
邊緣計算:萬物互聯時代新型計算模型
目錄
- 寫在前面
- 背景
- 現有的問題
- 定義
- 優勢
- 挑戰
- 可程式設計性
- 命名規則
- 資料抽象
- 服務管理
- 資料隱私保護及安全
- 理論基礎
- 商業模型
- 相關研究
- 總結
- 參考
寫在前面
本文是閱讀論文《邊緣計算:萬物互聯時代新型計算模型》的筆記。
背景
目前,大資料處理已經從以雲端計算為中心的集中式處理時代(把2005-2015年稱之為集中式大資料處理時代)正在跨入以萬物互聯為核心的邊緣計算時代(稱之為邊緣式大資料處理時代)。集中式大資料處理時代,更多的是集中式儲存和處理大資料,其採取的方式是建造雲端計算中心,並利用雲端計算中心超強的計算能力來集中式解決計算和儲存問題。相比而言,在邊緣式大資料處理時代,網路邊緣裝置會產生海量實時資料;並且,這些邊緣裝置將部署支援實時資料處理的邊緣計算平臺為使用者提供大量服務或功能介面,使用者可通過呼叫這些介面來獲取所需的邊緣計算服務。
現有的問題
隨著物聯網(Internet of things, IoT) 的快速發展和4G/5G無線網路的普及,萬物互聯(Internet of everything, IoE) 的時代已經到來,網路邊緣裝置數量的迅速增加,使得該類裝置所產生的資料已達到澤位元組(ZB)級別。以雲端計算模型為核心的集中式大資料處理時代,其關鍵技術已經不能高效處理邊緣裝置所產生的資料。主要存在以下四個問題:
- 線性增長的集中雲計算能力無法匹配爆炸式增長的海量邊緣資料;
- 從網路邊緣裝置傳輸海量資料到雲中心導致網路傳輸頻寬的負載量急劇增加,造成較長的網路延遲;
- 網路邊緣資料涉及個人隱私,使得隱私安全問題變得尤為突出;
- 有限電能的網路邊緣裝置傳輸資料到雲中心消耗較大電能。
定義
邊緣計算是指在網路邊緣執行計算的一種新型計算模型,邊緣計算中邊緣的下行資料表示雲服務,上行資料表示萬物互聯服務,而邊緣計算的邊緣是指從資料來源到雲端計算中心路徑之間的任意計算和網路資源。
圖1中,藍色實線表示資料生產者傳送源資料到雲中心,紅色實線表示資料消費者向雲中心傳送使用請求,紅色虛線表示雲中心將結果反饋給資料消費者。

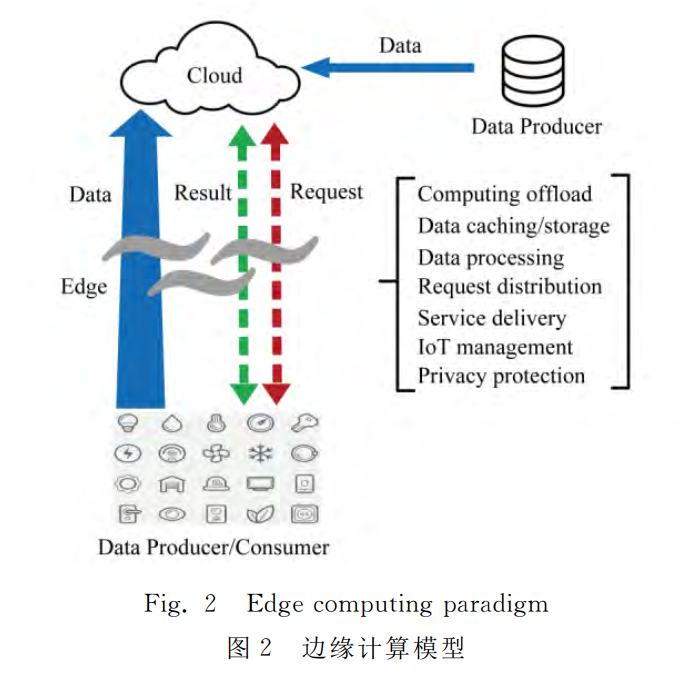
圖2表示基於雙向計算流的邊緣計算模型。雲端計算中心不僅從資料庫收集資料,也從感測器和智慧手機等邊緣裝置收集資料。這些裝置兼顧資料生產者和消費者.因此,終端裝置和雲中心之間的請求傳輸是雙向的。網路邊緣裝置不僅從雲中心請求內容及服務,而且還可以執行部分計算任務,包括資料儲存、處理、快取、裝置管理、隱私保護等。
