
Transformer各層網路結構詳解!面試必備!(附程式碼實現)
1. 什麼是Transformer
《Attention Is All You Need》是一篇Google提出的將Attention思想發揮到極致的論文。這篇論文中提出一個全新的模型,叫 Transformer,拋棄了以往深度學習任務裡面使用到的 CNN 和 RNN。目前大熱的Bert就是基於Transformer構建的,這個模型廣泛應用於NLP領域,例如機器翻譯,問答系統,文字摘要和語音識別等等方向。
2. Transformer結構
2.1 總體結構
Transformer的結構和Attention模型一樣,Transformer模型中也採用了 encoer-decoder 架構。但其結構相比於Attention更加複雜,論文中encoder層由6個encoder堆疊在一起,decoder層也一樣。
不瞭解Attention模型的,可以回顧之前的文章:Attention

每一個encoder和decoder的內部結構如下圖:

- encoder,包含兩層,一個self-attention層和一個前饋神經網路,self-attention能幫助當前節點不僅僅只關注當前的詞,從而能獲取到上下文的語義。
- decoder也包含encoder提到的兩層網路,但是在這兩層中間還有一層attention層,幫助當前節點獲取到當前需要關注的重點內容。
2.2 Encoder層結構
首先,模型需要對輸入的資料進行一個embedding操作,也可以理解為類似w2c的操作,enmbedding結束之後,輸入到encoder層,self-attention處理完資料後把資料送給前饋神經網路,前饋神經網路的計算可以並行,得到的輸出會輸入到下一個encoder。

2.2.1 Positional Encoding
