
單執行緒Redis效能為何如此之高?
文章原創於公眾號:程式猿周先森。本平臺不定時更新,喜歡我的文章,歡迎關注我的微信公眾號。

實際專案開發中現在無法逃避的一個問題就是快取問題,而快取問題也是面試必問知識點之一,如果面試官好一點可能會簡單的問你二八定律或者熱資料和冷資料,但是如果問的深入一點可能就會問到快取更新、降級、預熱、雪崩、穿透等問題,而這些問題可能會攔下大部分平時不怎麼關注快取的朋友,這些問題實際上都和快取伺服器息息相關,我們日常中經常使用的快取伺服器一般有兩種:Redis和Memcached。本篇開始正式進入Redis系列文章,本篇主要講講Redis使用單執行緒為何速度還能如此之快?
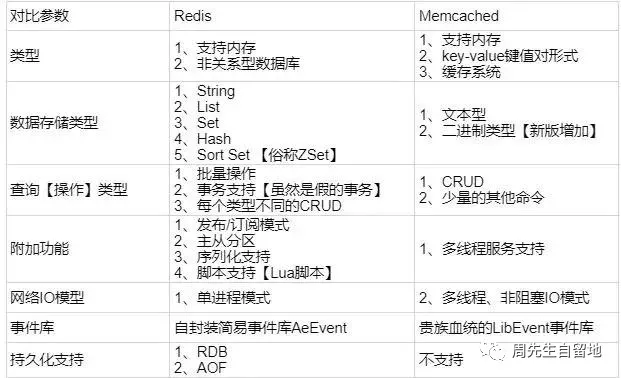
既然談到快取伺服器有兩種,那我們為何要選擇Redis呢?Redis與Memcached兩者之間有何區別呢?
Redis 和 Memcached 的區別
Redis支援常見資料型別:Redis 不僅僅支援簡單的 key/value 型別的資料,同時還提供string(字串)、list(連結串列)、set(集合)、zset(有序集合)和hash(雜湊型別)等資料結構的儲存。而Memcache 只支援簡單的資料型別 String。
Redis 支援資料的持久化,可以將記憶體中的資料保持在磁碟中,重啟的時候可以再次載入進行使用,而 Memecache 把資料全部存在記憶體之中。
叢集模式:Memcached 沒有原生的叢集模式,需要依靠客戶端來實現往叢集中分片寫入資料;但是 Redis 目前是原生支援 Cluster 模式的。
Memcached 是多執行緒,非阻塞 IO 複用的網路模型;Redis 使用單執行緒的多路 IO 複用模型。
Redis是一個key-value儲存系統。它支援儲存的value型別相對更多,包括string(字串)、list(連結串列)、set(集合)、zset(有序集合)和hash(雜湊型別)。這些資料型別都支援push/pop、add/remove及取交集並集和差集及更豐富的操作,而且這些操作都是原子性的。在此基礎上,redis支援各種不同方式的排序。為了保證效率,資料都是快取在記憶體中。區別的是redis會週期性的把更新的資料寫入磁碟或者把修改操作寫入追加的記錄檔案,並且在此基礎上實現了主從同步。簡單來說 Redis 就是一個數據庫,不過與傳統資料庫不同的是 Redis 的資料是存在記憶體中的,所以存寫速度非常快,因此 Redis 被廣泛應用於快取方向。Redis 也經常用來做分散式鎖。Redis 提供了多種資料型別來支援不同的業務場景。除此之外,Redis 支援事務 、持久化、LUA 指令碼、LRU 驅動事件、多種叢集方案。Redis中常用的資料型別實際上只有5種:String、Hash、List、Set、ZSet,我們可以先看下這五種基本資料型別的用法:
String
- 常用命令:set、get、decr、incr、mget 等。
String 資料結構是簡單的 Key-Value 型別,Value 可以是string或者數字。常規 Key-Value 快取應用;常規計數:部落格數,閱讀數等。
Hash
