
Apache Flink 零基礎入門(一):基礎概念解析
Apache Flink 的定義、架構及原理
Apache Flink 是一個分散式大資料處理引擎,可對有限資料流和無限資料流進行有狀態或無狀態的計算,能夠部署在各種叢集環境,對各種規模大小的資料進行快速計算。
Flink Application
瞭解 Flink 應用開發需要先理解 Flink 的 Streams、State、Time 等基礎處理語義以及 Flink 兼顧靈活性和方便性的多層次 API。
- Streams,流,分為有限資料流與無限資料流,unbounded stream 是有始無終的資料流,即無限資料流;而 bounded stream 是限定大小的有始有終的資料集合,即有限資料流,二者的區別在於無限資料流的資料會隨時間的推演而持續增加,計算持續進行且不存在結束的狀態,相對的有限資料流資料大小固定,計算最終會完成並處於結束的狀態。
- State,狀態是計算過程中的資料資訊,在容錯恢復和 Checkpoint 中有重要的作用,流計算在本質上是 Incremental Processing,因此需要不斷查詢保持狀態;另外,為了確保 Exactly- once 語義,需要資料能夠寫入到狀態中;而持久化儲存,能夠保證在整個分散式系統執行失敗或者掛掉的情況下做到 Exactly- once,這是狀態的另外一個價值。
- Time,分為 Event time、Ingestion time、Processing time,Flink 的無限資料流是一個持續的過程,時間是我們判斷業務狀態是否滯後,資料處理是否及時的重要依據。
- API,API 通常分為三層,由上而下可分為 SQL / Table API、DataStream API、ProcessFunction 三層,API 的表達能力及業務抽象能力都非常強大,但越接近 SQL 層,表達能力會逐步減弱,抽象能力會增強,反之,ProcessFunction 層 API 的表達能力非常強,可以進行多種靈活方便的操作,但抽象能力也相對越小。
Flink Architecture
- Flink 具備統一的框架處理有界和無界兩種資料流的能力
- 部署靈活,Flink 底層支援多種資源排程器,包括 Yarn、Kubernetes 等。Flink 自身帶的 Standalone 的排程器,在部署上也十分靈活。
