
【譯】How To Size Your Apache Flink® Cluster: A Back-of-the-Envelope Calculation
來自Flink Forward Berlin 2017的最受歡迎的會議是Robert Metzger的“堅持下去:如何可靠,高效地操作Apache Flink”。 Robert所涉及的主題之一是如何粗略地確定Apache Flink叢集的大小。 Flink Forward的與會者提到他的群集大小調整指南對他們有幫助,因此我們將他的談話部分轉換為部落格文章。 請享用!
Flink社群中最常見的問題之一是如何在從開發階段轉向生產階段時確定群集的大小。 對這個問題的明確答案當然是“它取決於”,但這不是一個有用的答案。 這篇文章概述了一系列問題,要求您提供一些可用作指導的數字。
做計算並建立基線
第一步是仔細考慮應用程式的運營指標,以獲得所需資源的基線。
要考慮的關鍵指標是:
- 每秒記錄數和每條記錄的大小
- 您擁有的不同key的數量以及每個key的狀態大小
- 狀態更新的數量和狀態後端的訪問模式
最後,更實際的問題是您的服務水平協議(SLA)與客戶的停機時間,延遲和最大吞吐量有關,因為這些直接影響您的容量規劃。
接下來,根據您的預算檢視您可用的資源。例如:
- 網路容量,考慮到也使用網路的任何外部服務,如Kafka,HDFS等。
- 您的磁碟頻寬,如果您依賴於基於磁碟的狀態後端(如RocksDB)(並考慮其他磁碟使用,如Kafka或HDFS)
- 機器的數量以及它們可用的CPU和記憶體
基於所有這些因素,您現在可以構建正常操作的基線,以及用於恢復追趕或處理負載峰值的資源緩衝區。我建議您在建立基線時考慮檢查點期間使用的資源。
示例:讓我們舉一些例子
我現在將計劃在假設的叢集上部署作業,以視覺化建立資源使用基準的過程。 這些數字是粗略的“背後”值,並且它們並不全面 - 在帖子的最後,我還將確定在進行此計算時我忽略的一些方面。
示例Flink流式處理作業和硬體
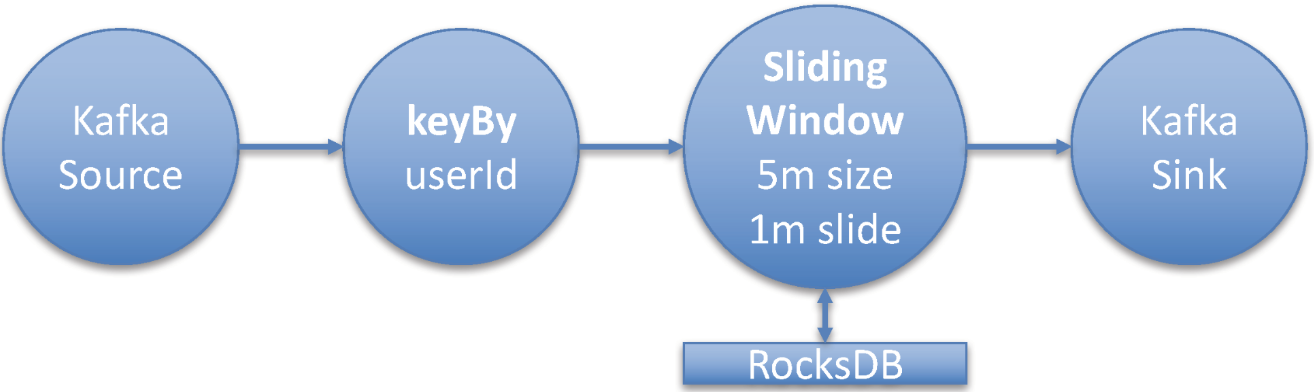
示例Flink Streaming作業拓撲
對於此示例,我將部署一個典型的Flink流式作業,該作業使用Flink的Kafka使用者從Kafka主題讀取資料。 然後使用鍵控聚合視窗運算子來變換流。 視窗操作符在5分鐘的時間視窗上執行聚合。 由於總是有新資料,我將視窗配置為一個滑動視窗,滑動時間為1分鐘。
這意味著我將獲得每分鐘更新過去5分鐘的聚合。 流式傳輸作業為每個userId建立一個聚合。 從Kafka主題消耗的訊息的大小(平均)為2 KB。
吞吐量是每秒100萬條訊息。 要了解視窗運算子的狀態大小,您需要知道不同鍵的數量。 在這種情況下,它是userIds的數量,即500,000,000個唯一身份使用者。 對於每個使用者,您計算四個數字,儲存為長(8個位元組)。
讓我們總結一下這項工作的關鍵指標:
- Message size: 2KB
- Throughput: 1,000,000 msg/sec
- Distinct keys: 500,000,000 (aggregation in window: 4 longs per key)
- Checkpointing: Once every minute.
