
《Designing.Data-Intensive.Applications》筆記 二
Partitioning(分割槽)
對於非常大的資料集,或非常高的吞吐量,僅複製是不夠的:我們需要將資料進行分割槽(partitions),也稱分片(sharding)
Partitioning of Key Range(根據鍵範圍分割槽)

缺點是某些特定的訪問模式會導致熱點
Partitioning by Hash of Key(根據鍵的雜湊分割槽):
由於偏斜和熱點的風險,許多分散式資料儲存使用雜湊函式來確定鍵的分割槽
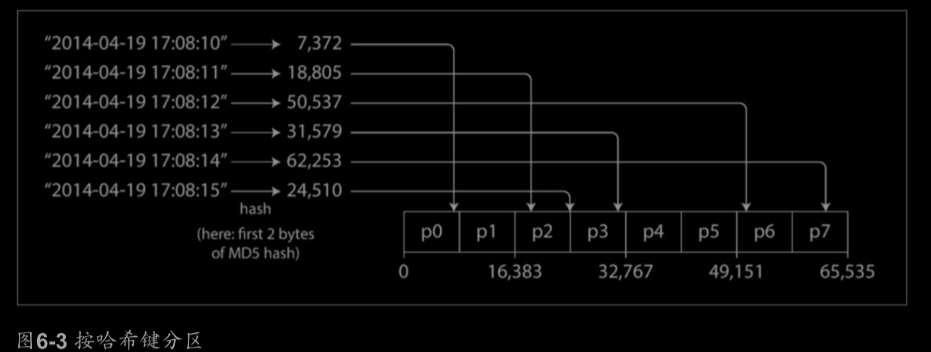
缺點:失去了鍵範圍分割槽的一個很好的屬性,高效執行範圍查詢的能力。曾經相鄰的鍵分散在所有分割槽裡
可通過組合索引方式解決:

雜湊分割槽可以幫助減少熱點。但不能完全避免,有一些極端場景。
如社交網站上,擁有數百萬粉絲的名人在做某事時可能引發一場風暴。此事件可能導致大量寫入同一個鍵(
鍵可能是名人ID,或人們談論的熱點話題)。
大多數資料系統無法自動補償這種高度傾斜的負載。一個簡單的辦法是在主鍵的開始或結尾新增一個隨機數,
只要一個兩位數的十進位制隨機數就可以將主鍵分散為100種不同的主鍵,從而儲存在不同分割槽中。