- 極高的可伸縮性,可伸縮性對於分散式系統十分重要,阿里巴巴雙 11 大屏採用 Flink 處理海量資料,使用過程中測得 Flink 峰值可達 17 億 / 秒。
- 極致的流式處理效能。Flink 相對於 Storm 最大的特點是將狀態語義完全抽象到框架中,支援本地狀態讀取,避免了大量網路 IO,可以極大提升狀態存取的效能。
Flink Operation
-
Flink 具備 7 X 24 小時高可用的 SOA(面向服務架構),原因是在實現上 Flink 提供了一致性的 Checkpoint。Checkpoint 是 Flink 實現容錯機制的核心,它週期性的記錄計算過程中 Operator 的狀態,並生成快照持久化儲存。當 Flink 作業發生故障崩潰時,可以有選擇的從 Checkpoint 中恢復,保證了計算的一致性。
-
Flink 本身提供監控、運維等功能或介面,並有內建的 WebUI,對執行的作業提供 DAG 圖以及各種 Metric 等,協助使用者管理作業狀態。
Flink 的應用場景:Data Pipeline
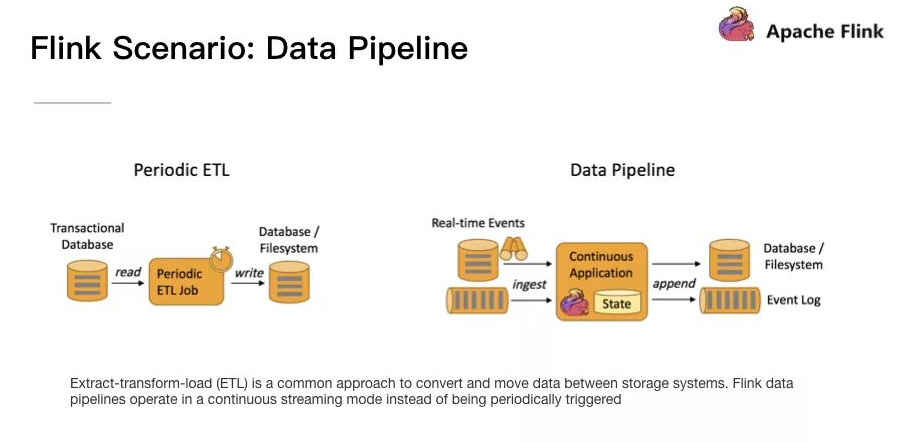
Data Pipeline 的核心場景類似於資料搬運並在搬運的過程中進行部分資料清洗或者處理,而整個業務架構圖的左邊是 Periodic ETL,它提供了流式 ETL 或者實時 ETL,能夠訂閱訊息佇列的訊息並進行處理,清洗完成後實時寫入到下游的 Database 或 File system 中。場景舉例:
- 實時數倉。當下遊要構建實時數倉時,上游則可能需要實時的 Stream ETL。這個過程會進行實時清洗或擴充套件資料,清洗完成後寫入到下游的實時數倉的整個鏈路中,可保證資料查詢的時效性,形成實時資料採集、實時資料處理以及下游的實時 Query。
- 搜尋引擎推薦。搜尋引擎這塊以淘寶為例,當賣家上線新商品時,後臺會實時產生訊息流,該訊息流經過 Flink 系統時會進行資料的處理、擴充套件。然後將處理及擴充套件後的資料生成實時索引,寫入到搜尋引擎中。這樣當淘寶賣家上線新商品時,能在秒級或者分鐘級實現搜尋引擎的搜尋。
Flink 應用場景:Data Analytics
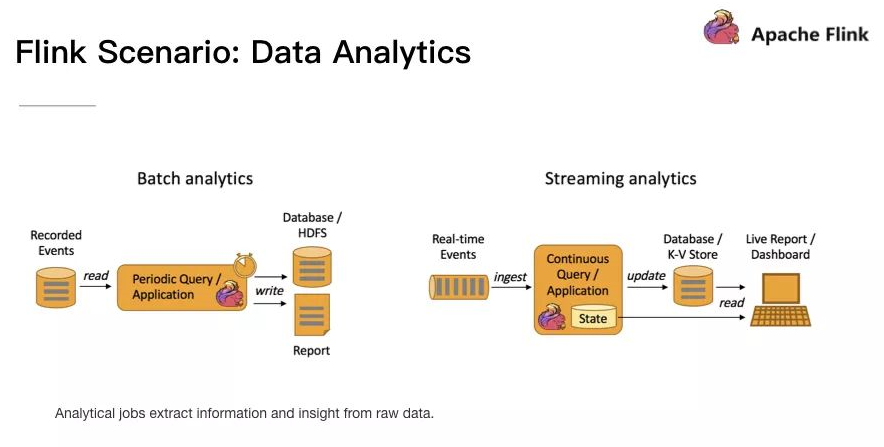
