go監控方案(1) -- 概述
概述
為什麼需要監控
在編寫應用程式的時候,通常會記錄日誌以便事後分析,在很多情況下是產生了問題之後,再去檢視日誌,是一種事後的靜態分析。 在很多時候,我們可能需要了解整個系統在當前,或者某一時刻執行的情況,比如當前系統中對外提供了多少次服務,這些服務的響應時間是多少, 隨時間變化的情況是什麼樣的,系統出錯的頻率是多少。這些動態的準實時資訊對於監控整個系統的執行健康狀況來說很重要。
由於業務系統數量大,每天都會產生大量的系統日誌和業務日誌,單流式業務的一臺伺服器產生的日誌達400M 想直接檢視內容開啟可能幾分鐘, 而且內容之多根本無法檢視,給開發和運維帶來諸多不便,現業務都是分散式的,日誌也是分佈在每臺伺服器上, 所以檢視日誌和統計更是效率低下。實時收集分佈在不同節點或機器上的日誌,供離線或線上查閱及分析來提升工作效率的需求異常迫切,
這些動態的準實時資訊對於監控整個系統的執行健康狀況來說很重要。
Profiling特別重要。如果能有一個特別強大的Profiling系統,就知道整個系統在哪個地方,哪臺機器上,花了多少CPU、記憶體、磁碟IO或者網路頻寬等資源,才能知道優化什麼地方效益最大。
監控需要的資訊從哪裡獲得?
這些資訊需要資料作為基礎直接獲得或者計算獲得,那麼實時資料怎麼去獲取,什麼標準來作為測量標準。也就是資訊採集的時候,怎麼去獲得。如下面這些實時資料如何獲得
- 響應時間:使用者傳送一個請求到使用者接受伺服器返回響應的這段時間就是響應時間
- 吞吐量:單位時間內系統處理的客戶端請求數量
- 併發使用者數量: 某一個時刻同事向系統提交請求的使用者數
- TPS: 每秒事務數
- PV: 訪問一個URL,產生一個PV
- UV: 使用者訪問站點的所有頁面算一個UV
整套方案需要使用到的技術
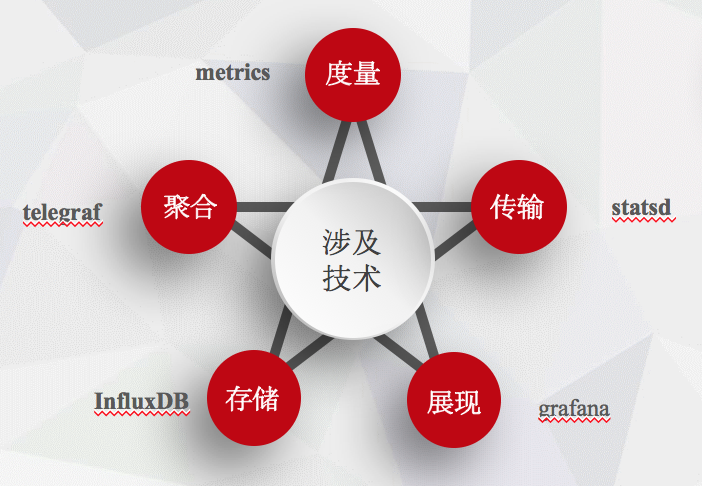
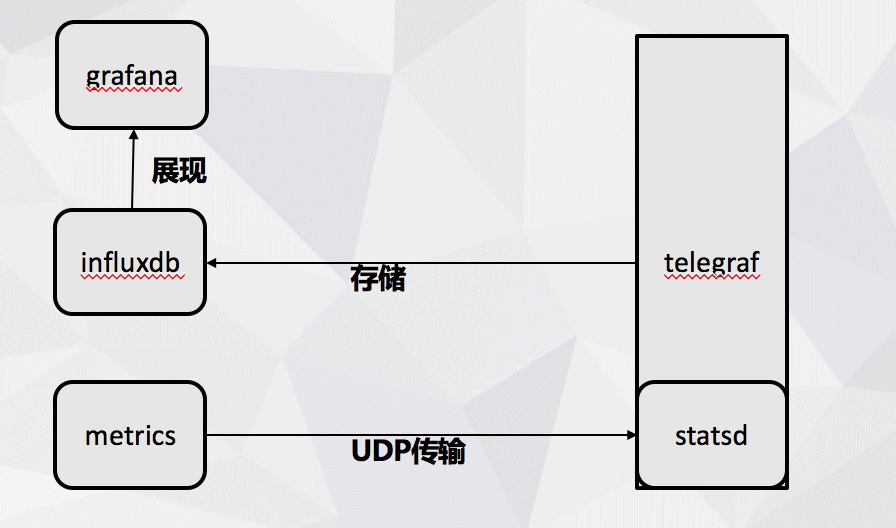
- metrics: 專案程式碼中監控資訊採集使用, 支援gc、mem 等資訊收集
- statsd: 使用statsd進行udp資料的傳輸,
- telegraf: 專案外部資料收集使用telegraf
- influxdb: 使用該時序資料進行資料儲存
- grafana: 進行資料展示
因為以前沒有涉及過監控相關的技術,所以在做的時候碰到各種問題,這裡記錄一下這個過程踩過的坑。
當時做的時候,我的主要是想使用metrics 提供的度量作為資料採集的標準,然後將資料寫入influxdb裡面,然後grafana進行展現就好了,但是git上使用的這個metrics 只提供TCP 連線influxdb的方式。 所以滿足不了我的需要。
TCP 因為要握手所以對效能有影響, 想使用UDP 作為傳輸方式, 然後找到 statsd 是支援TCP/UDP 方式進行傳輸的,但是 statsd 支援支援的型別很少,並不能完全滿足採集到的metrics 支援的這些度量標準。 所以需要將metrics 採集以後 複雜的型別轉換成 statsd 基礎型別進行傳輸。
原有系統有用telegraf 支援docker外部的資訊採集,並且可以新增statsd外掛,這樣既可以採集到程式碼之外的效能指標的,也可以方便的將statsd 傳輸資料存入influxdb中, 然後再用grafana 作為展示面板,將資料展現出來,就完成了整套方案。
方案大致流程