
Structured Streaming 簡單資料處理——讀取CSV並提取列關鍵詞
前言
近日想學學Spark 比較新的Structured Streaming ,百度一輪下來,全都是千篇一律的wordcount ,很是無語。只好自己摸索,除了Dataframe的Select和Filter 操作還能做些什麼處理。因為用的Python,用過Pandas,摸索中,想轉Pandas去處理,結果readStream並不支援直接toPandas()這個方法。最後翻來官方API,發現了還有Dataframe還有一個強大的操作,並且能夠在readStream中使用,那就是——UDF。
環境準備
- Hadoop 2.8.5
- Spark 2.4.3
- Python 3.7.3
- jieba (jieba分詞工具,提供了TF-IDF關鍵詞提取方法,pip install jieba)
程式下面的程式碼都是在互動式環境下執行,即pyspark下。
資料準備
| id | title_zh | content_zh | publish_date | |
|---|---|---|---|---|
假設CSV資料如上表格所示,分別表示文章id,標題,內容,釋出時間。
有如下需求:提取標題的關鍵詞,並將關鍵詞新增到新列。(本來還有提取文章關鍵詞,原理其實一樣,就不多寫了)
讀取資料
讀取csv檔案有兩步:定義schema,按照schema讀取檔案。
定義schema:
本例中,id為Integer型別,publish_date為TimestampType型別,其餘為StringType。首先引入部分依賴:
from pyspark.sql.functions import udf from pyspark.sql.types import StructType,StringType,IntegerType,TimestampType
定義一個StructType:
sdf=StructType().add('id',IntegerType())
sdf.add('title_zh',StringType()).add('content_zh',StringType())
sdf.add('publish_date',TimestampType())設定監聽資料夾,該資料夾當產生新的CSV檔案時,spark會自動讀取到stream,路徑需要指明是hdfs:///或者file:///
rcsv=spark.readStream.options(header='true',multiline='true',inferSchema='true').schema(sdf).csv("file:///home/moon/文件/test")通過rcsv.isStreaming判斷是否是Stream