當有二級索引時,兩種方法對資料庫進行分割槽:document-based(基於文件)、term-based(基於關鍵字)
假設一個二手車網站,每條資料都有一個唯一ID,稱之為文件ID--並用文件ID對資料庫進行分割槽(如,分割槽0中
的ID 0到499,分割槽1中的ID 500到999)
document-based:
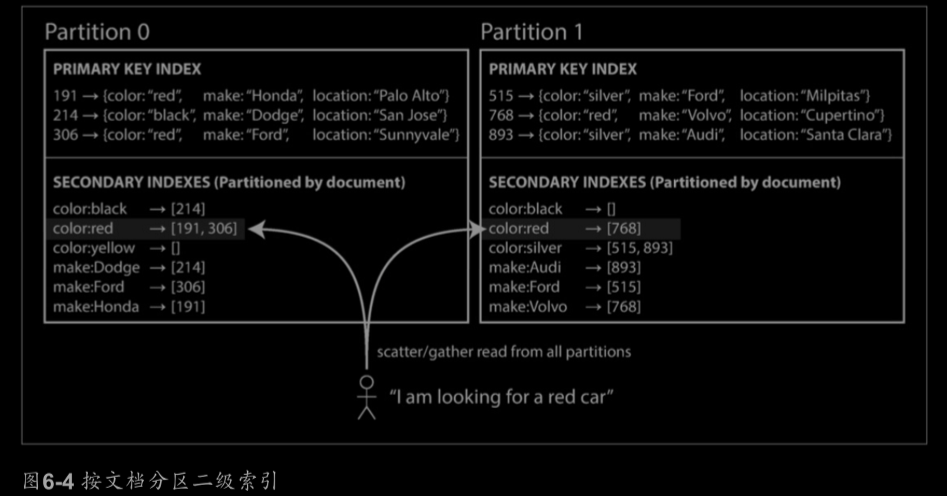
此索引方法中,每個分割槽維護自己的二級索引,不關心其他分割槽的資料。因此也稱這種索引為本地索引(local index)
因為特定查詢可能需要訪問所有分割槽(如搜尋紅色汽車),此查詢方法稱為scatter/gatter(分散/聚集),可能使二級
索引上的讀取查詢相當昂貴。
term-based:
我們可以構建一個覆蓋所有資料的全域性索引。但不能把這個索引只存在一個節點上,這樣會出現效能瓶頸,違背了
分割槽的目的。全域性索引也必須進行分割槽,但可採用與主鍵不同的分割槽方式。
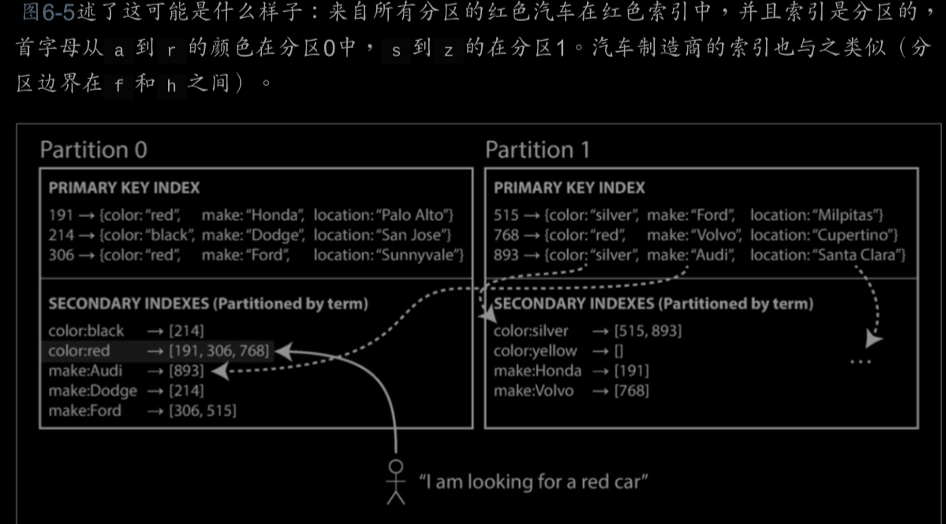
全域性索引的缺點在於寫入速度較慢和複雜,因為寫入單個文件可能影響索引的多個分割槽(文件中每個關鍵詞可能位於
不同的分割槽或節點上)
分割槽再平衡