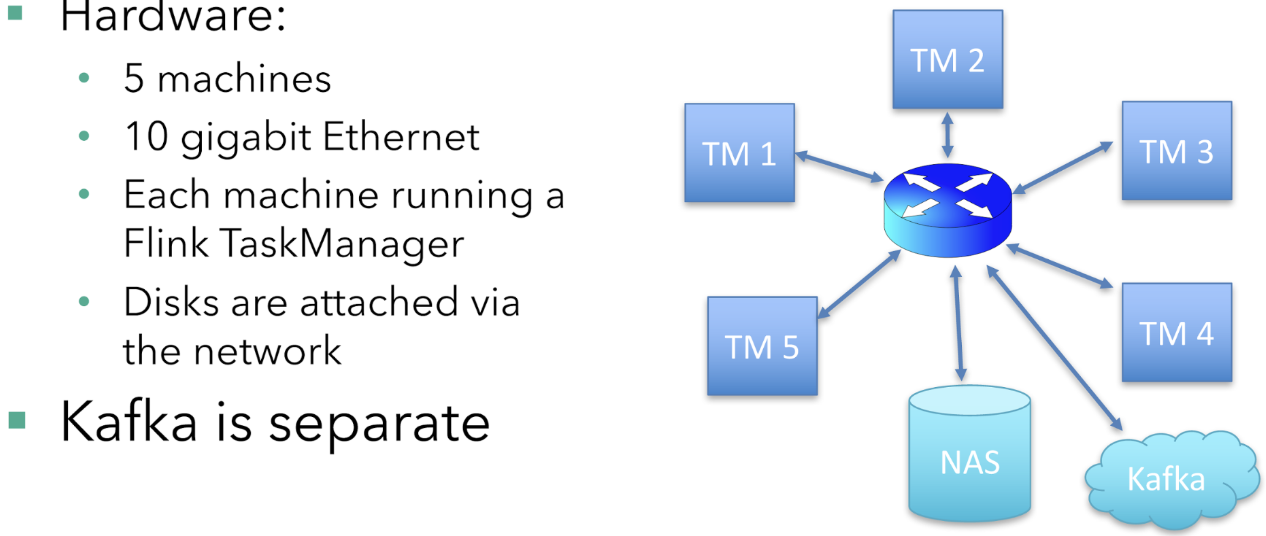
假設硬體設定
執行該作業的機器有五臺,每臺機器都執行Flink TaskManager(Flink的工作節點)。 磁碟是網路連線的(在雲設定中很常見),從主交換機到執行TaskManager的每臺機器都有一個10千兆乙太網連線。 Kafka broker分佈在不同的機器上執行。
每臺機器有16個CPU核心。 為簡單起見,我不會考慮CPU和記憶體要求。 在現實世界中,根據您的應用程式邏輯和使用中的狀態後端,您需要注意記憶體。 此示例使用基於RocksDB的狀態後端,該後端功能強大且記憶體要求低。
單機的視角
要了解整個作業部署的資源需求,最簡單的方法是首先關注一臺機器和一臺TaskManager中的操作。 然後,您可以使用從一臺計算機派生的數字來計算總體資源需求。
預設情況下(如果所有運算子具有相同的並行性且沒有特殊的排程限制),則每個計算機上都會執行流式作業的所有運算子。
在這種情況下,Kafka源(或消費者),視窗操作符和Kafka接收器(或生產者)都在五臺機器中的每臺機器上執行。
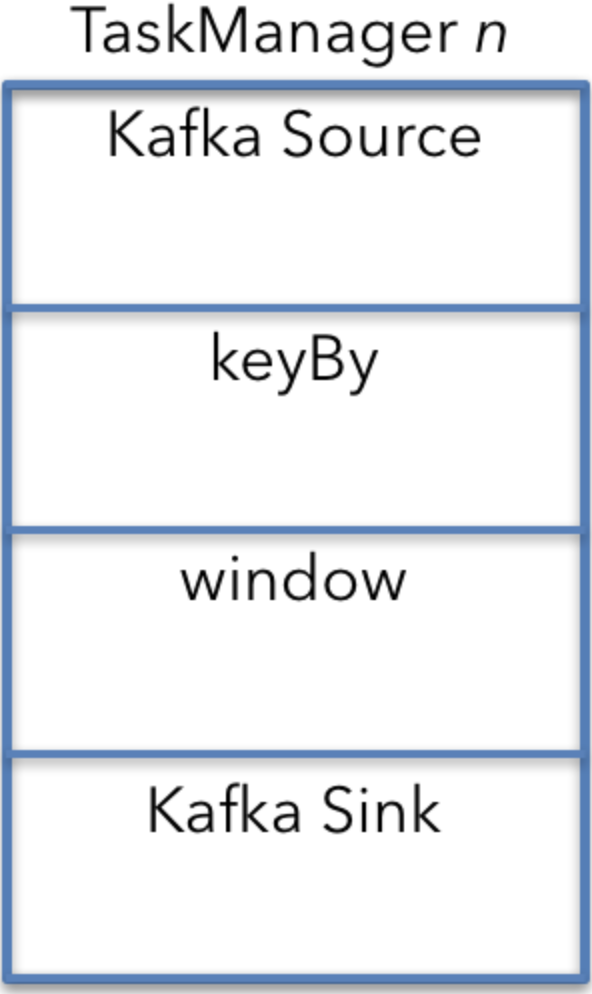
機器視角 - TaskManager n
keyBy是上圖中的一個單獨的運算子,因此計算資源需求更容易。 實際上,keyBy是一個API構造,並轉換為Kafka源和視窗運算子之間連線的配置屬性。