transformer模型中缺少一種解釋輸入序列中單詞順序的方法,它跟序列模型還不不一樣。為了處理這個問題,transformer給encoder層和decoder層的輸入添加了一個額外的向量Positional Encoding,維度和embedding的維度一樣,這個向量採用了一種很獨特的方法來讓模型學習到這個值,這個向量能決定當前詞的位置,或者說在一個句子中不同的詞之間的距離。這個位置向量的具體計算方法有很多種,論文中的計算方法如下:
\[PE(pos,2i)=sin(\frac{pos}{10000^{\frac{2i}{d_{model}}}})\]
\[PE(pos,2i+1)=cos(\frac{pos}{10000^{\frac{2i}{d_{model}}}})\]
其中pos是指當前詞在句子中的位置,i是指向量中每個值的index,可以看出,在偶數位置,使用正弦編碼,在奇數位置,使用餘弦編碼。
最後把這個Positional Encoding與embedding的值相加,作為輸入送到下一層。

2.2.2 Self-Attention
接下來我們詳細看一下self-attention,其思想和attention類似,但是self-attention是Transformer用來將其他相關單詞的“理解”轉換成我們正在處理的單詞的一種思路,我們看個例子:
The animal didn't cross the street because it was too tired
這裡的 it 到底代表的是 animal 還是 street 呢,對於我們來說能很簡單的判斷出來,但是對於機器來說,是很難判斷的,self-attention就能夠讓機器把 it 和 animal 聯絡起來,接下來我們看下詳細的處理過程。
