
2 Elasticsearch 篇之倒排索引與分詞
文章目錄
書的目錄與索引



書與搜尋引擎是相似的。
·目錄頁對應正排索引
·索引頁對應倒排索引
搜尋引擎
·正排索引
-文件Id到文件內容、單詞的關聯關係
·倒排索引
-單詞到文件Id的關聯關係
正排與倒排索引簡介
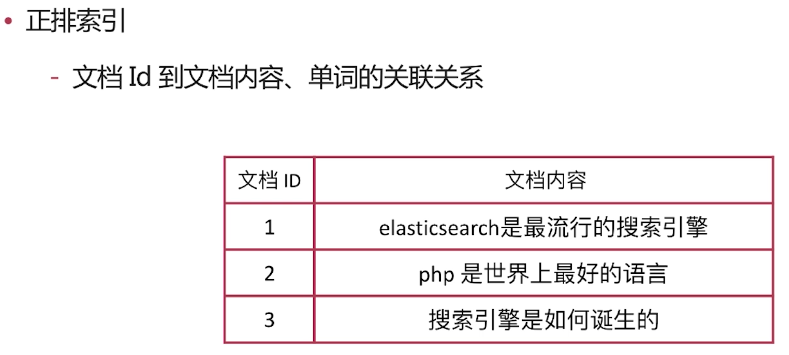
正排索引
-文件Id到文件內容、單詞的關聯關係
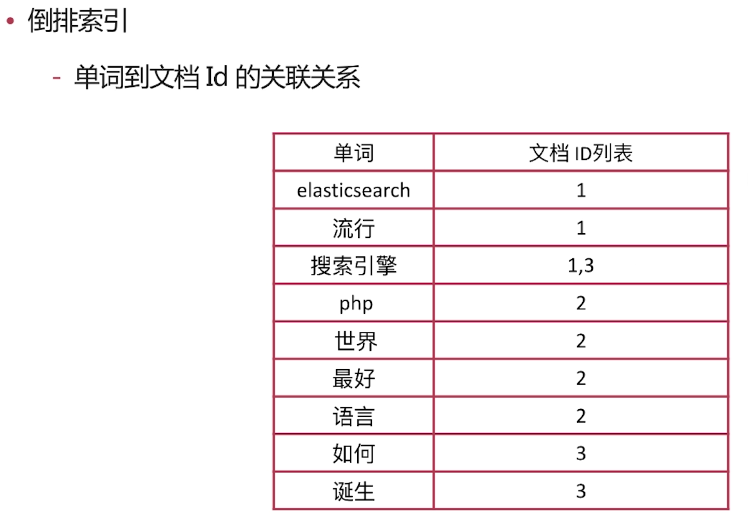
·倒排索引
-單詞到文件Id的關聯關係
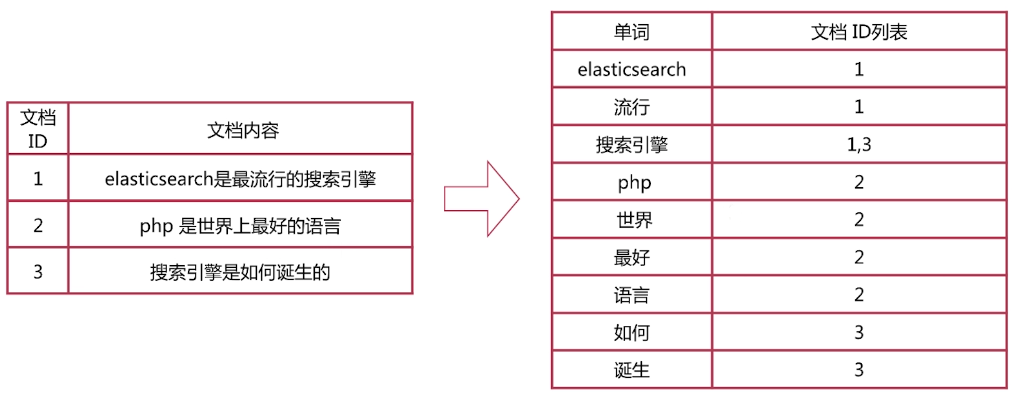
倒排索引-查詢流程
·查詢包含"搜尋引擎"的文件
-通過倒排索引獲得"搜尋引擎"對應的文件Id有1和3
-通過正排索引查詢1和3的完整內容
-返回使用者最終結果
倒排索引詳解
倒排索引組成:
倒排索引是搜尋引擎的核心,主要包含兩部分:
-單詞詞典( Term Dictionary)
-倒排列表( Posting List )
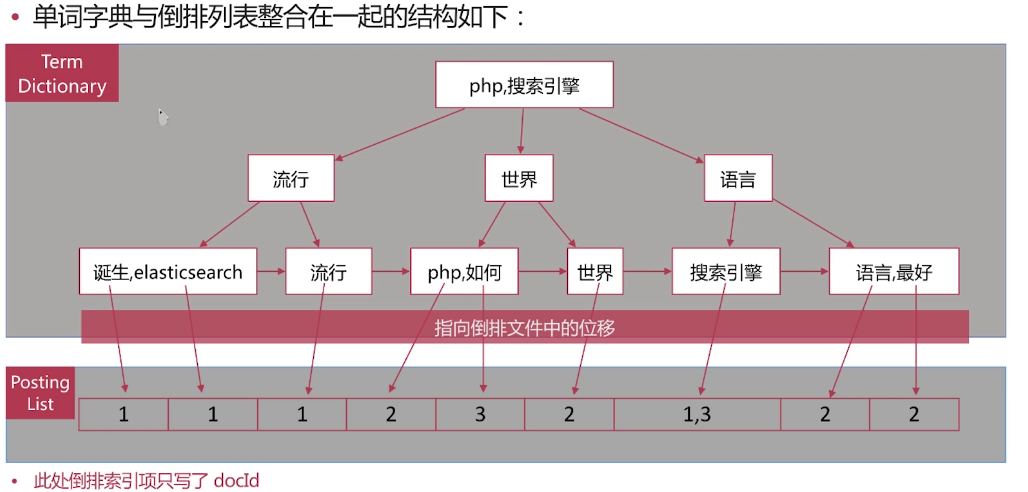
