegionEpoch regionEpoch; // region term
List<Peer> peers; // all peers in the region
}
class RegionEpoch {
// Conf change version, auto increment when add or remove peer
long confVer;
// Region version, auto increment when split or merge
long version;
}
class Peer {
long id;
long storeId;
Endpoint endpoint;
}
Region.id:為 Region 的唯一標識,通過 PD 全域性唯一分配。
Region.startKey、Region.endKey:這個表示的是 Region 的 key 的區間範圍 [startKey, endKey),特別值得注意的是針對最開始 Region 的 startKey,和最後 Region 的 endKey 都為空。
Region.regionEpoch:當 Region 新增和刪除 Peer,或者 split 等,此時 regionEpoch 就會發生變化,其中 confVer 會在配置修改後遞增,version 則是每次有 split 、merge(還未實現)等操作時遞增。
Region.peers:peers 則指的是當前 Region 所包含的節點資訊,Peer.id 也是由 PD 全域性分配的,Peer.storeId 代表的是 Peer 當前所處的 Store。
讀與寫 Read / Write
由於資料被拆分到不同 Region 上,所以在進行多 key 的讀、寫、更新操作時需要操作多個 Region,這時操作前我們需要得到具體的 Region,然後再單獨對不同 Region 進行操作。我們以在多 Region上 scan 操作為例, 目標是返回某個 key 區間的所有資料:
- 我們首先看 scan 方法的核心呼叫方法 internalScan 的非同步實現:
例如:com.alipay.sofa.jraft.rhea.client.DefaultRheaKVStore#scan(byte[], byte[], boolean, boolean)