首先,self-attention會計算出三個新的向量,在論文中,向量的維度是512維,我們把這三個向量分別稱為Query、Key、Value,這三個向量是用embedding向量與一個矩陣相乘得到的結果,這個矩陣是隨機初始化的,維度為(64,512)注意第二個維度需要和embedding的維度一樣,其值在BP的過程中會一直進行更新,得到的這三個向量的維度是64。

計算self-attention的分數值,該分數值決定了當我們在某個位置encode一個詞時,對輸入句子的其他部分的關注程度。這個分數值的計算方法是Query與Key做點成,以下圖為例,首先我們需要針對Thinking這個詞,計算出其他詞對於該詞的一個分數值,首先是針對於自己本身即q1·k1,然後是針對於第二個詞即q1·k2。

接下來,把點成的結果除以一個常數,這裡我們除以8,這個值一般是採用上文提到的矩陣的第一個維度的開方即64的開方8,當然也可以選擇其他的值,然後把得到的結果做一個softmax的計算。得到的結果即是每個詞對於當前位置的詞的相關性大小,當然,當前位置的詞相關性肯定會會很大。

下一步就是把Value和softmax得到的值進行相乘,並相加,得到的結果即是self-attetion在當前節點的值。

在實際的應用場景,為了提高計算速度,我們採用的是矩陣的方式,直接計算出Query, Key, Value的矩陣,然後把embedding的值與三個矩陣直接相乘,把得到的新矩陣 Q 與 K 相乘,乘以一個常數,做softmax操作,最後乘上 V 矩陣。
這種通過 query 和 key 的相似性程度來確定 value 的權重分佈的方法被稱為scaled dot-product attention。


2.2.3 Multi-Headed Attention
這篇論文更牛逼的地方是給self-attention加入了另外一個機制,被稱為“multi-headed” attention,該機制理解起來很簡單,就是說不僅僅只初始化一組Q、K、V的矩陣,而是初始化多組,tranformer是使用了8組,所以最後得到的結果是8個矩陣。


