
統一批處理流處理——Flink批流一體實現原理

實現批處理的技術許許多多,從各種關係型資料庫的sql處理,到大資料領域的MapReduce,Hive,Spark等等。這些都是處理有限資料流的經典方式。而Flink專注的是無限流處理,那麼他是怎麼做到批處理的呢?
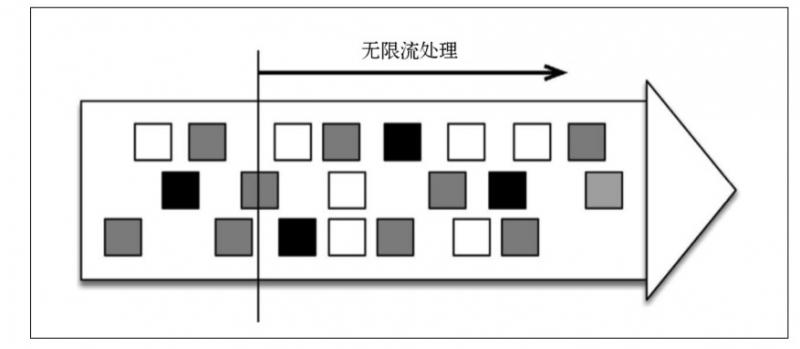
無限流處理:輸入資料沒有盡頭;資料處理從當前或者過去的某一個時間 點開始,持續不停地進行
另一種處理形式叫作有限流處理,即從某一個時間點開始處理資料,然後在另一個時間點結束。輸入資料可能本身是有限的(即輸入資料集並不會隨著時間增長),也可能出於分析的目的被人為地設定為有限集(即只分析某一個時間段內的事件)。
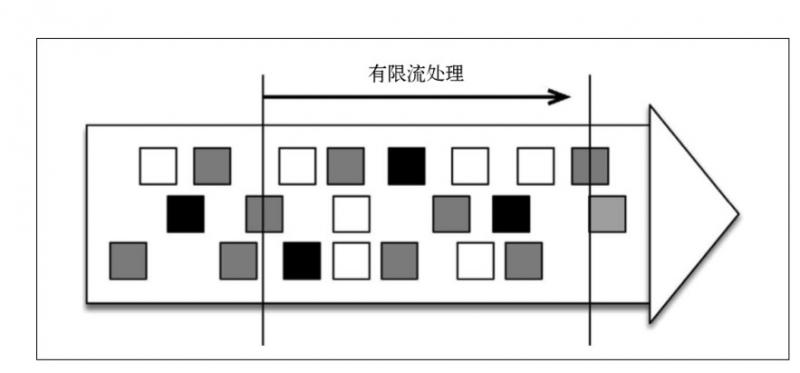
顯然,有限流處理是無限流處理的一種特殊情況,它只不過在某個時間點停止而已。此外,如果計算結果不在執行過程中連續生成,而僅在末尾處生成一次,那就是批處理(分批處理資料)。
批處理是流處理的一種非常特殊的情況。在流處理中,我們為資料定義滑 動視窗或滾動視窗,並且在每次視窗滑動或滾動時生成結果。批處理則不同,我們定義一個全域性視窗,所有的記錄都屬於同一個視窗。舉例來說, 以下程式碼表示一個簡單的Flink 程式,它負責每小時對某網站的訪問者計數,並按照地區分組。
val counts = visits
.keyBy("region")
.timeWindow(Time.hours(1))
.sum("visits")如果知道輸入資料是有限的,則可以通過以下程式碼實現批處理。
val counts = visits .keyBy("region") .window(GlobalWindows.create) .trigger(EndOfTimeTrigger.create) .sum("visits")