- 常用命令:hget、hset、hgetall 等。
Hash 特別適合用於儲存物件。
List
- 常用命令:lpush、rpush、lpop、rpop、lrange 等。
連結串列是 Redis 最重要的資料結構之一,Redis List 為一個雙向連結串列,支援反向查詢和遍歷,更方便操作,不過帶來了額外的記憶體開銷。
Set
- 常用命令:sadd、spop、smembers、sunion 等。
Set 其實和List都是列表的選項,Set 是可以自動去重的。當需要儲存一個不出現重複資料的列表資料,Set 是一個最好的選擇。你可以基於 Set 輕易實現交集、並集、差集的操作。
Sorted Set
- 常用命令:zadd、zrange、zrem、zcard 等。
Sorted Set 相比Set增加了一個權重引數 Score,使得集合中的元素能夠按 Score 進行有序排列。
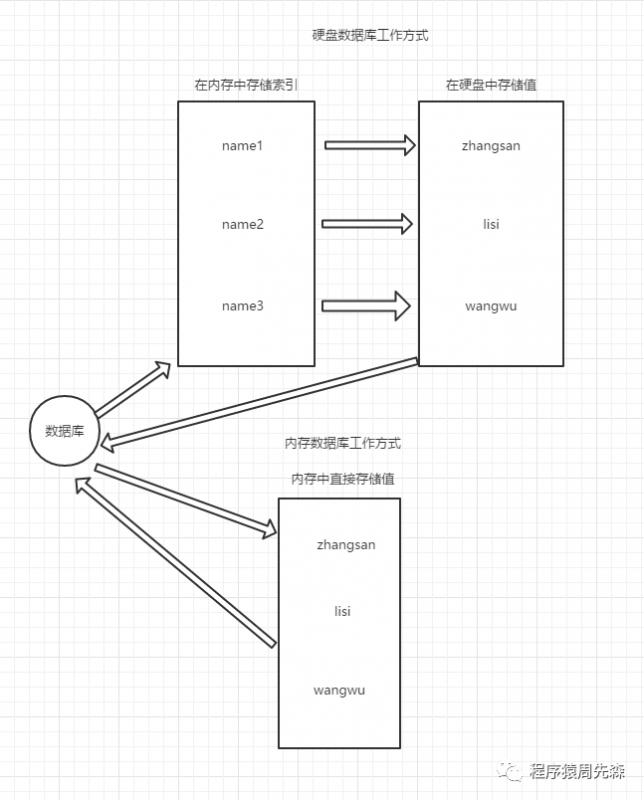
資料庫工作模式如果按照儲存方式進行劃分可以分成兩種:硬碟資料庫和記憶體資料庫。Redis讀寫資料之所以如此之快實際上就是由於Redis將資料儲存在記憶體中,所以在讀寫資料時不會受到硬碟I/O速度限制,所以讀寫速度自然很快。而硬碟資料庫則是在記憶體中儲存一個索引,然後根據索引去硬碟中查詢對應的值,所以效率肯定會相對更慢。
Redis基於記憶體採用單執行緒單程序模型的Key-Value資料庫,經過官方測試每秒查詢次數可以高達100000+,那為什麼Redis如此快呢?最關鍵的一點其實剛才已經提到過,因為Redis完全基於記憶體,Redis接收到的大部分請求都是直接操作記憶體就可以完成的,所以處理請求非常迅速,而且Redis中使用單執行緒,避免了不必要的上下文切換和競爭鎖機制,也不會出現頻繁切換執行緒導致CPU消耗,不會存在多執行緒的死鎖等一系列問題。在Redis中使用多路複用I/O模型,而不是非阻塞I/O,非阻塞I/O之前在Nginx提到過,所以我們不重複介紹,我們重點看看多路I/O複用模型。
多路I/O複用模型實際上是使用select、poll、epoll同時監聽多個流的I/O事件,在無I/O事件時也就是空閒狀態下會將執行緒阻塞,當有I/O事件需要處理時,執行緒就是從阻塞狀態下喚醒,然後使用epoll輪詢一遍所有發生I/O事件的流。多路複用實際上還就是說多個網路連線複用同一個執行緒,採用多路I/O複用技術可以讓單個程序高效的處理多個連線請求,且Redis在記憶體中對資料進行操作,所以資料操作速度非常快,所以速度不會受到瓶頸,所以Redis才可以具有很高的吞吐量及效能。Redis的瓶頸主要來源於機器記憶體或網路頻寬,CPU不是Redis的瓶頸所在,再加上單執行緒更易於實現,所以順理成章Redis採用單執行緒的方式,但是使用單執行緒的方式是無法發揮多核CPU的優勢的,比如在進行比較耗時的操作時會使得Redis併發量下降,因為單執行緒所以某一時刻只能處理一個操作,所以執行耗時操作會導致併發量的下降,有一個簡單的解決方案就是在多核CPU下可以單機開多個Redis例項來解決這個問題。
歡迎關注公眾號:程式猿周先森。

相關推薦
單執行緒Redis效能為何如此之高?