處理資料
處理資料分3步:
- 定義關鍵詞提取方法,定義方法選取係數最高的詞,剔除純數字
- 將提取方法構造成Udf
- 利用Dataframe的“轉換”方法呼叫Udf
最後選擇輸出模式、輸出目地,輸出結果。下面直接上程式碼,具體看註釋:
#引入jieba依賴
import jieba
import jieba.analyse
def getTopWord(words):
if(words==[]):
return ""
wordc=0
while (words[wordc].isdigit()):
if(wordc>=len(words)-1):
return words[wordc]
wordc+=1
return words[wordc]
def getKeyword(ctx):
#extract_tags方法有個可選topK=N引數,提取N個詞,但是這裡要剔除純數字要用另外的方法,所以使用它的預設值
word=getTopWord(jieba.analyse.extract_tags(ctx,withWeight=False))
return word;
#引數為(方法名,返回型別),方法可以是lambda,返回型別為必填。呼叫時,逐行呼叫udf
getKeyword_udf=udf(getKeyword,StringType())
#對['title_zh']這一列使用udf方法,並使用select生成新列,alias()定義別名,最後得到新的readStream
ncsv=rcsv.select('id','title_zh',getKeyword_udf(rcsv['title_zh']).alias('title_zh_keyword'),'publish_date')
#設定輸出模式為update,還有complete和Append;輸出到命令列。更詳細我也說不清,建議看官方文件。
query=ncsv.writeStream.outputMode('update').format("console").start()結果
上面的全部程式碼,在pyspark中,一條條輸入程式碼就行了,路徑根據自己實際替換,資料內容和型別可以根據自己喜好做調整。
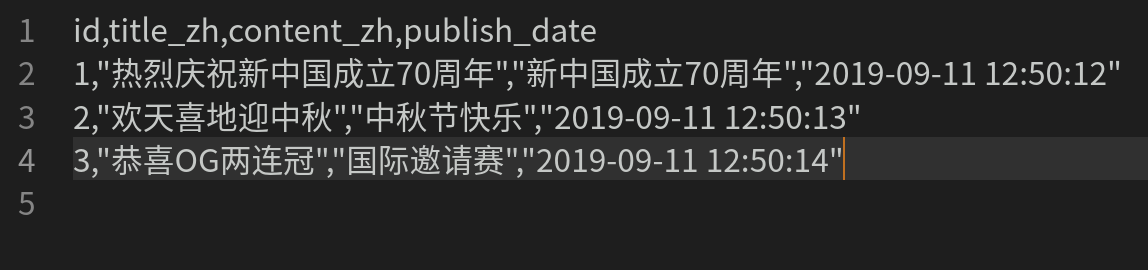
本例的CSV檔案如圖:
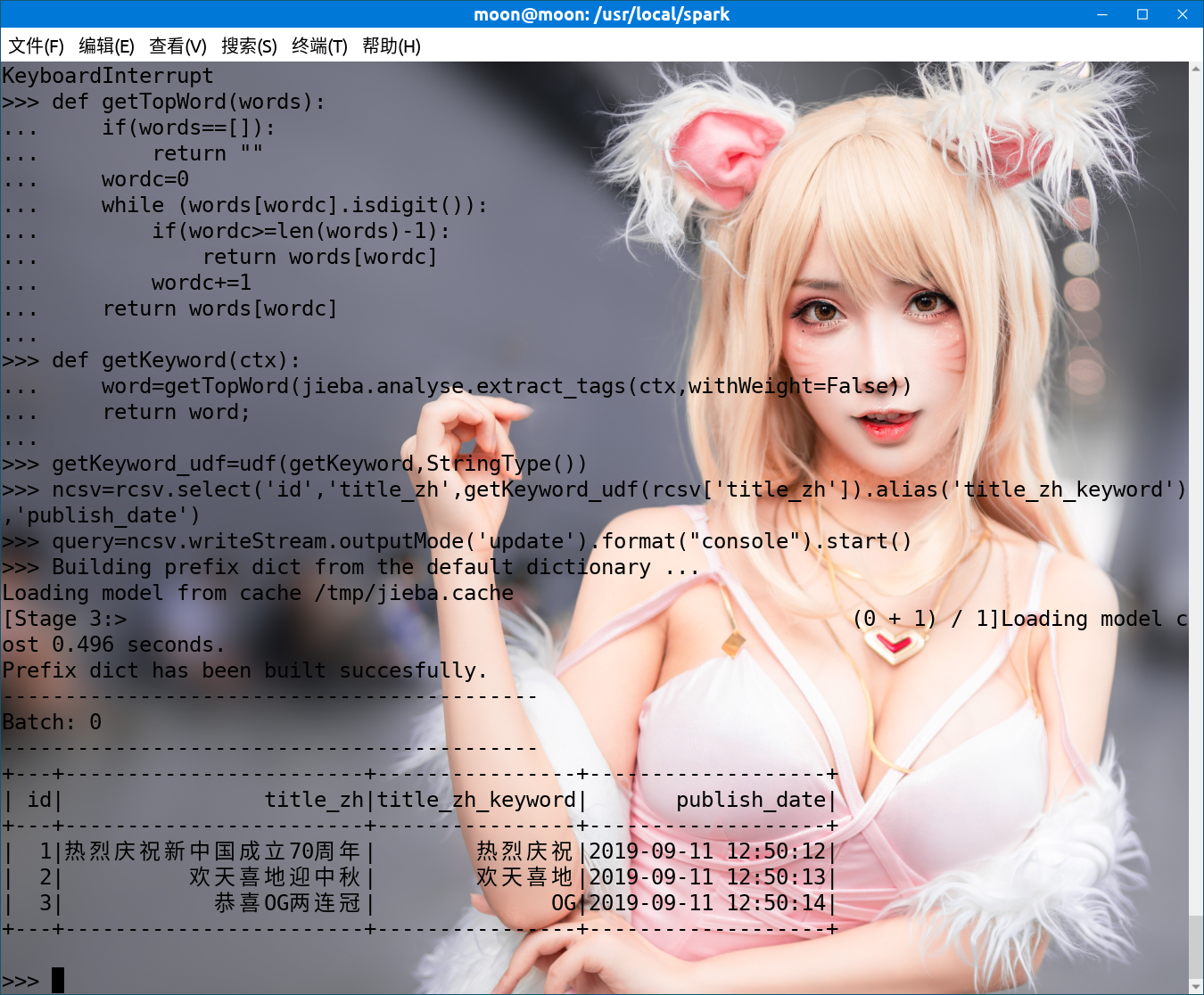
執行結果圖如下:
PS:小姐姐微博@只是簡言 ,侵刪~(反正我是不信有人