Flink 的不尋常之處在於,它既可以將資料當作無限流來處理,也可以將它當作有限流來處理。Flink 的 DataSet API 就是專為批處理而生的,如下所示。
val counts = visits
.groupBy("region")
.sum("visits")如果輸入資料是有限的,那麼以上程式碼的執行結果將與前一段程式碼的相同, 但是它對於習慣使用批處理器的程式設計師來說更友好。
Fink批處理模型
Flink 通過一個底層引擎同時支援流處理和批處理
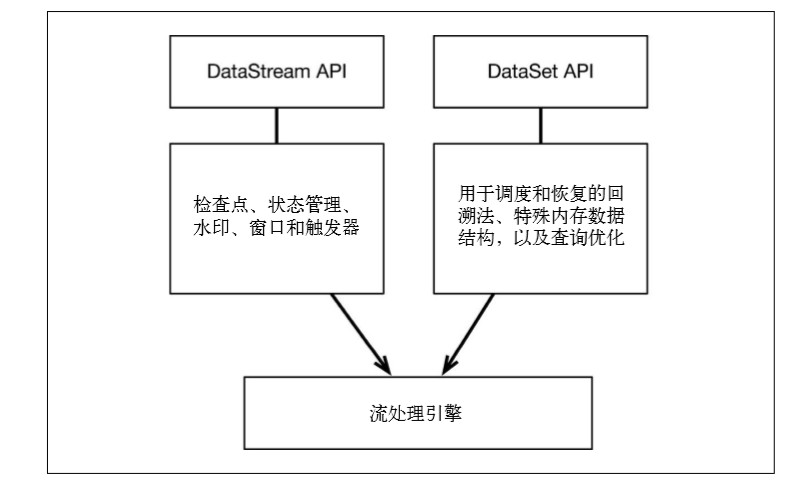
在流處理引擎之上,Flink 有以下機制:
檢查點機制和狀態機制:用於實現容錯、有狀態的處理;
水印機制:用於實現事件時鐘;
視窗和觸發器:用於限制計算範圍,並定義呈現結果的時間。
在同一個流處理引擎之上,Flink 還存在另一套機制,用於實現高效的批處理。
- 用於排程和恢復的回溯法:由 Microsoft Dryad 引入,現在幾乎用於所有批處理器;
- 用於雜湊和排序的特殊記憶體資料結構:可以在需要時,將一部分資料從記憶體溢位到硬碟上;
- 優化器:儘可能地縮短生成結果的時間。
兩套機制分別對應各自的API(DataStream API 和 DataSet API);在建立 Flink 作業時,並不能通過將兩者混合在一起來同時 利用 Flink 的所有功能。
在最新的版本中,Flink 支援兩種關係型的 API,Table API 和 SQL。這兩個 API 都是批處理和流處理統一的 API,這意味著在無邊界的實時資料流和有邊界的歷史記錄資料流上,關係型 API 會以相同的語義執行查詢,併產生相同的結果。Table API 和 SQL 藉助了 Apache Calcite 來進行查詢的解析,校驗以及優化。它們可以與 DataStream 和 DataSet API 無縫整合,並支援使用者自定義的標量函式,聚合函式以及表值函式。
Table API / SQL 正在以流批統一的方式成為分析型用例的主要 API。