優勢
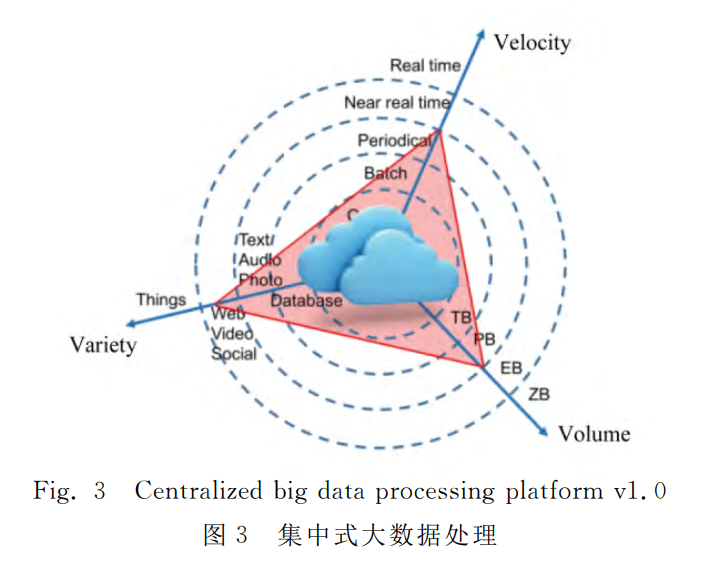
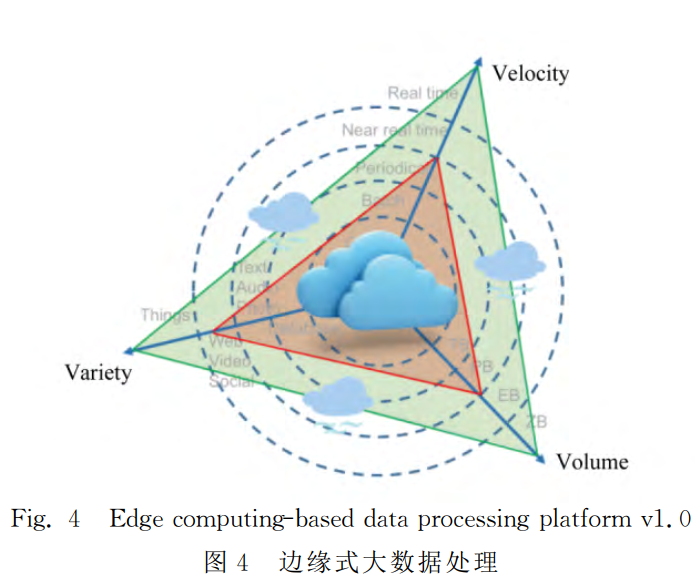
邊緣計算模型將原有云計算中心的部分或全部計算任務遷移到資料來源的附近執行。從大資料的3V特點,即資料量(volume)、時效性(velocity)、多樣性(variety),通過對比雲端計算模型為代表的集中式大資料處理(如圖3所示)和以邊緣計算模型為代表的邊緣式大資料處理(如圖4所示)時代不同資料特徵來闡述邊緣計算模型的優勢。
挑戰
在邊緣計算研究中可能遇到的迫切需要解決的7個關鍵問題,主要包括:可程式設計性、命名規則、資料抽象、服務管理、資料隱私保護及安全、理論基礎以及商業模式。
可程式設計性
雲端計算模型下應用程式開發的一個優點是基礎設施對使用者透明。使用者程式通常在目標平臺上編寫和編譯,在雲伺服器上執行。在邊緣計算模型中,需要將部分或全部的計算任務從雲端遷移到邊緣節點,而邊緣節點大多是異構平臺,每個節點上的執行時環境可能有所差異,因此,在邊緣計算模型下部署使用者應用程式時,程式設計師將遇到較大的困難。而現有傳統程式設計方式MapReduce,Spark等均不適合,需研究基於邊緣計算的新型程式設計方式。
命名規則
在邊緣計算模型中,邊緣裝置數目巨大,與計算機系統的命名規則類似,邊緣計算的命名規則對程式設計、定址、識別和資料通訊具有非常重要的作用,而當前暫無較為高效的命名規則。邊緣計算的命名規則不僅需要滿足異構裝置間的通訊的需求,還需要滿足移動裝置、高度動態的網路拓撲結構、隱私安全等需求。傳統的命名機制如DNS,URI滿足大多數的網路結構,但卻不能靈活地為動態邊緣網路提供服務,原因在於大多數的邊緣裝置具有高度移動性和有限資源,而基於IP的命名規則,因複雜性和開銷太大而難以應用到邊緣計算中。
資料抽象
邊緣計算模型中使用資料時會遇到3種挑戰:
- 不同裝置所傳輸資料格式的多樣性。
- 資料抽象程度的不確定性。如果資料抽象過濾較多的源資料,將導致一些應用或服務程式因無法獲得足夠資訊而執行失敗;反之,若保留大量源資料,資料儲存和管理將是系統開發者所面臨的另一種挑戰。此外,邊緣裝置傳送的資料具有不可靠性,如何從不可靠資訊源中抽象出有用的資訊仍是一個技術挑戰。
- 資料抽象的適用性。由於邊緣裝置的異構性,資料表示及操作也有所不同,這將成為通用資料抽象的障礙。
