
指標生成網路(Pointer-Generator-Network)原理與實戰
0 前言
本文主要內容:介紹Pointer-Generator-Network在文字摘要任務中的背景,模型架構與原理、在中英文資料集上實戰效果與評估,最後得出結論。參考的《Get To The Point: Summarization with Pointer-Generator Networks》以及多篇部落格均在文末給出連線,文中使用資料集已上傳百度網盤,程式碼已傳至GitHub,讀者可以在文中找到相應連線,實際操作過程中確實遇到很多坑,並未在文中一一指明,有興趣的讀者可以留言一起交流。由於水平有限,請讀者多多指正。
隨著網際網路飛速發展,產生了越來越多的文字資料,文字資訊過載問題日益嚴重,對各類文字進行一個“降 維”處理顯得非常必要,文字摘要便是其中一個重要的手段。文字摘要旨在將文字或文字集合轉換為包含關鍵資訊的簡短摘要。按照輸出型別可分為抽取式摘要和生成式摘要。抽取式摘要從源文件中抽取關鍵句和關鍵片語成摘要,摘要全部來源於原文。生成式摘要根據原文,允許生成新的詞語、原文字中沒有的短語來組成摘要。
指標生成網路屬於生成式模型。
僅用Neural sequence-to-sequence模型可以實現生成式摘要,但存在兩個問題:
1. 可能不準確地再現細節, 無法處理詞彙不足(OOV)單詞;
2. 傾向於重複自己。
原文是(they are liable to reproducefactual details inaccurately, and they tendto repeat themselves.)
