
OpenResty 社群王院生:APISIX 的高效能實踐
2019 年 7 月 6 日,OpenResty 社群聯合又拍雲,舉辦 OpenResty × Open Talk 全國巡迴沙龍·上海站,OpenResty 軟體基金會聯合創始人王院生在活動上做了《APISIX 的高效能實踐》的分享。
OpenResty x Open Talk 全國巡迴沙龍是由 OpenResty 社群、又拍雲發起,邀請業內資深的 OpenResty 技術專家,分享 OpenResty 實戰經驗,增進 OpenResty 使用者的交流與學習,推動 OpenResty 開源專案的發展。活動將陸續在深圳、北京、武漢、上海、成都、廣州、杭州等城市巡迴舉辦。

王院生,OpenResty 社群、OpenResty 軟體基金會聯合創始人,《OpenResty 最佳實踐》主要作者,APISIX 專案發起人和主要作者。
以下是分享全文:
大家好,我是王院生,很高興來到上海。首先做下自我介紹,我於 2014 年加入奇虎 360,在那時認識了 OpenResty,此前我是一個純粹的 C/C++ 語言開發者。在 360 工作期間,利用工作閒暇時間寫了《OpenResty 最佳實踐》,希望能影響更多的人正確掌握 OpenResty 入門。2017 年我作為技術合夥人和春哥(章亦春,agentzh)一起創業。今年我個人的重心有所調整並在今年三月份離職,準備將更多精力投入到開源上,於是發起了 APISIX 這個專案,企業宗旨是依託開源社群,致力於微服務 API 相關技術的創新和實現。
什麼是 API 閘道器
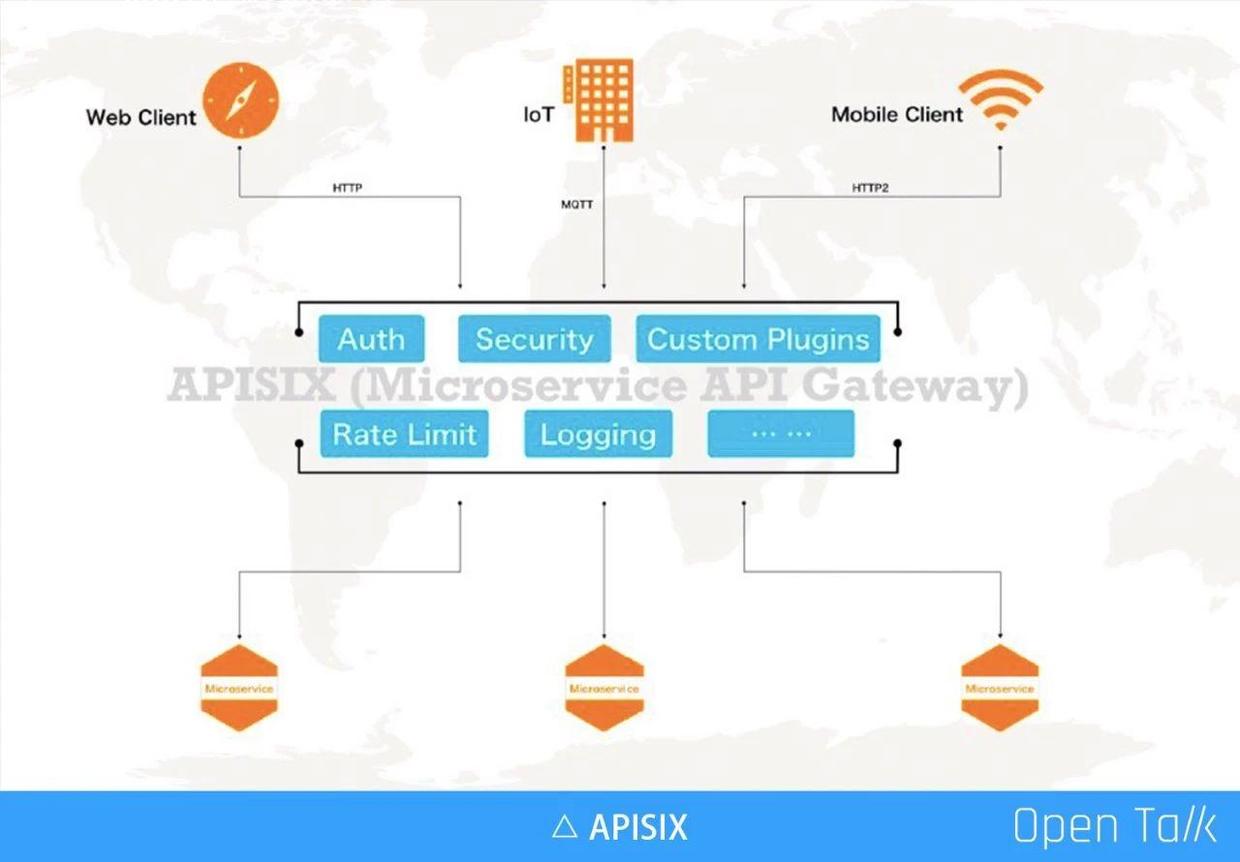
API 閘道器的地位越來越重要,它幾乎劫持了所有流量,內外之間完成了使用者的安全控制、審計,通過自定義外掛的方式滿足企業自身特定需求,最常見的自由身份認證等。隨著服務在數量和複雜度上的不斷增長,更多的企業採用了微服務的方式,這時通過 API 閘道器來完成統一的流量管理和排程就非常有必要。
微服務閘道器和傳統意義上的 API 閘道器有一些不同,主要包括下面幾點:
- 動態更新:在微服務之前,服務不像現在這樣經常來回地變化。比如微服務需要做橫向擴充,或者故障恢復、熱備、切換等,IP 、節點等變動更加頻繁。舉例如微博上一旦出現了爆點事件,就急速擴充計算點,必須要非常快地擴充新機器來扛壓。波峰波谷變化明顯,分鐘級別的機器動態管理,已經越發是常態。
- 更低延遲:通常動態就意味著可能會做一些延遲(複雜度增加),在微服務裡面,對於延遲要求比較高,尤其對於現在的使用者體驗,超過 1 秒以上的延遲是完全不可接受的。
- 使用者自定義外掛:API 閘道器是給企業使用者使用的,它一定存在私有邏輯(比如特殊的認證授權等),所以微服務閘道器必須能夠支援企業使用者自定義外掛。
- 更集中的管理 API:如前面所說 API 閘道器劫持了使用者的所有流量,所以用閘道器來做統一的 API 管理是非常必要的。在閘道器角度可以看到 API 是如何設計,是否存在延遲、安全問題,以及響應速度和健康資訊等。
我們要做的微服務 API 閘道器產品,除了上面的基本要求,還有一些是我們區別於其他人的:
- 通過社群聚焦:通過開源方式聚焦有共同需求的人群,讓更多不同公司的人可以一起協作,共同打磨更好的產品,減少冗餘開發。
- 簡潔的 core:產品的核心必須是非常簡潔的,如果核心複雜,會使得大家的上手成本高很多,望而卻步肯定不是我們期望的。
- 可擴充套件性、頂級效能、低延遲:這幾項都是要同時嚴格保障的,也是我們會花主要精力保證的。目前 APISIX 專案的效能比空跑 OpenResty 只低 15%,這點還是非常值得傲嬌的。
APISIX 高效能微服務閘道器
APISIX 架構與功能
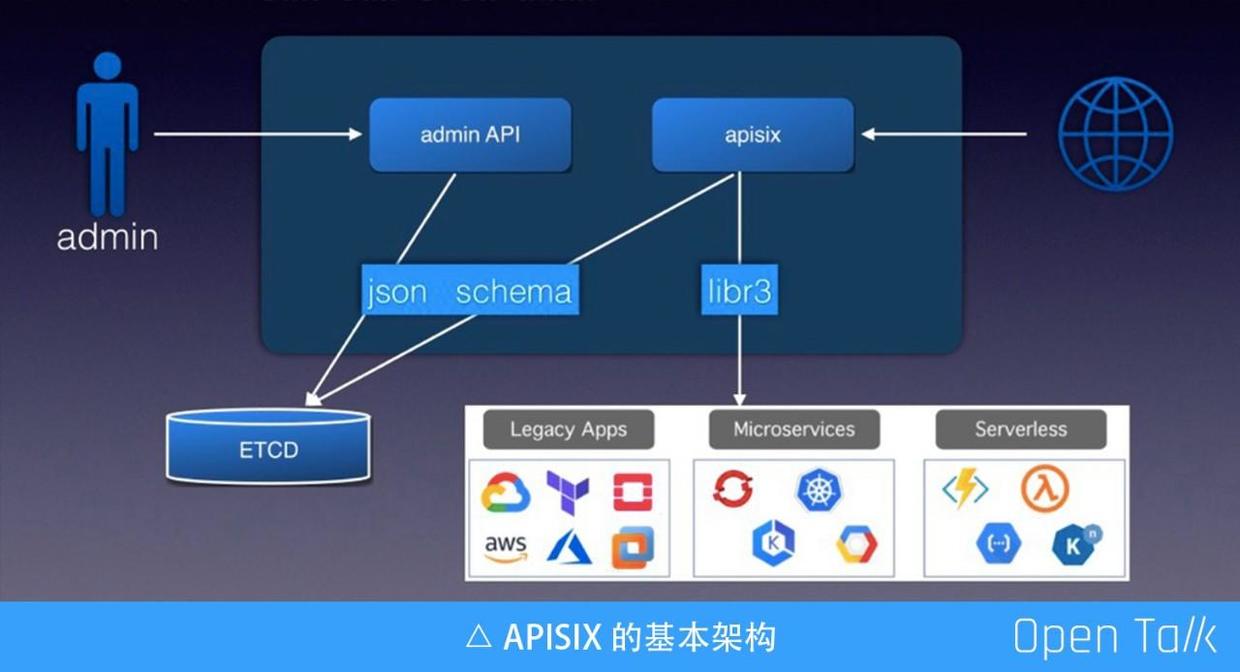
上圖是 APISIX 的基本架構,羅列用到的幾個基本元件。其中包括 ETCD 可以完成配置儲存,由於 ETCD 可以走叢集,所以我們可以借用它完成動態伸縮、高可用叢集等。ETCD 資料支援通過 watch 的方式增量獲取,使得 APISIX 節點規則更新可以做到毫秒級,甚至更低。APISIX 自身是無服務狀態的,所以方便橫向擴充。
另一個元件是 JSON Schema,它是一個標準協議,主要用來驗證資料的有效性。JSON Schema 目前對外公開有四個不同版本,我們最終選用 RapidJSON,因為他對這四個版本都有相對完整的支援。