Data Analytics,如圖,左邊是 Batch Analytics,右邊是 Streaming Analytics。Batch Analysis 就是傳統意義上使用類似於 Map Reduce、Hive、Spark Batch 等,對作業進行分析、處理、生成離線報表,Streaming Analytics 使用流式分析引擎如 Storm,Flink 實時處理分析資料,應用較多的場景如實時大屏、實時報表。
Flink 應用場景:Data Driven
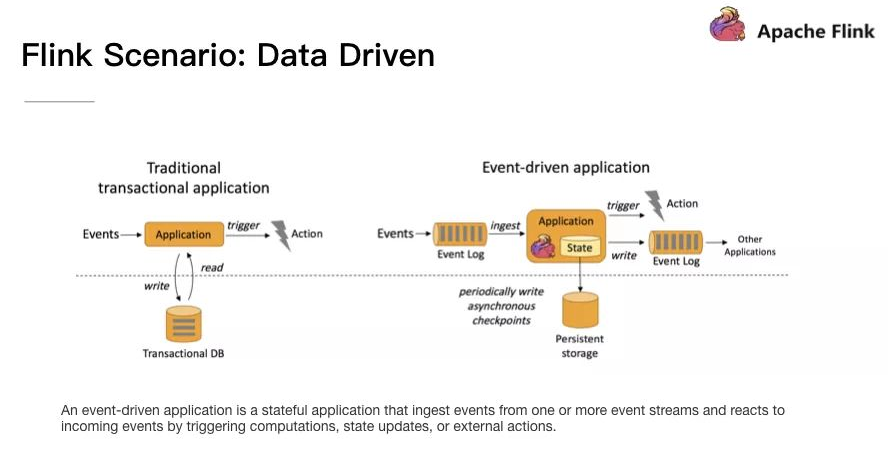
從某種程度上來說,所有的實時的資料處理或者是流式資料處理都是屬於 Data Driven,流計算本質上是 Data Driven 計算。應用較多的如風控系統,當風控系統需要處理各種各樣複雜的規則時,Data Driven 就會把處理的規則和邏輯寫入到 Datastream 的 API 或者是 ProcessFunction 的 API 中,然後將邏輯抽象到整個 Flink 引擎中,當外面的資料流或者是事件進入就會觸發相應的規則,這就是 Data Driven 的原理。在觸發某些規則後,Data Driven 會進行處理或者是進行預警,這些預警會發到下游產生業務通知,這是 Data Driven 的應用場景,Data Driven 在應用上更多應用於複雜事件的處理。
「有狀態的流式處理」概念解析
傳統批處理
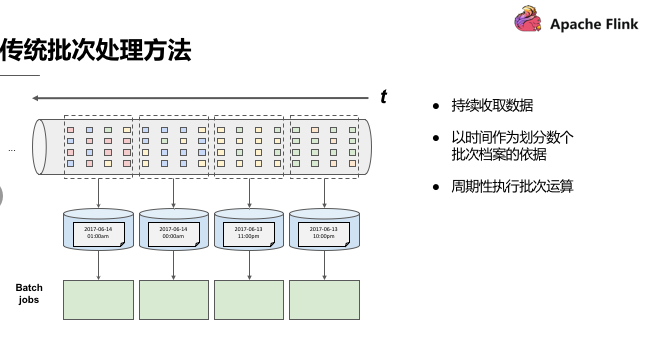
傳統批處理方法是持續收取資料,以時間作為劃分多個批次的依據,再週期性地執行批次運算。但假設需要計算每小時出現事件轉換的次數,如果事件轉換跨越了所定義的時間劃分,傳統批處理會將中介運算結果帶到下一個批次進行計算;除此之外,當出現接收到的事件順序顛倒情況下,傳統批處理仍會將中介狀態帶到下一批次的運算結果中,這種處理方式也不盡如人意。
理想方法
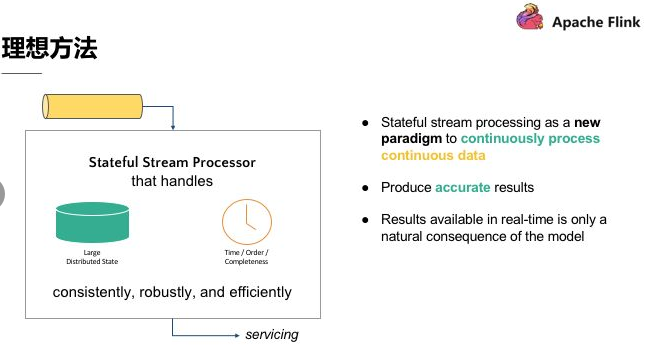
第一,要有理想方法,這個理想方法是引擎必須要有能力可以累積狀態和維護狀態,累積狀態代表著過去歷史中接收過的所有事件,會影響到輸出。
第二,時間,時間意味著引擎對於資料完整性有機制可以操控,當所有資料都完全接受到後,輸出計算結果。
第三,理想方法模型需要實時產生結果,但更重要的是採用新的持續性資料處理模型來處理實時資料,這樣才最符合 continuous data 的特性。
流式處理
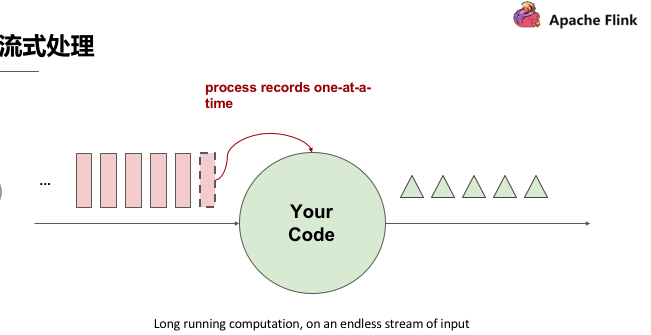
流式處理簡單來講即有一個無窮無盡的資料來源在持續收取資料,以程式碼作為資料處理的基礎邏輯,資料來源的資料經過程式碼處理後產生出結果,然後輸出,這就是流式處理的基本原理。