指標生成網路(Pointer-Generator-Network)從兩個方面進行了改進:
1. 該網路通過指向(pointer)從源文字中複製單詞,有助於準確地複製資訊,同時保留通過生成器產生新單詞的能力;
2. 使用coverage機制來跟蹤已總結的內容,防止重複。
接下來從下面幾個部分介紹Pointer-Generator-Network原理:
1. Baseline sequence-to-sequence;
2. Pointer-Generator-Network;
3. Coverage Mechanism。
1 Baseline sequence-to-sequence
Pointer-Generator Networks是在Baseline sequence-to-sequence模型的基礎上構建的,我們首先Baseline seq2seq+attention。其架構圖如下: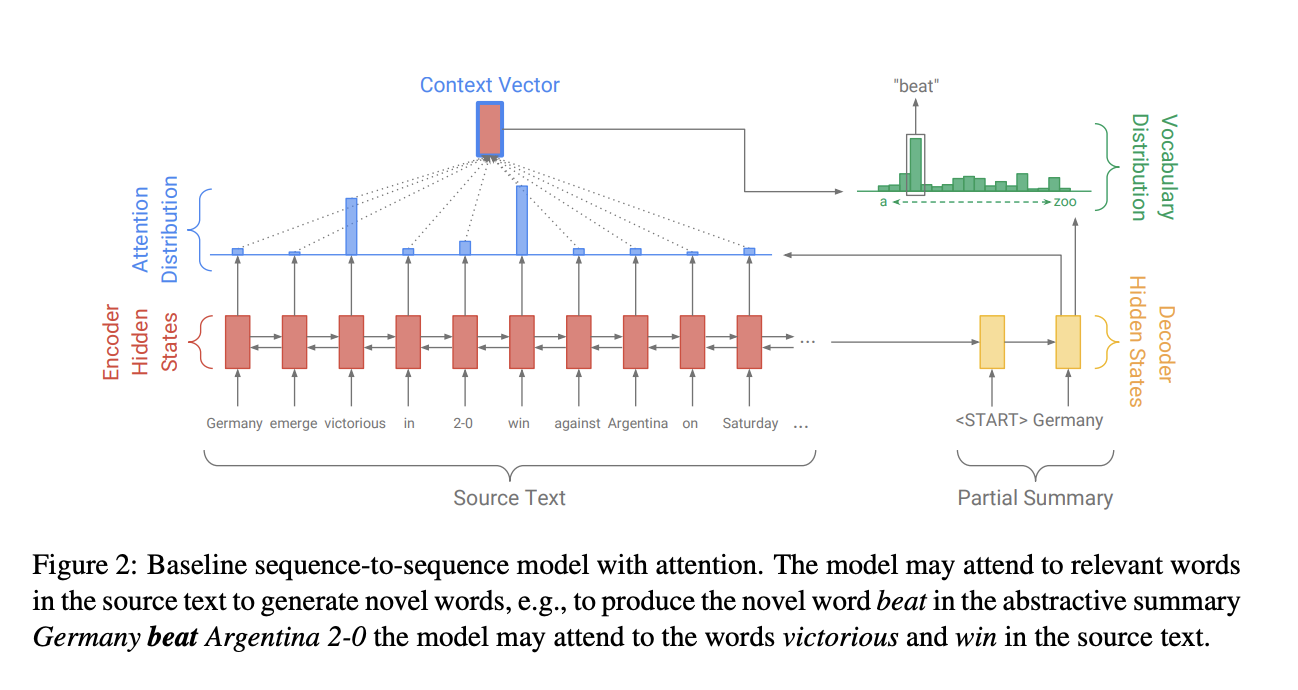
Seq2Seq的模型結構是經典的Encoder-Decoder模型,即先用Encoder將原文字編碼成一箇中間層的隱藏狀態,然後用Decoder來將該隱藏狀態解碼成為另一個文字。Baseline Seq2Seq在Encoder端是一個雙向的LSTM,這個雙向的LSTM可以捕捉原文字的長距離依賴關係以及位置資訊,編碼時詞嵌入經過雙向LSTM後得到編碼狀態 $h_i$ 。在Decoder端,解碼器是一個單向的LSTM,訓練階段時參考摘要詞依次輸入(測試階段時是上一步的生成詞),在時間步 $t$得到解碼狀態 $s_t$ 。使用$h_i$和$s_t$得到該時間步原文第 $i$個詞注意力權重。