2.2.4 Layer normalization
在transformer中,每一個子層(self-attetion,Feed Forward Neural Network)之後都會接一個殘缺模組,並且有一個Layer normalization。

Normalization有很多種,但是它們都有一個共同的目的,那就是把輸入轉化成均值為0方差為1的資料。我們在把資料送入啟用函式之前進行normalization(歸一化),因為我們不希望輸入資料落在啟用函式的飽和區。
Batch Normalization
BN的主要思想就是:在每一層的每一批資料上進行歸一化。我們可能會對輸入資料進行歸一化,但是經過該網路層的作用後,我們的資料已經不再是歸一化的了。隨著這種情況的發展,資料的偏差越來越大,我的反向傳播需要考慮到這些大的偏差,這就迫使我們只能使用較小的學習率來防止梯度消失或者梯度爆炸。BN的具體做法就是對每一小批資料,在批這個方向上做歸一化。
Layer normalization
它也是歸一化資料的一種方式,不過LN 是在每一個樣本上計算均值和方差,而不是BN那種在批方向計算均值和方差!公式如下:
\[LN(x_i)=\alpha*\frac{x_i-\mu_L}{\sqrt{\sigma_L^2+\varepsilon}}+\beta\]

2.2.5 Feed Forward Neural Network
這給我們留下了一個小的挑戰,前饋神經網路沒法輸入 8 個矩陣呀,這該怎麼辦呢?所以我們需要一種方式,把 8 個矩陣降為 1 個,首先,我們把 8 個矩陣連在一起,這樣會得到一個大的矩陣,再隨機初始化一個矩陣和這個組合好的矩陣相乘,最後得到一個最終的矩陣。

2.3 Decoder層結構
