
大白話5分鐘帶你走進人工智慧-第32節整合學習之最通俗理解XGBoost原理和過程
目錄
1、回顧:
1.1 有監督學習中的相關概念
1.2 迴歸樹概念
1.3 樹的優點
2、怎麼訓練模型:
2.1 案例引入
2.2 XGBoost目標函式求解
3、XGBoost中正則項的顯式表達
4、如何生長一棵新的樹?
5、xgboost相比原始GBDT的優化:
6、程式碼引數:
1、回顧:
我們先回顧下有監督學習中的一些核心概念:
1.1 有監督學習中的相關概念
我們模型關注的就是如何在給定xi的情況下獲得ŷi。線上性模型裡面,我們認為
i是x的橫座標,j是x的列座標,本質上linear/logistic regression中的yi^都等於這個,只不過在logistic regression裡面,分了兩步,第一步ŷi=∑j wj xij,此時ŷi含義是一個得分,第二步你把這得分再扔到Sigmoid函式裡面,才會得到概率。所以預測分值的ŷi在不同的任務中會有不同的解釋。對於線性迴歸(linear regression)來說,ŷi就是最終預測的結果。對於邏輯迴歸(logistic regression)來講,把ŷi丟到Sigmoid函式裡面去,是預測的概率。在其它的一些模型裡面,ŷi還有其它的作用。而線上性模型裡面的引數就是一組w,叫做θ。即
對於引數型模型,要優化的目標函式有兩項組成,一項是Loss,一項是Regularization。表達公式即
常見的損失函式Loss如:平方誤差損失函式(square loss),表示為:
交叉熵損失函式(Logistic loss),表示為
正則項Ωθ是用來衡量模型簡單程度的,有L1正則,即
有L2正則即L2範數的平方,乘一個λ。即
λ是我們要調節的超引數,用來衡量Obj函式到底是更在乎簡單程度,還是更在乎在訓練集上的經驗損失。所謂經驗損失就是你在訓練集上錯了多少就叫經驗損失。對於不同的loss和不同的Regularization這兩項加合起來,讓這兩項的和最小,就達到了一個兼顧的目的,所以它們倆都要相對比較小,才是最好的模型效果。如果說為了達到使L(θ)讓它下降一點點,而Ωθ上升好多,就代表著過擬合。模型複雜度上升了好多才帶來了一點點提升,這種事情並不是我們想要的。我們希望一個簡單的模型,能給我一個最好的答案;如果做不到這倆的話,也希望一個相對簡單的模型給我一個相對比較好的結果就行了。加法在這裡面達到了兼顧的目的。
對於不同的loss和不同的Regularization組合,再對它進行最優化,就構成了我們所謂的不同的演算法。
比如對於mse損失函式組合一個L2正則就是嶺迴歸,表達為:
對於mse損失函式組合一個L1正則就是lasso迴歸,表達為:
對於Logistic loss交叉熵損失函式組合一個L2正則就叫做邏輯迴歸,表達為:
所以邏輯迴歸的損失函式裡必定會帶這λw^2這項,沒有這項就不能叫做邏輯迴歸。
1.2 迴歸樹概念
在來回顧下回歸樹的相關概念,對於迴歸樹(CART樹Classification and Regression Trees)來講,它的決策的分裂條件和決策樹是一樣的,也是多次嘗試分裂,哪次結果最好就留下來。最後它會得到一個葉子節點,也能表達是一個連續的值,我們在此稱之為score分數,對於迴歸樹我們得到的是一組分數。比如下面例子:
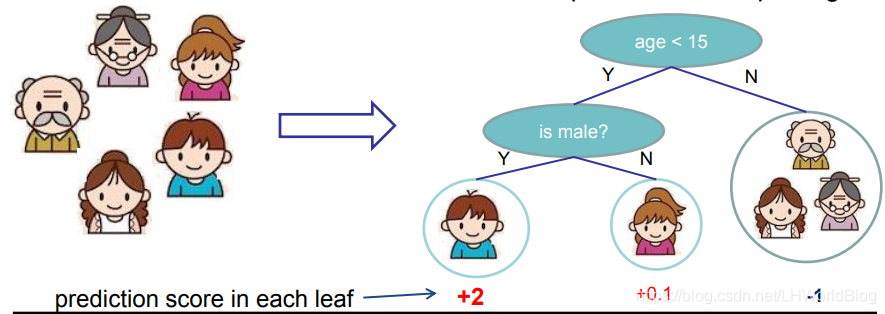
我們要判斷這個人是否喜歡電腦遊戲,通過一個迴歸樹來訓練,年齡小於15的點被分到左邊,是否是男的分到左邊。所以小男孩最終落到了左邊葉子節點,小女孩通過分裂落在了右邊葉子節點,而另外三位落到了右邊葉子節點。最終通過某種方法,先不用考慮是什麼方法,它通過y平均得到了小男孩得分是+2,小女孩+0.1,而另外三位對於計算機遊戲的喜好程度是-1,這是一個迴歸樹的形式。
1.3 樹的優點
樹有這麼一個優勢,就是inputs對於輸入數量的大小,不太在意。做分類,原來最強的霸主是SVM,但它有一個問題就時間複雜度是O(n3)。所以它在小資料集上表現得非常好,程式碼也跑得起來,但一旦到海量資料集上,它就會變得不可接受。如果一千條資料用十分鐘,10萬條資料可能就以年來記了。三次方實在太可怕了,這是它最慢的情況,當然它內部也做了一些優化,不是所有情況都會達到O(n3)。但是樹的訓練基本就是O(n)或者O(n*m),它需要遍歷所有的維度,它比O(n3)要scaling了好多,scaling在機器學習領域特指的是小資料量上表現的好不好,在小資料量上能跑的,在大資料量上還跑得起來的這個方面的效能。 這是一個非常重要的特性。樹模型最不怕的就是這個東西,它表現的時間複雜度比較穩定。另外它對於資料集的是否歸一化,不需要太過在意,引數型模型裡y是通過x計算出來的,它們之間有一個等式關係,而對於樹一系列的模型來講,x和y實際上是被割裂開的。x值只用來分裂,跟y值最後的結果沒有直接的計算關係,它有間接的關係。y的計算結果是通過落在葉子節點上的其它的y算出來的,而不是通過x算出來。
這裡先給大家鋪墊下,在xgboost中,第一,它雖然用的是CART樹,但它葉子節點的表達,不再像以前使用y平均了,但是它仍然是一顆迴歸樹,不再是計算純度的分類樹。第二,它判斷分裂條件的標準也不再是方差了,而是看損失函式下降的高低。所以它雖然形式上是一顆迴歸樹,但無論分裂條件的判斷,還有葉子節點的表達,跟我們之前講的迴歸樹不一樣了。
2、怎麼訓練模型:
實際上永遠咱們講模型是這個套路,先模型假使已經從天上掉下來了,你要怎麼用它也就是預測部分,理解了怎麼預測之後,咱們再講它是怎麼得到這模型的,怎麼訓練出來的。
2.1 案例引入
那麼我們該如何學到一堆樹?首先要定義一個損失函式或者目標函式,包括損失項和正則項,然後去優化它。
先看個例子:我想要預測到底在t時刻有多麼的喜歡浪漫的音樂,以下圖兩個時間節點來學到了這麼一棵樹(實際上我們知道做迴歸樹就是在上面畫鋸齒),當所有小於左邊圖中時間節點的時候,用這幾個點的平均值代表葉子節點的預測;當大於右邊節點的時候,用這些點的平均值代表葉子節點的預測。中間也是一樣。假設左邊這個點是我遇到女朋友的時候,接下來你會越來越喜歡romantic music一直到後邊,對於浪漫音樂喜好程度又開始下降了。