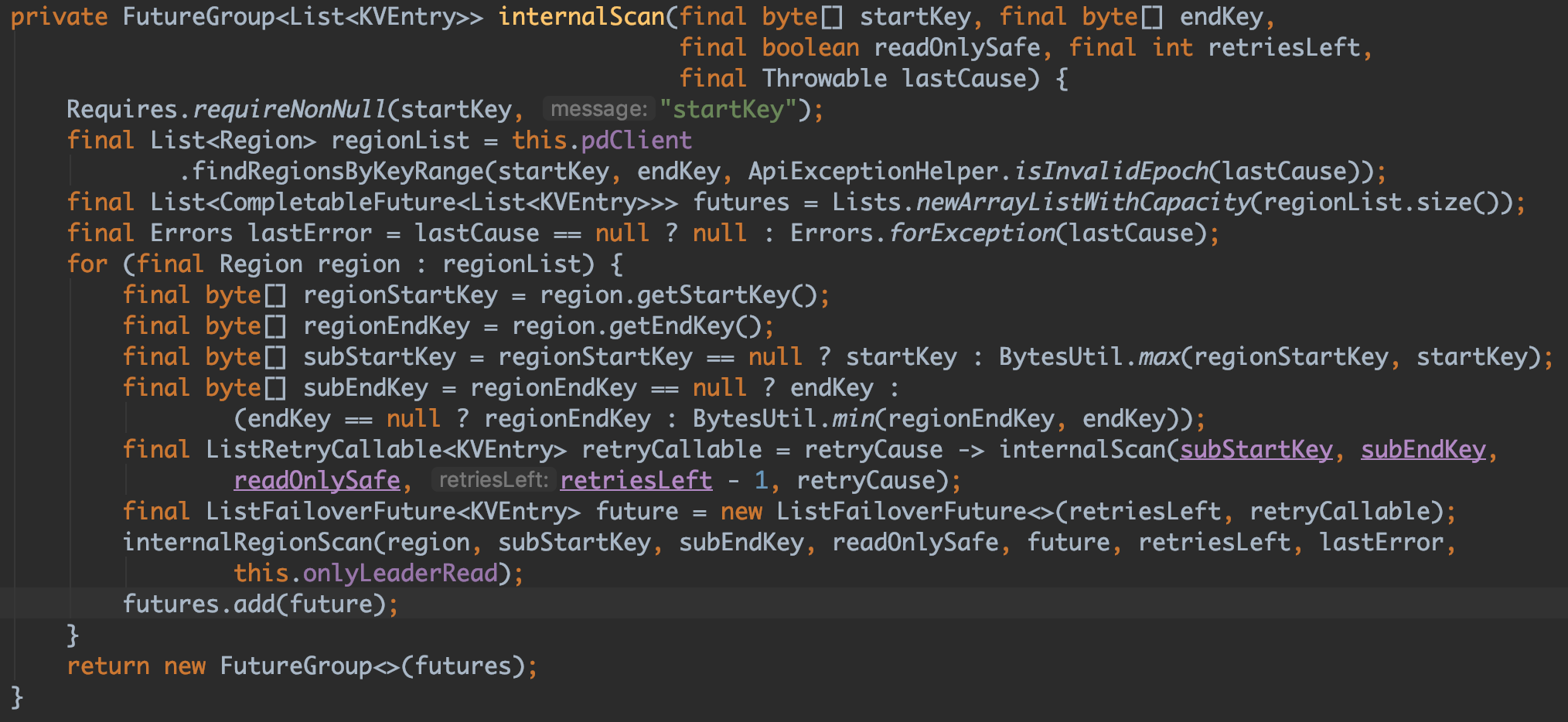
我們很容易看到,在呼叫 scan 首先讓 PD Client 通過 RegionRouteTable.findRegionsByKeyRange 檢索 startKey、endKey 所覆蓋的 Region,最後返回的可能為多個 Region,具體 Region 覆蓋檢索方法如下:
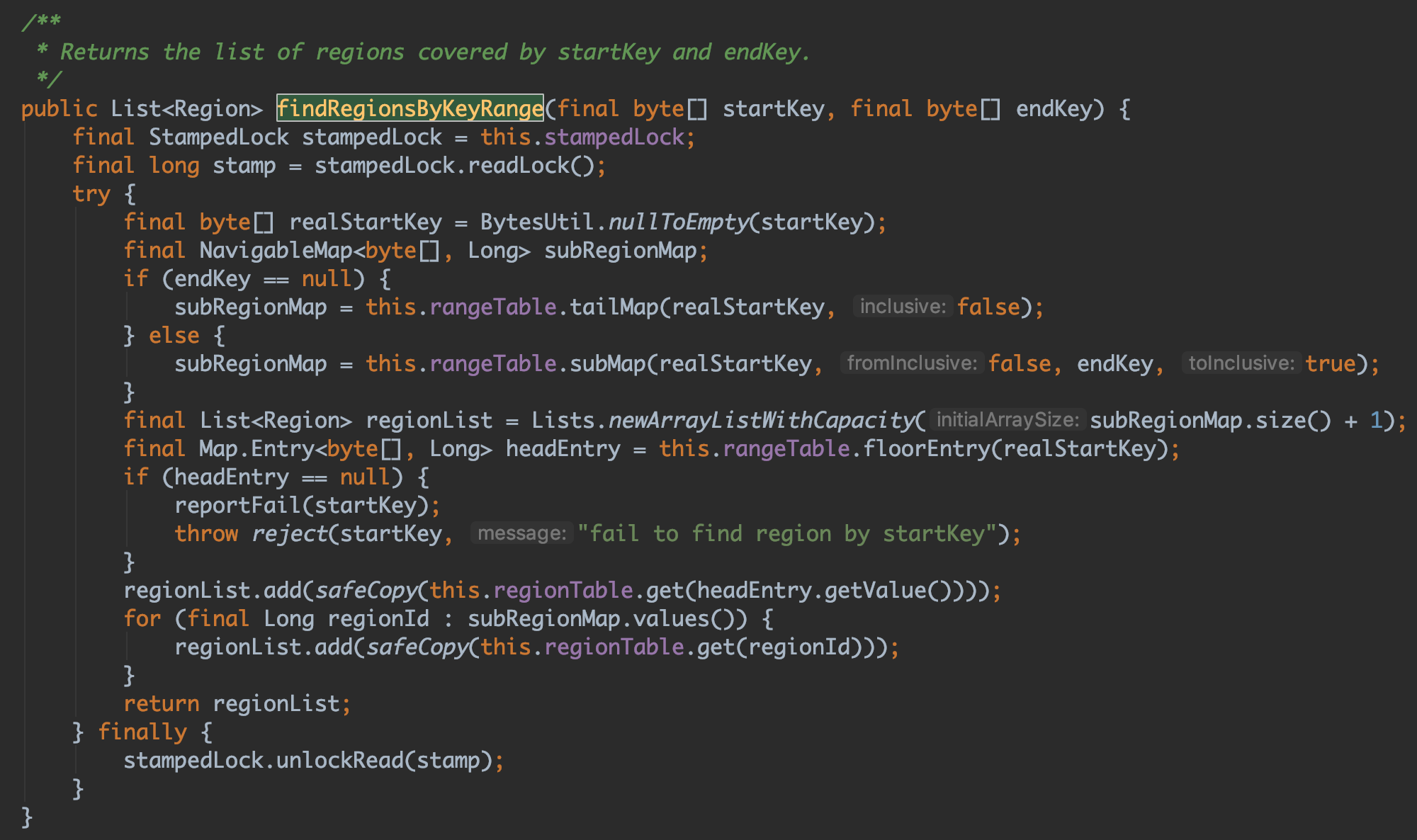
檢索相關變數定義如下:

我們可以看到整個 RheaKV 的 range 路由表是通過 TreeMap 的進行儲存的,正呼應我們前面講過所有的 key 是通過對應位元組進行排序儲存。對應的 Value 為該 Region 的 RegionId,隨後我們通過 Region 路由 regionTable 查出即可。