圖中的 Admin API 和 APISIX 可以放在一起,也可以分開。Admin API 接收使用者提交的請求,在請求引數儲存到 ETCD 之前,會使用 JSON Schema 做一次完整校驗,有了校驗可以確定到 ETCD 裡的都是有效資料。
上圖右側是接收外部使用者的真實流量,APISIX 從 ETCD 中訂閱所有配置規則,拿到配置規則後給到下面的路由引擎(libr3),目前預設使用的路由引擎是 libr3,我之前在武漢的分享中進行過詳細介紹(https://www.upyun.com/opentalk/428.html)。 libr3 是一個路由引擎實現,基於字首樹,由於他還支援正則,所以效率非常高的,同時功能也很強大。
APISIX 的 v0.5 版本具備以下功能:

APISIX 的效能

通常來說,引入了前面提到的十幾項功能,會伴隨著效能的下降,那麼究竟下降了多少呢?這裡我做了一個性能的測試對比。如上圖,右側是我為了測試寫的一個虛假的服務,這個服務裡面空空如也,只是把 ngx_lua 裡的一些變數拿出來,然後傳給了什麼都不做的 fake_fetch,後面的 http filter、log 階段等一樣,沒有任何計算量。
然後對 APISIX 和右邊的虛假服務分別跑壓力測定,對比結果發現 APISIX 的效能僅僅下降了 15%,也就是說在接受了 15% 的效能下降的同時,就可以享受前面提到的所有功能。
說一下具體數值,這裡使用的是阿里雲的計算平臺,單 worker 下可以跑到 23-24k QPS,4 worker 可以跑到 68k 的 QPS。
APISIX 目前的狀態
目前最新版本是 v0.5,架構是基於 ETCD+libr3+RapidJSON。這個版本加的最多的是程式碼覆蓋率,v0.4 版本程式碼覆蓋率不超過 5%,但最新版本中程式碼覆蓋率達到 70%,這其中 95% 是核心程式碼,周邊的程式碼覆蓋率相對較低,主要是外掛的相關測試有所欠缺。
原本計劃在 0.5 版本上線管理介面功能,這樣可以降低入門門檻,但是遺憾的是目前還沒開發完成,這與我們自身專業有關係,不擅長做前端介面,需要藉助前端的專家幫我們實現,我們計劃會在 0.6 的版本上線(注:目前已經發布了 v0.6 版本:https://github.com/iresty/apisix/blob/master/CHANGELOG_CN.md#060)。