根據上面的總體結構圖可以看出,decoder部分其實和encoder部分大同小異,剛開始也是先新增一個位置向量Positional Encoding,方法和 2.2.1 節一樣,接下來接的是masked mutil-head attetion,這裡的mask也是transformer一個很關鍵的技術,下面我們會進行一一介紹。
其餘的層結構與Encoder一樣,請參考Encoder層結構。
2.3.1 masked mutil-head attetion
mask 表示掩碼,它對某些值進行掩蓋,使其在引數更新時不產生效果。Transformer 模型裡面涉及兩種 mask,分別是 padding mask 和 sequence mask。其中,padding mask 在所有的 scaled dot-product attention 裡面都需要用到,而 sequence mask 只有在 decoder 的 self-attention 裡面用到。
padding mask
什麼是 padding mask 呢?因為每個批次輸入序列長度是不一樣的也就是說,我們要對輸入序列進行對齊。具體來說,就是給在較短的序列後面填充 0。但是如果輸入的序列太長,則是擷取左邊的內容,把多餘的直接捨棄。因為這些填充的位置,其實是沒什麼意義的,所以我們的attention機制不應該把注意力放在這些位置上,所以我們需要進行一些處理。
具體的做法是,把這些位置的值加上一個非常大的負數(負無窮),這樣的話,經過 softmax,這些位置的概率就會接近0!
而我們的 padding mask 實際上是一個張量,每個值都是一個Boolean,值為 false 的地方就是我們要進行處理的地方。
Sequence mask