現在我們得到 scan 覆蓋到的所有 Region:List<Region> 在迴圈查詢中我們看到有一個“retryCause -> {}”的 Lambda 表示式很容易看出這裡是加持異常重試處理,後面我們會講到,接下來會通過 internalRegionScan 查詢每個 Region 的結果。具體原始碼如下:
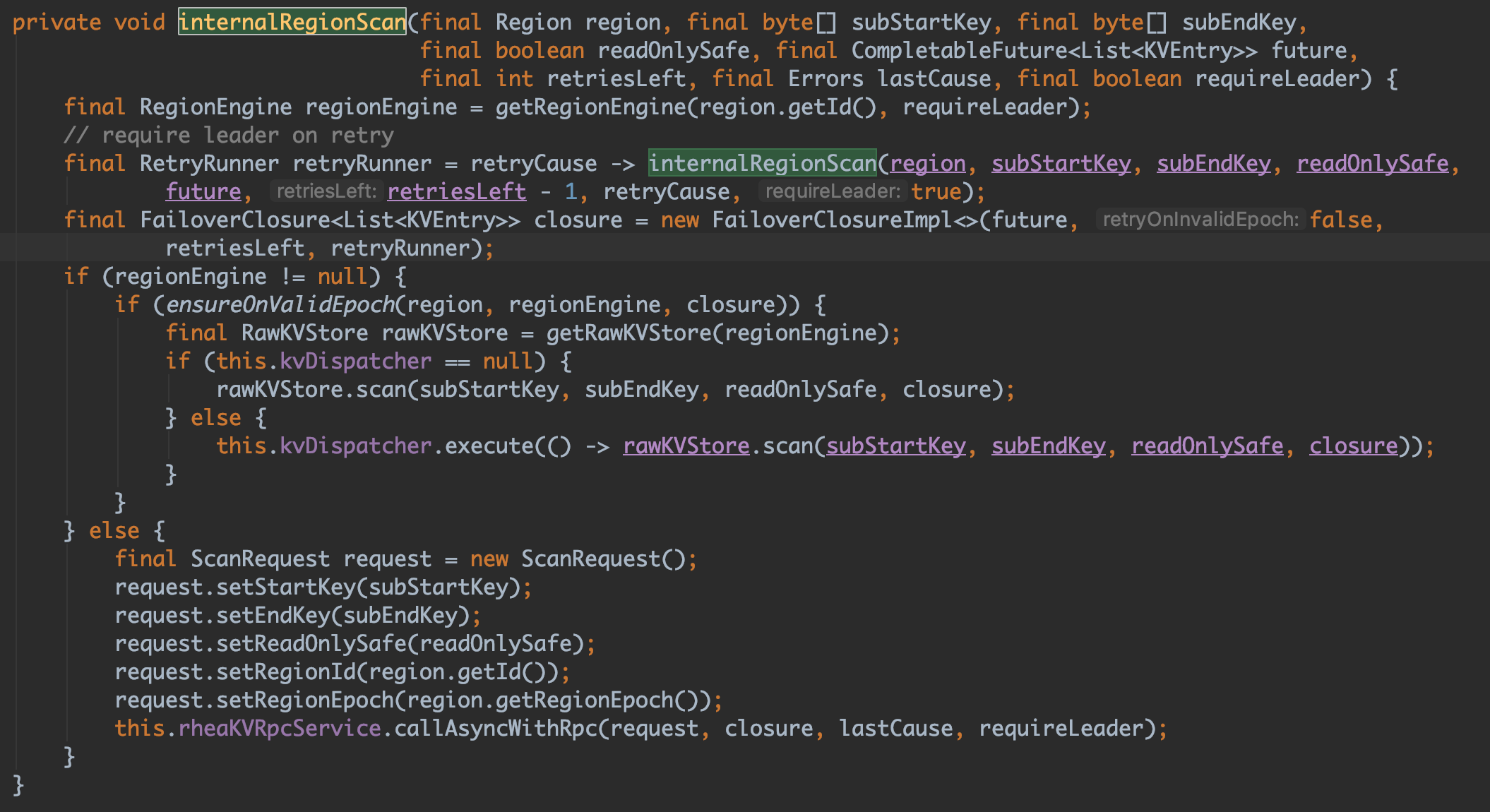
這裡也同樣有一個重試處理,可以看到程式碼中根據當前是否為 Region 節點來決定是本機查詢還是通過RPC進行查詢,如果是本機則呼叫 rawKVStore.scan() 進行本地直接查詢,反之通過 rheaKVRpcService 進行 RPC 遠端節點查詢。最後每個 Region 查詢都返回為一個 future,通過 FutureHelper.joinList 工具類 CompletableFuture.allOf 非同步併發返回結果 List<KVEntry>。
- 我們再看看寫入具體流程。相比 scan 讀,put 寫相對比較簡單,只需要針對 key 計算出對應 Region 再進行儲存即可,我們可以看一個非同步 put 的例子。