OpenResty 程式設計哲學與優化技巧
我從 2014 年開始做 OpenResty 開發,至今已經有六年了。在 OpenResty 的領域裡,它的哲學是要學會大事化小,小事化了,因為 Nginx 的記憶體管理方式是把所有的請求記憶體預設放到一個記憶體池裡,請求退出的時再把記憶體池銷燬。如果不能很快地一進一出,它就會不停申請,最後釋放時資源損耗很大,這是 Nginx 不擅長的。所以用 OpenResty 做長連線就需要非常小心,避免把記憶體池搞大。
此外,要儘可能少地建立臨時物件。這裡所指的臨時物件有兩類,一類是 table 類,一類是字串拼接,比如某兩個變數拼接產生新的字串,這個看似在其他很多語言都沒有問題,但在 OpenResty 裡需要儘量少做這種操作。Lua 語言雖然簡單,但也是門高階語言,攜帶了優良的 GC ,讓我們無需關心所有變數的生命週期,只負責申請就好了,但如果濫用臨時變數等,會讓 GC 比較忙碌,付出代價是整體執行效能不高。Lua 擅長動態和流程控制,如果遇到硬核的 CPU 運算任務,還是推薦交給 C/C++ 實現。
今天和大家分享優化技巧,主要還是如何寫好 Lua,畢竟他的受眾群體更多。在 APISIX 的 core 中,我們使用了一些比較特別的優化技巧,下面逐一給大家介紹。
技巧一:delay_json
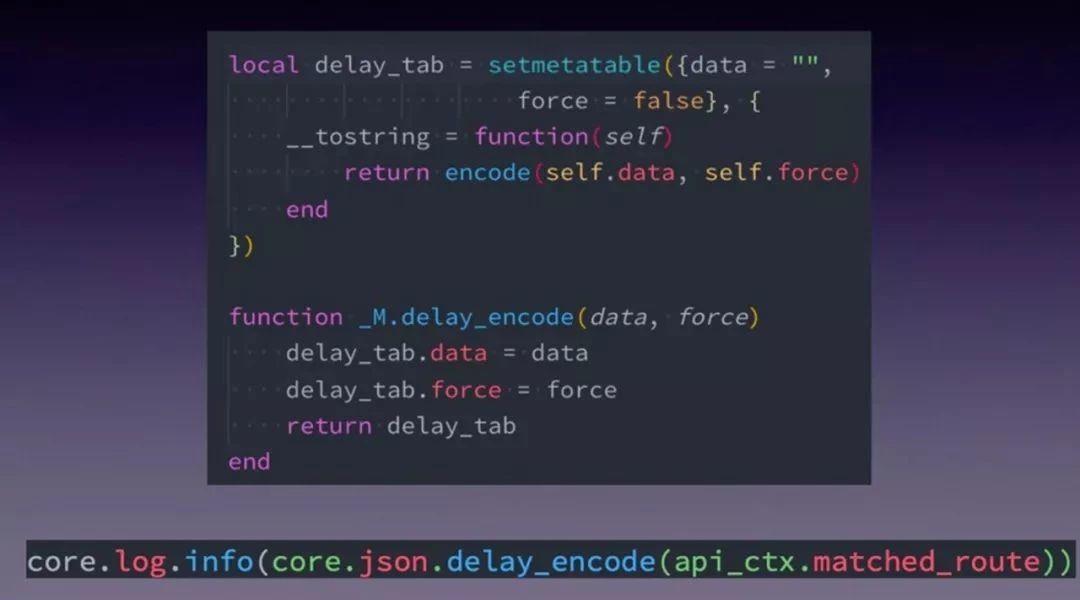
先說一下場景:比如上面的這行日誌呼叫,如果當前日誌級別是 info ,我們期望會正常 json encode;而當是 error 級別,我們就不期望發生 json encode 操作,如果能自動跳過是最完美了。那我們如何近似的實現這個目的呢?
我們看一下 delay_encode 的實現原始碼,首先用元方法過載了 tostring ,下面 delay_encode 只是對 delay_tab 的兩個物件 data 和 force 做了賦值,然後沒有做其他的事情,這與大家平時看到的 json encode 方法都不一樣。因為真正在寫日誌時,如果給定的引數是 table,在 OpenResty 裡會把他轉成 string 的,過程是檢查是否有 tostring 的元方法註冊,如果有就調這個方法把它轉換成字串。有了上面的封裝,我們就在高效能和易用性上做了很好的平衡。