隨著時間推移,資料庫會有各種變化
- 查詢吞吐量增加,要新增更多的CPU處理負載
- 資料集大小增加,要新增更多的磁碟和RAM
- 機器出現故障,需要其他機器接管
這些更改都需要資料和請求從一個節點移動到另一個節點。這個過程稱為再平衡(rebalancing)
幾種平衡策略
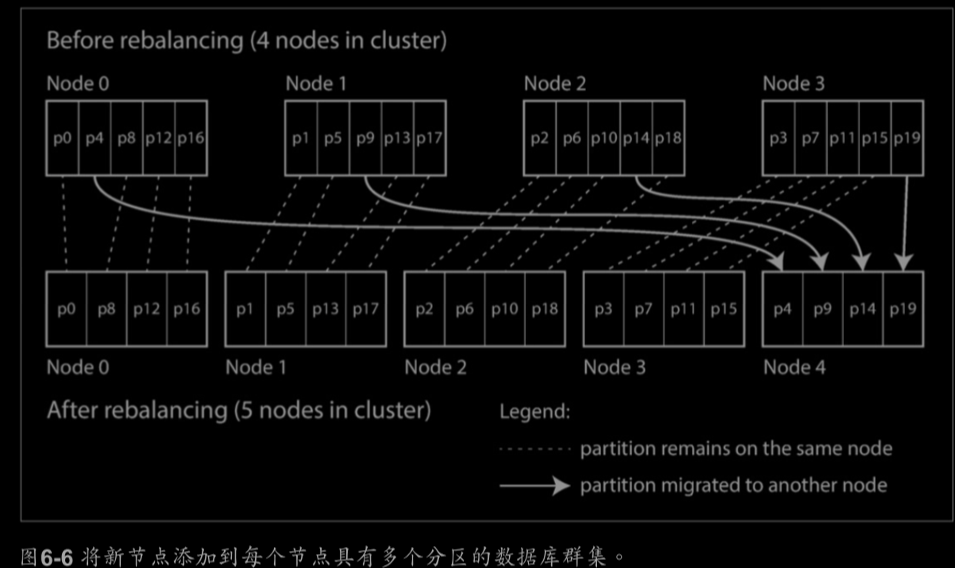
1.固定數量的分割槽:
建立比節點更多的分割槽,如執行在10個節點上的資料庫被分為1000個分割槽。有新節點加入時,新節點可以從當前
每個節點拿一些分割槽,知道分割槽再次公平分配。
2.動態分割槽:分割槽數量與資料集的大小成正比
3.按節點比例分割槽:分割槽數與節點數成比例。
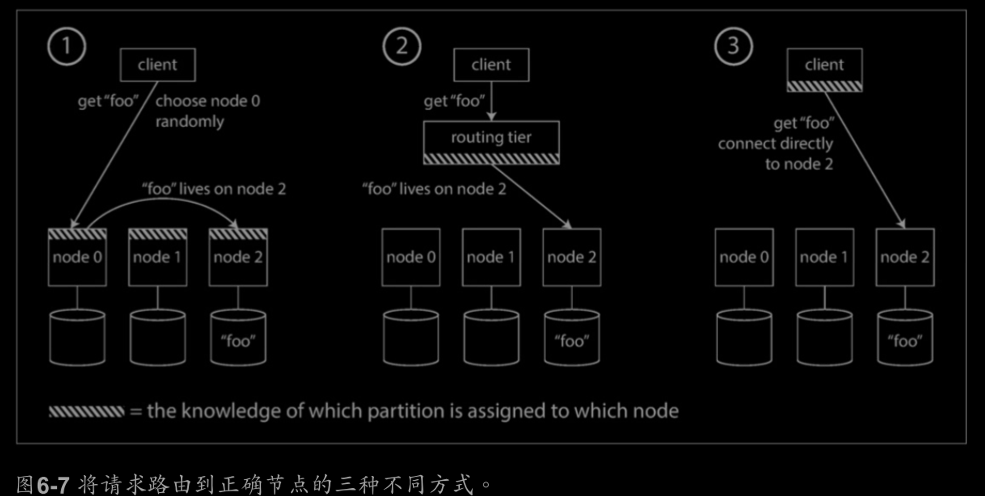
服務發現(service discovery)
客戶發出請求時,如何知道要連線哪個節點?如想讀或寫鍵"foo",需要連線哪個IP地址和埠號?
有幾種不同的解決方案:
1.允許客戶聯絡任何節點。
2.首先將所有客戶端請求發到路由層,路由層決定哪個節點處理,並相應轉發。
3.要求客戶端知道分割槽和節點的分配。
以上所有情況的關鍵問題是,做出路由決策的元件(節點、路由層或客戶端)如何瞭解分割槽--節點之間的分配關係變化?