$$e_i^t = v^T tanh(W_{h}h_i + W_{s}s_t + b_{attn})$$ $$a^t = softmax(e^t)$$得到的注意力權重和 $h_i$加權求和得到重要的上下文向量 $h_t^*(context vector)$:
$$h_{t}^{*} = \sum_{i}{a_i^t h_i}$$
$h_t^*$可以看成是該時間步通讀了原文的固定尺寸的表徵。然後將 $s_t$和 $h_t^*$ 經過兩層線性層得到單詞表分佈 $P_{vocab}$:
$$P_{vocab} = softmax(V'(V[s_t, h_t^*] + b) + b')$$
其中 $[s_t, h_t^*]$是拼接。這樣再通過$sofmax$得到了一個概率分佈,就可以預測需要生成的詞:
$$P(w) = P_{vocab}(w)$$
在訓練階段,時間步 $t$ 時的損失為:
$$loss_{t} = -logP(w_t^*)$$
那麼原輸入序列的整體損失為:
$$loss = \frac{1}{T} \sum_{t=0}^{T}loss_t$$
2 Pointer-Generator-Network
原文中的Pointer-Generator Networks是一個混合了 Baseline seq2seq和PointerNetwork的網路,它具有Baseline seq2seq的生成能力和PointerNetwork的Copy能力。該網路的結構如下:
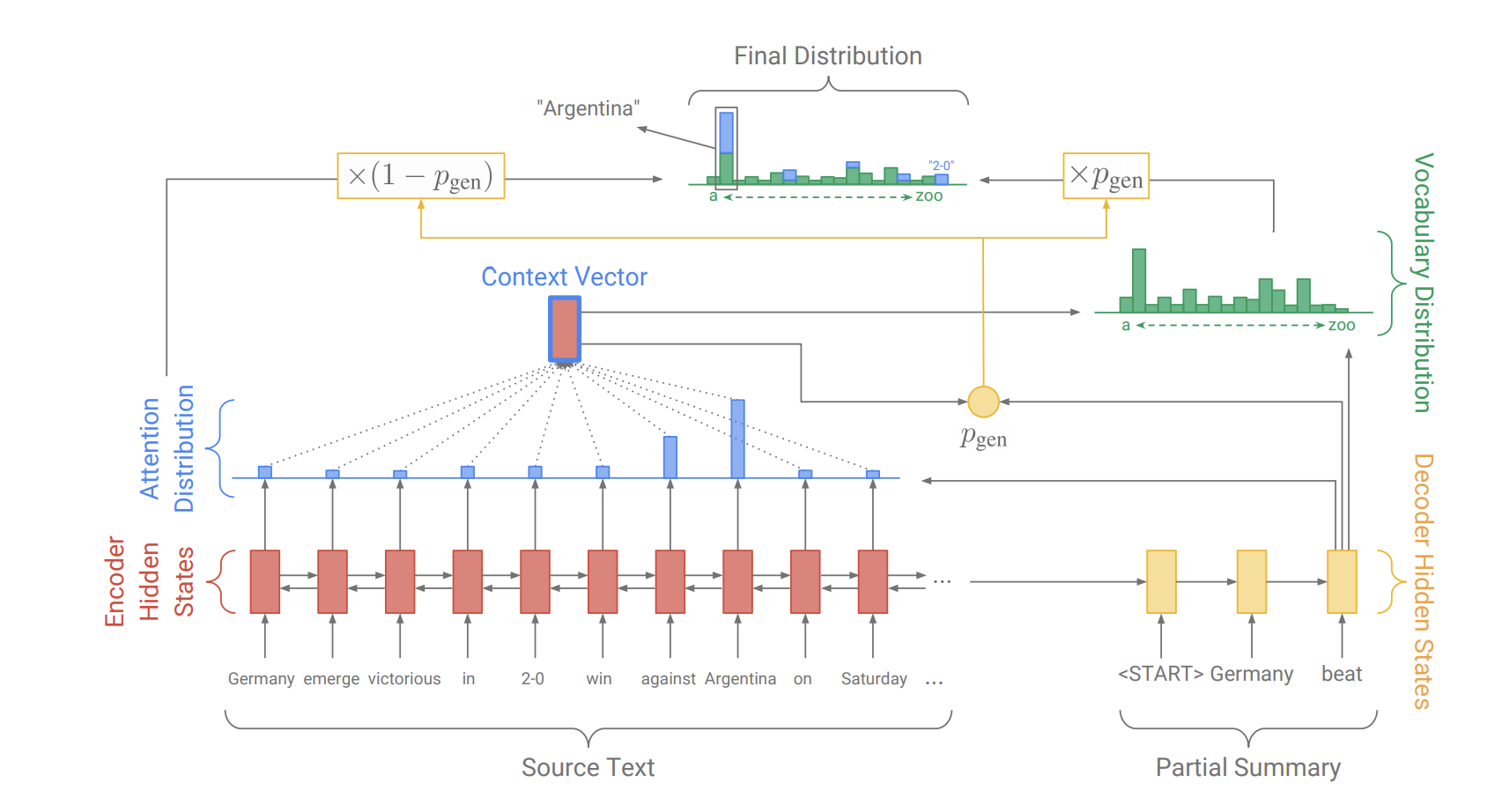
如何權衡一個詞應該是生成的還是複製的?