文章原創於公眾號:程式猿周先森。本平臺不定時更新,喜歡我的文章,歡迎關注我的微信公眾號。 實際專案開發中現在無法逃避的一個問題就是快取問題,而快取問題也是面試必問知識點之一,如果面試官好一點可能會簡單的問你二八定律或者熱資料和冷資料,但是如果問的深入一點可能就會問到快取更新、降級、預熱、雪崩、穿透等問題,
Redis單執行緒為何速度如此之快
Redis之所以執行速度很快,主要依賴於以下幾個原因: (一)純記憶體操作,避免大量訪問資料庫,減少直接讀取磁碟資料,redis 將資料儲存在記憶體裡面,讀寫資料的時候都不會受到硬碟 I/O 速度的限制,所以速度快; (二)單執行緒操作,避免了不必要的上下文切換和競爭條件
Redis之單執行緒模型
Redis客戶端對服務端的每次呼叫都經歷了傳送命令,執行命令,返回結果三個過程。其中執行命令階段,由於Redis是單執行緒來處理命令的,所有每一條到達服務端的命令不會立刻執行,所有的命令都會進入一個佇列中,然後逐個被執行。並且多個客戶端傳送的命令的執行順序是不確定的。但是可以確定的是不會有兩條命
Redis面試題(一): Redis到底是多執行緒還是單執行緒?
0. redis單執行緒問題 單執行緒指的是網路請求模組使用了一個執行緒(所以不需考慮併發安全性),即一個執行緒處理所有網路請求,其他模組仍用了多個執行緒。 1
Redis 是單執行緒的,為什麼這麼快?
近乎所有與Java相關的面試都會問到快取的問題,基礎一點的會問到什麼是“二八定律”、什麼是“熱資料和冷資料”,複雜一點的會問到快取雪崩、快取穿透、快取預熱、快取更新、快取降級等問題,這些看似不常見的概念,都與我們的快取伺服器相關,一般常用的快取伺服器有Redis、Memcached等,而筆者目前最常
為什麼說Redis是單執行緒的以及Redis為什麼這麼快?
一、前言 近乎所有與Java相關的面試都會問到快取的問題,基礎一點的會問到什麼是“二八定律”、什麼是“熱資料和冷資料”,複雜一點的會問到快取雪崩、快取穿透、快取預熱、快取更新、快取降級等問題,這些看似不常見的概念,都與我們的快取伺服器相關,一般常用的快取伺服器有Redis、Memcached等,而筆者目
Redis單執行緒的原因
一、前言 近乎所有與Java相關的面試都會問到快取的問題,基礎一點的會問到什麼是“二八定律”、什麼是“熱資料和冷資料” ,複雜一點的會問到快取雪崩、快取穿透、快取預熱、快取更新、快取降級等問題,這些看似不常見的概念,都與我們的快取伺服器相關,一般常用的快取伺服器有Redis、Memcached等
Redis核心技術---單執行緒
以前一直有個誤區,以為:高效能伺服器 一定是 多執行緒來實現的 原因很簡單因為誤區二導致的: 多執行緒 一定比 單執行緒 效率高。其實不然。 redis 核心就是 如果我的資料全都在記憶體裡,我單執行緒的去操作 就是效率最高的,為什麼呢,因為多執行緒的本質就是 CPU 模擬出來多個
提高C++效能的程式設計技術筆記:單執行緒記憶體池+測試程式碼
頻繁地分配和回收記憶體會嚴重地降低程式的效能。效能降低的原因在於預設的記憶體管理是通用的。應用程式可能會以某種特定的方式使用記憶體,並且為不需要的功能付出效能上的代價。通過開發專用的記憶體管理器可以解決這個問題。對專用記憶體管理器的設計可以從多個角度考慮。我們至少可以想到兩個方面:大小和併發。
Redis是單執行緒
一、前言 近乎所有與Java相關的面試都會問到快取的問題,基礎一點的會問到什麼是“二八定律”、什麼是“熱資料和冷資料” ,複雜一點的會問到快取雪崩、快取穿透、快取預熱、快取更新、快取降級等問題,這些看似不常見的概念,都與我們的快取伺服器相關,一般常用的快取伺服器有Redis、Memcached等