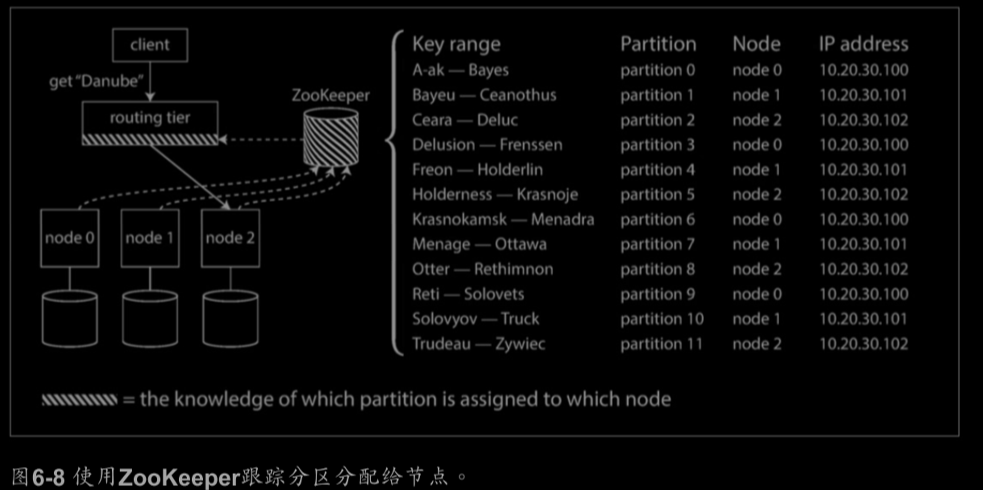
許多分散式資料系統都依賴於一個獨立的協調服務,比如ZooKeeper來跟蹤叢集元資料。每個節點在ZooKeeper
中註冊自己,ZooKeeper維護分割槽到節點的可靠對映。其他參與者(如路由層或分割槽感知客戶端)可在ZooKeeper中
訂閱此資訊。只要分割槽分配發生改變,ZooKeeper就會通知路由層使路由資訊保持最新狀態。
第七章:事務(transaction)

數十年來,事務一直是簡化這些問題的首選機制。
但不應將事務當作理所當然,事務不是自然的規律,它們是為簡化程式設計模型訪問資料庫設計的。
並不是所有的應用都需要事務,有時弱化事務保證或完全放棄事務也是有好處的(如獲得更高效能)
事務的ACID:Atomicity原子性、Consistency一致性、隔離性Isolation、永續性Durability
Atomicity:能夠在出錯時中止事務,丟棄該事務進行的所有寫入變更的能力。
Consistency:you have certain statements about your data (invariants) that must always be true。但一致性的概念取決於應用程式對不變數的定義。一致性是應用程式的屬性,其他三者不是。
Isolation:同時執行的事務是相互隔離的,它們不能互相冒犯。然而實踐中很少用Isolation,有效能損失。
Durability:事務一旦成功完成,即使發生硬體故障或資料庫崩潰,寫入的任何資料都不會丟失
read-commited,為了避免dirty-read、dirty-write
implementing read-commit:
prevent dirty-write:using row-level locks;Only one transaction can hold that lock。
prevent dirty-read:database remembers both the old-commited value and the new value set by the transaction that currency holds the write lock.
