
Spark 系列(十六)—— Spark Streaming 整合 Kafka
一、版本說明
Spark 針對 Kafka 的不同版本,提供了兩套整合方案:spark-streaming-kafka-0-8 和 spark-streaming-kafka-0-10,其主要區別如下:
| spark-streaming-kafka-0-8 | spark-streaming-kafka-0-10 | |
|---|---|---|
| Kafka 版本 | 0.8.2.1 or higher | 0.10.0 or higher |
| AP 狀態 | Deprecated 從 Spark 2.3.0 版本開始,Kafka 0.8 支援已被棄用 |
Stable(穩定版) |
| 語言支援 | Scala, Java, Python | Scala, Java |
| Receiver DStream | Yes | No |
| Direct DStream | Yes | Yes |
| SSL / TLS Support | No | Yes |
| Offset Commit API(偏移量提交) | No | Yes |
| Dynamic Topic Subscription (動態主題訂閱) |
No | Yes |
本文使用的 Kafka 版本為 kafka_2.12-2.2.0,故採用第二種方式進行整合。
二、專案依賴
專案採用 Maven 進行構建,主要依賴如下:
<properties> <scala.version>2.12</scala.version> </properties> <dependencies> <!-- Spark Streaming--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> <!-- Spark Streaming 整合 Kafka 依賴--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka-0-10_${scala.version}</artifactId> <version>2.4.3</version> </dependency> </dependencies>
完整原始碼見本倉庫:spark-streaming-kafka
三、整合Kafka
通過呼叫 KafkaUtils 物件的 createDirectStream 方法來建立輸入流,完整程式碼如下:
import org.apache.kafka.common.serialization.StringDeserializer import org.apache.spark.SparkConf import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent import org.apache.spark.streaming.kafka010._ import org.apache.spark.streaming.{Seconds, StreamingContext} /** * spark streaming 整合 kafka */ object KafkaDirectStream { def main(args: Array[String]): Unit = { val sparkConf = new SparkConf().setAppName("KafkaDirectStream").setMaster("local[2]") val streamingContext = new StreamingContext(sparkConf, Seconds(5)) val kafkaParams = Map[String, Object]( /* * 指定 broker 的地址清單,清單裡不需要包含所有的 broker 地址,生產者會從給定的 broker 裡查詢其他 broker 的資訊。 * 不過建議至少提供兩個 broker 的資訊作為容錯。 */ "bootstrap.servers" -> "hadoop001:9092", /*鍵的序列化器*/ "key.deserializer" -> classOf[StringDeserializer], /*值的序列化器*/ "value.deserializer" -> classOf[StringDeserializer], /*消費者所在分組的 ID*/ "group.id" -> "spark-streaming-group", /* * 該屬性指定了消費者在讀取一個沒有偏移量的分割槽或者偏移量無效的情況下該作何處理: * latest: 在偏移量無效的情況下,消費者將從最新的記錄開始讀取資料(在消費者啟動之後生成的記錄) * earliest: 在偏移量無效的情況下,消費者將從起始位置讀取分割槽的記錄 */ "auto.offset.reset" -> "latest", /*是否自動提交*/ "enable.auto.commit" -> (true: java.lang.Boolean) ) /*可以同時訂閱多個主題*/ val topics = Array("spark-streaming-topic") val stream = KafkaUtils.createDirectStream[String, String]( streamingContext, /*位置策略*/ PreferConsistent, /*訂閱主題*/ Subscribe[String, String](topics, kafkaParams) ) /*列印輸入流*/ stream.map(record => (record.key, record.value)).print() streamingContext.start() streamingContext.awaitTermination() } }
3.1 ConsumerRecord
這裡獲得的輸入流中每一個 Record 實際上是 ConsumerRecord<K, V> 的例項,其包含了 Record 的所有可用資訊,原始碼如下:
public class ConsumerRecord<K, V> {
public static final long NO_TIMESTAMP = RecordBatch.NO_TIMESTAMP;
public static final int NULL_SIZE = -1;
public static final int NULL_CHECKSUM = -1;
/*主題名稱*/
private final String topic;
/*分割槽編號*/
private final int partition;
/*偏移量*/
private final long offset;
/*時間戳*/
private final long timestamp;
/*時間戳代表的含義*/
private final TimestampType timestampType;
/*鍵序列化器*/
private final int serializedKeySize;
/*值序列化器*/
private final int serializedValueSize;
/*值序列化器*/
private final Headers headers;
/*鍵*/
private final K key;
/*值*/
private final V value;
.....
