
Redis快取,持久化,高可用
一,Redis作快取伺服器
本篇部落格是接著上一篇部落格未分享完的技術點。
redis作為快取伺服器是眾多企業中的選擇之一,雖然該技術很成熟但也是存在一定的問題。就是快取帶來的快取穿透,快取擊穿,快取失效問題,繼而引用分散式鎖。
1.1,快取穿透
在如今的專案中大多采用垂直的MVC架構,由service層去呼叫DAO層,然後DAO層再去查詢資料庫。而redis作為快取伺服器就是在service層去呼叫DAO層去查詢時先去快取伺服器查詢,如果存在則直接返回該資料,否則再去查詢資料庫。由此可知,這麼做大量減少了對磁碟I/O的操作,減輕了資料庫的壓力。
現在我們假設一種情況,在資料庫中存在有id為1到1000的資料。現在如果有人手動去模擬一個id為1001的請求,那麼該資料在快取伺服器中是不存在的,因而便會去查詢資料庫。那麼問題來了,如果是一個大量無效的請求去查詢資料庫。則勢必會對資料庫造成難以承受的壓力,這種情況就是所謂的快取穿透。
那如何解決呢?
1,將查詢到的null值直接儲存到快取伺服器中,但是這種做法並不推薦,因為如果是大量不同的請求id同樣會去查詢資料庫。
2,介面的限流,降級與熔斷
在專案中對於重要的介面一定要做限流,對於以上惡意攻擊的請求除了要限流,還要做好降級準備,並且進行熔斷,這種做法可以有效控制大量無效請求。
3,布隆過濾器
Bloomfilter就類似於一個hash set,用於快速判某個元素是否存在於集合中,其典型的應用場景就是快速判斷一個key是否存在於某容器,不存在就直接返回。布隆過濾器的關鍵就在於hash演算法和容器大小,該做法是多數企業所選擇的。
1.2,快取擊穿
在高併發下,對某些熱點的值進行查詢,但是這個時候快取正好過期了,快取沒有命中,導致大量請求直接落到資料庫上,此時這種大量的請求可能會是資料庫崩盤。
解決方案:
1,將熱點key設定成永不過期。
2,使用互斥鎖。
以上兩種情況均是屬於快取失效,但裡面還有小小的細節。那就是存在多個快取同時失效的問題,尤其在高併發時間段。為避免這種多個快取失效的問題,我們在設定超時時間的時候,可以使用固定時間+隨機時間。以最大限度避免當快取失效時大量請求去查詢資料庫。
1.3,分散式鎖
通常情況下分散式鎖有三種實現方式,1. 資料庫樂觀鎖;2. 基於ZooKeeper的分散式鎖;3. 基於Redis的分散式鎖;這裡只記錄基於redis的分散式鎖。
作為分散式鎖的要求:
- 互斥性: 保證在分散式應用叢集中,同一把鎖在同一時間只能被一臺機器上的一個執行緒執行。
- 避免死鎖:有一個客戶端在持有鎖的過程中崩潰而沒有解鎖,也能保證其他客戶端能夠加鎖。
先參看如下程式碼:
public List<Goods> goodsManager() {
System.out.println("呼叫過了業務層的goodsManager方法");
return goodsDao.queryAllPage();
// 1,先去查詢快取伺服器
List<Goods> goodsList = (List<Goods>) redisTemplate.opsForValue().get("goods");
if(goodsList == null){
// 2,申請分散式鎖
RedisConnection conn = redisTemplate.getConnectionFactory().getConnection();
if(conn.setNX("lock".getBytes(), "1".getBytes())){
// 3,給分散式鎖設定一個超時時間
conn.expire("lock".getBytes(), 60);
System.out.println("去資料庫中查詢所有的商品");
// 4,快取中沒有商品列表的資料
goodsList = goodsDao.queryAllPage();
// 5,將結果放入快取中