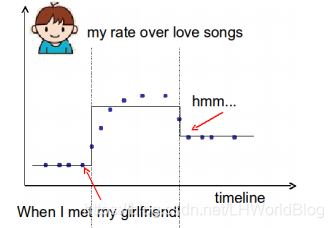

對於這個模型來說分了兩支,因為決策樹就怕過擬合,它如果沒做預剪枝的話,會一直細分下去。
這是一個實際的例子,通過這個例子,我們可以得到對於普通的一棵樹來說,我們要學習的是:第一,splitting positions,意思是分裂的位置,也就是分裂條件應該設在哪,第二我們要學得每一段的高度,也就是指這個區間內葉子節點表達應該等於多少,因為它是取葉子結點的平均值作為結果。
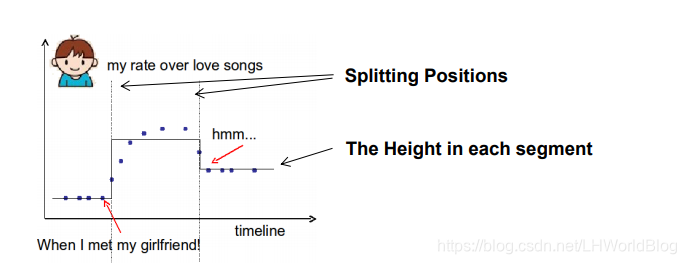
基於這兩個因素,我們怎麼定義這個樹是複雜還是不復雜呢?首先有多少個分裂點可以看出它複雜還是不復雜,如果它切的更碎,正則項也就更多更復雜;另外一個類似L2正則的方式,就是每一段的高度的L2正則,也可以像邏輯迴歸,線性迴歸一樣,一定程度上衡量葉子節點有多麼的複雜。所以它提出了兩種思想,第一個是分裂的次數可以衡量這個樹複雜不復雜,第二分裂之後每個樹給你一個score結果,這個結果做一個平方再加和的總體值,也可以一定程度上衡量這個樹到底複雜不復雜。
比如對於如下的樹我們用以上的定義複雜的因素來評判下:
分裂幾種情況,第一種情況:

對於這麼一個要分類的結果,顯然它會造成Loss小,因為它非常好的擬合了訓練集;如果簡用分裂次數和段高低的平方加和來講,正則項會很大。
第二種情況:
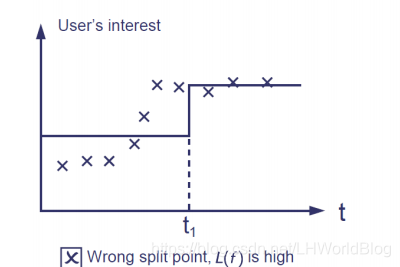
它在不對的splitting point上分割了,導致L大了,而Ω項還可以,因為它只做了一次分裂。
第三種情況:
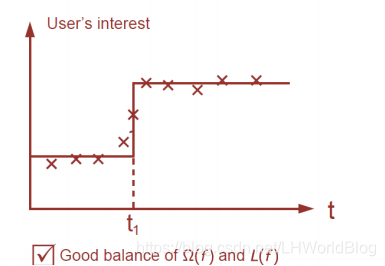
就是一個非常好的平衡,只做了一次分裂,並且損失項還比較小,所以我們的目標就是在訓練樹上也應該去衡量一下樹的複雜程度,能讓它做到即訓練損失小一些,並且正則項也要小一些。
2.2 XGBoost目標函式求解
對於整合學習,我們知道是把多棵樹的結果給累加起來。假設我們有K棵樹,最終的ŷ就是K棵樹的預測結果的相加。表達為:
這裡面的F是我們所有的迴歸樹,就之前的線性模型來講,它的引數是一組w,而在這個裡面,它的引數是就一堆樹。所以原來引數型模型我們要學的目標是一組權重w,是我們要的結果,而樹的整合學習模型,我們要學到的是一堆樹,這是要從訓練集中學到的。基於此,我們建立一個目標函式的形式即:
其中第一項是損失函式,損失函式既然每顆小樹裡面沒有w,我們也就不費事地把它翻譯成w的語言了,直接把ŷ拿來用,一定是有了yi,y^這兩項就能算損失函式的,這是損失部分,跟GBDT裡面的損失是一個概念。而另一項Ω是新引入的。這個公式裡面從1到K,從一到n分別代表什麼含義? n是樣本的數量,K是樹的數量。你有n條樣本,統計損失的時候,n條樣本都要考慮進去,而有K棵樹在統計複雜度的時候,要以樹為單位去統計。
如何去定義Ω這個東西?它提出了幾種思路:
第一每棵樹葉子節點數量,可以描述這個樹的複雜程度。
第二每棵樹葉子節點上的評分score的L2範數也可以評估這棵樹是否複雜。
第三把這上面兩項結合在一起,做了一個正則項。