DataStream API 是資料驅動應用程式和資料管道的主要API。
從長遠來看,DataStream API應該通過有界資料流完全包含DataSet API。
Flink批處理效能
MapReduce、Tez、Spark 和 Flink 在執行純批處理任務時的效能比較。測試的批處理任務是 TeraSort 和分散式雜湊連線。
第一個任務是 TeraSort,即測量為 1TB 資料排序所用的時間。
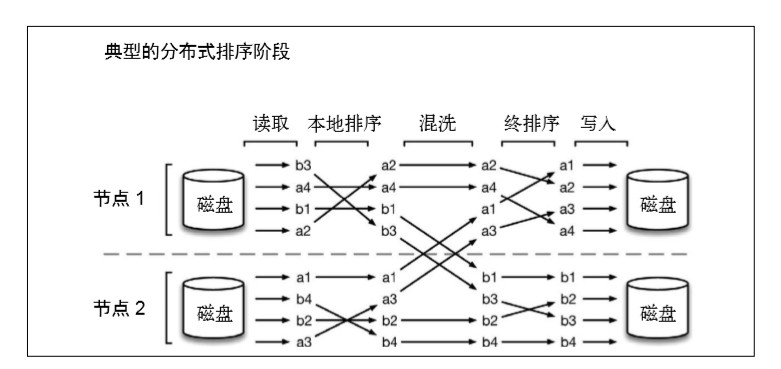
TeraSort 本質上是分散式排序問題,它由以下幾個階 段組成:
(1) 讀取階段:從 HDFS 檔案中讀取資料分割槽;
(2) 本地排序階段:對上述分割槽進行部分排序;
(3) 混洗階段:將資料按照 key 重新分佈到處理節點上;
(4) 終排序階段:生成排序輸出;
(5) 寫入階段:將排序後的分割槽寫入 HDFS 檔案。
Hadoop 發行版包含對 TeraSort 的實現,同樣的實現也可以用於 Tez,因為 Tez 可以執行通過MapReduce API 編寫的程式。Spark 和 Flink 的 TeraSort 實現由 Dongwon Kim 提供.用來測量的叢集由 42 臺機器組成,每臺機器 包含 12 個 CPU 核心、24GB 記憶體,以及 6 塊硬碟。
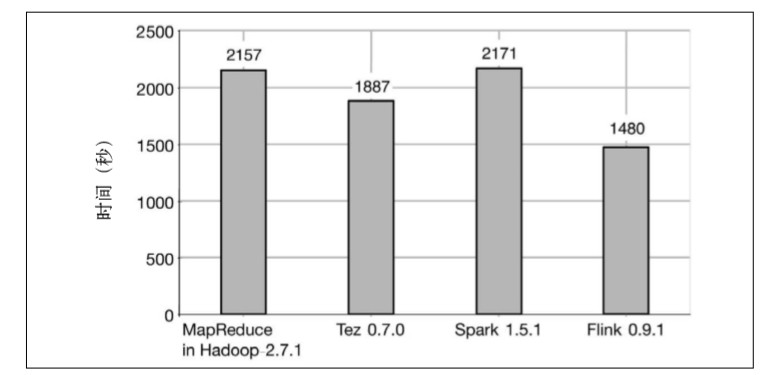
結果顯示,Flink 的排序時間比其他所有系統都少。 MapReduce 用了2157 秒,Tez 用了1887 秒,Spark 用了2171 秒,Flink 則 只用了 1480 秒。
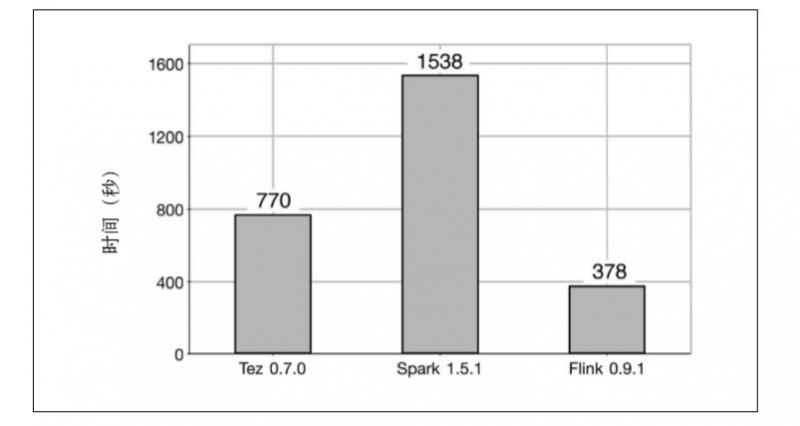
第二個任務是一個大資料集(240GB)和一個小資料集(256MB)之間的分散式雜湊連線。結果顯示,Flink 仍然是速度最快的系統,它所用的時間分別是 Tez 和 Spark 的 1/2 和 1/4.