原文中引入了一個權重 $p_{gen}$ 。
從Baseline seq2seq的模型結構中得到了$s_t$ 和$h_t^*$,和解碼器輸入 $x_t$ 一起來計算 $p_{gen}$ :
$$p_{gen} = \sigma(w_{h^*}^T h_t^* + w_s^Ts_t + w_x^Tx_t + b_{ptr})$$
這時,會擴充單詞表形成一個更大的單詞表--擴充單詞表(將原文當中的單詞也加入到其中),該時間步的預測詞概率為:
$$P(w) = p_{gen}P_{vocab}(w) + (1 - p_{gen}) \sum_{i:w_i=w} a_i^t$$
其中 $a_i^t$ 表示的是原文件中的詞。我們可以看到解碼器一個詞的輸出概率有其是否拷貝是否生成的概率和決定。當一個詞不出現在常規的單詞表上時 $P_{vocab}(w)$ 為0,當該詞不出現在文件中$ \sum_{i:w_i=w} a_i^t$為0。
3 Coverage mechanism
原文的特色是運用了Coverage Mechanism來解決重複生成文字的問題,下圖反映了前兩個模型與添加了Coverage Mechanism生成摘要的結果:

藍色的字體表示的是參考摘要,三個模型的生成摘要的結果差別挺大;
紅色字體表明瞭不準確的摘要細節生成(UNK未登入詞,無法解決OOV問題);
綠色的字體表明瞭模型生成了重複文字。
為了解決此問題--Repitition,原文使用了在機器翻譯中解決“過翻譯”和“漏翻譯”的機制--Coverage Mechanism。
具體實現上,就是將先前時間步的注意力權重加到一起得到所謂的覆蓋向量 $c^t (coverage vector)$,用先前的注意力權重決策來影響當前注意力權重的決策,這樣就避免在同一位置重複,從而避免重複生成文字。計算上,先計算coverage vector $c^t$:
$$c^t = \sum_{t'=0}^{t-1}a^{t'}$$
然後新增到注意力權重的計算過程中,$c^t$用來計算 $e_i^t$:
$$e_i^t = v^T tanh(W_{h}h_i + W_{s}s_t + w_{c}c_i^t + b_{attn})$$
同時,為coverage vector新增損失是必要的,coverage loss計算方式為:
$$covloss_{t} = \sum_{i}min(a_i^t, c_i^t)$$
這樣coverage loss是一個有界的量 $covloss_t \leq \sum_{i}a_i^t = 1$ 。因此最終的LOSS為:
$$loss_t = -logP(w_t^*) + \lambda \sum_{i}min(a_i^t, c_i^t)$$
4 實戰部分
4.1 DataSet
英文資料集: cnn dailymail資料集,地址:https://github.com/becxer/cnn-dailymail/。
中文資料集:新浪微博摘要資料集,這是中文資料集,有679898條文字及摘要。
中英文資料集均可從這裡下載,連結:https://pan.baidu.com/s/18ykewFUrTLzW8R84bF42pg 密碼:9yqt。
4.2 Experiments
試驗環境:centos7.4/python3.6/tensorflow1.12.0 GPU:Tesla-K40m-12G*4 程式碼參考:python3 tensorflow版本。除錯時候各種報錯,所以需要debug。
改動後的程式碼已上傳至GitHub:https://github.com/zingp/NLP/tree/master/P007PytorchPointerGeneratorNetwork。
中文資料集預處理程式碼:
第一部分是對原始資料進行分詞,劃分訓練集測試集,並儲存檔案。
import os
import sys
import time
import jieba
ARTICLE_FILE = "./data/weibo_news/train_text.txt"
SUMMARRY_FILE = "./data/weibo_news/train_label.txt"
TRAIN_FILE = "./data/weibo_news/train_art_summ_prep.txt"
VAL_FILE = "./data/weibo_news/val_art_summ_prep.txt"
def timer(func):
def wrapper(*args, **kwargs):
start = time.time()
r = func(*args, **kwargs)
end = time.time()
cost = end - start
print(f"Cost time: {cost} s")
return r
return wrapper
@timer
def load_data(filename):
"""載入資料檔案,對文字進行分詞"""
data_list = []
with open(filename, 'r', encoding= 'utf-8') as f:
for line in f:
# jieba.enable_parallel()
words = jieba.cut(line.strip())
word_list = list(words)
# jieba.disable_parallel()
data_list.append(' '.join(word_list).strip())
return data_list
def build_train_val(article_data, summary_data, train_num=600_000):
"""劃分訓練和驗證資料"""
train_list = []
val_list = []
n = 0
for text, summ in zip(article_data, summary_data):
n += 1
if n <= train_num:
train_list.append(text)
train_list.append(summ)
else:
val_list.append(text)
val_list.append(summ)
return train_list, val_list
def save_file(filename, li):
"""預處理後的資料儲存到檔案"""
with open(filename, 'w+', encoding='utf-8') as f:
for item in li:
f.write(item + '\n')
print(f"Save {filename} ok.")