redisTemplate.opsForValue().set("goods", goodsList);
redisTemplate.expire("goods", 5, TimeUnit.MINUTES);
// 6,釋放分散式鎖
conn.del("lock".getBytes());
} else {
try {
Thread.sleep(50);
goodsManager();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
return goodsList;
} else {
//快取伺服器中有商品列表的資料
return goodsList;
}
} 程式碼設計思路:
1,請求到來呼叫方法。
2,先去redis快取中查詢是否存在,如果沒有則查詢資料庫。
3,使用原生的連線(setNX)獲得分散式鎖,然後設定超時時間。
設定超時時間的原因在於,如果執行緒獲得鎖之後不下心崩潰,為防止發生死鎖因而設定超時時間。
4,查詢資料庫獲得資料,並儲存在資料庫中。
5,釋放鎖。
1.4,雪崩效應
簡單來說,快取在同一時間內大量鍵(key)過期(失效),而新的快取又沒有即時的儲存到伺服器中,此時大量的請求瞬間都落在了資料庫中導致連線異常。
解決方案:
1、可以使用分散式鎖 ,單架構專案使用syn
2、永不過期
3、在設定快取超時時間,固定時間+隨機超時時間,防止多數快取同時失效。
4、高可用,叢集
1.5,redis快取與springboot整合
在啟動函式中先要開啟快取註解@Enablecaching
@Cacheable
被該註解標註的方法,會在執行前查詢快取伺服器,如果快取伺服器有結果,則直接返回結果,當前方法就不會執行。如果沒有結果,則在執行該方法的方法體,並且將該方法返回值放入快取伺服器中。
@CachePut
該註解和@Cacheable註解的功能差不多,唯一的區別在於不管快取伺服器有沒有對應的值,都會去呼叫相應的方法用於新增和更新的方法。
@CacheEvict
刪除指定的快取,一般用於刪除方法的使用 。
二,Redis持久化
### 2.1,redis提供兩種持久化方式:- RDB:它是備份當前瞬間Redis在記憶體中的資料結構(就是我們所說的快照)。
- AOF:它的作用是當Redis執行寫命令後,在一定的條件下將執行過的寫命令依次儲存在Redis的檔案中,以後依次執行這些儲存的命令就可回覆Redis的資料。
2.2,RDB原理分析
RDB持久化有兩種操作方式,手動操作進行持久化。
- save:會阻塞當前Redis伺服器,直到持久化完成,線上應該禁止使用。
- bgsave:該觸發方式會fork一個子程序,由子程序負責持久化過程,因此阻塞只會發生在fork子程序的時候。
bgsave和save最大的區別在於bgsave不會阻塞客戶端的寫操作,但是如果bgsave執行失敗,Redis預設將停止接受接入操作,否則就沒人會注意到災難的發生,如果不希望這樣做,可以將stop-writes-on-bgsave-error yes設定為no
另一種為自動觸發持久化,首先我們可以在配置檔案中配置快照的規則。
save 900 1 當900秒以內執行1個寫命令,使用快照備份
save 300 10 當300秒以內執行10個寫命令,使用快照備份
save 60 10000 當60秒以內執行10000個寫命令,使用快照備份
注意:redis執行備份命令時,將禁止寫入命令
2.3,AOF原理分析
AOF的整個流程大體來看可以分為兩步,一步是命令的實時寫入,第二步是對aof檔案的重寫,重寫是為了減少aof檔案的大小。
AOF檔案追加大致流程為:命令寫入-->追加到aof_buf(緩衝區) -->同步到aof磁碟。為什麼要先寫入buf緩衝區在同步到磁碟呢?因為如果實時寫入便會帶來大量的磁碟I/O操作,會很大程度上降低系統的效能。
關於AOF持久化大概有以下幾種配置。