現在既想要一個有一定的預測效果,而相對簡單的模型,要怎麼做呢?我們給整合學習將Ft(x)寫成如下的形式:
這裡的yi^代表之前寫的大F(x),y^0就是F0(x),y^1就是F1(x),一直到Ft(x)。通過boosting這種加法模式,最終的ŷ就等於之前所有小樹的加和,也等於上一代的ŷ加上最新的一棵小樹。此時Loss中的ŷ是什麼的問題就解決了。
我們把它分解一下,既然
此時Obj函式就變成了
我們現在的目標就是找到一個f(t),能夠使這個函式變小。只要這個函式小了,預測結果一定差不了。這個函式帶著求和號就代表著它已經考慮到所有樣本的情況了。
如果我們的損失函式是mse的話,將上式中的l替換成具體的損失函式就是:
yi^2和yi^(t-1)^2這兩項都可以放到後面的常數項裡面去,它們不會影響ft(xi)這一項的變大或者變小,只有它的係數可以影響。所以整合完後就是如上所述的公式,其中ft(xi)是未知數。所以這就變成了一個簡單的二次函式求最小值的問題。
ax^2+bx+c當x等於什麼的時候有最小值?根據初中的理論,當x為-b/a2的時候,函式有最小值。此時在上述公式裡面
a是1,b是
所以當ft(x)為yi-yi^(t-1)的時候,函式取最小值。這就是我們說的殘差,所以殘差你從這個角度也可以一樣推出來,我們希望損失函式可以最小,就是當ft(x)為yi-yi^(t-1)的時候最小,這裡面為什麼我們要寫成ft(xi)的形式,因為我們目標是要找到ft,所以一定要把它暴露出來,這樣我們才知道ft要滿足什麼條件才可以。
mse函式是一個非常幸運的函式,它展開之後就是一個二次函式,你可以求出它最小值的解析解,對於邏輯迴歸函式甚至更復雜的函式你是沒法寫出解析解的,你就需要把目標函式展開成一個能寫出解析解的東西來,再去求它的解析解,此時就用到我們的二階泰勒展開。二階泰勒展開的公式如下:
我們再看下我們的目標函式:
結合二階泰勒展開的公式,這裡把 看作△x,把
看作x。進行二階泰勒展開,x已知。對f(x)求一階導是:
上面的含義是對l求一次導,然後把y^(t-1)帶進去。
對f(x)求二階導是:
所以最後的二階泰勒展開就是
在這個函式裡面只有 是自變數,同樣這也是一個二階函式,所以當x=-b/2a的時候,損失函式取得最小值,也就是ft(xi)=f''(x)/f'(x)的時候。如果看到這不理解的話,我們考慮下一個特殊的函式--平方損失函式。對於平方損失函式來講,一階導是二倍的殘差,二階導是一個常數2,即:
把它帶進去二階泰勒展開的式子裡,會得到跟之前直接把它展開同樣的結果。因為它本身是個二次函式,對於二次函式進行二階泰勒展開沒有損失,實際上是用一個拋物線去擬合一個拋物線,所以不會有約等於號。但是對於複雜一點的函式,比如說交叉熵損失函式,它就有損失了,但是有損失它也不在乎了,我就保留它的這些近似項。
再來對這個公式進行簡化,
而 這一項可以扔掉,因為它是常數項,yi是真實值,而y^(t-1),是前面t-1輪預測已經得到的結果,所以這裡面的關於它兩個的損失函式可以計算出來。現在只有
未知,剩餘的都是可以算出來的。 我們把常數項放在一起,整理之後,新目標函式:
其中:
這裡面簡化之後雖然l丟掉了,但l實際上存活在gi和hi裡,因為在計算gi和hi的時候,需要對l進行ft-1的求偏導,再把ft-1帶進去,gi就是函式空間中梯度下降對應著如下結果:
gi和hi是什麼東西?它已經是個能求得出來的真真切切的一個數。y^(t-1)是知道的,它是某一個數據點在上一輪預測出來的具體的結果值,對它求偏導的解析式也能知道,只要損失函式定義出來就知道了。求完偏導得到了一個新的函式,把具體的值代進去就得到了一個新的值。有多少條樣本就有多少個gi和hi。
3、XGBoost中正則項的顯式表達
我們目前把loss項已經整理好了,而Ω這一項還沒顯式地表示出來。我們最終想找到一個ft去讓整個目標函式最小,gi和hi已經是具體的數了,而Ω這一項還沒有定義。接下來我們來討論下Ω的表達。
引入分配機的概念,它定義了ft(x)最終的預測結果就等於wq(x)。其中q(x)代表它落到了哪一個葉子節點上。假如說x第一條資料落到了第一個葉子節點上,這會的第一條資料就等於1。對於小男孩來說,它落到了一號節點上,q(小男孩)=1,也就是ft(小男孩)=wq(x)=w1,某一條資料最終會落在幾號葉子節點上,q這條資料就等於幾。也就是它定義了什麼叫w,在這裡面w1就是第一個葉子節點的表達,w2就是第二個葉子節點的表達,w3就是第三個葉子節點表達。
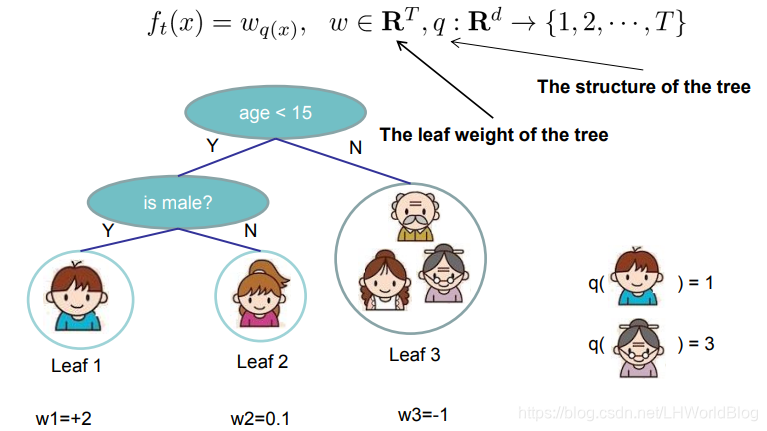
有了w的定義,我們定義Ω項,定義了損失項。損失項包含兩部分,Ω是跟著每棵樹來的,應該一棵樹有一個Ω。也就是對於任何一個小樹我扔到Ω裡面,你就要給我評估出我樹有多複雜。先看定義公式:
對於某一棵樹的正則項來講,它就等於葉子節點的數量乘以第一個超引數γ,這個是設定的。然後就是這棵樹上的每一個葉子節點的表達的平方加和,再乘1/2λ。比如下面這個樹它的Ω等於多少?
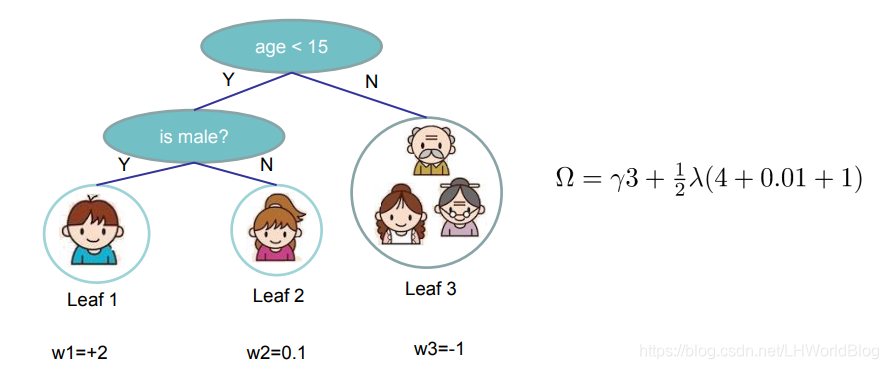
它有三個葉子節點,就是3乘以γ,w1等於+2,平方是4,w2平方等於0.01,w3平方等於1。所以最終的正則項是上述表達,也就是說對於這棵樹的Ω,在確定了這兩個超引數之後,也是一個可以具體計算的數。
我們再看下一種表達,假設 ,它是一個樣本的集合,所有被分到一號葉子節點裡邊的樣本的集合就叫I1,所有分到二號葉子節點裡邊的集合就叫I2。 然後ft(x)寫成wq(x),最後我們的損失函式就表示成:
解釋下:
從第一步到第二步應該沒有問題就是把正則的具體表達帶入進去,而第二步到第三步實際上就是我們換一種遍歷的維度,原來是樣本序號,從樣本i=1遍歷到n,現在改成遍歷葉子節點j=1到T,從1號葉子節點裡數,所有屬於1號葉子節點的gi做一個加和,統一乘wj。比如有三個葉子節點,其中1,2號樣本落在第一個,所以表達為w1。3,5落在第二個葉子結點,表達為w2。4,6落在第三個葉子結點,表達為w3。根據第二個公式的加法 就是g1w1+g2w1+g3w2+g4w3+g5w2+g6w3,而現在根據第三個公式表達的就是(g1+g2)w1+(g3+g5)w2+(g4+g6)w3,實際上這一項的轉換就是把相同的w給提到一起去,也就相是同葉子節點裡邊的g都加和到一起。