if __name__ == '__main__':
article_data = load_data(ARTICLE_FILE) # 大概耗時10分鐘
summary_data = load_data(SUMMARRY_FILE)
TRAIN_SPLIT = 600_000
train_list, val_list = build_train_val(article_data, summary_data, train_num=TRAIN_SPLIT)
save_file(TRAIN_FILE, train_list)
save_file(VAL_FILE, val_list)
第二部分是將檔案打包,生成模型能夠載入的二進位制檔案。
import os
import struct
import collections
from tensorflow.core.example import example_pb2
# 經過分詞處理後的訓練資料與測試資料檔案
TRAIN_FILE = "./data/weibo_news/train_art_summ_prep.txt"
VAL_FILE = "./data/weibo_news/val_art_summ_prep.txt"
# 文字起始與結束標誌
SENTENCE_START = '<s>'
SENTENCE_END = '</s>'
VOCAB_SIZE = 50_000 # 詞彙表大小
CHUNK_SIZE = 1000 # 每個分塊example的數量,用於分塊的資料
# tf模型資料檔案存放目錄
FINISHED_FILE_DIR = './data/weibo_news/finished_files'
CHUNKS_DIR = os.path.join(FINISHED_FILE_DIR, 'chunked')
def chunk_file(finished_files_dir, chunks_dir, name, chunk_size):
"""構建二進位制檔案"""
in_file = os.path.join(finished_files_dir, '%s.bin' % name)
print(in_file)
reader = open(in_file, "rb")
chunk = 0
finished = False
while not finished:
chunk_fname = os.path.join(chunks_dir, '%s_%03d.bin' % (name, chunk)) # 新的分塊
with open(chunk_fname, 'wb') as writer:
for _ in range(chunk_size):
len_bytes = reader.read(8)
if not len_bytes:
finished = True
break
str_len = struct.unpack('q', len_bytes)[0]
example_str = struct.unpack('%ds' % str_len, reader.read(str_len))[0]
writer.write(struct.pack('q', str_len))
writer.write(struct.pack('%ds' % str_len, example_str))
chunk += 1
def chunk_all():
# 建立一個資料夾來儲存分塊
if not os.path.isdir(CHUNKS_DIR):
os.mkdir(CHUNKS_DIR)
# 將資料分塊
for name in ['train', 'val']:
print("Splitting %s data into chunks..." % name)
chunk_file(FINISHED_FILE_DIR, CHUNKS_DIR, name, CHUNK_SIZE)
print("Saved chunked data in %s" % CHUNKS_DIR)
def read_text_file(text_file):
"""從預處理好的檔案中載入資料"""
lines = []
with open(text_file, "r", encoding='utf-8') as f:
for line in f:
lines.append(line.strip())
return lines
def write_to_bin(input_file, out_file, makevocab=False):
"""生成模型需要的檔案"""
if makevocab:
vocab_counter = collections.Counter()
with open(out_file, 'wb') as writer:
# 讀取輸入的文字檔案,使偶數行成為article,奇數行成為abstract(行號從0開始)
lines = read_text_file(input_file)
for i, new_line in enumerate(lines):
if i % 2 == 0:
article = lines[i]
if i % 2 != 0:
abstract = "%s %s %s" % (SENTENCE_START, lines[i], SENTENCE_END)
# 寫入tf.Example
tf_example = example_pb2.Example()
tf_example.features.feature['article'].bytes_list.value.extend([bytes(article, encoding='utf-8')])
tf_example.features.feature['abstract'].bytes_list.value.extend([bytes(abstract, encoding='utf-8')])
tf_example_str = tf_example.SerializeToString()
str_len = len(tf_example_str)
writer.write(struct.pack('q', str_len))
writer.write(struct.pack('%ds' % str_len, tf_example_str))
# 如果可以,將詞典寫入檔案
if makevocab:
art_tokens = article.split(' ')
abs_tokens = abstract.split(' ')
abs_tokens = [t for t in abs_tokens if
t not in [SENTENCE_START, SENTENCE_END]] # 從詞典中刪除這些符號
tokens = art_tokens + abs_tokens
tokens = [t.strip() for t in tokens] # 去掉句子開頭結尾的空字元
tokens = [t for t in tokens if t != ""] # 刪除空行
vocab_counter.update(tokens)
print("Finished writing file %s\n" % out_file)
# 將詞典寫入檔案
if makevocab:
print("Writing vocab file...")