倒排索引一單詞詞典
·單詞詞典( Term Dictionary )是倒排索引的重要組成
-記錄所有文件的單詞,一般都比較大
-記錄單詞到倒排列表的關聯資訊
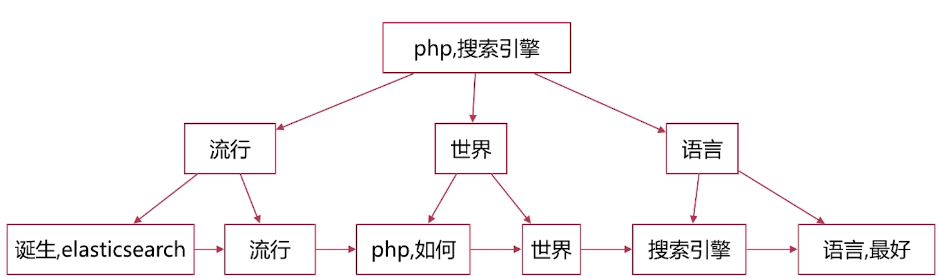
·單詞字典的實現一般是用B+ Tree ,示例如下圖:
-下圖排序採用拼音實現,構造方法參見如下網址
倒排索引-倒排列表
·倒排列表( Posting List )記錄了單詞對應的文件集合,由倒排索引項( Posting )組成
·倒排索引項( Posting )主要包含如下資訊:
-文件Id ,用於獲取原始資訊
-單詞頻率( TF, Term Frequency ) ,記錄該單詞在該文件中的出現次數,用於後續相關性算分
-位置( Position ) ,記錄單詞在文件中的分詞位置(多個) ,用於做詞語搜尋(Phrase Query)
-偏移( Offset ) ,記錄單詞在文件的開始和結束位置,用於做高亮顯示·
以“搜尋引擎”為例
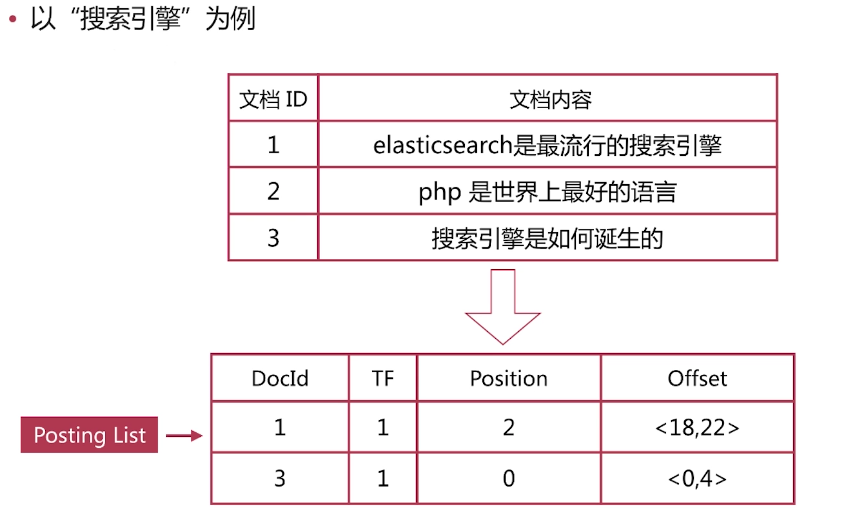
. es儲存的是一個json格式的文件,其中包含多個欄位,每個欄位會有自己的倒排索引