我現在將從上到下遍歷每個運營商,以瞭解他們的網路資源需求。
The Kafka source
要計算單個Kafka源接收的資料量,首先計算聚合Kafka輸入。 源每秒接收1,000,000條訊息,每條訊息2KB。
2KB x 1,000,000/s = 2GB/s
將2GB / s除以機器數量(5)會產生以下結果:
2GB/s ÷ 5 machines = 400MB/s
群集中執行的5個Kafka源中的每一個都接收平均吞吐量為400 MB / s的資料。
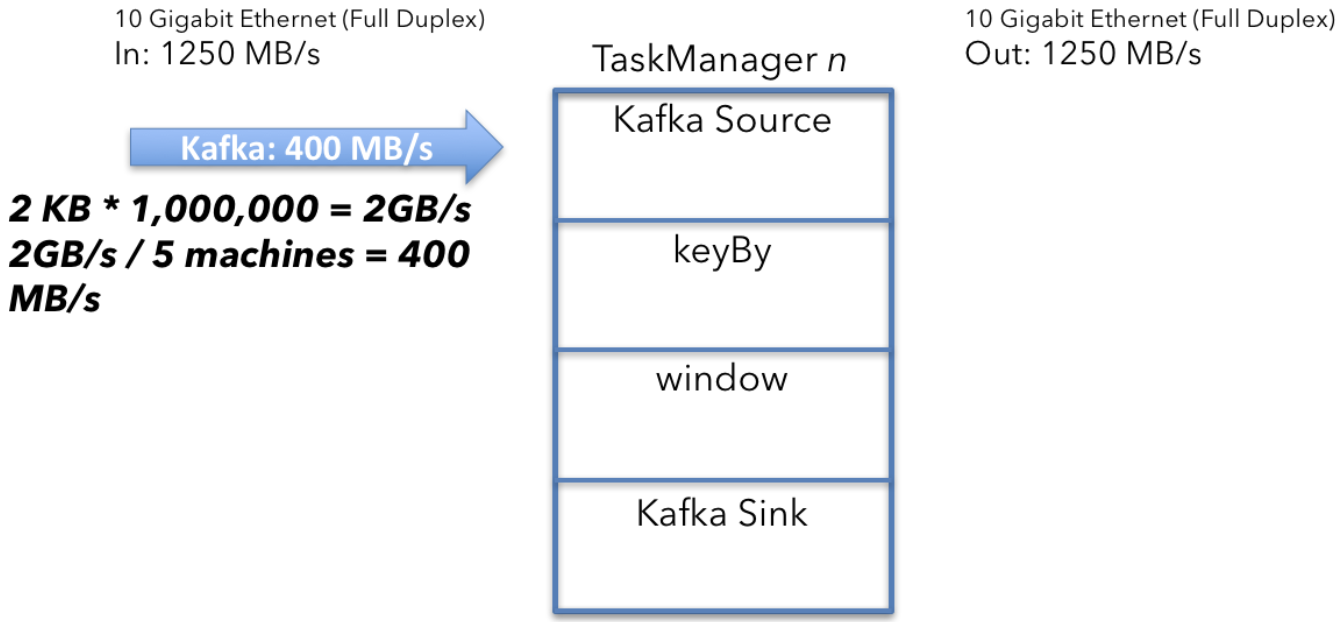
The Kafka source calculation
混洗和分割槽
接下來,您需要確保具有相同key的所有事件(在本例中為userId)最終位於同一臺計算機上。 您正在讀取的Kafka主題中的資料可能會根據不同的分割槽方案進行分割槽。
混洗過程將具有相同key的所有資料傳送到一臺計算機,因此您將來自Kafka的400MB / s資料流拆分為userId分割槽流:
400MB/s ÷ 5 machines = 80MB/s
平均而言,您必須向每臺計算機發送80 MB / s的資料。 這個分析是從一臺機器的角度來看的,這意味著一些資料已經在指定的目標機器上,因此減去80MB / s來解釋:
原文連線:https://www.ververica.com/blog/how-to-size-your-apache-flink-cluster-g