
又想 Cube 小,又想 Cube 跑得好?
“隨著維度數目的增加,Cuboid 的數量會爆炸式地增長。為了緩解 Cube 的構建壓力,Apache Kylin 引入了一系列的高階設定,幫助使用者篩選出真正需要的 Cuboid。這些高階設定包括聚合組(Aggregation Group)、聯合維度(Joint Dimension)、層級維度(Hierachy Dimension)和必要維度(Mandatory Dimension)等。”
正如上述官方文件提到的,在維度過多時,合理地使用聚合組能解決 Cube 膨脹率過大的問題。聽起來那麼美好,但是,不合理的聚合組設定將對效能產生災難性影響。
剪枝原理
Apache Kylin 的主要工作就是為源資料構建 N 個維度的 Cube,實現聚合的預計算。從理論上說,構建 N 個維度的 Cube 就會生成 2^N 個 Cuboid。
所以,只要降低最終 Cuboid 的數量,就可以減小膨脹率,達到對 Cube 剪枝的效果。

構建一個 4 個維度(A,B,C, D)的 Cube,就需要生成 16 個Cuboid。
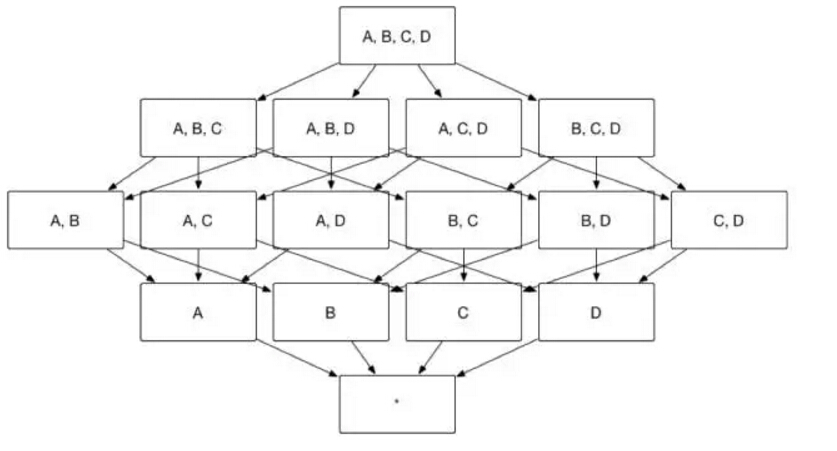
那麼問題來了,如果這 4 個維度(A,B,C, D),能夠根據某業務邏輯找出一個隱藏的規律,即:當進行聚合時,使用者僅僅關注維度 AB 組合和維度 CD 組合(即只會通過維度 A 和 B 或者 C 和 D 進行聚合,而不會通過 A 和 C、B 和 C、A 和 D、B 和 D 進行聚合),那麼就可以通過設定聚合組,使生成的 Cuboid 數目從 16 個縮減成 8 個(大大降低 Cube 膨脹率),如下圖所示。

上面這段內容來自 Kylin 公眾號的【技術帖】Apache Kylin 高階設定:聚合組(Aggregation Group)原理解析這篇文章中,值得對聚合組還不太瞭解的同學讀一讀。
但是,這裡好像完全沒有提到用於過濾資料(而不是聚合)的維度欄位,應該怎麼處理?
問題產生
某年某月某日,某業務人員突然發現某張報表的開啟速度極其緩慢,並上報給系統管理人員。隨後,通過對該報表產生的 SQL 進行篩查,發現瞭如下一條嫌疑重大的 SQL 語句,拖慢了整個報表的開啟速度。
select "A","B",sum("VALUE") from test_agg_group where "D" = 1 group by 1,2;
Kylin 日誌資訊:
==========================[QUERY]===============================
Query Id: 7fe300c2-211c-9429-eebf-b4cc57bfd679
SQL: select "A","B",sum("VALUE")
from test_agg_group
where "D" = 1
group by 1,2;
User: ADMIN
Success: true
Duration: 4.891
Project: 0000_reserved
Realization Names: [CUBE[name=test_agg_group]]
Cuboid Ids: [15]
Total scan count: 1000000
Total scan bytes: 51000000
Result row count: 100000
Accept Partial: true
Is Partial Result: false
Hit Exception Cache: false
Storage cache used: false
Is Query Push-Down: false
Is Prepare: false
Trace URL: null
Message: null
==========================[QUERY]===============================因為這是在測試環境(資料量不大)執行的 SQL,所以執行時間為 4.891 秒,生產環境真實的 SQL 執行時間已超過 40 秒,Total scan count 為千萬級。但是問題出現的原理和線上是一樣的。