with open(os.path.join(FINISHED_FILE_DIR, "vocab"), 'w', encoding='utf-8') as writer:
for word, count in vocab_counter.most_common(VOCAB_SIZE):
writer.write(word + ' ' + str(count) + '\n')
print("Finished writing vocab file")
if __name__ == '__main__':
if not os.path.exists(FINISHED_FILE_DIR):
os.makedirs(FINISHED_FILE_DIR)
write_to_bin(VAL_FILE, os.path.join(FINISHED_FILE_DIR, "val.bin"))
write_to_bin(TRAIN_FILE, os.path.join(FINISHED_FILE_DIR, "train.bin"), makevocab=True)
chunk_all()
在訓練中文資料集的時候,設定的hidden_dim為 256 ,詞向量維度emb_dim為126,詞彙表數目vocab_size為50K,batch_size設為16。這裡由於我們的模型有處理OOV能力,因此詞彙表不用設定過大;在batch_size的選擇上,視訊記憶體小的同學建議設為8,否則會出現記憶體不夠,難以訓練。
在batch_size=16時,訓練了27k step, 出現loss震盪很難收斂的情況,train階段loss如下:

相關推薦
指標生成網路(Pointer-Generator-Network)原理與實戰
0 前言 本文主要內容:介紹Pointer-Generator-Network在文字摘要任務中的背景,模型架構與原理、在中英文資料集上實戰效果與評估,最後得出結論。參考的《Get To The Point: Summarization with Point
從 SRGAN(TensorFlow) 匯出生成網路(generator)資料
按《tensorflow2caffe(2) : 如何在tensorflow中取出模型引數》一文的程式碼原理: 把下面的程式碼放到 main.py 的 generator 部分: #---------------------------------------
為文字摘要網路Pointer-Generator Networks製作中文複述訓練資料
下面是pointer-generator的開源專案地址:https://github.com/abisee/pointer-generator。我們現在要用它做中文複述的工作,那麼首先來看一下它是如何處理英文文字摘要的。 Github網頁上給了測試集輸出結果,我們拿出第一
《深入淺出MyBatis技術原理與實戰》——7. 插件
看到了 5.1 com htm html 而不是 sig stat str 在第6章討論了四大運行對象的運行過程,在Configuration對象的創建方法裏我們看到了MyBatis用責任鏈去封裝它們。 7.1 插件接口 在MyBatis中使用插件,我們必須使用接口Inte
網絡實戰ospf多區域原理與實戰
網絡實戰ospf多區域原理與實戰OSPF多區域原理與配置楔子 其實網路算得上是底層的原理了 根據tcp/ip 七層協議就可以看出 系統原理和網絡是不可分割的一部分。生成OSPF多區域的原因改善網絡的可擴展性快速收斂OSPF區域的容量劃分多區域後,每個OSPF區域裏到底可以容納多少臺路由器?單個區域所支持的路由
Java並發編程原理與實戰
地址 騰訊 http baidu 密碼 iyu .com 實戰 java並發 Java並發編程原理與實戰網盤地址:https://pan.baidu.com/s/1c3mpC7A 密碼: pe62備用地址(騰訊微雲):https://share.weiyun.com/11e
Java並發編程原理與實戰視頻教程
cnp mysql enter 架構師 分享圖片 span aid rocketmq 相對 14套java精品高級架構課,緩存架構,深入Jvm虛擬機,全文檢索Elasticsearch,Dubbo分布式Restful 服務,並發原理編程,SpringBoot,Spring
Squid緩存服務器原理與實戰演練
