
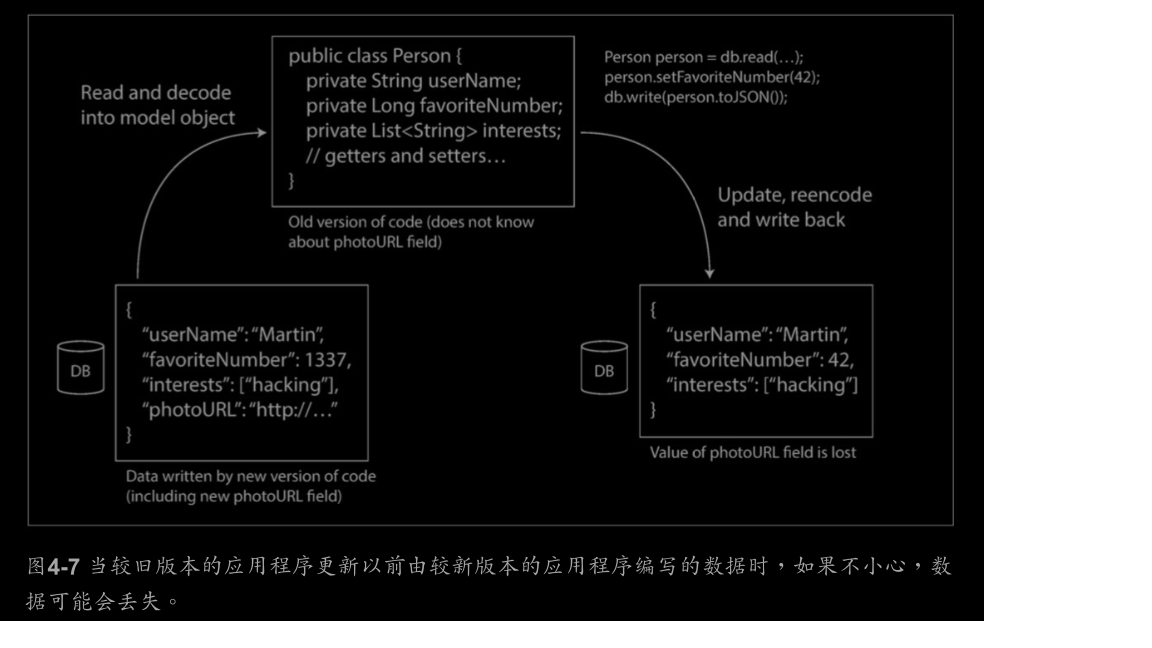
《Designing.Data-Intensive.Applications》筆記
程式通常(至少)使用兩種形式的資料:
1.記憶體中,資料儲存在物件、結構體、列表、陣列、雜湊表、樹等中。這些資料
結構針對CPU的高效訪問和操作進行了優化(通常使用指標)。
2.如果要將資料寫入檔案,或通過網路傳送,則必須將其編碼(encode)為某種
位元組序列(如JSON文件)。由於每個程序都有自己獨立的地址空間,一個
程序的指標對其他程序沒有任何意義,所以這個位元組序列通常與記憶體中的
資料結構完全不同。
所以,需要在兩種表示之間進行翻譯。
記憶體到位元組序列稱為編碼(Encoding)、序列化(serialization)、編組(marshalling)
位元組序列到記憶體稱為解碼(Decoding)、反序列化(deserialization)、反編組(unmarshalling)、解析(parsing)
資料在流程之間流動的最常見方式:
- 通過資料庫
- 通過服務呼叫(REST、RPC)
- 通過非同步訊息傳遞
資料庫中,寫入資料庫的過程對資料進行編碼,從資料庫讀取的過程對資料進行解碼。
服務中的資料流:REST與SOA
當需要網路通訊時,最常見的配置是兩個角色:客戶端和伺服器。
伺服器本身可以是另一個服務的客戶端(典型的Web應用伺服器充當資料庫的客戶端)
這種方法通常用於將大型應用程式按照功能區域分解為較小的服務,這樣當一個服務
需要另一個服務的某些功能或資料時,會向另一個服務發出請求。這種構建應用程式
的方式稱為面向服務的體系結構(service-oriented architecture,SOA)現在被改進為
微服務架構(microservices architecture)
當服務使用HTTP作為底層通訊協議時,稱之為Web服務。有兩種流行的Web服務方法:REST、SOAP
REST(Representational State Transfer)不是一個協議,是基於HTTP原則的設計哲學,強調簡單的資料格式。
SOAP(Simple Object Access Protocol)是基於XML的協議,與HTTP協議結合使用。
RPC(Remote Procedure Call)遠端過程呼叫:
PRC要解決兩個問題:
- 解決分散式系統中,服務之間的呼叫問題。
- 遠端呼叫時,能夠像本地呼叫一樣方便,讓呼叫者感知不到遠端呼叫的邏輯。
RPC與本地函式呼叫非常不同:
- 本地函式呼叫是可預測的,RPC不可預知;由於網路問題,請求和響應可能丟失。
但網路問題是常見的,必須預測它們,如重試失敗的請求。
- 本地函式要麼返回結果,要麼丟擲異常,或永遠不返回(無限迴圈或程序崩潰)。RPC