read-commited has problems: nonrepeatable read or read skew
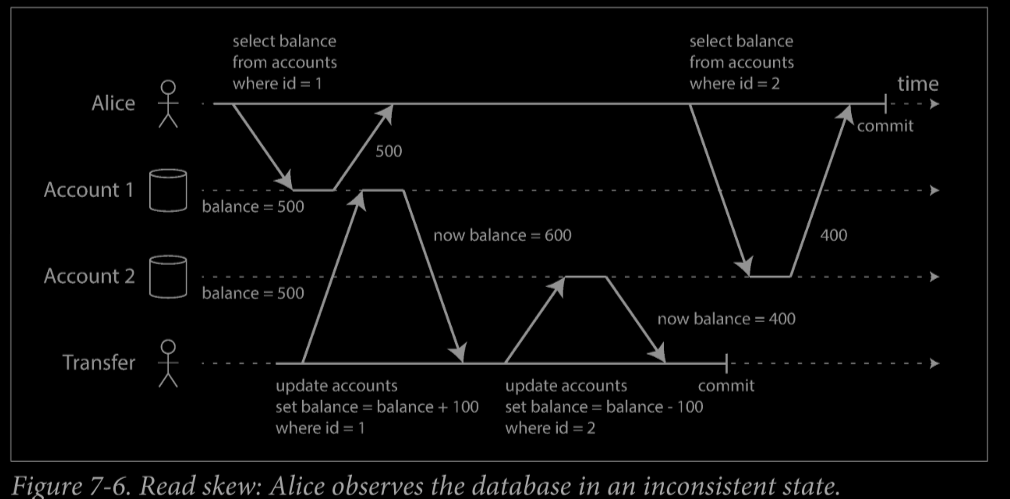
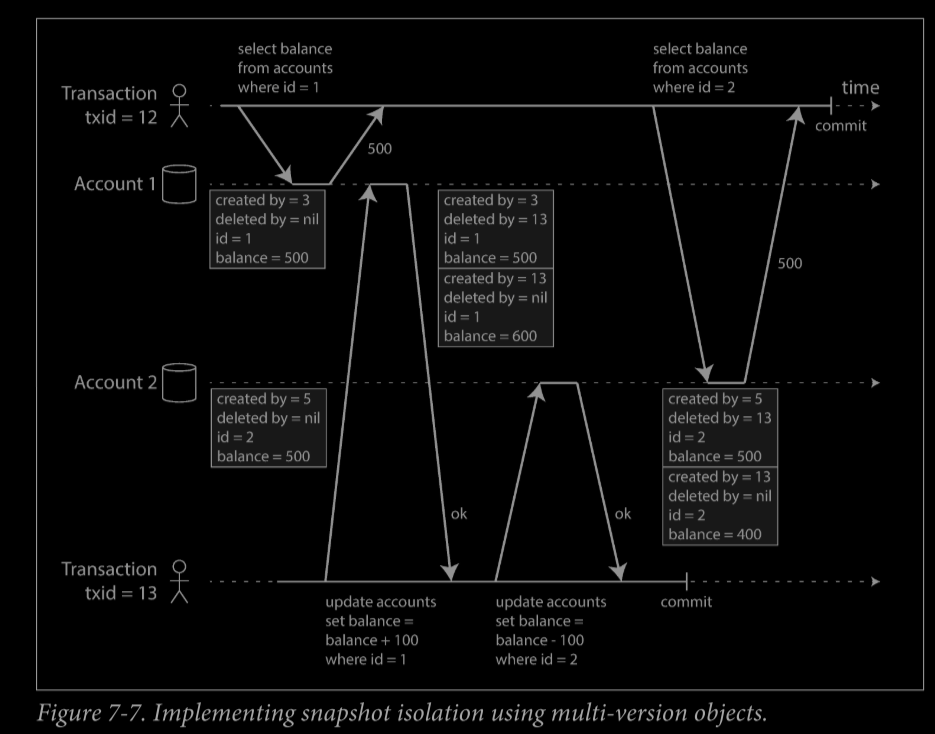
Snapshot solation(快照隔離) is the most common solution to this problem.
To implements snapshot isolation,database potentially keep several different commited versions of an object,
this technique is known as multiversion concurrency control(MVCC).
how MVCC-based snapshot isolation is implemented:
the lost update problem : it is a common problem,a variety of solutions have been developed.
1.Atomic write operations(原子寫) : such as UPDATE counters SET value = value + 1 WHERE key = 'foo'
2.Explicit locking(顯式鎖) : for update語句
3.Automatically detecting lost updates : allow them to execute in parallel,if the transaction manager detects
a lost update,abort it.
4.Compare-and-Set(CAS) : apply in database that don't provide transactions.