例如:com.alipay.sofa.jraft.rhea.client.DefaultRheaKVStore#put(java.lang.String, byte[])
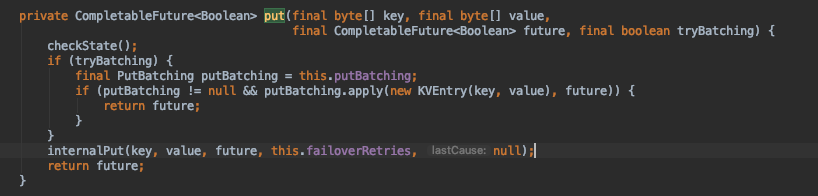
我們可以發現 put 基礎方法是支援 batch 的,即可成批提交。如未使用 batch 即直接提交,具體邏輯如下:
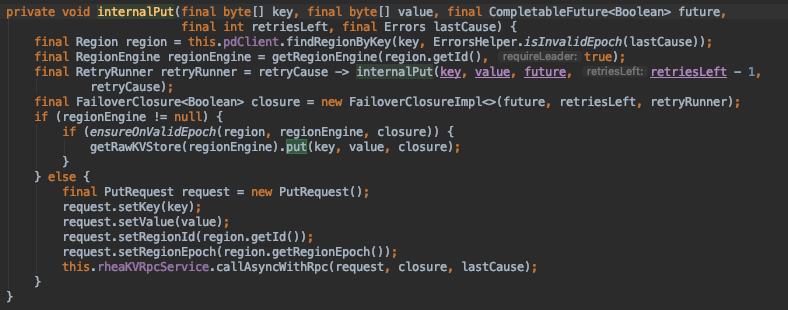
通過 pdClinet 查詢對應儲存的 Region,並且通過 regionId 拿到 RegionEngine,再通過對應儲存引擎 KVStore 進行 put,整個過程同樣支援重試機制。我們再回過去看看 batch 的實現,很容易發現利用到了 Disruptor 的 RingBuffer 環形緩衝區,無鎖佇列為效能提供了保障,程式碼現場如下:
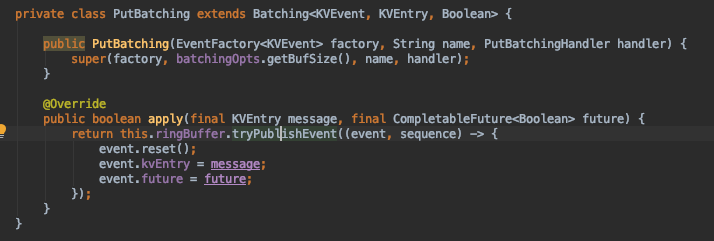
Split / Merge
- 什麼時候 Region 會拆分?