由於超時,可能返回沒有結果。
- 如果重試失敗的RPC,可能前一個請求已通過,只是響應丟失。除非你在協議中引入
除重idempotence機制。
- 本地方法,每次執行時間大致相同;RPC則慢得多,根據網路狀況,時間波動也很大。
- 呼叫本地函式,可以高效的將引用(指標)傳給本地記憶體中的物件。RPC所有引數必須被
編碼成可用過網路傳送的位元組,如引數是較大的物件,就存在問題。
PRC與資料庫之間的非同步訊息傳遞系統-通過訊息中介軟體來臨時儲存資訊
與直接RPC相比,使用訊息中介軟體(message-oriented middleware)的優點:
- 如果收件人不可用或過載,可以充當緩衝區,提高系統可靠性;
- 可以自動將訊息重新發送給已崩潰的程序,防止訊息丟失;
- 避免發件人需要知道收件人的IP地址、埠號(虛擬機器經常出入的雲部署中有用)
- 允許將一條訊息傳送給多個收件人;
- 將收件人和發件人邏輯分離(發件人只發布郵件,不關心使用者)
中介軟體(也稱Message brokers)的大體執行方式:
one process sends a message to a named queue or topic, and the broker ensures that
the message is delivered to one or more consumers of or subscribers to that queue or topic.
There can be many producers and many consumers on the same topic.
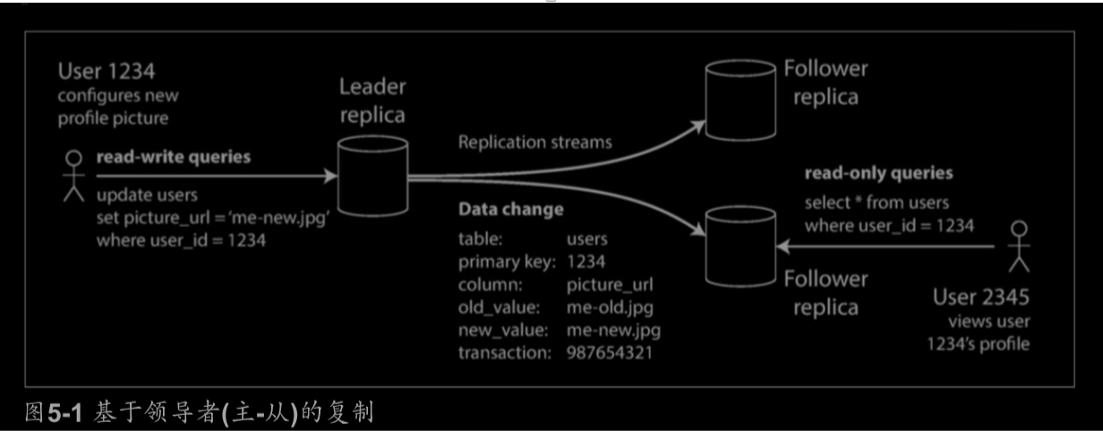
資料分佈在多個節點上通常有兩種方式:複製(Replication)、分割槽(Partitioning)
使用複製的原因:
- 使得資料與使用者在地理上接近(從而減少延遲)
- 即使系統的一部分出現故障,系統還能正常工作
- 擴充套件可以接收讀請求的機器數量(從而提高讀取吞吐量)
複製的資料會隨時間改變,因此處理複製資料的變更是難點,有三種流行的變更復制演算法:
- singer leader(單領導者)
- multi leader(多領導者)
- leaderless(無領導者)
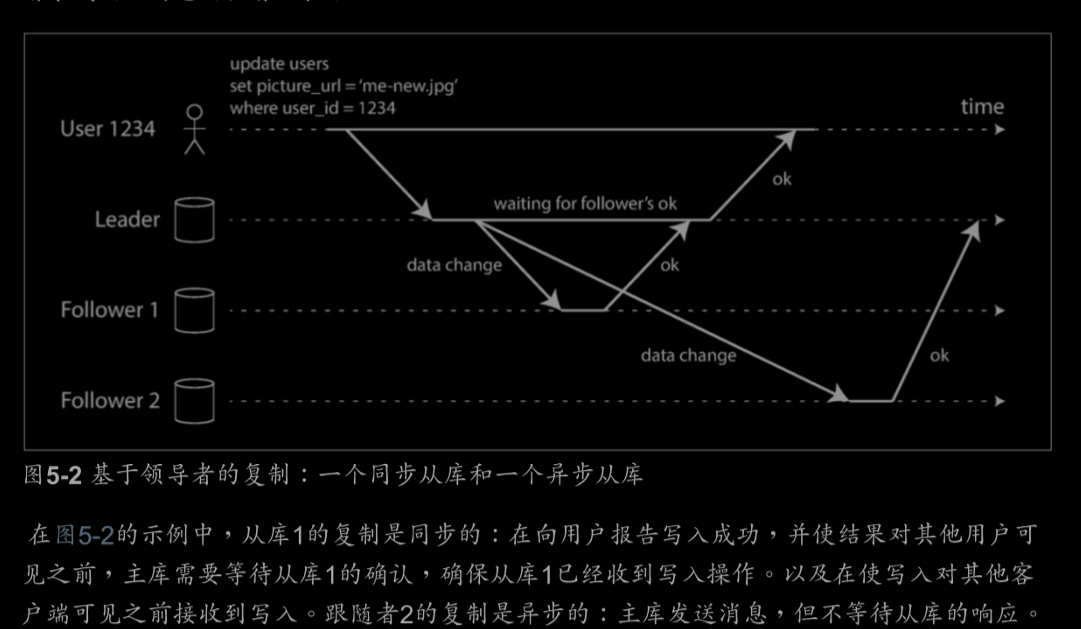
複製系統的一個重要細節:複製是同步還是非同步發生
最終一致性(eventually consistency)

這種情況下,我們需要讀寫一致性(read-after-write consistency),也稱讀己之寫一致性(read-your-writes consistency)

單調讀(Monotonic Reads):