appendonly no是否啟用AOF備份,預設為no,不啟用,如果需要啟用則改為yes。appendfilename "appendonly.aof"定義追加命令寫入的檔案為appendonly.aof- #
appendfsync always - always表示每次執行redis命令都會同步儲存到AOF檔案中,效能會收影響,但是安全性很高。
appendfsync everysecevarysec(預設)表示每一秒同步一次,效能會提升,但是安全性會下降,可能丟失1秒之內的命令。#appendfsync nono表示不同步,需要手動執行同步命令,效能得到了保證,但是安全性太差。
2.4,Redis記憶體回收策略
在redis.conf中的配置項maxmemory-policy用於配置redis的記憶體回收策略,當記憶體達到最大值時所採取的記憶體處理方式。
redis提供六種記憶體淘汰策略
volatile-lru:最近使用最少的淘汰策略,redis將回收那些設定了超時時間的鍵值對(僅僅只回收超時)。allkeys-lru:採用使用最少的淘汰策略,redis將所有鍵值對中使用最少的。volatile-random:才有隨機淘汰策略刪除設定了超時時間的鍵值對。allkeys-random:採用隨機淘汰策略刪除所有的鍵值對,(不常用)。volatile-ttl:刪除剩餘存活時間最短的鍵值對策略。noeviction(預設):不淘汰任何鍵值對,當記憶體已經滿時,進入只讀模式。
在記憶體回收機制中,LRU演算法和TTl演算法在redis中都不是精準計算,而是一個近似演算法。redis預設有一個探測數量的配置maxmemory-samples 預設為3。
三,Redis高可用
3.1,主從複製
在使用者量非常龐大的時候,單臺redis肯定是完全不夠用的。因此更多的時候我們更希望可以讀/寫分離,讀/寫分離的前提就是讀操作比寫操作頻繁的多,將資料放在多臺伺服器上那麼久可以消除單臺伺服器的壓力。
因此對於伺服器的搭建如圖:

假設一臺伺服器負責寫操作,其餘三臺為讀操作,以此實現一個獨寫分離的快取功能。但是很明視訊記憶體在一種弊端,就是其餘三臺讀取資料的伺服器它們之間的資料是不能夠進行同步的。這樣便造成資料不一致的情況,此時就需要對它們之間進行一個數據上的互通。
簡單介紹一下主從複製的概念,如上圖Master為主,負責寫入資料的操作,其餘三臺為從(Slave),負責讀取資料操作。當有資料寫入時,根據配置好的屬性自動將更新的資料複製到其餘三臺伺服器中,這樣便實現了伺服器之間的資料一致性。
主從複製的大致流程:
1、保證主伺服器(Master)的啟動。
2、當從伺服器啟動時,傳送SYNC命令給主伺服器。主伺服器接受到同步命令時,就是執行bgsave命令備份資料,但是主伺服器並不會拒絕客戶端的寫操作,而是將來自客戶端的寫命令寫入緩衝區。從伺服器在未收到主伺服器的備份快照檔案之前,會根據配置決定使用現有資料響應客戶端還是返回錯誤。
3、當bgsave命令被主伺服器執行完後,開始向從伺服器傳送備份檔案,這個時候從伺服器就會丟棄現有的所有資料,開始載入傳送過來的快照檔案。
4、當主伺服器傳送完備份檔案後,會將bgsave執行之後的快取區內的寫命令也傳送給從伺服器,從伺服器完成備份檔案解析後,就開始等待主伺服器的後續命令。
5、同步完成以後,每次主伺服器完成一次寫入命令,都會同時往從伺服器傳送同步寫入命令,主從同步就完成了。
從機配置:
slaveof server port 設定Master的ip和埠
masterauth root設定Master的密碼
到此為止,就完成了嗎?
並不是,以上步驟只是完成了主從複製,並沒有完成讀寫分離。並且,如果主(Master)伺服器宕機,那整個快取伺服器就全部掛掉了。==而且作為從(Slave)伺服器時不可以進行寫的操作,==那又如何解決呢(哨兵模式)?
3.2,哨兵模式
1,什麼時哨兵模式?