產生以上結果的總體原因是,Flink 的執行過程是基於流的,這意味著各個處理階段有更多的重疊,並且混洗操作是流水線式的,因此磁碟訪問操作更少。相反,MapReduce、Tez 和 Spark 是基於批的,這意味著資料在通過網路傳輸之前必須先被寫入磁碟。該測試說明,在使用Flink 時,系統空閒時間和磁碟訪問操作更少。
值得一提的是,效能測試結果中的原始數值可能會因叢集設定、配置和軟體版本而異。
因此,Flink 可以用同一個資料處理框架來處理無限資料流和有限資料流,並且不會犧牲效能。
更多Flink相關文章:
穿梭時空的實時計算框架——Flink對時間的處理
Flink快速入門--安裝與示例執行
大資料實時處理的王者-Flink
Flink,Storm,SparkStreaming效能對比
更多實時計算,Flink,Kafka的技術文章歡迎關注實時流式計算

相關推薦
統一批處理流處理——Flink批流一體實現原理
實現批處理的技術許許多多,從各種關係型資料庫的sql處理,到大資料領域的MapReduce,Hive,Spark等等。這些都是處理有限資料流的經典方式。而Flink專注的是無限流處理,那麼他是怎麼做到批處理的呢? 無限流處理:輸入資料沒有盡頭;資料處理從當前或者過去的某一個時間 點開始,持續不停地進行
將Flink中的批處理的WordCount轉化為流處理的WordCount
將Flink中的批處理的WordCount轉化為流處理的WordCount 目的:將Flink中批處理的WordCount轉化為流處理的WordCount 作用:感覺毫無用處 如何實現:將批的environmentBatch中的各個運算元,在流的environmentStream中
(二):Flink概述,Flink如何支援批流處理,程式流程
前言 以下都儘量對比Spark(或者大資料生態的其他技術)進行理解。 Flink簡介,Flink能做什麼 Flink簡介 Flink最初是一個名為Stratosphere的研究專案,目標是為柏林地區的一些大學建立下一代大資料分析平臺。 它於2014年4月16
shell判斷批處理的目錄下的流文件是否處理完成
top $0 err delete date proc conf shel script #!/bin/bash log_error() {? ? echo -e $target date "+%Y-%m-%d %H:%M:%S" ["\033[31merror\
大型企業級雲產品-數據統計分析系統(離線處理-流處理-批處理)
大數據大型企業級雲產品-數據統計分析系統(離線處理-流處理-批處理)課程觀看地址:http://www.xuetuwuyou.com/course/249課程出自學途無憂網:http://www.xuetuwuyou.com講師:友凡 課程介紹本套教程為真實的大數據實戰案例,適合有大數據基礎的學員學習,熟練掌
大數據爭論:批處理與流處理的C位之戰
數據管理 sha 區別 mark spark 連續 錘子 常用 兩種 數據無疑是當今數字經濟中的新貨幣,但要跟上企業數據變化和遞增的業務信息需求,仍然是非常艱難。這也就解釋了公司將數據從傳統基礎構架中遷移至雲中,以衡量數據驅動決策的原因。這可確保公司寶貴資源——數據——受到
Apache Beam 2.9.0 釋出,大資料批處理和流處理標準
Apache Beam 2.9.0 釋出了。Apache Beam 是 Google 在2016年2月份貢獻給 Apache 基金會的專案,主要目標是統一批處理和流處理的程式設計正規化,為無限、亂序、web-scale 的資料集處理提供簡單靈活,功能豐富以及表達能力十分強
批處理和流處理
Reference [1] https://www.jianshu.com/p/5cc07eae1a0c 批處理 Batch Processing 批處理在大資料世界有著悠久的歷史。批處理主要操作大容量靜態資料集,並在計算過程完成後返回結果。 批處理模式中使用的資
大資料架構簡述(三):流處理、批處理、互動式查詢
我們將大資料處理按處理時間的跨度要求分為以下幾類 基於實時資料流的處理,通常的時間跨度在數百毫秒到數秒之間 基於歷史資料的互動式查詢,通常時間跨度在數十秒到數分鐘之間 複雜的批
最佳實踐:Pulsar 為批流處理提供融合儲存
非常榮幸有機會和大家分享一下 Apache Pulsar 怎樣為批流處理提供融合的儲存。希望今天的分享對做大資料處理的同學能有幫助和啟發。 這次分享,主要分為四個部分: * 介紹與其他訊息系統相比, Apache Pulsar 的獨特優勢 * 分析批流處理中的儲存需求 * 講述 Apache Pulsar
Flink之流處理基礎
目錄 Chapter 1. Introduction to Stateful Stream Processing Traditional Data Infrastructures Stateful Stream Processing The Evolution of Op
[Flink基礎]--什麼是流處理?