分散式流式處理
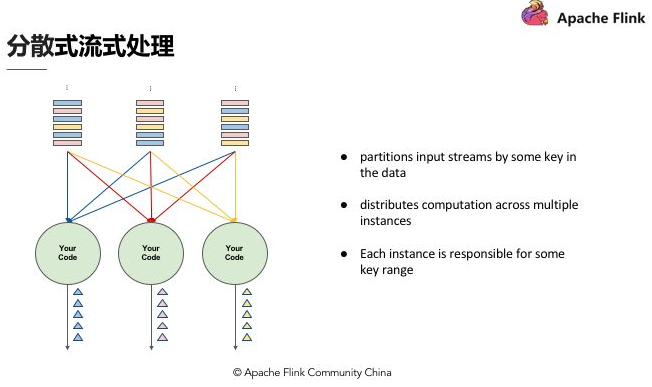
假設 Input Streams 有很多個使用者,每個使用者都有自己的 ID,如果計算每個使用者出現的次數,我們需要讓同一個使用者的出現事件流到同一運算程式碼,這跟其他批次需要做 group by 是同樣的概念,所以跟 Stream 一樣需要做分割槽,設定相應的 key,然後讓同樣的 key 流到同一個 computation instance 做同樣的運算。
有狀態分散式流式處理
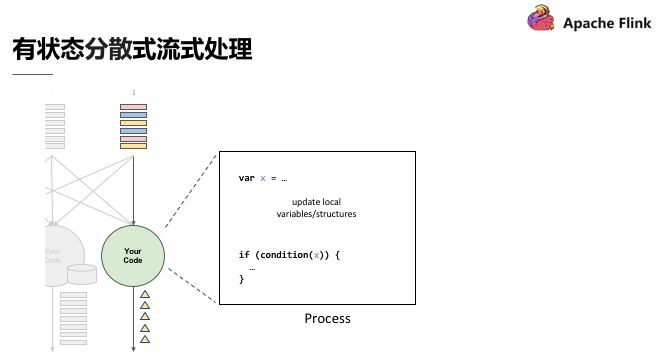
如圖,上述程式碼中定義了變數 X,X 在資料處理過程中會進行讀和寫,在最後輸出結果時,可以依據變數 X 決定輸出的內容,即狀態 X 會影響最終的輸出結果。這個過程中,第一個重點是先進行了狀態 co-partitioned key by,同樣的 key 都會流到 computation instance,與使用者出現次數的原理相同,次數即所謂的狀態,這個狀態一定會跟同一個 key 的事件累積在同一個 computation instance。
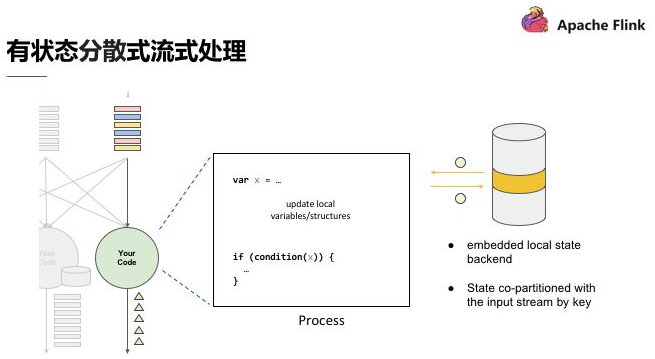
相當於根據輸入流的 key 重新分割槽的狀態,當分割槽進入 stream 之後,這個 stream 會累積起來的狀態也變成 copartiton 了。第二個重點是 embeded local state backend。有狀態分散式流式處理的引擎,狀態可能會累積到非常大,當 key 非常多時,狀態可能就會超出單一節點的 memory 的負荷量,這時候狀態必須有狀態後端去維護它;在這個狀態後端在正常狀況下,用 in-memory 維護即可。
Apache Flink 的優勢
狀態容錯
當我們考慮狀態容錯時難免會想到精確一次的狀態容錯,應用在運算時累積的狀態,每筆輸入的事件反映到狀態,更改狀態都是精確一次,如果修改超過一次的話也意味著資料引擎產生的結果是不可靠的。
- 如何確保狀態擁有精確一次(Exactly-once guarantee)的容錯保證?
- 如何在分散式場景下替多個擁有本地狀態的運運算元產生一個全域一致的快照(Global consistent snapshot)?
- 更重要的是,如何在不中斷運算的前提下產生快照?