5.Conflict resolution and replication : 複製資料庫中,防止丟失的更新需要考慮另一個維度:由於多節點存在資料副本且不同節點的資料可能被併發修改,因此需要一些額外的步驟防止丟失更新。
Write Skew and Phantoms(寫偏差和幻讀):
兩個事務讀取相同的物件,然後更新另一些物件,就可能發生寫偏差。
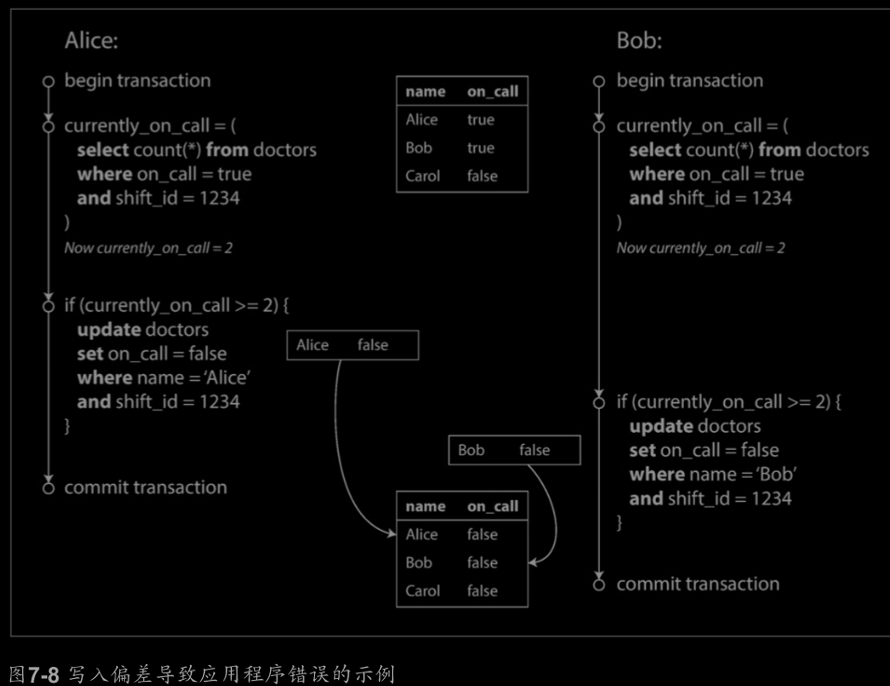
所有類似的例子遵循類似的模式:
1.一個SELECT查詢出符合條件的行,並檢查是否符合一些要求。
2.按照第一個查詢的結果,應用程式碼決定是否繼續。
3.如果決定繼續,執行寫入操作,提交事務。
一個事務中的寫入改變另一個事務的搜尋結果,稱為幻讀(Phantoms)
解決方案:A serializable isolation(可序列化的隔離級別) level is much preferable in most cases.
Most databases that provide serializability today use one of three techniques:
1.Literally executing transactions in a serial order(Redis implements this).
2.兩相鎖定(2PL, two-phase locking),幾十年來唯一可行的選擇。
3.樂觀併發控制技術,例如可序列化的快照隔離(serializable snapshot isolation)
為了高效執行方法1,可在儲存過程中封裝事務(Encapsulating transactions in stored procedures)
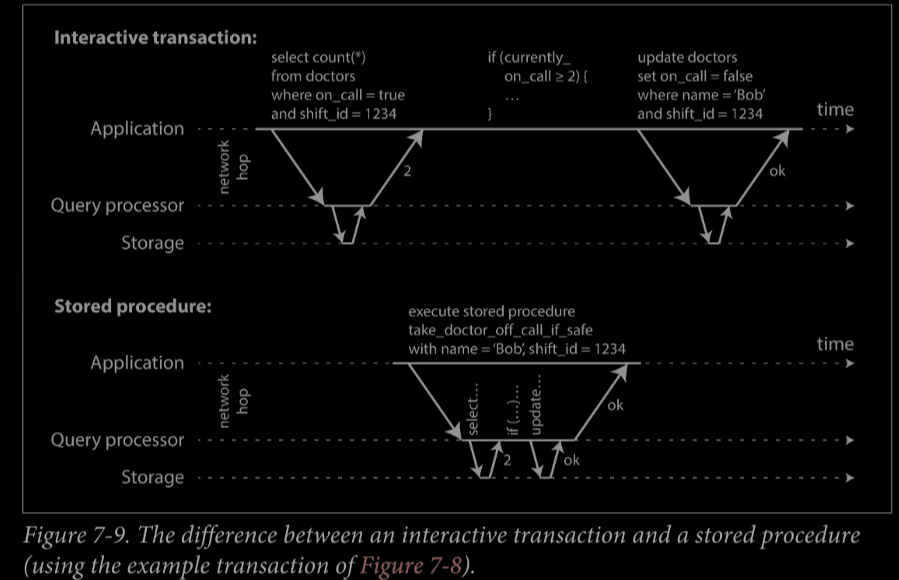
With stored procedures and in-memory data,executing all transactions on a single thr