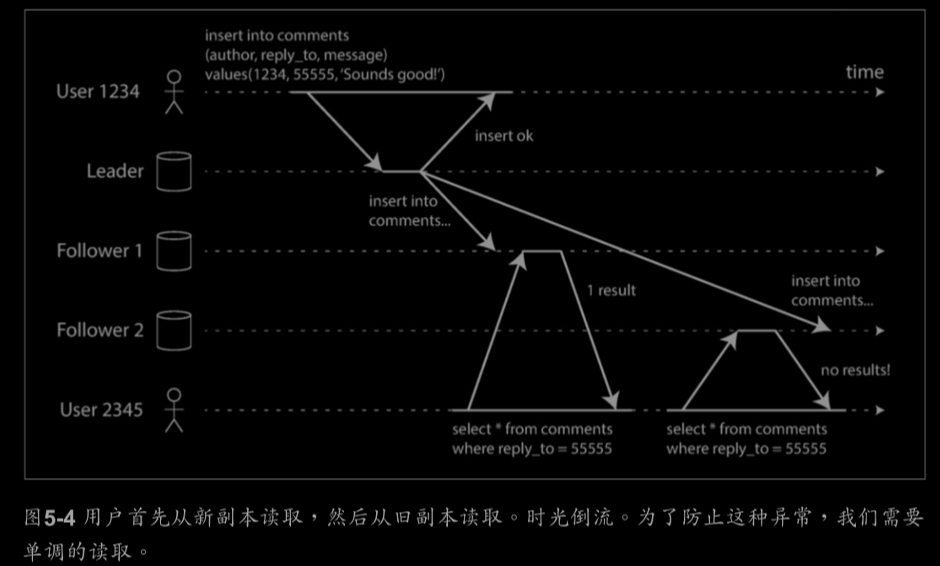
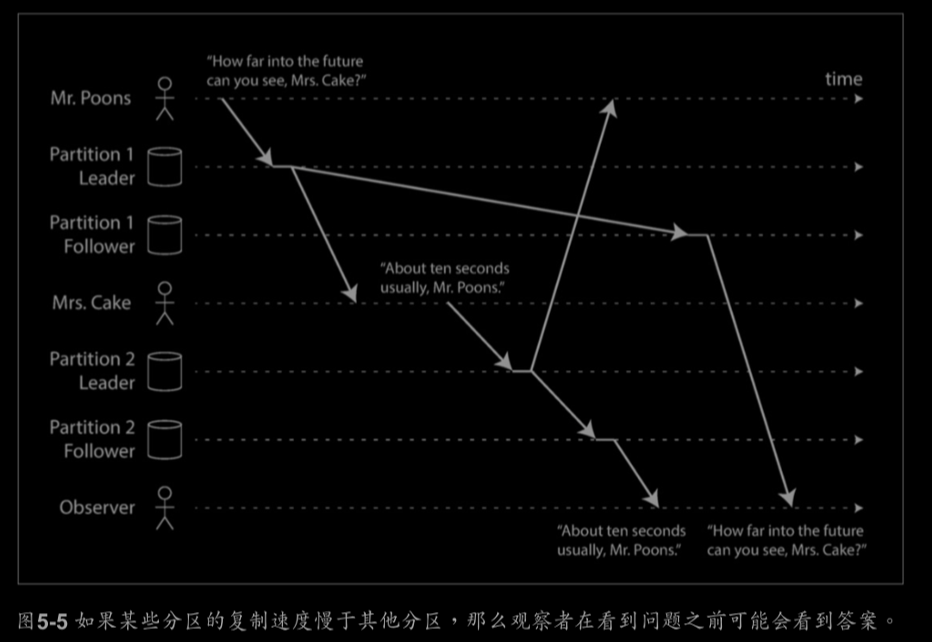
一致字首讀取(Consistent Prefix Reads):
如果一系列寫入按某個順序發生,那麼任何人也會按同樣的順序讀取
The "happens-before" relationship and concurrency(在之前發生與併發)
相關推薦
副本機制與副本同步------《Designing Data-Intensive Applications》讀書筆記6
一致性 不響應 rabbit 故障恢復 logs 啟動 markdown 分布式系統 觸發器 進入到第五章了,來到了分布式系統之中最核心與復雜的內容:副本與一致性。通常分布式系統會通過網絡連接的多臺機器上保存相同數據的副本,所以在本篇之中,我們來展開看看如何去管理和維護這
P2P結構與Quorum機制------《Designing Data-Intensive Applications》讀書筆記8
服務器 遠的 數據系統 接收 圖片 次數 小結 概念 覆蓋 前文涉及到了很多與Leader相關的算法,大家有木有想過,王侯將相,寧有種乎,既然Leader這麽麻煩,幹脆還是采用P2P模型吧,來個大家平等的架構。本篇需要和大家探討的就是多副本下實現民主政治的Quorum機制
數據分區------《Designing Data-Intensive Applications》讀書筆記9
zookeep 組件 搜索 介紹 程序 cas 只有一個 核心技術 熱點 進入到第六章了,我們要開始聊聊分布式系統之中的核心問題:數據分區。分布式系統通常是通過大規模的數據節點來處理單機沒有辦法處理的海量數據集,因此,可以將一個大型數據集可以分布在多個磁盤上,查詢負載可以
事務與隔離級別------《Designing Data-Intensive Applications》讀書筆記10
串行化 clas block atomic 硬件故障 nsis 特性 筆記 額外 和數據庫打交道的程序員繞不開的話題就是:事務,作為一個簡化訪問數據庫的應用程序的編程模型。通過使用事務,應用程序可以忽略某些潛在的錯誤場景和並發問題,由數據庫負責處理它們。而並非每個應用程序
分布式系統的煩惱------《Designing Data-Intensive Applications》讀書筆記11
而不是 例如 有一個 客戶端 每天 不可 解決 通信 由於 使用分布式系統與在單機系統中處理問題有很大的區別,分布式系統帶來了更大的處理能力和存儲容量之後,也帶來了很多新的"煩惱"。在這一篇之中,我們將看看分布式系統帶給我們新的挑戰。 1.故障 當我們在使用單機系統時,