感謝原文作者:https://data-artisans.com/what-is-stream-processing 什麼是流處理? Data Artisans由ApacheFlink®的原始建立者建立,我們花了很長時間來解決流處理領域的問題。在這篇介紹性文章中,我們將提供有關流處理和Apa
Apache Flink流處理(一)
Apache Flink是一個分散式流處理器,它使用直接且富有表現力的API來實現有狀態的流處理應用程式。它以容錯的方式高效地大規模執行此類應用程式。Flink於2014年4月加入Apache軟體基金會作為孵化專案,並於2015年1月成為頂級專案。從一開始,Flink就有一個非常活躍且不斷增
Flink視頻教程_基於Flink流處理的動態實時電商實時分析系統
分布 業務 電商分析 apr 進行 處理 密碼 教程 包括 Flink視頻教程_基於Flink流處理的動態實時電商實時分析系統 課程分享地址鏈接:https://pan.baidu.com/s/1cX7O-45y6yUPT4B-ACfliA 密碼:jqmk 在開始學習前給
flink流處理內容
Flink核心是一個流式的資料流執行引擎,其針對資料流的分散式計算提供了資料分佈、資料通訊以及容錯機制等功能 Flink提供了諸多更高抽象層的API以便使用者編寫分散式任務: DataSet API, 對靜態資料進行批處理操作,將靜態資料抽象成分散式的資料集,使用者可以方便地使用Flink提供的各種操作符
Apache Flink流處理(二)
到目前為止,您已經瞭解了流處理如何解決傳統批處理的侷限性,以及它如何支援新的應用程式和體系結構。您已經熟悉了開源的流處理空間的演變,並對Flink流應用程式有了簡單的瞭解。在這一章,你將進入流世界中,並得到本書本書剩下部分所必要的基礎知識。 這一章仍然與Flink無關。它的目標是介紹流處
Flink流處理過程的部分原理分析
文章目錄 前言 流的時間有序性保證 視窗序列對齊 流資料的容錯:Checkpoint機制 Barrier State 引用 前言 在分散式領域,計算和儲存一直是兩大子領域。很多分散式
Apache Flink 1.5.6 釋出,流處理框架
Apache Flink 1.5.6 釋出了,Flink 是一個流處理框架,應用於分散式、高效能、始終可用的與準確的資料流應用程式。 主要更新如下: [FLINK-4173] - flink-metrics 中用 maven-shade-plugin 替換
Spark Streaming、Storm、Flink對比分析,以及為什麼選擇Flink作為流處理框架
隨著大資料技術的不斷髮展和成熟,無論是傳統企業還是網際網路公司都已經不再滿足於離線批處理,實時流處理的需求和重要性日益增長。17年底公司就著力打造實時計算平臺,探索實時流計算引擎和 API,例如這幾年火爆的 Storm、Spark Streaming、Kafka
回顧2016--Apache Flink流處理在生產中的實踐
從2016年4月底開始接觸Flink,到現在已經8個多月了。從瞭解到熟悉,再到實際開發,這個過程就是我從0到實際開發使用Flink的過程。 上週,我們的Flink流計算程式終於上線了。也算是在實時流計算方面的一個成果。 下面,我將簡要介紹下公司如何使用Fli