類似下圖:

分詞介紹
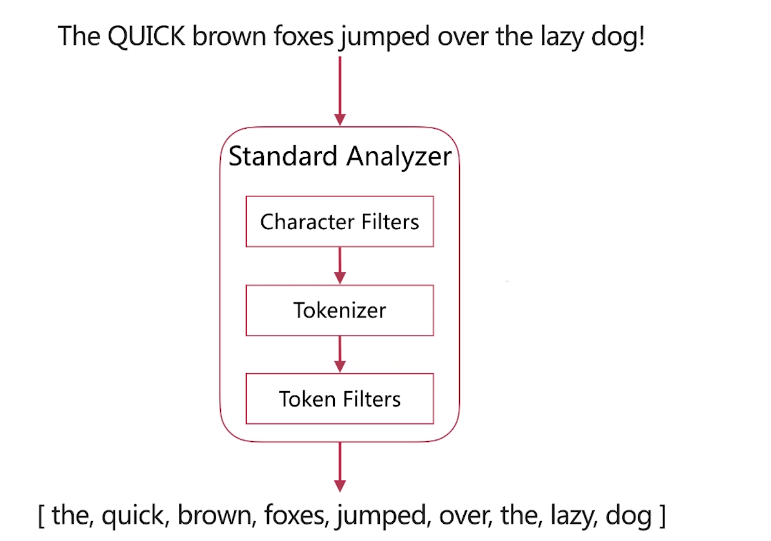
·分詞是指將文字轉換成一系列單詞( term or token )的過程,也可以叫做文字分析,在es裡面稱為Analysis ,如下圖所示:

·分詞器是es中專門處理分詞的元件,英文為Analyzer ,它的組成如下
- Character Filters
-針對原始文字進行處理,比如去除html特殊標記符
- Tokenizer
-將原始文字按照一定規則切分為單詞
- Token Filters
-針對tokenizer處理的單詞就行再加工,比如轉小寫、刪除或新增等處理
analyze_api
. es提供了一個測試分詞的api介面,方便驗證分詞效果, endpoint是_analyze
-可以直接指定analyzer進行測試
-可以直接指定索引中的欄位進行測試
-可以自定義分詞器進行測試
·直接指定analyzer進行測試,介面如下:
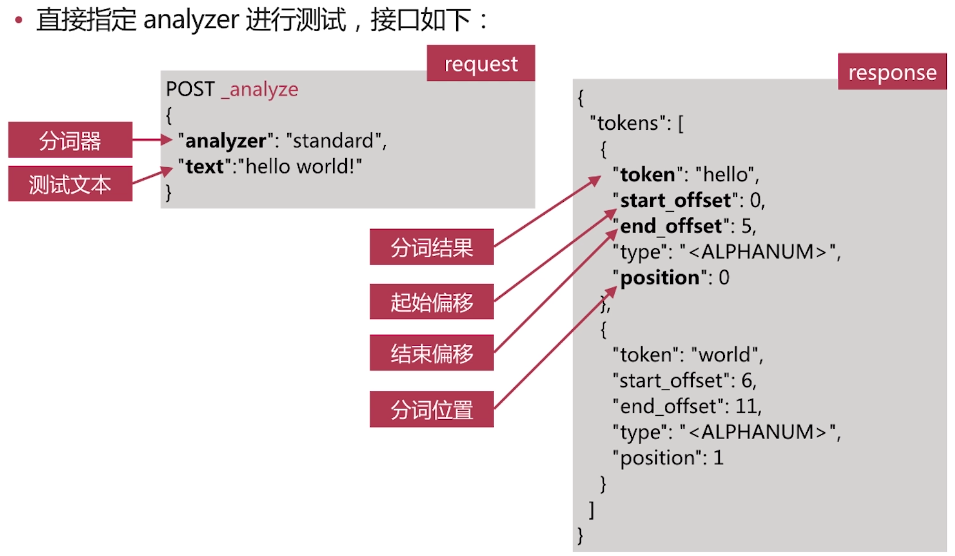
當沒有定義analyzer的時候會使用預設分詞器”analyzer”:”standard”