線性一致性與全序廣播------《Designing Data-Intensive Applications》讀書筆記12
拷貝 原理 隔離 來看 這樣的 失效 一個 syn 分布式系 上一篇聊了聊構建分布式系統所面臨的困難,這篇將著重討論構建容錯分布式系統的算法與協議。構建容錯系統的最佳方法是使用通用抽象,允許應用程序忽略分布式系統中的一些問題。本篇我們先聊一聊線性一致性,以及與線性一致性有
分布式系統的一致性算法------《Designing Data-Intensive Applications》讀書筆記13
基礎 我們 時序 中間 服務器 可能 對象 可用性 有用 一致性算法是分布式系統中最重要的問題之一。表面上看,這似乎很簡單,只是讓幾個節點在某些方面達成一致。在本篇之中,會帶大家完整的梳理分布式系統之中的共識算法,來更加深刻的理解分布式系統的設計。 1.原子提交和兩階段
MapReduce與批處理------《Designing Data-Intensive Applications》讀書筆記14
利用 目的 專業 構建 創建 實現邏輯 內容 sign 傳統 之前的文章大量的內容在和大家探討分布式存儲,接下來的章節進入了分布式計算領域。坦白說,個人之前專業的重心側重於存儲,對許多計算的內容理解可能不是和確切,如果文章中的理解有所不妥,願虛心賜教。本篇將和大家聊一聊分
《Designing.Data-Intensive.Applications》筆記
程式通常(至少)使用兩種形式的資料: 1.記憶體中,資料儲存在物件、結構體、列表、陣列、雜湊表、樹等中。這些資料 結構針對CP
《Designing.Data-Intensive.Applications》筆記 三
Two-Phase Locking(兩階段鎖定,2PL) 2PL與2PC是完全不同(兩階段提交)的概念。 事務A讀取了一個物件,
《Designing.Data-Intensive.Applications》筆記 二
Partitioning(分割槽) 對於非常大的資料集,或非常高的吞吐量,僅複製是不夠的:我們需要將資料進行分割槽(partit
《Designing.Data-Intensive.Applications》筆記 四
第九章 一致性與共識 分散式系統最重要的的抽象之一是共識(consensus):讓所有的節點對某件事達成一致。 最終一致性(eve
Data URL scheme 筆記
pst type tin vmx 模式 grv d+ 數據 dpi 0x01起因 今天做CTF的時候,發現一堆數據,大概是這樣的 data:image/jpg;base64,iVBORw0KGgoAAAANSUhEUgAAAIUAAACFCAYAAAB12js8
spring data mongo使用筆記