當Master宕機以後需要手動的把一臺Slave切換為Master,這種方式需要人工干預,費時費力。因此哨兵模式可以幫助我們解決這個問題。
2,簡述哨兵模式
- 哨兵是一個獨立的程序。
- 哨兵會檢測多個redis伺服器,包括Master和Slave。通過傳送命令,讓redis伺服器響應,檢測其執行狀態。
- 當哨兵檢測到master宕機,就會自動將slave切換成master,然後通過釋出訂閱模式通知其他slave修改配置檔案,切換主機。
- 為了實現哨兵的高可用,可以配置成多哨兵模式,即多個哨兵程序執行在不同的伺服器上檢測各個redis伺服器,哨兵兩兩之間也會互相監控。
- 多哨兵模式時,Master一旦宕機,哨兵1檢測到這個結果,並不會馬上進行故障切換,而僅僅是哨兵1主管的認為Master不可用。當其他哨兵也檢測到Master不可用時,並且有一定的數量後,那麼哨兵之間就會形成一次投票,投票的結果由一個哨兵發起,進行切換操作,切換完成後,就會通過釋出訂閱方式讓各個哨兵把自己監控的伺服器實現切換主機。
3,哨兵模式配置
3.1,#配置哨兵配置檔案:
redis/src/sentinel.conf
3.2,#禁止保護模式
protected-mode no
3.3,#配置監聽的主服務, 最後的2表示當2個或2個以上的哨兵認為主服務不可用才會進行故障切換
sentinel monitor 伺服器名稱(自定義) 主服務ip 埠 2
3.4,#定義服務密碼
sentinel auth-pass 伺服器名稱(和上面相同) 密碼
3.5,#啟動哨兵模式;
./redis-sentinel sentinel.conf
4,其他相關配置
sentinel down-after-milliseconds :指定哨兵在檢測redis服務時,當redis服務在一個毫秒數內都無法回答時,單個哨兵認為的主觀下線時間,預設為30秒。
sentinel failover-timeout:指定故障切換執行的毫秒數,當超過這個毫秒數時,就認為切換故障失敗,預設3分鐘。
sentinel notification-script:指定哨兵檢測到redis例項異常時,呼叫的報警指令碼。
3.3,分片叢集
分片叢集原理在於多個快取伺服器之間兩兩相互通訊,每個複製集具有一個主例項和多個從例項。並且每個複製集朱儲存一部分資料庫中的鍵值對,解決了主從複製集中總資料儲存量最小例項的限制,大大擴大了快取伺服器的大小。
其結構圖如下:
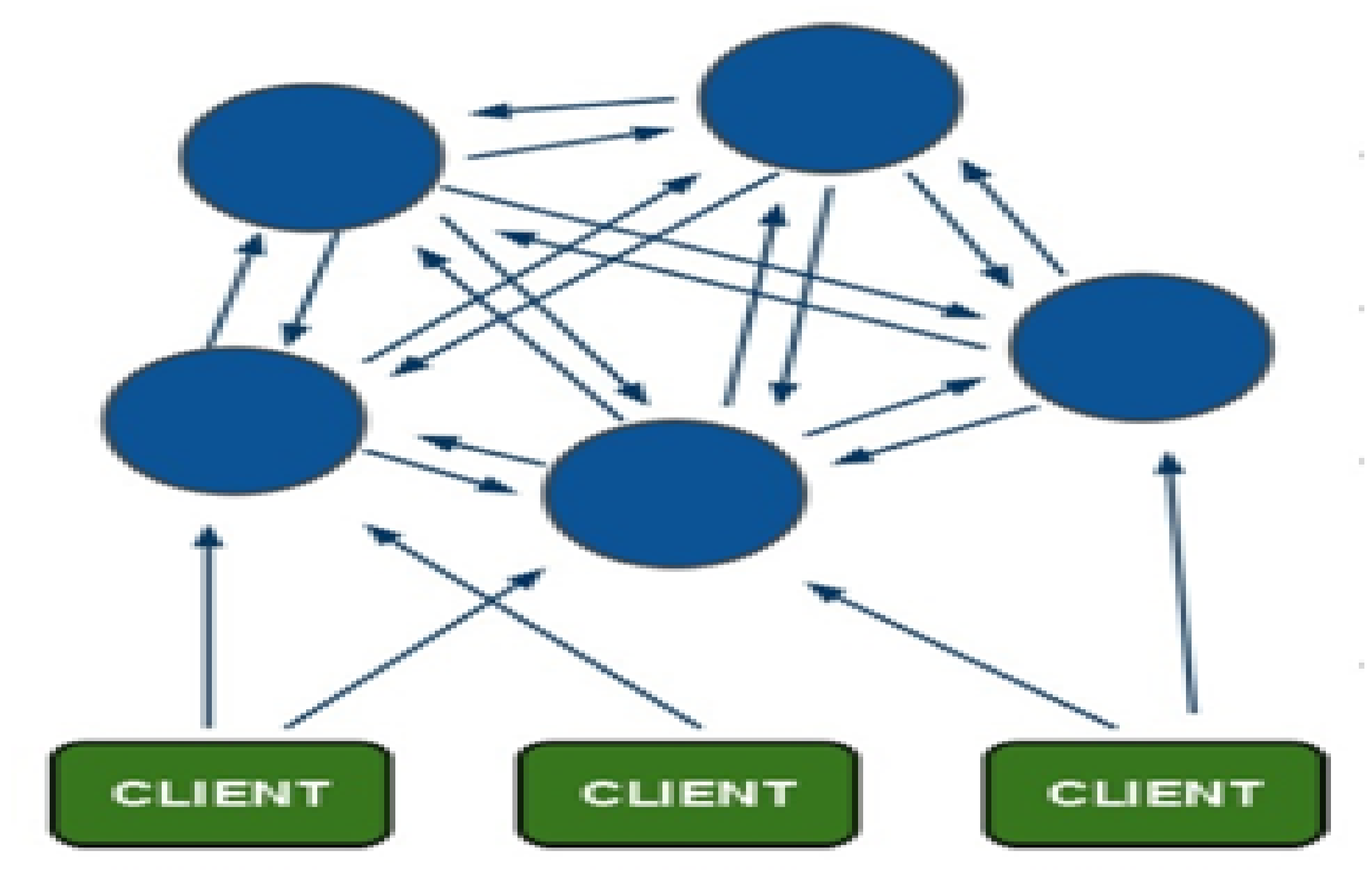
1,分片叢集特點
1、Client與redis節點直接連線,不需要中間proxy層。