問題定位
對於這種極慢的 SQL,我通常會觀察日誌資訊中的 Total scan count 與 Result row count 數值差異是否巨大。
如果差異極大(例如上述 SQL 的差異已經達到 10 倍),那就意味著該條 SQL 掃描了很多不會被作為最終結果的無用資料。
此時我發現只要刪掉那個 where 條件就可以很快的得到響應:
select "A","B",sum("VALUE")
from test_agg_group
group by 1,2Kylin 日誌資訊:
==========================[QUERY]===============================
Query Id: 2a9d7422-7268-2805-f1ac-a0fc544602c9
SQL: select "A","B",sum("VALUE")
from test_agg_group
group by 1,2
User: ADMIN
Success: true
Duration: 0.628
Project: 0000_reserved
Realization Names: [CUBE[name=test_agg_group]]
Cuboid Ids: [12]
Total scan count: 100000
Total scan bytes: 4900000
Result row count: 100000
Accept Partial: true
Is Partial Result: false
Hit Exception Cache: false
Storage cache used: false
Is Query Push-Down: false
Is Prepare: false
Trace URL: null
Message: null
==========================[QUERY]===============================很明顯,相比原 SQL,查詢的響應時間就提升了好幾個數量級。值得注意的是,Total scan count 也從原來的 100w 降到了 10w。
如果是一個傳統 RDBMS 的 DBA 看到這一幕,一定會感到疑惑,添加了 where 條件的 SQL 掃描的行數竟然比沒有 where 條件的 SQL 掃描的行數更多,簡直不可思議。
問題根源
看到這裡,有人可能已經逐漸忘記了標題。
回到這個 Cube 上看一看,它教科書般地使用了聚合組進行剪枝操作,完美的將 AB 和 CD 分到了兩個聚合組中,將膨脹率降低了一半。

因此,當我們以 AB 維度進行聚合,D 維度進行過濾,Kylin 在搜尋哪些行滿足 D=1 這個條件時,就無法通過下圖的方式進行搜尋了。
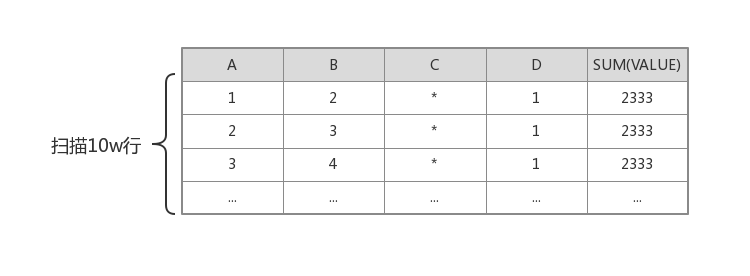
因為不會有任何一個 Cuboid(大約 10w 行)像上面這樣包含 ABD 三個維度和預計算好的值。所以最終 Kylin 會掃描下面這個 Cuboid (即包含 ABCD 四個欄位的 Cuboid,大約有 100w 行)來獲取最終資料。

這是一個在聚合組設定不當,且運氣還很差的情況下才能觸發的問題。
運氣差在哪?
- C 欄位的基數非常大
- D 欄位的基數非常小
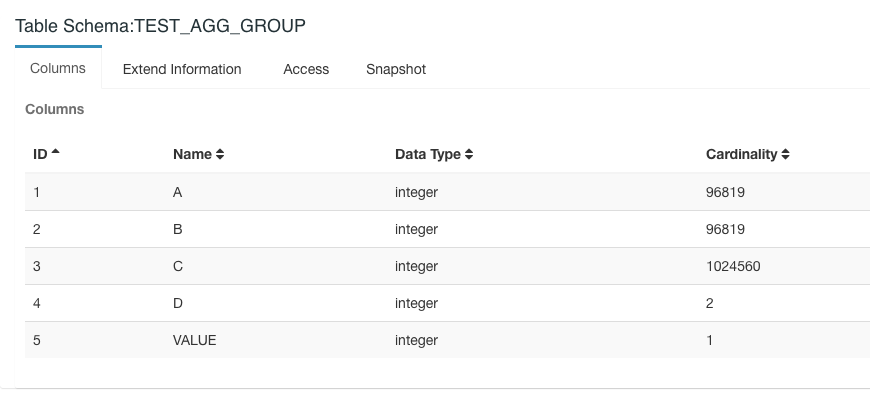
通過檢視 SQL 執行的日誌資訊我們也能看到。當以 D 欄位為過濾條件時,只能使用包含 ABCD 四個欄位的 Cuboid 進行掃描。
但是 C 欄位的基數非常大,所以該 Cuboid 的行數也就非常多。同時, C 欄位並沒有進行篩選,使用了基數非常小的 D 欄位進行了篩選(一共 1000w 行,D欄位有 500w 行是 1,500w 行是 2)。
最終導致要掃描完 Cuboid ABCD 的 100w 行才能得到計算結果。
那麼如果篩選欄位不是 D 而是 C,我們嘗試下估算下需要掃描多少行呢?