技巧二:HASH vs 字首樹 vs 遍歷
- Lua table 的 HASH:效能最好的匹配方式,缺點是隻能做全量匹配。
- 字首樹:藉助 libr3 完成字首等高階匹配(支援正則)。
- 遍歷:永遠是最糟糕的。
在 APISIX 的世界裡,我把 HASH 和字首樹做了融合,如果你的請求和路由規則不包含高階規則匹配,會預設走 HASH 來保證效率;但如果有模糊匹配邏輯,則使用字首樹。
技巧三:ngx.log 是 NYI
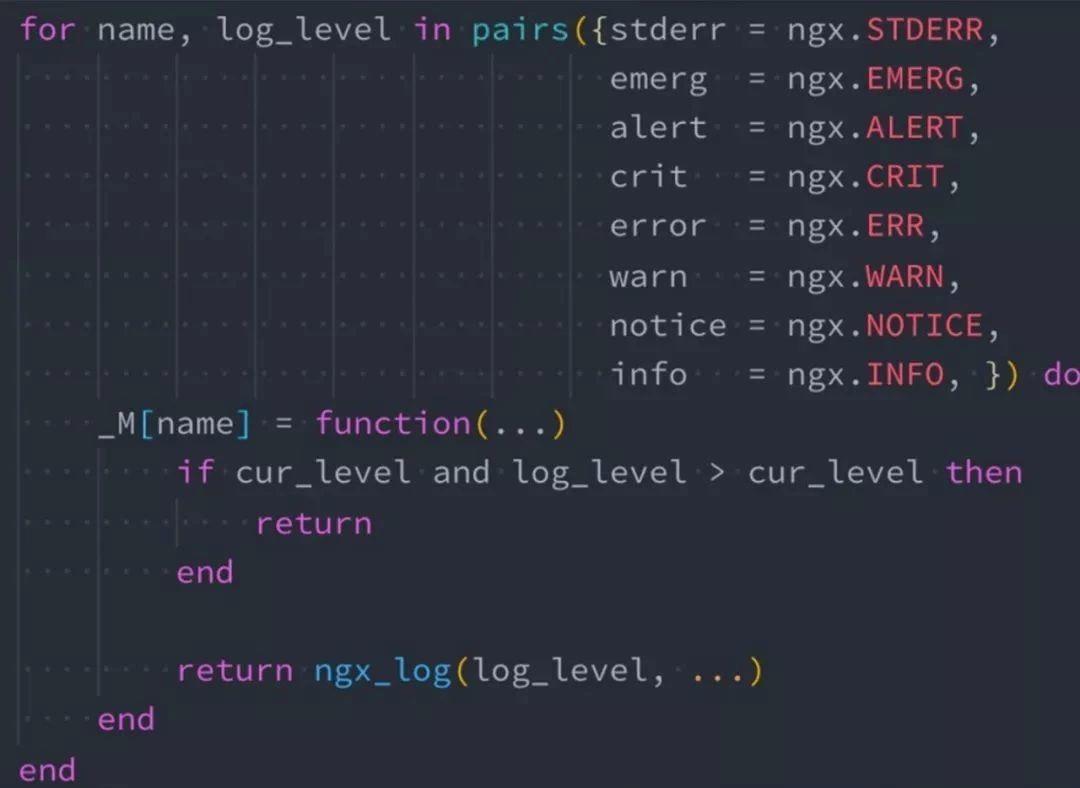
因為 ngx.log 是 NYI,所以我們要儘量減少下面這段程式碼的觸發頻率:
return ngx_log(log_level,…)要降到最低,需要判斷當前日誌級別,如果當前的日誌級別和你輸入的日誌級別存在大小比值關係,發現不需要輸入就直接 return。避免出現日誌處理完,傳到 Nginx 核心後再發現不需要寫日誌,這樣就會浪費非常多的資源。
前面提到的壓力測試,都是把日誌打到 error 級別,加了非常多的除錯程式碼並且保留不刪,這些測試程式碼的存在完全不會影響效能結果。
技巧四:gc for cdata and table
場景:當某個 table 物件被系統回收時,希望觸發特定邏輯以釋放關聯資源。那麼我們如何給 table 註冊 gc 呢?請參考下圖示例:
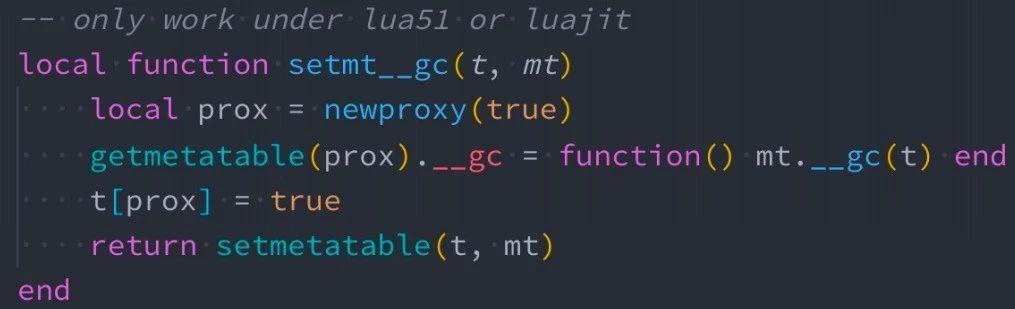
當我們無法控制 Lua table 的整個生命週期,可以用上圖的方法去註冊一個 GC,當 table 物件沒有任何引用時會觸發 GC,釋放關聯資源。
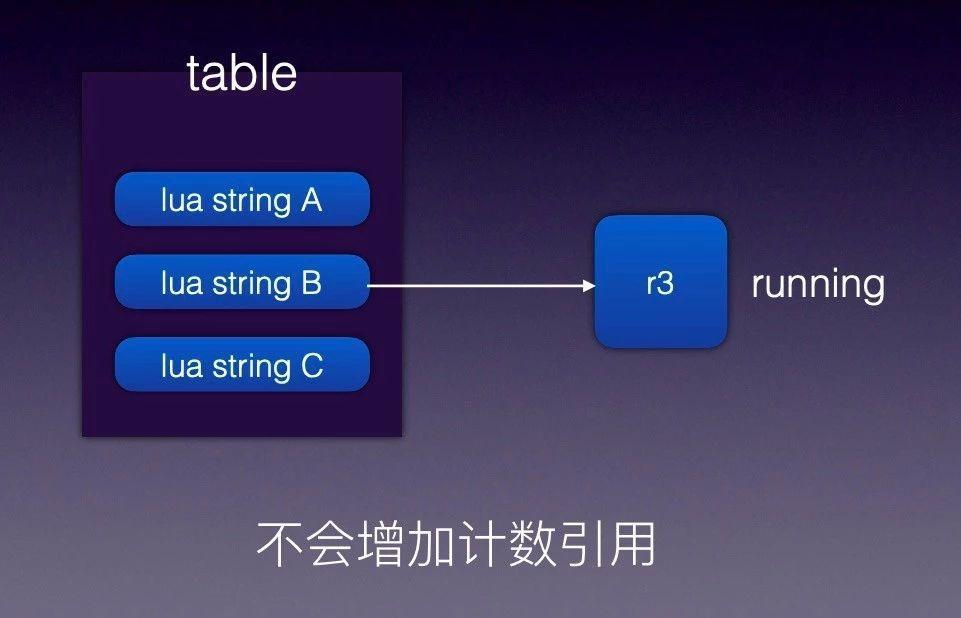
技巧五:如何保護常駐記憶體的 cdata 物件
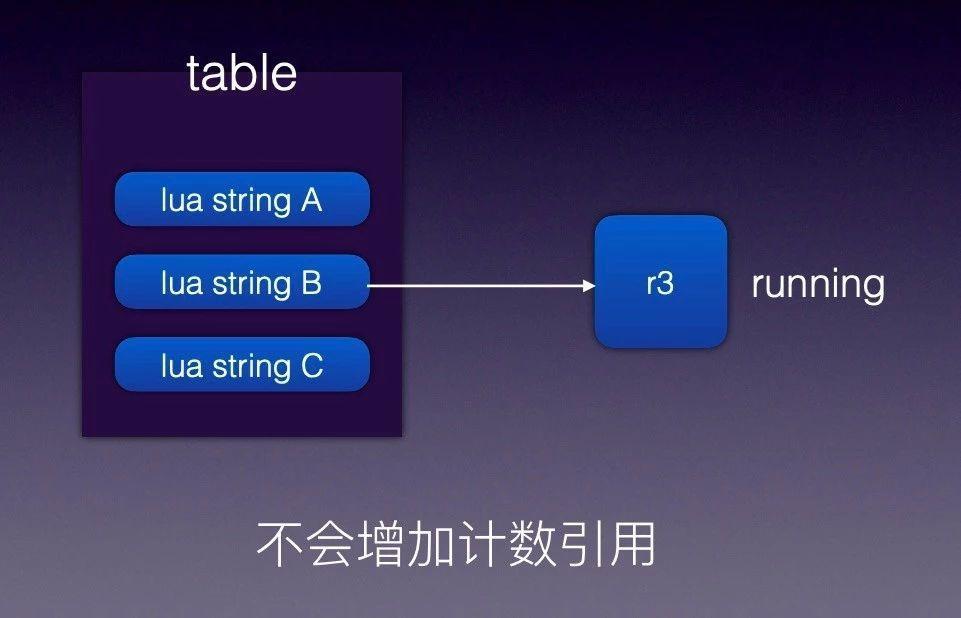