前面我們有講過,PD 會在 Region 的 heartBeat 裡面對 Region 進行排程,當某個 Region 裡的 keys 數量超過預設閥值,我們即可對該 Region 進行拆分,Store 的狀態機 KVStoreStateMachine 即收到拆分訊息進行拆分處理。具體拆分原始碼如下:
KVStoreStateMachine.doSplit 原始碼如下:
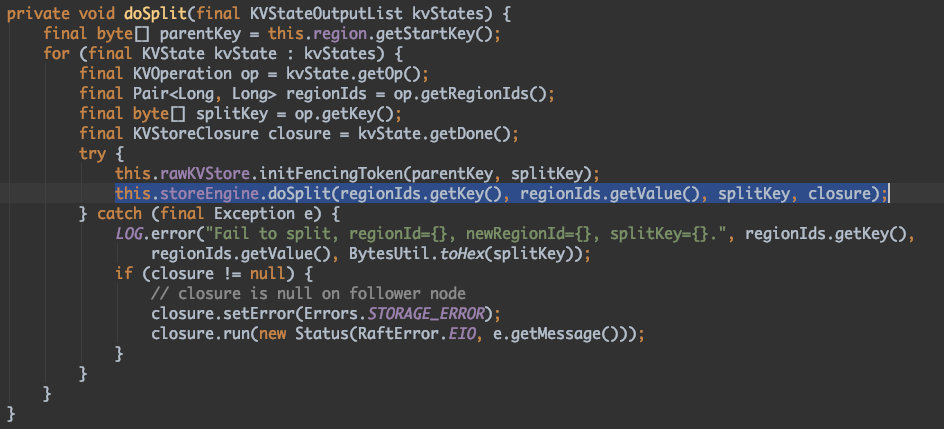
StoreEngine.doSplit 原始碼如下:
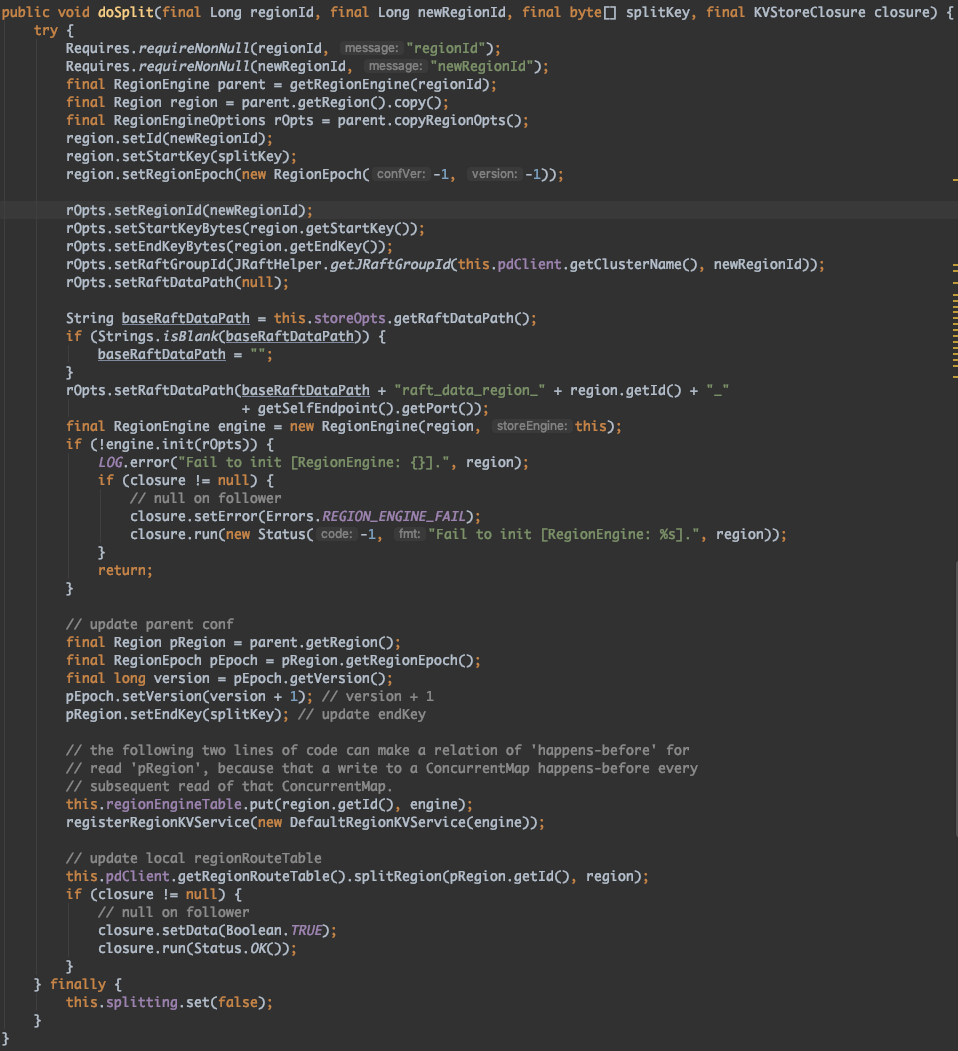
我們可以輕易的看到從原始 parentRegion 切分成 region 和 pRegion,並重設了 startKey、endKey 和版本號,並新增到 RegionEngineTable 註冊到 RegionKVService,同時呼叫 pdClient.getRegionRouteTable().splitRegion() 方法進行更新儲存在 PD 的 Region 路由表。
- 什麼時候需要對 Region 進行合併?