select "A","B",sum("VALUE")
from test_agg_group
where "C" = 100000
group by 1,2Kylin 日誌資訊:
==========================[QUERY]===============================
Query Id: e304ae37-f7ec-233b-d353-845e2feba908
SQL: select "A","B",sum("VALUE")
from test_agg_group
where "C" = 100000
group by 1,2
User: ADMIN
Success: true
Duration: 0.806
Project: 0000_reserved
Realization Names: [CUBE[name=test_agg_group]]
Cuboid Ids: [15]
Total scan count: 2
Total scan bytes: 102
Result row count: 2
Accept Partial: true
Is Partial Result: false
Hit Exception Cache: false
Storage cache used: false
Is Query Push-Down: false
Is Prepare: false
Trace URL: null
Message: null
==========================[QUERY]===============================僅需要掃描個位數的行即可,因為 C 欄位基數大,包含的重複值很少。而且我們可以看到,這條 SQL 和最初的 SQL 都是用了 Cuboid Id 為 15 的 Cuboid 進行查詢,也就是包含了 ABCD 四個欄位的 Cuboid。
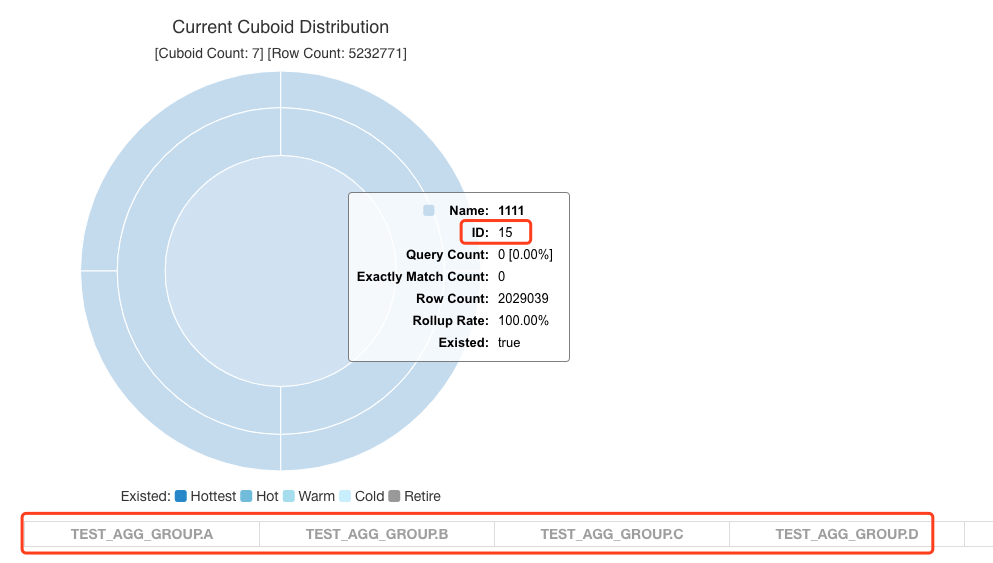
而僅用了 AB 兩個欄位,不使用 CD 中任何一個欄位進行篩選的 SQL 使用了 Cuboid Id 為 12 的 Cuboid。
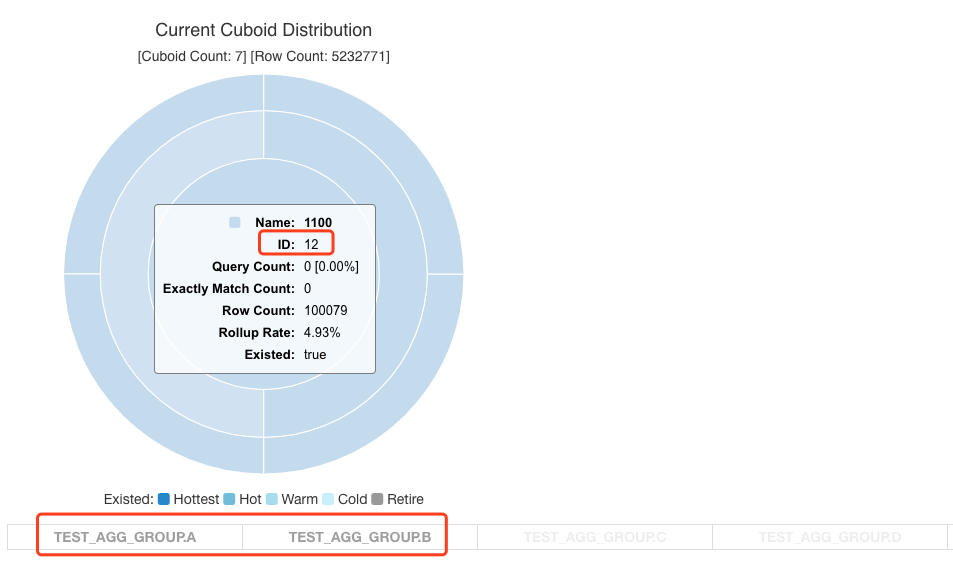
總結
分聚合組時,哪怕使用者僅僅關注維度 AB 組合和維度 CD 組合,但使用者會可能用 D 作為過濾條件來查詢 AB 組合,就一定要保證 ABD 要分到同一個聚合組當中。
當然了,如果欄位的基數不像例子中這麼極端,聚合組隨便怎麼分對效能影響應該都不大。但是,如果哪天墨菲定律突然上線,希望大家能想起本文。