自定義分詞器:tokenizer指名要用哪個分詞器,filter指明的是token filter:

自帶分詞器
.es自帶如下的分詞器
-Standard Simple
-Whitespace
-Stop
-Keyword
-Pattern
-Language
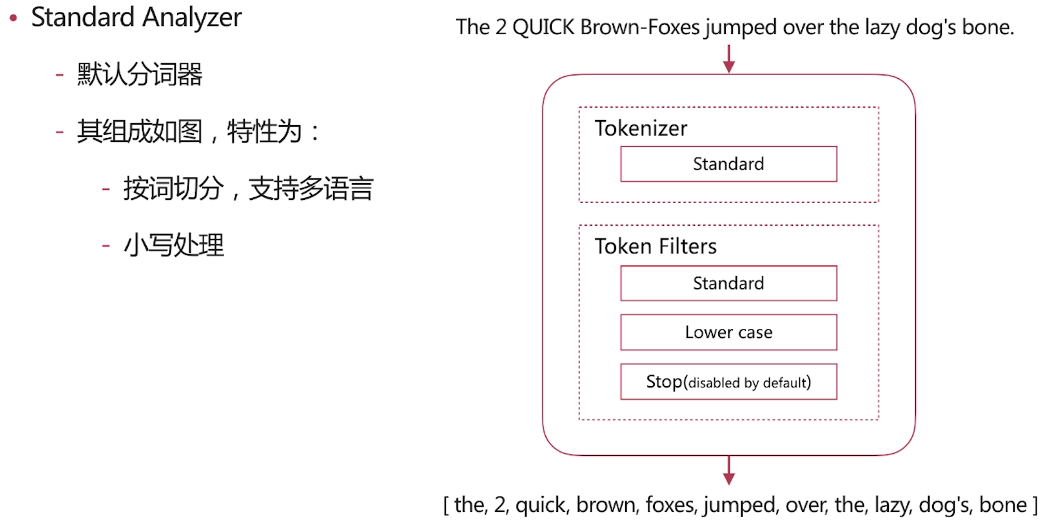
Standard Analyzer
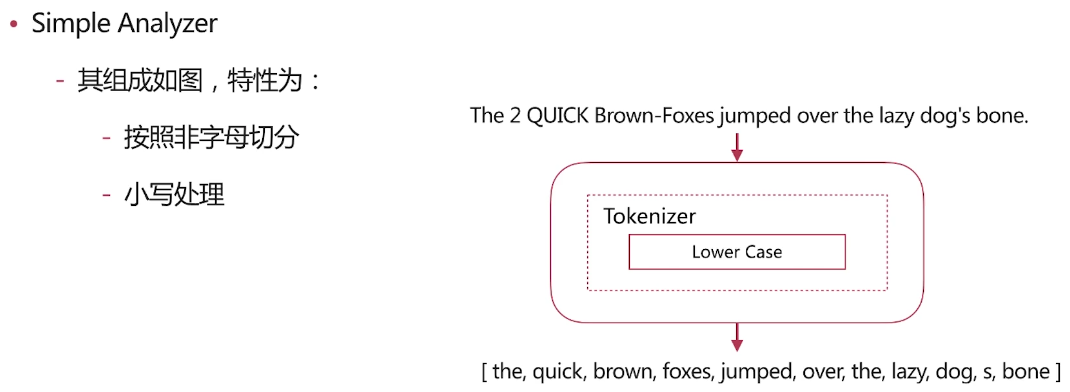
Simple Analyzer
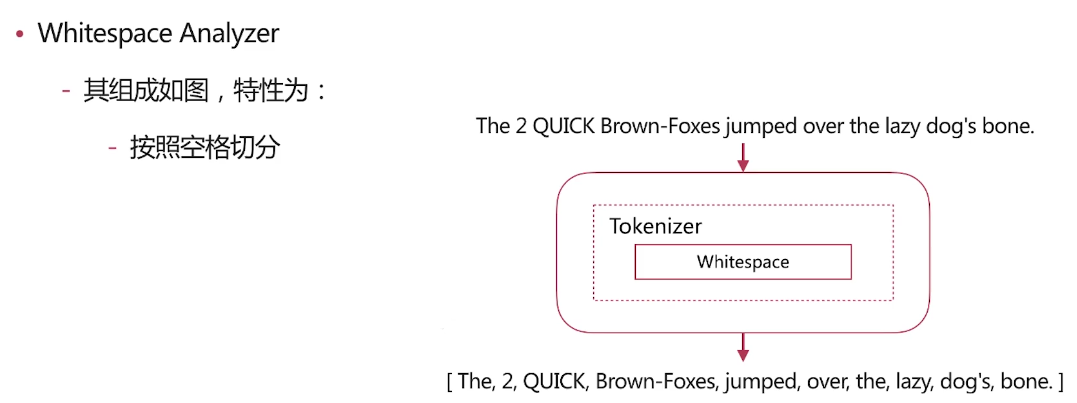
Whitespace Analyzer
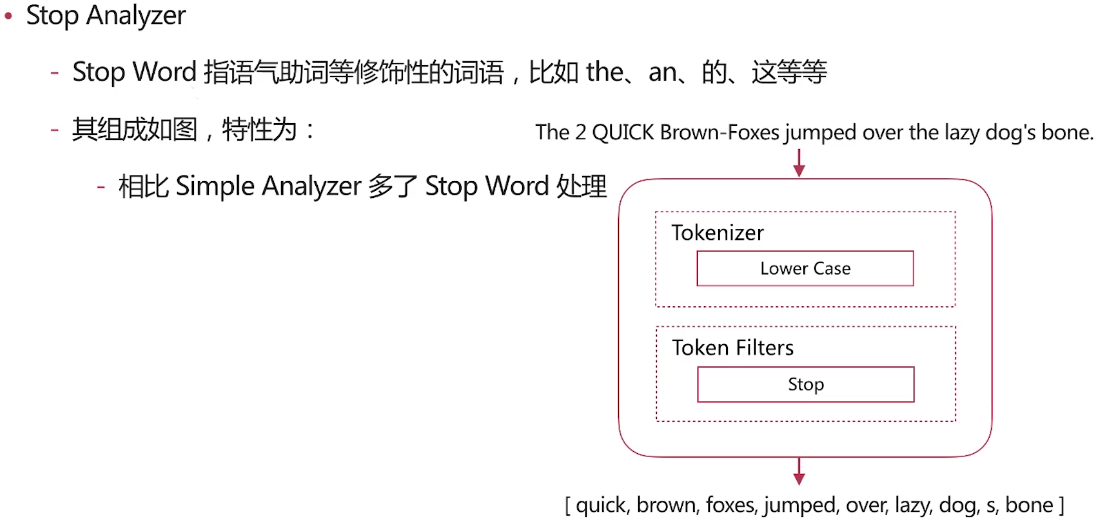
Stop Analyzer
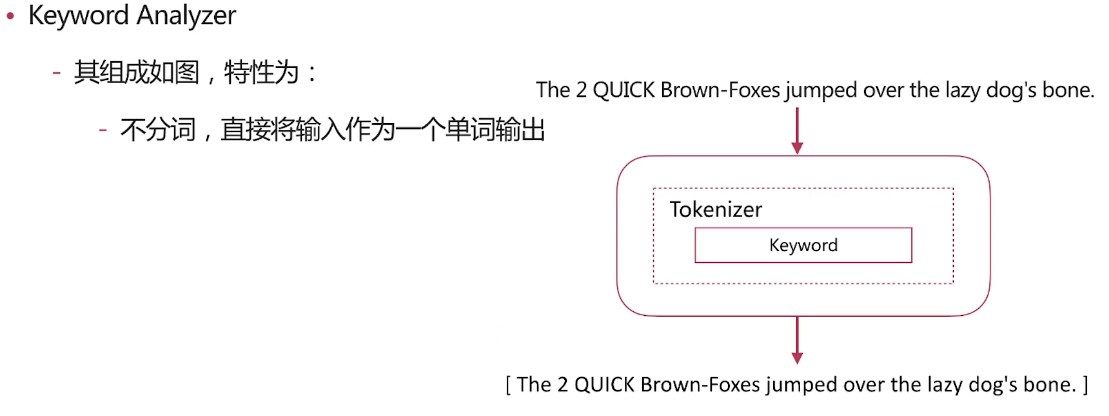
Keyword Analyzer
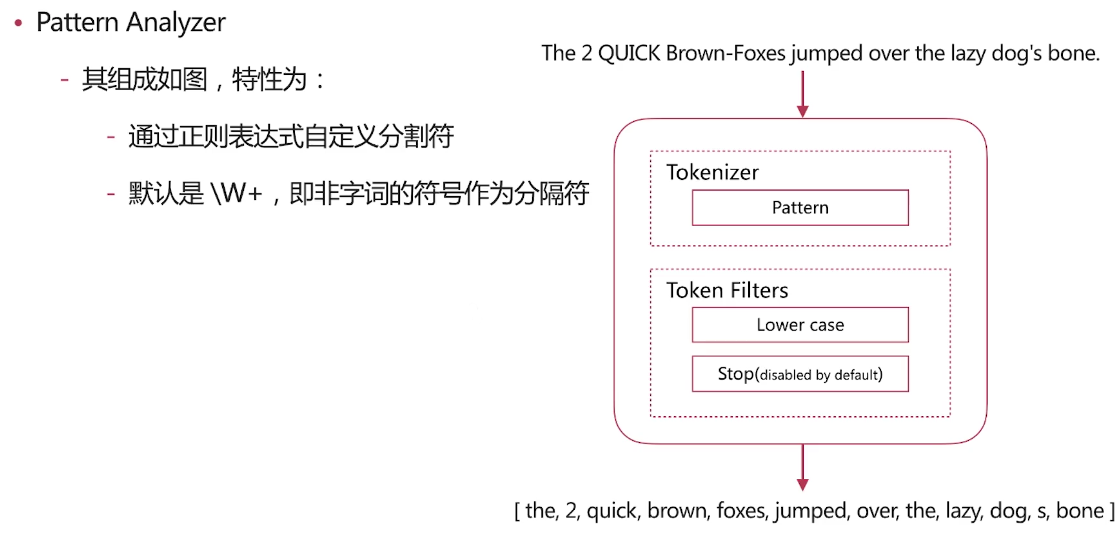
Pattern Analyzer
Language Analyzer