我們在使用 r3 這個 C 庫時遇到這麼一個問題:我們給 r3 新增很多路由規則,然後生成 r3 tree,如果規則沒有變化 r3 將被反覆使用,由於 r3 內部沒有申請額外的記憶體儲存,只是引用指標地址。但外面傳入的 Lua 變數可能是臨時變數,引用計數為 0 後會被 Lua GC 自動回收。導致的現象是 r3 內部引用的原有記憶體地址內容突然發生變化,最後致使路由匹配失敗。
知道了問題原因,解決方法就比較簡單了,只需要避免變數 A 提前釋放,讓 Lua 裡面變數 A 的生命週期和 r3 物件的生命週期保持一致即可。
技巧六:ngx.var.* 是比較慢的
大家知道 C 是不支援動態的,它是編譯性語言。ngx.var.* 的內部實現可以檢視 Nginx 原始碼,或者通過火焰圖的方式可以看到他內部的實現方式。為了完成動態獲取變數,內部必須通過一次 hash 查詢,到後用內部的規則把變數值讀出。
解決方案是用上圖這個庫(http://github.com/iresty/lua-var-nginx-module),非常簡單沒有技術含量的辦法。比如要獲取客戶端的 IP,在 C 裡面直接把程式碼摘出來,然後通過 Lua FFI 方式讀取變數的值,就是這麼一段小程式碼可以讓 APISIX 效能有 5% 提升。這麼做缺點是必須要對 OpenResty 編譯時新增這個第三方模組,上手成本略高。
技巧七:減少每請求的垃圾物件
我們要儘可能降低每請求產生的垃圾物件的數量,作為 OpenResty 開發者,如果把這句話理解透徹,基本上可以進階到前 50% 的行列。
減少不必要的字串的拼接,並非意味著在需要做拼接字串的時候不要拼接,而是需要在腦子裡一直有這個意識,把無效的拼接降低下來,當這些小細節累積下來,效能提升就會非常大。
技巧八:重用 table

首先介紹下初級版的 table.clear。當需要使用一個臨時 table,大家習慣性的寫法是
local t ={}我們來聊聊這麼做的缺點,如果在開頭建立了一個臨時的 table t,當函式退出的時候,t 會被回收;下次再進來這個函式,又會產生一個臨時的 table t。在 Lua 世界,table 的產生和銷燬是非常耗資源的,因為 table 是一個複雜物件,它不像 number、字串等簡單物件,申請和釋放可以用一個結構體搞定,它會讓你的 GC 一下子變得非常忙碌。