簡單場景的精確一次容錯方法
還是以使用者出現次數來看,如果某個使用者出現的次數計算不準確,不是精確一次,那麼產生的結果是無法作為參考的。在考慮精確的容錯保證前,我們先考慮最簡單的使用場景,如無限流的資料進入,後面單一的 Process 進行運算,每處理完一筆計算即會累積一次狀態,這種情況下如果要確保 Process 產生精確一次的狀態容錯,每處理完一筆資料,更改完狀態後進行一次快照,快照包含在佇列中並與相應的狀態進行對比,完成一致的快照,就能確保精確一次。
分散式狀態容錯
Flink 作為分散式的處理引擎,在分散式的場景下,進行多個本地狀態的運算,只產生一個全域一致的快照,如需要在不中斷運算值的前提下產生全域一致的快照,就涉及到分散式狀態容錯。
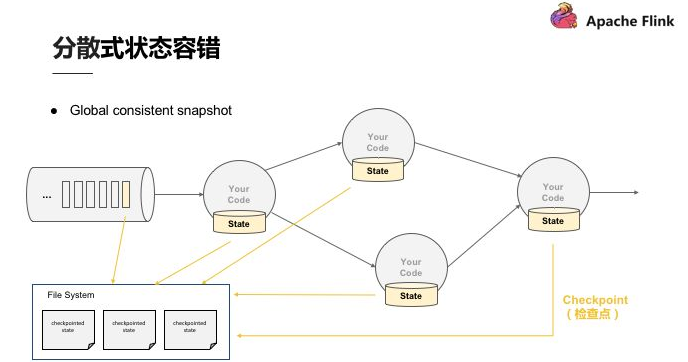
關於 Global consistent snapshot,當 Operator 在分散式的環境中,在各個節點做運算,首先產生 Global consistent snapshot 的方式就是處理每一筆資料的快照點是連續的,這筆運算流過所有的運算值,更改完所有的運算值後,能夠看到每一個運算值的狀態與該筆運算的位置,即可稱為 consistent snapshot,當然,Global consistent snapshot 也是簡易場景的延伸。
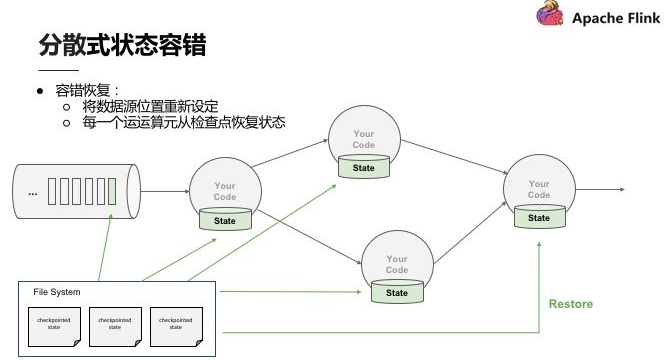
首先了解一下 Checkpoint,上面提到連續性快照每個 Operator 運算值本地的狀態後端都要維護狀態,也就是每次將產生檢查點時會將它們傳入共享的 DFS 中。當任何一個 Process 掛掉後,可以直接從三個完整的 Checkpoint 將所有的運算值的狀態恢復,重新設定到相應位置。Checkpoint 的存在使整個 Process 能夠實現分散式環境中的 Exactly-once。
分散式快照(Distributed Snapshots)方法
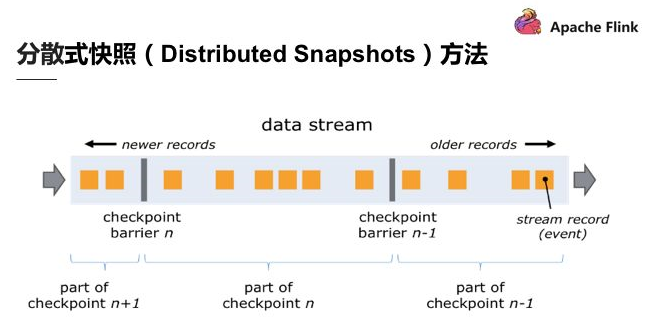
關於 Flink 如何在不中斷運算的狀況下持續產生 Global consistent snapshot,其方式是基於用 simple lamport 演演算法機制下延伸的。已知的一個點 Checkpoint barrier, Flink 在某個 Datastream 中會一直安插 Checkpoint barrier,Checkpoint barrier 也會 N — 1 等等,Checkpoint barrier N 代表著所有在這個範圍裡面的資料都是 Checkpoint barrier N。