中文分詞
·難點
-中文分詞指的是將一個漢字序列切分成一個一個單獨的詞。在英文中,單詞之間是以空格作為自然分界符,漢語中詞沒有一個形式上的分界符。
-上下文不同,分詞結果迥異,比如交叉歧義問題,比如下面兩種分詞都合理
-乒乓球拍/賣完了
-乒乓球/拍賣/完了
- https://mp.weixin.qq.com/s/SiHSMrn8lxCmrtHbcwL-NQ
·常用分詞系統
-IK
-實現中英文單詞的切分,支援ik smart, ik maxword等模式
-可自定義詞庫,支援熱更新分詞詞典,
- https://github.com/medcl/elasticsearch-analysis-ik
- jieba
-python中最流行的分詞系統,支援分詞和詞性標註
-支援繁體分詞、自定義詞典、並行分詞等
- https://github.com/sing1ee/elasticsearch-jieba-plugin
·基於自然語言處理的分詞系統
- Hanlp
-由一系列模型與演算法組成的Java工具包,目標是普及自然語言處理在生產環境中的應用
- https://github.com/hankcs/HanLP
-THULAC
-THU Lexical Analyzer for Chinese ,由清華大學自然語言處理與社會人文計算實驗室研製推出的一套中文詞法分析工具包,具有中文分詞和詞性標註功能
- https://github.com/microbun/elasticsearch-thulac-plugin
自定義分詞
CharacterFilter
·當自帶的分詞無法滿足需求時,可以自定義分詞
-通過自定義Character Filters, Tokenizer和Token Filter實現. Character Filters
-在Tokenizer之前對原始文字進行處理,比如增加、刪除或替換字元等
-自帶的如下:
-HTML Strip去除html標籤和轉換html實體
-Mapping進行字元替換操作
-Pattern Replace進行正則匹配替換
-會影響後續tokenizer解析的postion和offset資訊
. Character Filters測試時可以採用如下api :

Tokenizer
Tokenizer
-將原始文字按照一定規則切分為單詞( term or token )