}3.2 生產者屬性
在示例程式碼中 kafkaParams 封裝了 Kafka 消費者的屬性,這些屬性和 Spark Streaming 無關,是 Kafka 原生 API 中就有定義的。其中伺服器地址、鍵序列化器和值序列化器是必選的,其他配置是可選的。其餘可選的配置項如下:
1. fetch.min.byte
消費者從伺服器獲取記錄的最小位元組數。如果可用的資料量小於設定值,broker 會等待有足夠的可用資料時才會把它返回給消費者。
2. fetch.max.wait.ms
broker 返回給消費者資料的等待時間。
3. max.partition.fetch.bytes
分割槽返回給消費者的最大位元組數。
4. session.timeout.ms
消費者在被認為死亡之前可以與伺服器斷開連線的時間。
5. auto.offset.reset
該屬性指定了消費者在讀取一個沒有偏移量的分割槽或者偏移量無效的情況下該作何處理:
- latest(預設值) :在偏移量無效的情況下,消費者將從其啟動之後生成的最新的記錄開始讀取資料;
- earliest :在偏移量無效的情況下,消費者將從起始位置讀取分割槽的記錄。
6. enable.auto.commit
是否自動提交偏移量,預設值是 true,為了避免出現重複資料和資料丟失,可以把它設定為 false。
7. client.id
客戶端 id,伺服器用來識別訊息的來源。
8. max.poll.records
單次呼叫 poll() 方法能夠返回的記錄數量。
9. receive.buffer.bytes 和 send.buffer.byte
這兩個引數分別指定 TCP socket 接收和傳送資料包緩衝區的大小,-1 代表使用作業系統的預設值。
3.3 位置策略
Spark Streaming 中提供瞭如下三種位置策略,用於指定 Kafka 主題分割槽與 Spark 執行程式 Executors 之間的分配關係:
PreferConsistent : 它將在所有的 Executors 上均勻分配分割槽;
- PreferBrokers : 當 Spark 的 Executor 與 Kafka Broker 在同一機器上時可以選擇該選項,它優先將該 Broker 上的首領分割槽分配給該機器上的 Executor;
PreferFixed : 可以指定主題分割槽與特定主機的對映關係,顯示地將分割槽分配到特定的主機,其構造器如下:
@Experimental
def PreferFixed(hostMap: collection.Map[TopicPartition, String]): LocationStrategy =
new PreferFixed(new ju.HashMap[TopicPartition, String](hostMap.asJava))
@Experimental
def PreferFixed(hostMap: ju.Map[TopicPartition, String]): LocationStrategy =
new PreferFixed(hostMap)3.4 訂閱方式
Spark Streaming 提供了兩種主題訂閱方式,分別為 Subscribe 和 SubscribePattern。後者可以使用正則匹配訂閱主題的名稱。其構造器分別如下:
/**
* @param 需要訂閱的主題的集合
* @param Kafka 消費者引數
* @param offsets(可選): 在初始啟動時開始的偏移量。如果沒有,則將使用儲存的偏移量或 auto.offset.reset 屬性的值
*/
def Subscribe[K, V](
topics: ju.Collection[jl.String],
kafkaParams: ju.Map[String, Object],
offsets: ju.Map[TopicPartition, jl.Long]): ConsumerStrategy[K, V] = { ... }
/**
* @param 需要訂閱的正則
* @param Kafka 消費者引數
* @param offsets(可選): 在初始啟動時開始的偏移量。如果沒有,則將使用儲存的偏移量或 auto.offset.reset 屬性的值
*/
def SubscribePattern[K, V](
pattern: ju.regex.Pattern,
kafkaParams: collection.Map[String, Object],
offsets: collection.Map[TopicPartition, Long]): ConsumerStrategy[K, V] = { ... }在示例程式碼中,我們實際上並沒有指定第三個引數 offsets,所以程式預設採用的是配置的 auto.offset.reset 屬性的值 latest,即在偏移量無效的情況下,消費者將從其啟動之後生成的最新的記錄開始讀取資料。
3.5 提交偏移量
在示例程式碼中,我們將 enable.auto.commit 設定為 true,代表自動提交。在某些情況下,你可能需要更高的可靠性,如在業務完全處理完成後再提交偏移量,這時候可以使用手動提交。想要進行手動提交,需要呼叫 Kafka 原生的 API :
commitSync: 用於非同步提交;commitAsync:用於同步提交。
具體提交方式可以參見:Kafka 消費者詳解
四、啟動測試
4.1 建立主題
1. 啟動Kakfa
Kafka 的執行依賴於 zookeeper,需要預先啟動,可以啟動 Kafka 內建的 zookeeper,也可以啟動自己安裝的:
# zookeeper啟動命令
bin/zkServer.sh start
# 內建zookeeper啟動命令
bin/zookeeper-server-start.sh config/zookeeper.properties啟動單節點 kafka 用於測試:
# bin/kafka-server-start.sh config/server.properties2. 建立topic
# 建立用於測試主題
bin/kafka-topics.sh --create \
--bootstrap-server hadoop001:9092 \
--replication-factor 1 \
--partitions 1 \
--topic spark-streaming-topic
# 檢視所有主題
bin/kafka-topics.sh --list --bootstrap-server hadoop001:90923. 建立生產者
這裡建立一個 Kafka 生產者,用於傳送測試資料:
bin/kafka-console-producer.sh --broker-list hadoop001:9092 --topic spark-streaming-topic4.2 本地模式測試
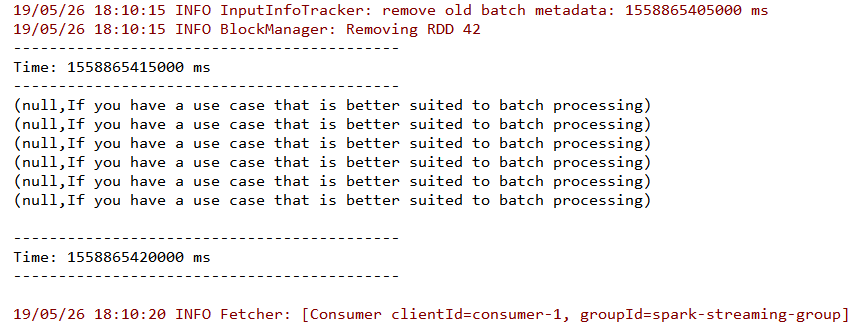
這裡我直接使用本地模式啟動 Spark Streaming 程式。啟動後使用生產者傳送資料,從控制檯檢視結果。
從控制檯輸出中可以看到資料流已經被成功接收,由於採用 kafka-console-producer.sh 傳送的資料預設是沒有 key 的,所以 key 值為 null。同時從輸出中也可以看到在程式中指定的 groupId 和程式自動分配的 clientId。
參考資料
- https://spark.apache.org/docs/latest/streaming-kafka-0-10-integration.html
更多大資料系列文章可以參見 GitHub 開源專案: 大資料入門指南