既然資料過多需要進行拆分,那 Region 進行合併那就肯定是 2 個或者多個連續的 Region 資料量明顯小於絕大多數 Region 容量則我們可以對其進行合併。這一塊後面會考慮實現。
RegionKVService 結構及實現分析
StoreEngine
通過上面我們知道,一個 Store 即為一個節點,裡面包含著一個或者多個 RegionEngine,一個 StoreEngine 通常通過 PlacementDriverClient 對 PD 進行呼叫,同時擁有 StoreEngineOptions 配置項,裡面配置著儲存引擎和節點相關配置。
- 我們以預設的 DefaultRheaKVStore 載入 StoreEngine 為例,DefaultRheaKVStore 實現了 RheaKVStore 介面的基礎功能,從最開始 init 方法,根據 RheaKVStoreOptions 載入了 pdClinet 例項,隨後載入 storeEngine。
- 在 StoreEngine 啟動的時候,首先會去載入對應的 StoreEngineOptions 配置,構建對應的 Store 配置,並且生成一致性讀的執行緒池 readIndexExecutor、快照執行緒池 snapshotExecutor、RPC 的執行緒池 cliRpcExecutor、Raft 的 RPC 執行緒池 raftRpcExecutor,以及儲存 RPC 執行緒池 kvRpcExecutor、心跳傳送器 HeartbeatSender 等,如果開啟程式碼,我們還能看到 metricsReportPeriod,開啟配置可以進行效能指標監控。
- 在 DefaultRheaKVStore 載入完所有工序之後,便可使用 get、set、scan 等操作,還包含對應同步、非同步操作。
在這個過程中裡面的 StoreEngine 會記錄著 regionKVServiceTable、regionEngineTable,它們分別掌握著具體每個不同的 Region 儲存的操作功能,對應的 key 即為 RegionId。
RegionEngine
每個在 Store 裡的 Region 副本中,RegionEngine 則是一個執行單元。它裡面記錄著關聯著的 StoreEngine 資訊以及對應的 Region 資訊。由於它也是一個選舉節點,所以也包含著對應狀態機 KVStoreStateMachine,以及對應的 RaftGroupService,並啟動裡面的 RpcServer 進行選舉同步。
這個裡面有個transferLeadershipTo方法,這個可被呼叫用於平衡當前節點分割槽的Leader,避免壓力重疊。
DefaultRegionKVService 是 RegionKVService 的預設實現類,主要處理對 Region 的具體操作。
RheaKV FailoverClosure 解讀
需要特別講到的是,在具體的 RheaKV 操作時,FailoverClosure 擔任著比較重要的角色,也給整個系統增加了一定的容錯性。假如在一次 scan 操作中,如果跨 Store 需要多節點 scan 資料的時候,任何網路抖動都會造成資料不完整或者失敗情況,所以允許一定次數的重試有利於提高系統的可用性,但是重試次數不宜過高,如果出現網路堵塞,多次 timeout 級別失敗會給系統帶來額外的壓力。這裡只需要在 DefaultRheaKVStore 中,進行配置 failoverRetries 設定次數即可。
RheaKV PD 之 PlacementDriverClient
PlacementDriverClient 介面主要由 AbstractPlacementDriverClient 實現,然後 FakePlacementDriverClient、RemotePlacementDriverClient 為主要功能。FakePlacementDriverClient 是當系統不需要 PD 的時候進行 PD 物件的模擬,這裡主要講到 RemotePlacementDriverClient。
- RemotePlacementDriverClient 通過PlacementDriverOptions 進行載入,並根據基礎配置重新整理路由表;
- RemotePlacementDriverClient 承擔著對路由表RegionRouteTable 的管控,例如獲取Store、路由、Leader節點資訊等;
- RemotePlacementDriverClient 還包含著 CliService,通過 CliService 外部可對複製節點進行操作運維,如addReplica、removeReplica、transferLeader。
總結
由於很多傳統儲存中介軟體並不原生支援分散式,所以一直少有體感,Raft 協議是一套比較比較好理解的共識協議,SOFAJRaft 通俗易懂是一個非常好的程式碼和工程範例,同時 RheaKV 也是一套非常輕量化支援多儲存結構可分片的嵌入式資料庫。寫一篇程式碼分析文章也是一個學習和進步的過程,由此我們也可以窺探到了一些資料庫的基礎實現,祝願社群能在 SOFAJRaft / RheaKV 基礎上構建更加靈活和自治理的系統和應用。