-自帶的如下:
-standard按照單詞進行分割
-letter按照非字元類進行分割
-whitespace按照空格進行分割
-UAX URL Email按照standard分割,但不會分割郵箱和url
-NGram和Edge NGram連詞分割
-Path Hierarchy按照檔案路徑進行切割
Tokenizer測試時可以採用如下api:

TokenFilter
. Token Filters
-對於tokenizer輸出的單詞( term )進行增加、刪除、修改等操作
-自帶的如下:
-lowercase將所有term轉換為小寫
-stop刪除stop words
-NGram和Edge NGram連詞分割
-Synonym新增近義詞的term
Filter測試時可以採用如下api:

自定義分詞
.自定義分詞的api
-自定義分詞需要在索引的配置中設定,如下所示:

自定義如下圖所示的分詞器:
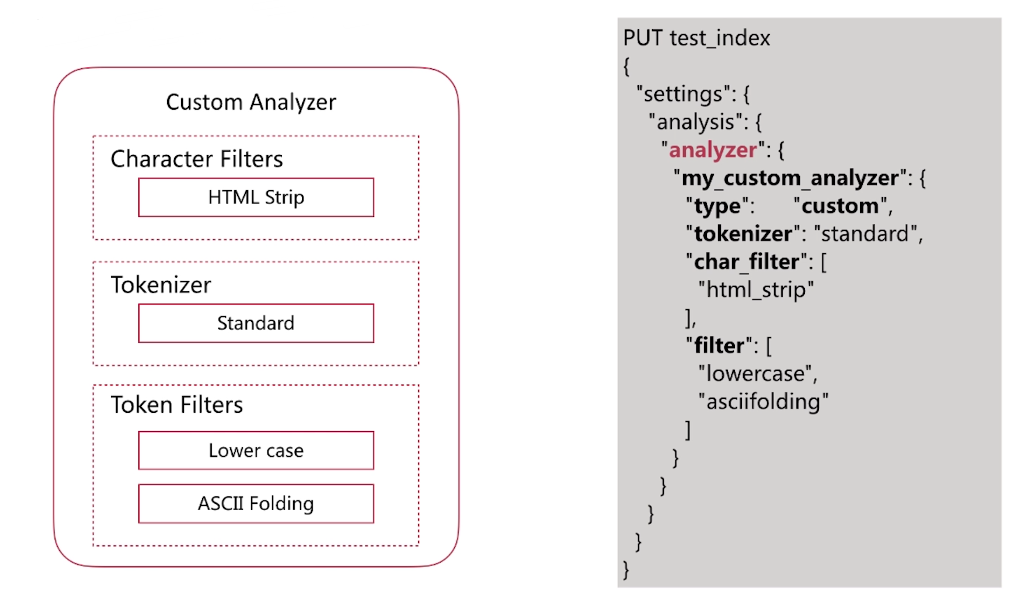
自定義分詞驗證:

自定義如下圖所示的分詞器二:
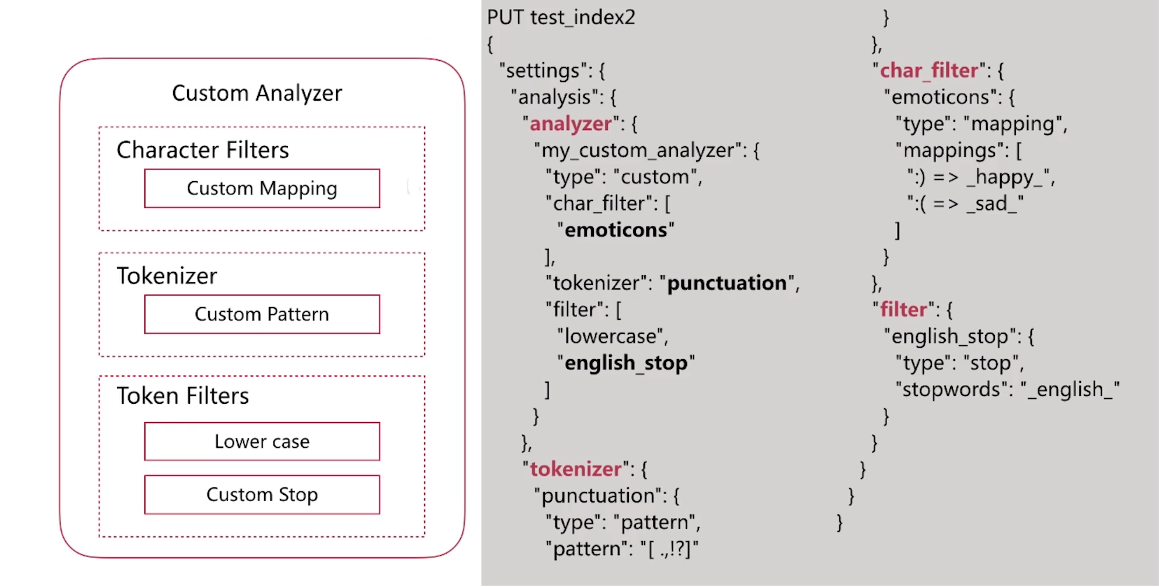