文章前面也提到,sequence mask 是為了使得 decoder 不能看見未來的資訊。也就是對於一個序列,在 time_step 為 t 的時刻,我們的解碼輸出應該只能依賴於 t 時刻之前的輸出,而不能依賴 t 之後的輸出。因此我們需要想一個辦法,把 t 之後的資訊給隱藏起來。
那麼具體怎麼做呢?也很簡單:產生一個上三角矩陣,上三角的值全為0。把這個矩陣作用在每一個序列上,就可以達到我們的目的。
- 對於 decoder 的 self-attention,裡面使用到的 scaled dot-product attention,同時需要padding mask 和 sequence mask 作為 attn_mask,具體實現就是兩個mask相加作為attn_mask。
- 其他情況,attn_mask 一律等於 padding mask。
2.3.2 Output層
當decoder層全部執行完畢後,怎麼把得到的向量對映為我們需要的詞呢,很簡單,只需要在結尾再新增一個全連線層和softmax層,假如我們的詞典是1w個詞,那最終softmax會輸入1w個詞的概率,概率值最大的對應的詞就是我們最終的結果。
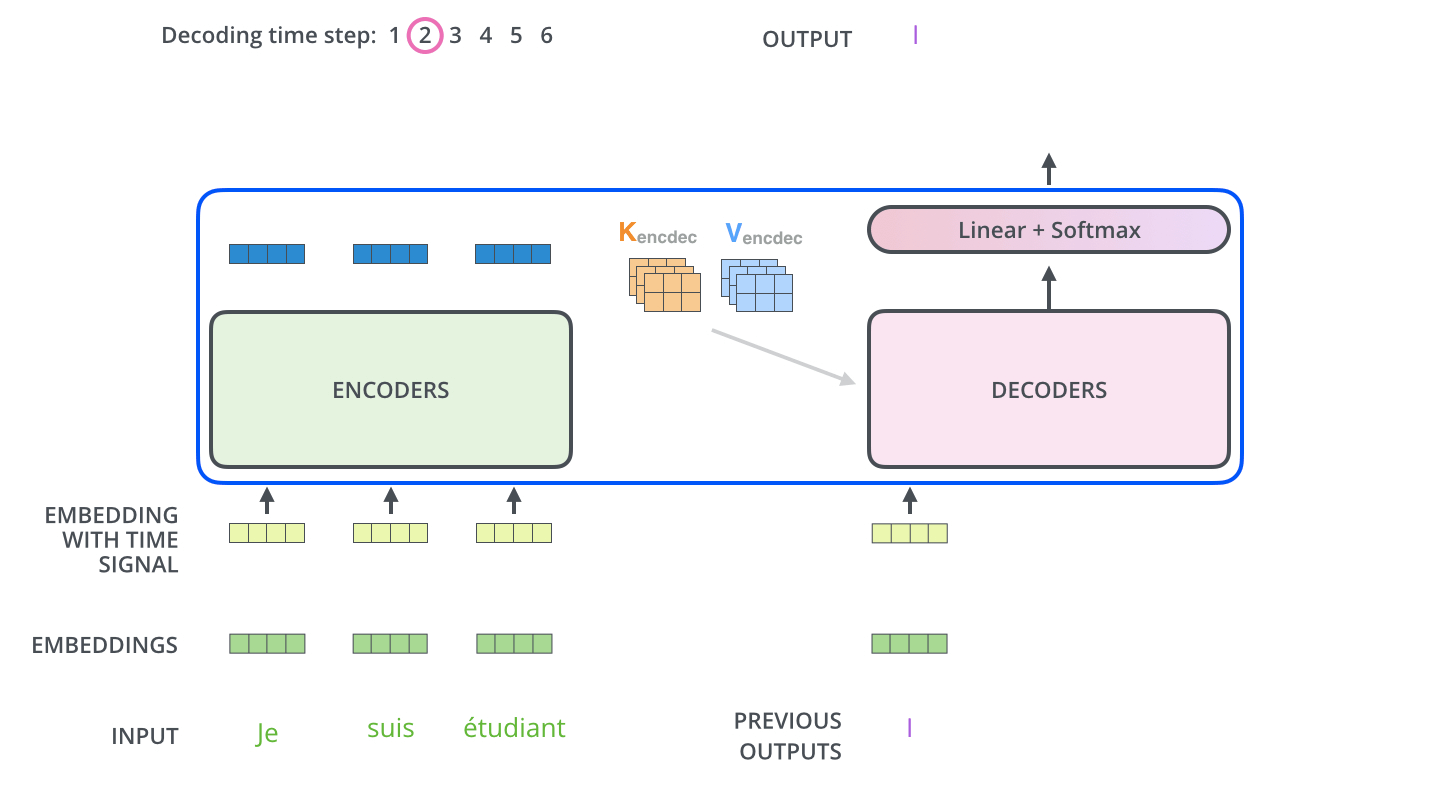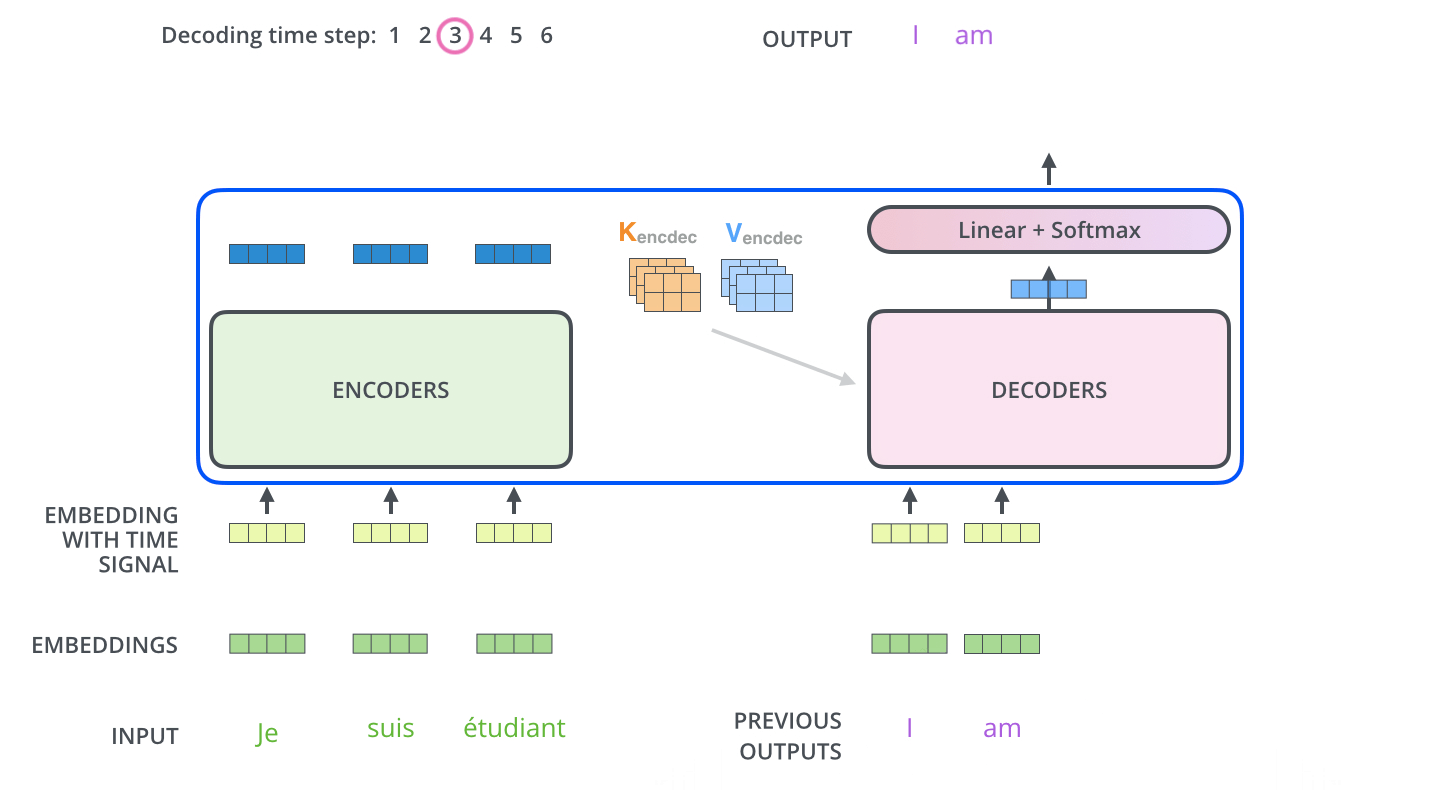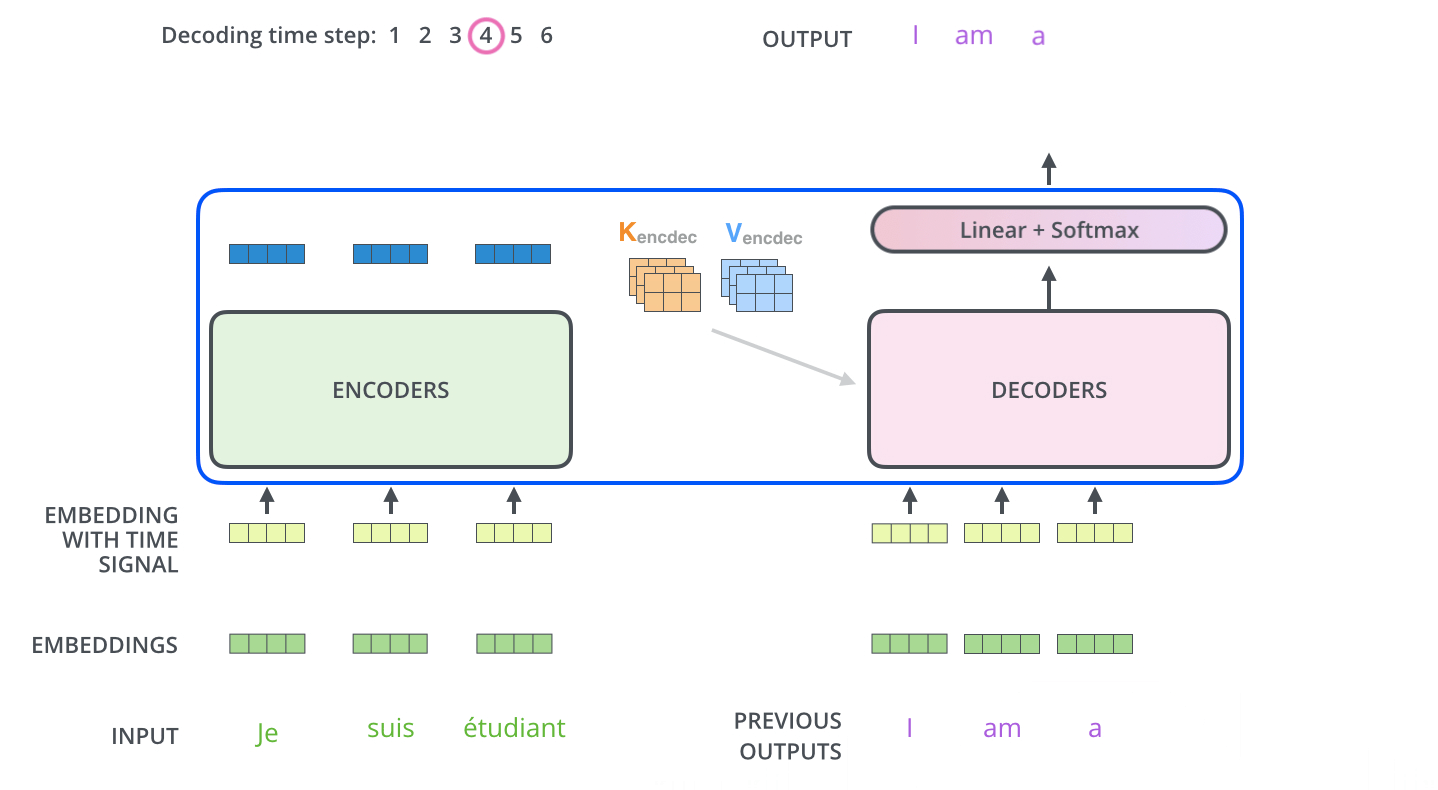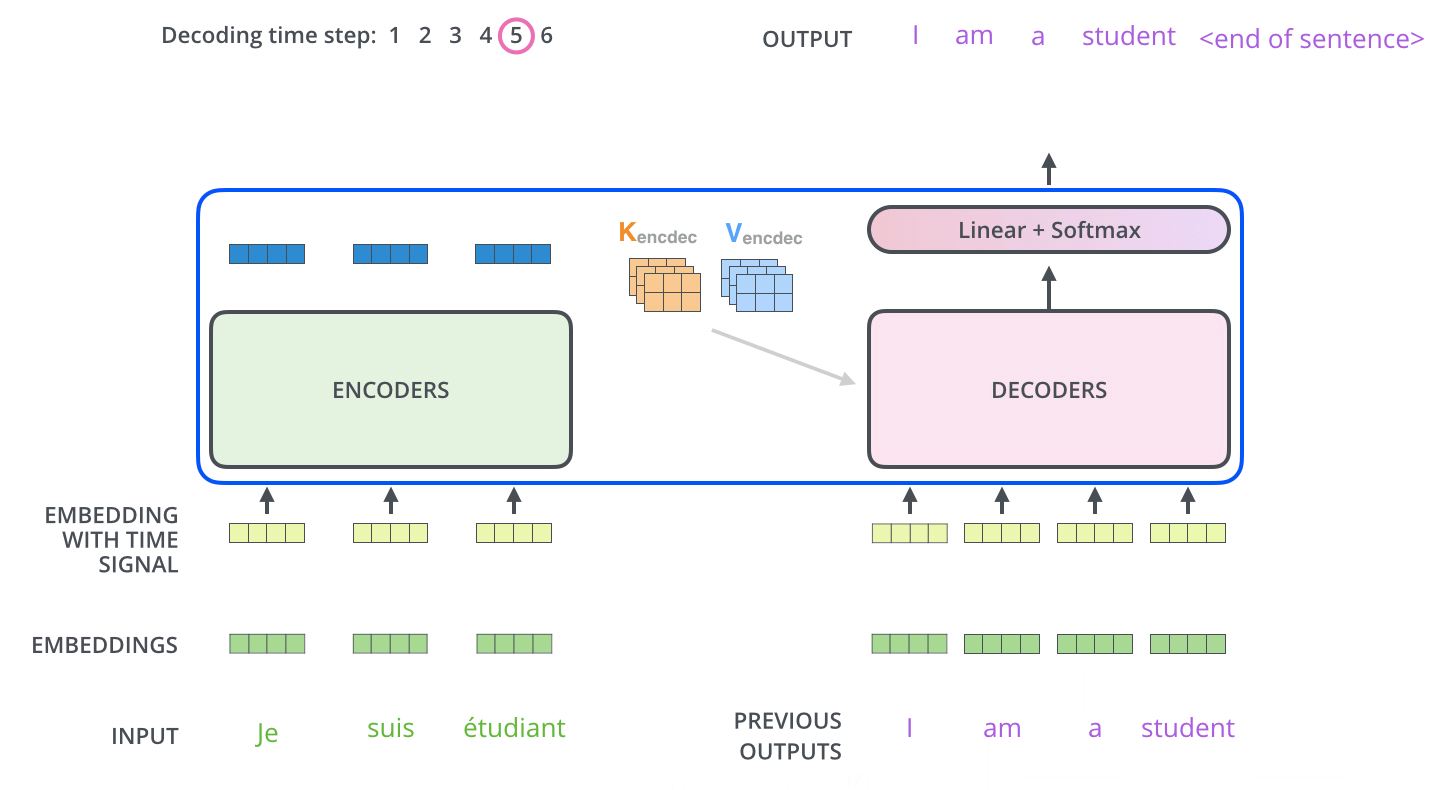
2.4 動態流程圖
編碼器通過處理輸入序列開啟工作。頂端編碼器的輸出之後會變轉化為一個包含向量K(鍵向量)和V(值向量)的注意力向量集 ,這是並行化操作。這些向量將被每個解碼器用於自身的“編碼-解碼注意力層”,而這些層可以幫助解碼器關注輸入序列哪些位置合適:
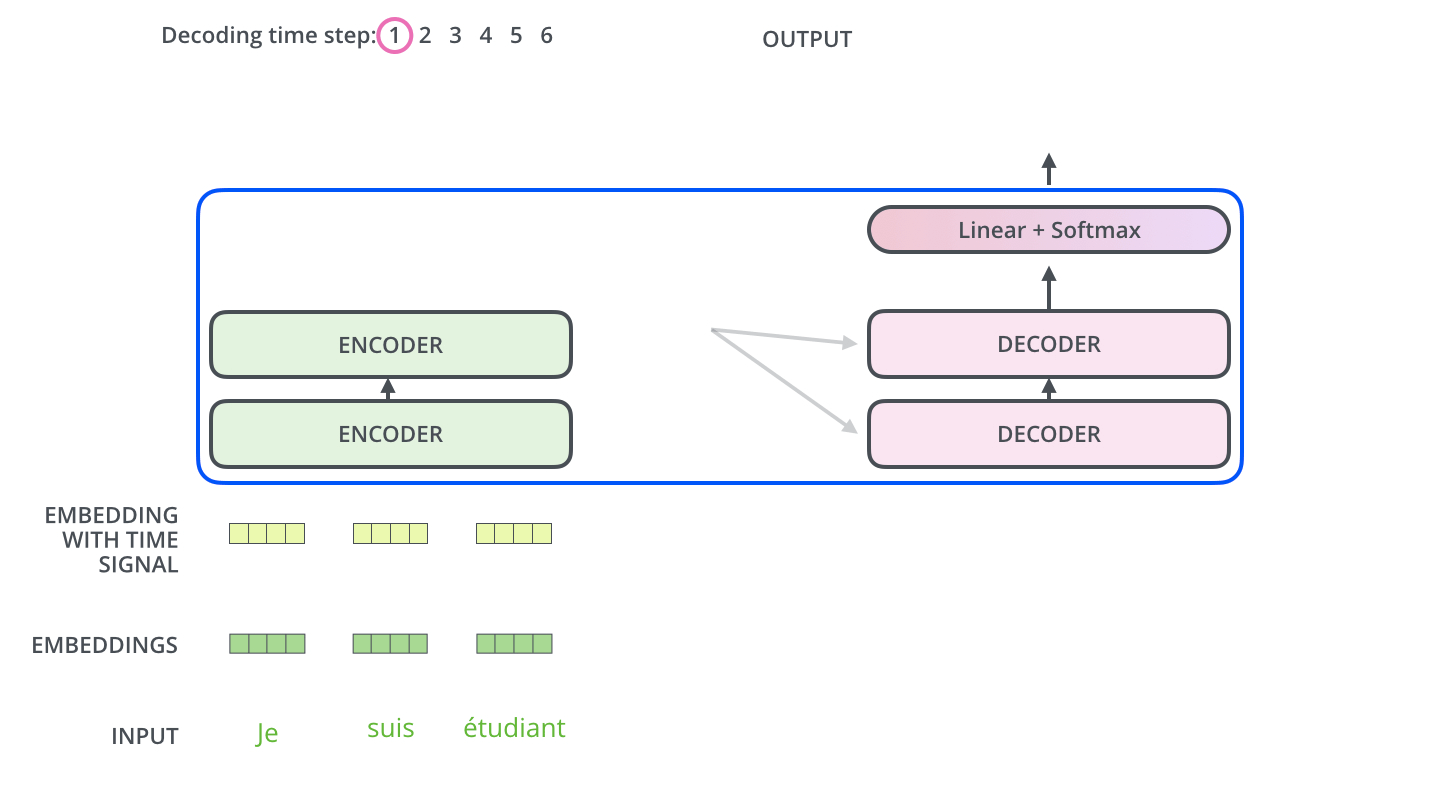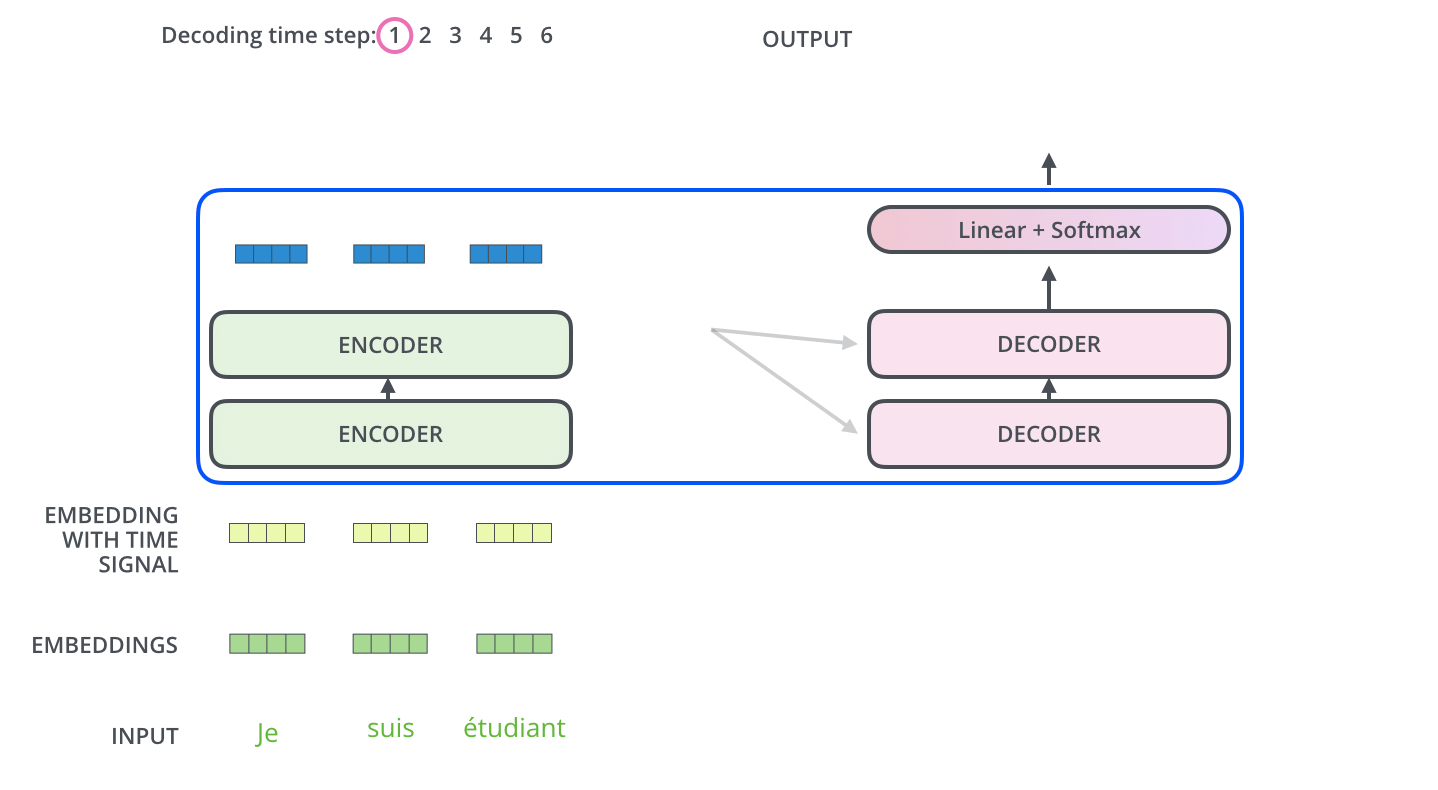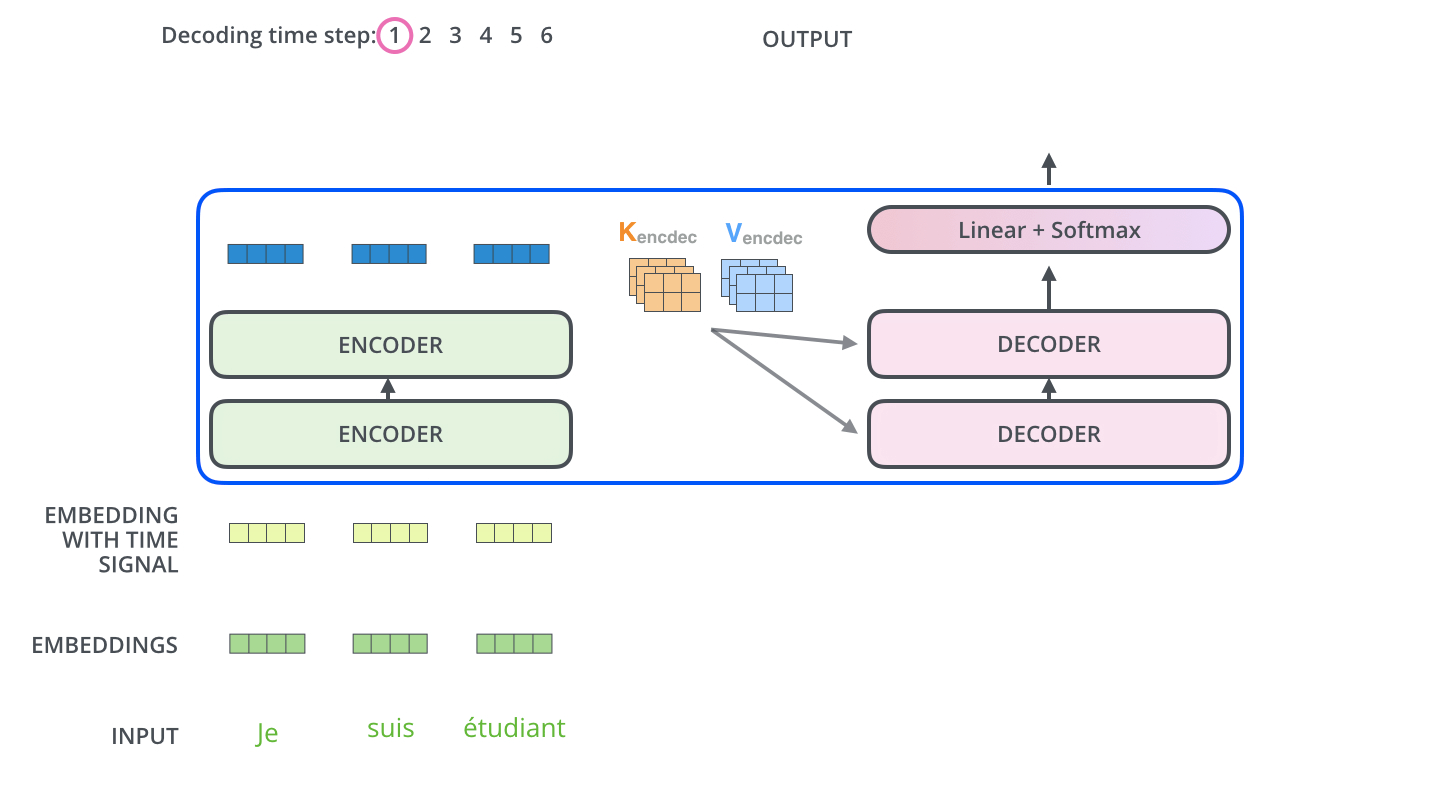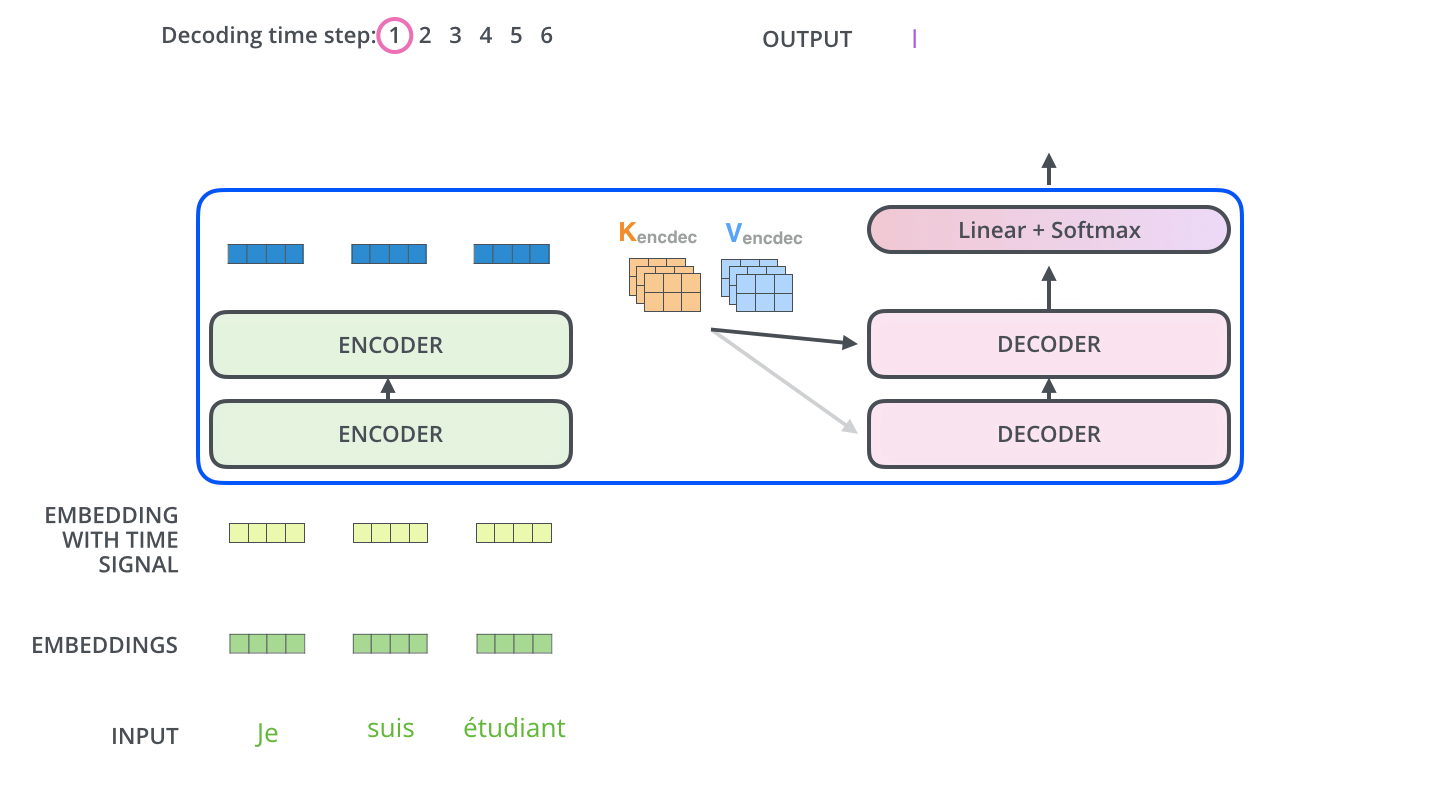
在完成編碼階段後,則開始解碼階段。解碼階段的每個步驟都會輸出一個輸出序列(在這個例子裡,是英語翻譯的句子)的元素。
接下來的步驟重複了這個過程,直到到達一個特殊的終止符號,它表示transformer的解碼器已經完成了它的輸出。每個步驟的輸出在下一個時間步被提供給底端解碼器,並且就像編碼器之前做的那樣,這些解碼器會輸出它們的解碼結果 。
3. Transformer為什麼需要進行Multi-head Attention
原論文中說到進行Multi-head Attention的原因是將模型分為多個頭,形成多個子空間,可以讓模型去關注不同方面的資訊,最後再將各個方面的資訊綜合起來。其實直觀上也可以想到,如果自己設計這樣的一個模型,必然也不會只做一次attention,多次attention綜合的結果至少能夠起到增強模型的作用,也可以類比CNN中同時使用多個卷積核的作用,直觀上講,多頭的注意力有助於網路捕捉到更豐富的特徵/資訊。
4. Transformer相比於RNN/LSTM,有什麼優勢?為什麼?
RNN系列的模型,平行計算能力很差。RNN平行計算的問題就出在這裡,因為 T 時刻的計算依賴 T-1 時刻的隱層計算結果,而 T-1 時刻的計算依賴 T-2 時刻的隱層計算結果,如此下去就形成了所謂的序列依賴關係。
Transformer的特徵抽取能力比RNN系列的模型要好。
具體實驗對比可以參考:放棄幻想,全面擁抱Transformer:自然語言處理三大特徵抽取器(CNN/RNN/TF)比較
但是值得注意的是,並不是說Transformer就能夠完全替代RNN系列的模型了,任何模型都有其適用範圍,同樣的,RNN系列模型在很多工上還是首選,熟悉各種模型的內部原理,知其然且知其所以然,才能遇到新任務時,快速分析這時候該用什麼樣的模型,該怎麼做好。