如果 worker 裡只需要一個唯一例項 table 物件,那麼就可以使用 table.clear 方式來反覆使用這個臨時表,比如上圖的臨時表 local_plugins_hash。
重用 table :進階版 table.pool
有些 Lua table 的生命週期是每請求的,通常是請求進入申請物件,請求退出釋放物件,這時候使用 table.pool 會非常合適。tablepool 中文翻譯過來是表池,裡面放的是可以重用的 table。官方文件可以到 https://github.com/openresty/lua-tablepool#synopsis 檢視,結合 APISIX 的業務使用程式碼,更容易理解。
在 APISIX 中最集中使用的是兩個地方,除了上圖這裡做回收,還有是申請的地方。在回收之後,這些 table 可以被其他請求所複用,由 tablepool 做統一控制,在 pool 裡維持的物件可能就固定的幾十、幾百個,會反覆使用,不存在銷燬的情況。這個技巧的正確使用,效能至少可以提升 20%,提升效果非常明顯。
技巧九:Irucache 的正確姿勢
簡單介紹下 Irucache,Irucache 可以完成在 worker 內的資料的快取和複用,Irucache 有一個非常大的優勢是可以儲存任何物件。而共享記憶體則是完成不同 worker 之間的資料共享,但它只能儲存簡單物件,有些東西是不能跨 worker 共享,比如 function、cdata 物件等。
對 Irucache 進行二次封裝,封裝的內容主要包括:
- key 要儘量短、簡單:我們在寫 key 時最重要的是要簡單,key 最糟糕的設計是裡面東西很長,但是有用資訊不多。key 理論上大家都喜歡用字串,但他可以是 table 等物件,key 儘量做到明確,只包含你感興趣的內容,能省略的儘量省略,降低拼接成本。
- version 可降低垃圾快取:這點算是我在做 APISIX 的突破:提取出了 version, Irucache+ version 這套組合,可以極大地降低垃圾快取。
- 重用 stale 狀態的快取資料。

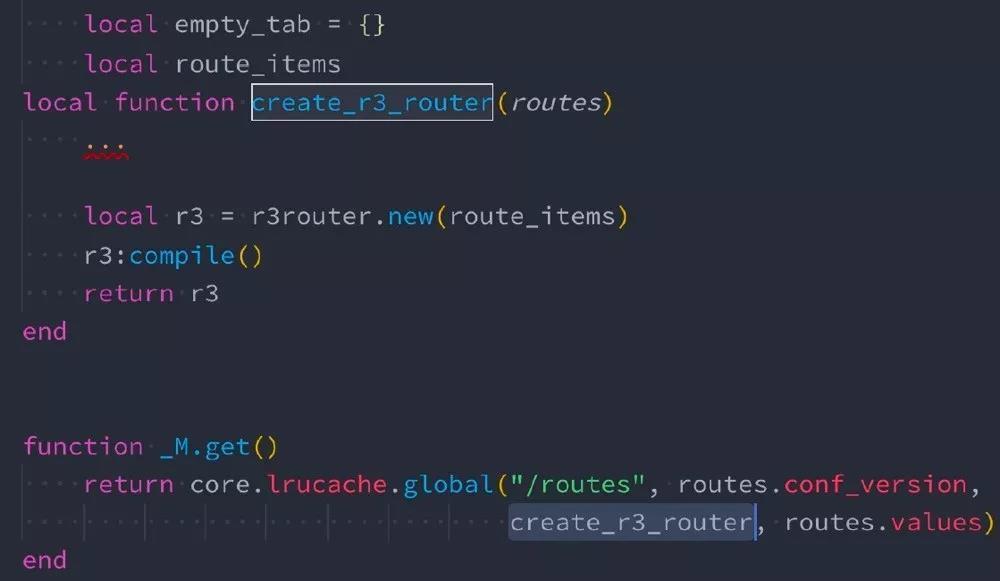