另一項
按葉子節點遍歷,就是
而結合最外面的正則項,剛好也是按葉子節點遍歷,所以乾脆合到一起,就變稱第三個公式的表達。
原來是按樣本遍歷,但這樣本里面肯定有很多點落在同一個葉子節點裡了,也就是這些點,未來的wq(xi)都是相同的。我們就把它以葉子節點來遍歷,把所有屬於一號葉子節點的gi,雖然它們落在同一個葉子節點裡了,但是它們的gi不一定相等,取決於這條樣本在上一輪預測中它落在哪一個葉子節點。
通過顯示的定義的Ω,我們就把目標函式整理成了如下形式:
這就是我們的目標函式。 現在這個目標函式只看wj的變化而變化了。我們定義Gj等於落在某一個葉子節點上的所有gi的加和, Hj定義為落在某一個j葉子節點上所有hi的加和。即:
最後損失函式表示為:
現在這個損失函式是大還是小,取決於誰呢?GjWj是已經知道的,Hj這一項也是知道的,λ是自己設的超引數,只有wj是未知的。當它等於什麼的時候能讓Obj最小呢?這又是一個二次函式,當x=-b/a2的時候最小,在這裡wj是未知數,b是Gj,a是1/2(Hj+λ),所以根據表示式,即wj如下的時候:
能讓損失函式等於最小值。此時損失函式根據一般的二次方程的最小值表達形式-b^2/4+c,此時損失函式的最小值可以表達出來如下:
這是一個簡單的二次函式,函式的最小值解能寫出來。
所以我們可以看到葉子節點的表達不再等於y平均了,而等於上面wj的表達。
舉個例子,假設有這麼一棵樹:

分到一號葉子節點有的第一號樣本,分到二號葉子節點有第四號樣本,分到第三個葉子節點有235,三個樣本。此時的G1就是小男孩的g1,H1就是小男孩的h1。G3=g2+g3+g5,H2=h2+h3+h5。最終的得分,左邊為什麼是+2?g1就應該等於前面所有的樹對y的偏導,算出了具體的值。對它再求一次偏導,算出h。g1,h1是具體數,每一條樣本都可以帶到一階導和二階導的函式裡面,算出它的g和h。在分裂的過程中,如果分到了同一個葉子節點,要把它們所有的g,h相加,再帶到剛才obj公式裡面去,算得一個葉子節點表達即2。所以葉子結點的表達就不再是平均了,而變成了跟以前的預測結果相關的。
4、如何生長一棵新的樹?
假如我想訓練第T+1棵樹,也是就f(t+1),那你在手裡有什麼,你其實有個FT,你手裡還有一個訓練集,根據這些我們能得到從g1一直到gn,從h1一直到hn。它們每一個都是訓練集背後具體的一個數。
我們看下從最開始的首先一個根節點,這個根節點裡包含了n條資料。你每次分裂,就像樹一樣,變例所有可能的分裂的維度,每次分裂,都能算一下此時的obj等於多少,Obj是關於G和H的,然後再求和,在加上一個t倍的γ,你每嘗試一次就算一次obj,是不是總能找到一個使得obj最小的那個標準,固化在這,沒問題吧?
上面是兩個葉子結點。
接下來我該試著下一次分裂是不是左邊的節點又能一份為二,如下:

分完之後這棵樹變為3個葉子結點,然後1裡邊落哪些,你每次分裂的時候。假如這棵樹就是現在這個額結構,那麼我obj應該能等於多少也可以求出來。所以肯定能夠找到使得obj