2、 redis-cluster把所有的物理節點對映到[0-16383]slot(插槽)上,cluster 負責維護。
3、所有的redis節點彼此互聯(PING-PONG機制),內部使用gossip二進位制協議優化傳輸資料。
4、 節點的失效檢測是通過叢集中超過半數的節點檢測失效時才生效。
==問題:Redis 叢集中內建了 16384 個雜湊槽,那他是如何決定將key放入哪個插槽的?==
當Redis 叢集中放置一個 key-value 時,redis 先對 key 使用 crc16 演算法算出一個結果,然後把結果對 16384 求餘數,這樣每個 key 都會對應一個編號在 0-16383 之間的雜湊槽,redis 會根據節點數量大致均等的將雜湊槽對映到不同的節點。
2,叢集搭建步驟
前置條件:
刪除redis/src下的appendonly.aof,dump.rdb,nodes-6379.conf3個檔案。
1、修改redis.conf,配置叢集資訊開啟叢集,
cluster-enabled yes指定叢集的配置檔案,
cluster-config-file nodes-埠.conf
2、用redis-trib.rb搭建叢集因為redis-trib.rb是用Ruby實現的Redis叢集管理工具,所以我們需要先安裝ruby的環境.
2.1、安裝ruby
yum -y install zlib ruby rubygems
2.2、安裝rubygems的redis依賴
gem install -l redis-3.3.0.gem
3、安裝好依賴的環境之後,我們就可以來使用指令碼命令了
注意:此指令碼檔案在我們的解壓縮目錄src下。
執行命令:
./redis-trib.rb create --replicas 0 192.168.10.167:6379 192.168.10.167:6380 192.168.10.167:6381 開放16379 redis埠+1W--replicas 0:指定了從資料的數量為0。
4、檢視叢集狀態
通過客戶端輸入以下命令:
cluster nodes:這個命令可以檢視插槽的分配情況
整個Redis提供了16384個插槽,./redis-trib.rb 指令碼實現了是將16384個插槽平均分配給了N個節點。
四,總結
本篇部落格文字較多,大多數是描述問題的原因及解決方案。本次部落格與上一篇一起,是Redis從入門到高可用。其大部分在工作中都會遇到,以此做一個淺顯的記錄。但其中描述的較為簡單,仍有很多不可預料的問題,在此後會繼續更新,也會將問題與方案及原理描述更加清楚詳細。
由於能力有限,更為深層次的技術點沒有記錄到,以上如有不適之處,還請留言(郵箱)指教。
感謝閱讀