上圖是 lrucache 的封裝,從下往上看,key 是 /routes,它跟的版本號是 conf_version,global 函式裡做的事情是根據 key+version 的方式,去查詢有無陳舊資料的快取,如果有就直接返回,如果沒有就調 creat_r3_router 完成建立,creat_r3_router 是負責建立一個新的物件,它只接受一個傳參 routes,這個傳參是由 routes.values 傳進去的。
這層封裝,把 Irucache new、數量等都隱藏起來,這樣很多東西我們看不到,當我們需要自定義的時候可能還是需要關心這些。APISIX 為了簡化外掛開發者對各種東西的理解,所以必須要做一層封裝,簡化使用。
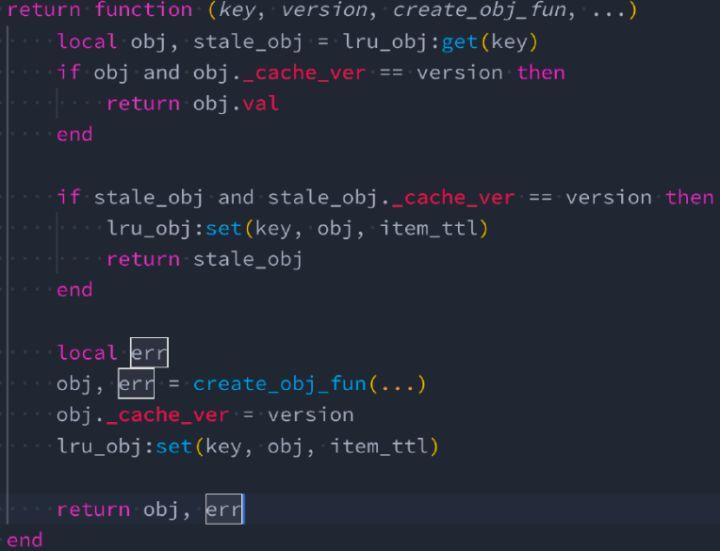
△ lrucache 最佳實踐⽤例
上圖是用 version 降低垃圾快取、重用 stale 狀態的快取資料,這 Irucache 的二次封裝的程式碼。首先來看第二行,根據 key 去快取裡面取物件,然後把物件的 cache_ver 拿出來和當前傳入的 version 做比較,如果相同則判定這個快取物件一定是可用的。
往下多了 stale_obj,stale_obj 在文件裡面說明的比較少,它只有在一種情況會發生:快取物件在 Irucache 中已經被淘汰了,但是它只是到了淘汰的邊緣,還沒有完全被扔掉。上圖中通過陳舊資料的 cache_ver 與進來的 version 做比較,如果 version 一致那就是有效的。所以只要源頭的資料沒有變化,就可以再次使用。這樣我們就可以複用 stale_obj 從而避免再次建立新的物件。
到這裡可以解釋一下前面提到的:version 可降低垃圾快取。如果沒有 version,我們需要把 version 寫到 key 裡面,每次 version 變化都會產生一個新的 key,那些被淘汰的舊資料會一直存在,沒辦法剔除掉。同時意味著 Irucache 裡面的物件數會不停增加。而我們前面的方式是保證 key 如果是一個物件,只會有一個 table 與它對應,不會根據不同的 version 產生不同的物件快取,進而降低快取總數。
以上是我今天的全部分享,謝謝大家!
演講視訊及PPT下載傳送門:
APISIX 的高效能實