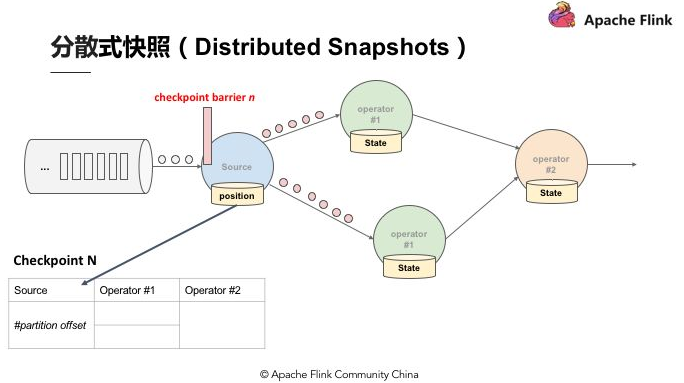
舉例:假設現在需要產生 Checkpoint barrier N,但實際上在 Flink 中是由 job manager 觸發 Checkpoint,Checkpoint 被觸發後開始從資料來源產生 Checkpoint barrier。當 job 開始做 Checkpoint barrier N 的時候,可以理解為 Checkpoint barrier N 需要逐步填充左下角的表格。
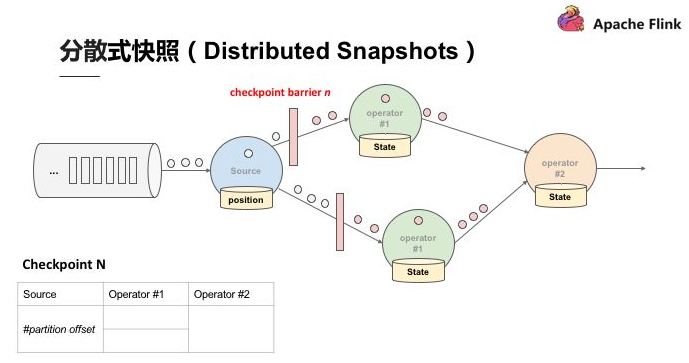
如圖,當部分事件標為紅色,Checkpoint barrier N 也是紅色時,代表著這些資料或事件都由 Checkpoint barrier N 負責。Checkpoint barrier N 後面白色部分的資料或事件則不屬於 Checkpoint barrier N。
在以上的基礎上,當資料來源收到 Checkpoint barrier N 之後會先將自己的狀態儲存,以讀取 Kafka 資料為例,資料來源的狀態就是目前它在 Kafka 分割槽的位置,這個狀態也會寫入到上面提到的表格中。下游的 Operator 1 會開始運算屬於 Checkpoint barrier N 的資料,當 Checkpoint barrier N 跟著這些資料流動到 Operator 1 之後,Operator 1 也將屬於 Checkpoint barrier N 的所有資料都反映在狀態中,當收到 Checkpoint barrier N 時也會直接對 Checkpoint 去做快照。
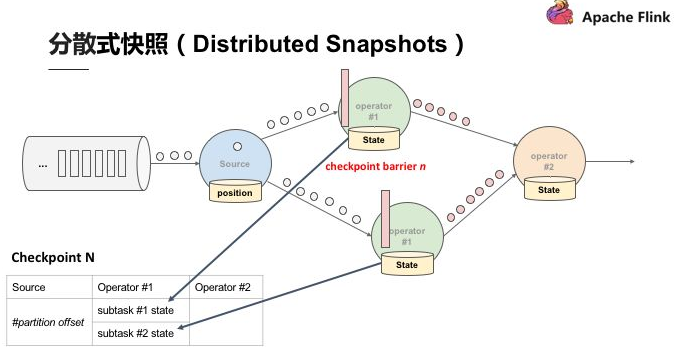
當快照完成後繼續往下游走,Operator 2 也會接收到所有資料,然後搜尋 Checkpoint barrier N 的資料並直接反映到狀態,當狀態收到 Checkpoint barrier N 之後也會直接寫入到 Checkpoint N 中。以上過程到此可以看到 Checkpoint barrier N 已經完成了一個完整的表格,這個表格叫做 Distributed Snapshots,即分散式快照。分散式快照可以用來做狀態容錯,任何一個節點掛掉的時候可以在之前的 Checkpoint 中將其恢復。繼續以上 Process,當多個 Checkpoint 同時進行,Checkpoint barrier N 已經流到 job manager 2,Flink job manager 可以觸發其他的 Checkpoint,比如 Checkpoint N + 1,Checkpoint N + 2 等等也同步進行,利用這種機制,可以在不阻擋運算的狀況下持續