Squid緩存服務器原理與實戰演練Squid服務基礎講解代理緩存機制:代理的基本類型:1、 傳統代理:需要在客戶端軟件手動設置指定代理服務器 2、 透明代理:無需用戶手動指定,通過路由、防火墻策略將訪問重定向Squid 反向代理:為網站服務下面進行實戰演練! 實驗環境:代理服務器squid 192.168
Java並發編程原理與實戰八:產生線程安全性問題原因(javap字節碼分析)
cpu next() 讀者 setting pack obj http chm val 前面我們說到多線程帶來的風險,其中一個很重要的就是安全性,因為其重要性因此,放到本章來進行講解,那麽線程安全性問題產生的原因,我們這節將從底層字節碼來進行分析。 一、問題引出 先看一
Java並發編程原理與實戰十三:JDK提供的原子類原理與使用
執行 atomic .com new length 基本類 .get out sys 原子更新基本類型 原子更新數組 原子更新抽象類型 原子更新字段 原子更新基本類型: package com.roocon.thread.t8;import java.u
Java並發編程原理與實戰十九:AQS 剖析
影響 clu cbo 大神 ping 方法 extc 共享鎖 一次 一、引言在JDK1.5之前,一般是靠synchronized關鍵字來實現線程對共享變量的互斥訪問。synchronized是在字節碼上加指令,依賴於底層操作系統的Mutex Lock實現。而從JDK1.5以
Java並發編程原理與實戰二十:線程安全性問題簡單總結
依次 mar 時間 clu 版本號 exc 虛擬 locking ron 一、出現線程安全性問題的條件 •在多線程的環境下 •必須有共享資源 •對共享資源進行非原子性操作 二、解決線程安全性問題的途徑 •synchro
Java並發編程原理與實戰二十一:線程通信wait¬ify&join
ola run 原理 ons spa sta pro join() cto wait和notify wait和notify可以實現線程之間的通信,當一個線程執行不滿足條件時可以調用wait方法將線程置為等待狀態,當另一個線程執行到等待線程可以執行的條件時,調用notify
Java並發編程原理與實戰二十五:ThreadLocal線程局部變量的使用和原理
解決 ava 應用 並發 資料 clas 線程安全 mage else 1.什麽是ThreadLocal ThreadLocal顧名思義是線程局部變量。這種變量和普通的變量不同,這種變量在每個線程中通過get和set方法訪問, 每個線程有自己獨立的變量副本。
Java並發編程原理與實戰四十一:重排序 和 happens-before
而已 註意 ron 不知道 load chm title 並行 ola 一、概念理解 首先我們先來了解一下什麽是重排序:重排序是指編譯器和處理器為了優化程序性能而對指令序列進行重新排序的一種手段。 從Java源代碼到最終實際執行的指令序列,會分別經歷下面3種重排序,如下
C++ 設計模式原理與實戰大全-架構師需備課程-夏曹俊-專題視訊課程
C++ 設計模式原理與實戰大全-架構師需備課程—716人已學習 課程介紹 C++屬於難學易用的工程開發語言,C++繁複的語法往往使得開發人員過於強調細節而缺乏軟體體系結構的大局觀。特
最新Java併發程式設計原理與實戰分享
課程大綱第1節你真的瞭解併發嗎? 00:27:48分鐘 | 第2節理解多執行緒與併發的之間的聯絡與區別 00:11:59分鐘 | 第3節解析多執行緒與多程序的聯絡以及上下文切換所
Istio 流量治理功能原理與實戰
一、負載均衡演算法原理與實戰 負載均衡演算法(load balancing algorithm),定義了幾種基本的流量分發方式,在Istio中共有4種標準負載均衡演算法。 •Round_Robin: 輪詢演算法,顧名思義請求將會依次發給每一個例項,來共同分擔所有的請求。 •Random: 隨機演算法,將
轉:Hystrix原理與實戰
背景 分散式系統環境下,服務間類似依賴非常常見,一個業務呼叫通常依賴多個基礎服務。如下圖,對於同步呼叫,當庫存服務不可用時,商品服務請求執行緒被阻塞,當有大批量請求呼叫庫存服務時,最終可能導致整個商品服務資源耗盡,無法繼續對外提供服務。並且這種不可用可能沿請求呼叫鏈向上
MySQL 閃回原理與實戰
DBA或開發人員,有時會誤刪或者誤更新資料,如果是線上環境並且影響較大,就需要能快速回滾。傳統恢復方法是利用備份重搭例項,再應用去除錯誤sql後的binlog來恢復資料。此法費時費力,甚至需要停機維護,並不適合快速回滾。也有團隊利用LVM快照來縮短恢復時間,但快照的缺點是會影