服務管理
邊緣計算的服務管理方面,任意一種可靠系統均具有4種特徵:即差異性(differentiation)、可擴充套件性(extensibility)、隔離性(isolation)及可靠性(reliability)。
- 差異性:網路的邊緣會部署多種服務,而這些服務需要有不同的優先順序。如健康相關的服務高於其他娛樂服務的優先順序。
- 可擴充套件性:需要設計一種靈活且可擴充套件的邊緣作業系統來實現服務層的管理。
- 隔離性:由於在邊緣計算模型中存在多個應用共享同一種資料,當某個應用程式崩潰時不能影響到其他需要訪問該資料的應用程式。另外如何隔離第三方程式與使用者的隱私資料也是一個挑戰。
- 可靠性:從服務的角度來看,當服務失敗時要能夠快速診斷故障或者恢復服務;從系統的角度來看,能夠在系統層部署如故障檢測、裝置替換和資料質量檢測等服務;從資料的角度來看,要能夠在資料通訊不可靠的情況下,提供可靠的服務。
資料隱私保護及安全
資料隱私保護及安全是邊緣計算提供的一種重要服務。相比將所有的資料處理過程都在雲端計算中心進行,在資料來源附近進行計算是保護隱私和資料安全的一種有效方法。
理論基礎
邊緣計算的理論基礎當前並不成熟,需要綜合計算、資料通訊、儲存及能耗優化等多學科已有比較完善的理論基礎,提出綜合性或多維度的邊緣計算理論,這是目前在開展邊緣計算研究中首要解決的關鍵性問題。合理的邊緣計算理論基礎對學界和產業界未來更好地開展基於邊緣計算模型的應用服務研究和開發工作具有極為重要的指導意義。
商業模型
邊緣計算橫跨資訊科技(IT)、通訊技術(CT)等多個領域,涉及軟硬體平臺、網路聯接、資料聚合、晶片、感測、行業應用等多個產業鏈角色.邊緣計算的商業模型更多的將會不僅是以服務為驅動,使用者請求相應的服務,而更多的將以資料為驅動。
相關研究
隨著大資料時代的發展,為了解決雲端計算中心計算負載和資料傳輸頻寬的問題,研究者也提出多種關於計算任務從雲端計算中心遷移到網路的邊緣的技術,其中主要典型模型包括:分散式資料庫模型、P2P模型、CDN模型、移動邊緣計算模型、霧計算模型以及海雲端計算。
總結
邊緣計算模型與雲端計算模型並不是非此即彼的關係,而是相輔相成的關係,邊緣式大資料處理時代是邊緣計算模型與雲端計算模型的相互結合的時代,二者的有機結合將為萬物互聯時代的資訊處理提供較為完美的軟硬體支撐平臺。
參考
施巍鬆,孫輝,曹傑,等.邊緣計算:萬物互聯時代新型計算模型[J].計算機研究與發展,2017,54(5):904-