自定義分詞驗證:

分詞使用說明
·分詞會在如下兩個時機使用:
-建立或更新文件時(Index Time ) ,會對相應的文件進行分詞處理
-查詢時( Search Time ) ,會對查詢語句進行分詞
索引時分詞
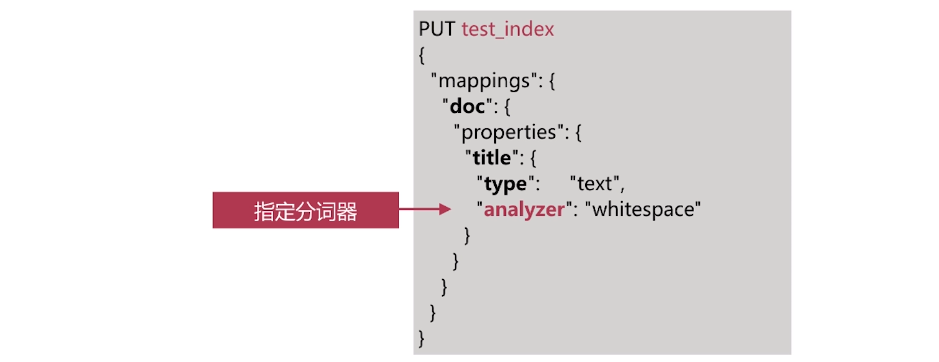
·索引時分詞是通過配置Index Mapping中每個欄位的analyzer屬性實現的如下:
不指定分詞時,使用預設standard
查詢時分詞
·查詢時分詞的指定方式有如下幾種:
-查詢的時候通過analyzer指定分詞器
-通過index mapping設定search_analyzer實現

.一般不需要特別指定查詢時分詞器,直接使用索引時分詞器即可,否則會出現無法匹配的情況
分詞建議
·明確欄位是否需要分詞,不需要分詞的欄位就將type設定為keyword ,可以節省空間和提高寫效能
·善用_analyze API ,檢視文件的具體分詞結果
·動手測試,
官方文件分詞連結
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis.html