Redis單執行緒理解
簡介 從接觸Redis到現在,一直被它的單執行緒問題困擾,這對於一個苛求原理的我來說是種折磨,今天吃飯途中看了幾篇部落格,茅塞頓開。 個人理解 redis分客戶端和服務端,一次完整的redis請求事件
redis面試題集錦 Redis為什麼使用單程序單執行緒方式也這麼快
1為什麼Redis需要把所有資料放到記憶體中? Redis為了達到最快的讀寫速度將資料都讀到記憶體中,並通過非同步的方式將資料寫入磁碟。所以Redis具有快速和資料持久化的特性。如果不將資料放到記憶體中,磁碟的I/O速度會嚴重影響redis的效能。在記憶體越來越便宜的今天,redis將會越來越受歡迎。如果設
整理總結 --- Redis 為什麼說Redis是單執行緒的
那麼為什麼Redis是單執行緒的 Redis 所需資源 CPU, 記憶體, 網路I/O 官方FAQ表示,因為Redis是基於記憶體的操作,CPU不是Redis的瓶頸,Redis的瓶頸最有可能是機器記憶體的大小或者網路頻寬。既然單執行緒容易實現,而且CPU不會成為瓶頸,那就順理成章
redis單執行緒處理,以及單雙執行緒的優缺點
Redis快的主要原因是: 完全基於記憶體 資料結構簡單,對資料操作也簡單 使用多路 I/O 複用模型 單程序單執行緒好處 程式碼更清晰,處理邏輯更簡單 不用去考慮各種鎖的問題,不存在加鎖釋放鎖操作,沒有因為可能出現死鎖而導致的效能消耗 不存在
Java多執行緒之—Synchronized方式和CAS方式實現執行緒安全效能對比
效能比較猜想 1.大膽假設 在設計試驗方法之前,針對Synchronized和CAS兩種方式的特點,我們先來思考一下兩種方式效率如何? 首先,我們在回顧一下兩種方式是如何保證執行緒安全的。Synchronized方式通過大家應該很熟悉,他的行為非常悲觀,只要有一個執行緒進
為什麼說Redis單執行緒效率高
Redis效率高的主要原因有下面幾個: 基於記憶體操作,速度非常快 採用單執行緒,避免了上下文的切換導致消耗CPU 採用單執行緒,不用去考慮各種加鎖釋放鎖的問題 使用IO多路複用模型,非阻塞IO Redis採用的是基於記憶體的採用的是單程序單執行緒模型的
redis單執行緒模型分析
redis原理 redis採用自己實現的事件分離器,效率比較高,內部採用非阻塞的執行方式,吞吐能力比較大。 不過,因為一般的記憶體操作都是簡單存取操作,執行緒佔用時間相對較短,主要問題在io上,因此,redis這種模型是合適的,但是如果某一個執行緒出現問題導致執行緒佔用很長時間,那麼reids的單
關於redis的單執行緒與後臺執行緒的原始碼分析
前言: 通常大家都會說redis是單執行緒的,這個理解其實也沒錯。 redis的命令處理基本上都是單執行緒處理的,除了個別任務會fork子程序進行處理。 分析版本:redis 3.0.7 其實r
多程序單執行緒模型與單程序多執行緒模型之爭
伺服器,事件 多程序單執行緒模型典型代表:nginx 單程序多執行緒模型典型代表:memcached 另外redis, mongodb也可以說是走的“多程序單執行緒模”模型(叢集),只不過作為資料庫伺服器,需要進行防寫,只提供了讀同步。 原因很簡單,因為伺服器的發展大部分都
單程序單執行緒的Redis如何能夠高併發
1、基本原理 採用多路 I/O 複用技術可以讓單個執行緒高效的處理多個連線請求(儘量減少網路IO的時間消耗) (1)為什麼不採用多程序或多執行緒處理?多執行緒處理可能涉及到鎖 多執行緒處理會涉及到執行緒切換而消耗CPU(2)單執行緒處理的缺點?無法發揮多核CPU效能,不過可以