先列提綱,後續有時間再完善 1.配置 maven依賴 <dependency> <groupId>org.springframework.boot</groupId>
Sound — An API for playing sound data from applications.
https://docs.oracle.com/javase/tutorial/sound/index.html The Java Sound API is a low-level API for effecting and controlling the input and
Designing Multi-Threaded Applications Using Swift
Designing Multi-Threaded Applications Using SwiftBeing an iOS Developer in the automotive industry, I spend a great deal of time working with real time dat
Spring-Data-JPA 學習筆記(一)
作者:zeng1994 一、spring-data-jpa的簡單介紹 SpringData : Spring 的一個子專案。用於簡化資料庫訪問,支援NoSQL 和 關係資料儲存。其主要目標是使資料庫的訪問變得方便快捷。 SpringData
Coursera-Getting and Cleaning Data-Week2-課程筆記
按照Quiz知識點來的筆記 1.API 視訊裡介紹了用httr包讀取twitter資料,在httr Demo頁有其讀取twitter, facebook, google,github等的demo程式碼。 在使用httr包前,都要到相應網站去註冊API,獲得訪問許可權,httr裡訪問資料的方式基本都是
Coursera-Getting and Cleaning Data-week1-課程筆記
課程概述 Getting and Cleaning Data是Coursera資料科學專項的第三門課,有中文翻譯。但是由於中文區討論沒有英文區熱鬧,以及資料積累,強烈建議各位同時選報中文專案和英文專案,可以互相匹配學習。 Week1的課程概括下來,主要介紹了getting and cleaning d
《python for data analysis》筆記三--Numpy基礎:arrays和向量化計算2
繼續Numpy基礎... 1. Fancy Indexing 指的是用一個整數array來當做index下標,比如:arr[[4,3,0,6]] ,中間的那個array就是一個fancy indexing形式。也可以是負數形式,如arr[[-3,-5,-7]]; 當傳進的引