5. 為什麼說Transformer可以代替seq2seq?
seq2seq缺點:這裡用代替這個詞略顯不妥當,seq2seq雖已老,但始終還是有其用武之地,seq2seq最大的問題在於將Encoder端的所有資訊壓縮到一個固定長度的向量中,並將其作為Decoder端首個隱藏狀態的輸入,來預測Decoder端第一個單詞(token)的隱藏狀態。在輸入序列比較長的時候,這樣做顯然會損失Encoder端的很多資訊,而且這樣一股腦的把該固定向量送入Decoder端,Decoder端不能夠關注到其想要關注的資訊。
Transformer優點:transformer不但對seq2seq模型這兩點缺點有了實質性的改進(多頭互動式attention模組),而且還引入了self-attention模組,讓源序列和目標序列首先“自關聯”起來,這樣的話,源序列和目標序列自身的embedding表示所蘊含的資訊更加豐富,而且後續的FFN層也增強了模型的表達能力,並且Transformer平行計算的能力是遠遠超過seq2seq系列的模型,因此我認為這是transformer優於seq2seq模型的地方。
6. 程式碼實現
地址:https://github.com/Kyubyong/transformer
程式碼解讀:Transformer解析與tensorflow程式碼解讀
【機器學習通俗易懂系列文章】

7. 參考文獻
- Transformer模型詳解
- 圖解Transformer(完整版)
- 關於Transformer的若干問題整理記錄
作者:@mantchs
GitHub:https://github.com/NLP-LOVE/ML-NLP
歡迎大家加入討論!共同完善此專案!群號:【541954936】
