
詳解Huffman壓縮原理和c++程式碼實現
寫在前面
Huffman壓縮原理其實挺好理解的,我用java很快就寫好了。然後用c++寫,一開始我是這麼想的:c++偏底層,應該對二進位制串檔案的讀寫會更簡單吧。
不涉及到檔案讀寫的部分確實很快就做好了,然後就被檔案讀寫折磨。
各種深夜痛哭... ...
但還是值得的,學習了更多底層的知識。我對Huffman壓縮基本掌握了。(本來想說完全掌握的,但,呵,生活。微笑 )
)
寫這篇部落格花了我很長時間,我完全盡力了。我儘可能詳細地寫了三部分,分別是Huffman原理、坑和c++程式碼實現。我舉了一些例子,並且經過實際動手驗證,還自行繪製了幾幅圖幫助理解。
歡迎指錯和討論交流,也歡迎提問質疑,儘管能力有限,但我盡力解答。
目錄
一、Huffman壓縮
1、檔案在計算機中儲存形式
2、Huffman壓縮演算法原理
3、例子解析
二、需要特別注意的坑
1、windows的'\r\n'問題,c/c++可以用二進位制方式讀取來解決
2、檔案讀取末尾問題
三、Huffman的實現(上程式碼,本文c++版本,如果要java版本請私聊我)
編碼篇
1、統計頻率
2、建立Huffman樹
3、獲取Huffman編碼表
4、編碼
譯碼篇
1、獲取Huffman譯碼錶
2、譯碼
正文
一、Huffman壓縮
1、檔案在計算機中儲存形式
在開始實現之前,我們要了解下計算機底層的編解碼。
計算機只認0與1,一切檔案最終的儲存形式都是0、1串。文字、圖片、視訊等檔案都是通過一定的協議進行編解碼,而 這些協議及其轉化由各種各樣的軟體(音訊軟體、畫圖軟體、記事本等)實現。 下圖是一張png圖片檔案在計算機中儲存形式, 可以通過Binary Viewer 軟體進行檢視。

檔案的儲存有定長儲存和不定長儲存,定長儲存就是int、char、byte等型別會以固定的位數b進行儲存。舉個例子,我們新建txt檔案,寫入“4 中”然後敲回車換行,再寫入“16”,儲存。現在我們用Binary Viewer檢視它在計算機中的儲存。

因為我們是用文字檔案進行儲存,所以記事本的編解碼方式是將每一個字元對應的ASCII碼寫入文字檔案,如果是0-127的只有8位,如果是中文這樣的拓展字元則有16位。
我們看圖吧,第一個位元組(8位)“00110100”轉化為10進製為52, 查ASCII表為‘4’,接下來的第二個位元組“00100000”代表空格,接下來的兩個位元組是‘中’,然後依次是‘\r’,‘\n’,‘1’,6’。這裡特別強調下,Windows系統用‘\r\n’表示換行,而Liunx用‘\n’,Mac用‘\r’。為什麼會有如此差異呢?感興趣的自行百度,這個跟早期印表機有關,現在只是一個規則,並沒有實際含義,但要特別特別注意 。我寫Huffman的時候被這個坑了,具體我們後面再說。我強烈建議寫壓縮的時候用上檢視二進位制串的工具(比如Binary Viewer),有利於理解和debug。
2、Huffman壓縮演算法原理
我們上邊提到了計算機的定長儲存,其實我們也看到了儲存‘4’這樣的數字,計算機用了8位,那麼我們能不能減少二進位制串呢,從而來實現壓縮?有很多壓縮演算法,他們主要是用新一套的編解碼錶來實現。而每次所用的編碼表都是不同的,是依據壓縮的檔案來決定的。
那Huffman是怎麼做的呢?它先通過對要壓縮的檔案進行統計頻率,比如在“65da as 美65a”中a-3(表示a出現3次),d-1,s-1,6-2,5-2,美-1,空格-2。Huffman採用不定長進行儲存,頻率高的對應的編碼長度較短,頻率低的對應的編碼長度較長。但我們壓縮後是要能解壓的,假如有這樣的一組編碼“00101110”,Huffman壓縮演算法每次讀取一位,直至找到在Huffman編碼表中找到,然後去除這一串,接著重複以上操作,直至編碼讀取完畢。要實現這樣的結果,我們要怎麼創立Huffman編碼表呢?以下是具體做法:(邊看例子輔助理解)
(1)先對壓縮檔案的字元進行頻率統計,以“字元--頻率”的形式存入某容器m
(2) 在容器m中取出兩個頻率最小對應的字元,作為二叉樹的兩個葉子節點,並將頻率和作為它們的根節點,同時將新結點存入容器m,將舊的兩個結點踢出容器m。(容器m可以是優先佇列)
(3)重複(2),直到最後容器m中只有一個元素。
(4) 將形成的二叉樹的左節點標0,右節點標1。把從最上面的根節點到最下面的葉子節點途中遇到的0,1序列串起來,就得到了各個符號的編碼。
3、例子解析
例子:有一串“cdbedfaabca”,進行Huffman編碼和解碼。
編碼: (1)頻率統計 f:1 e:1 d:2 c:2 b:2 a:5
(2) f與 e作為葉子結點,其根節點為_2 。 此時,新的頻率表為:_2 d:2 c:2 b:2 a:5
d與_2作為葉子結點,其根節點為_4 。 此時,新的頻率表為:c:2 b:2 _4 a:5
b與 c作為葉子結點,其根節點為_4 。 此時,新的頻率表為:_4 _4 a:5
_4與_4作為葉子結點,其根節點為_8 。 此時,新的頻率表為: _8 a:5
_8與 a作為葉子結點,其根節點為_13 。
結束。
(3)左子樹標0,右子樹標1。如下圖所示:
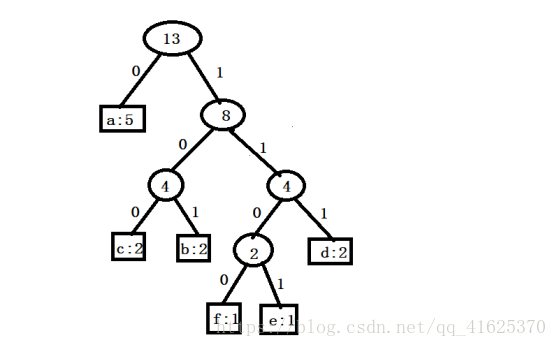
Huffman編碼表 a:0 c:100b:101f:1100e:1101d:111
那麼“cdbedfaabca”的編碼為“10011110111011111100001011000”。
解碼: 讀取第一位‘1’,搜尋Huffman表,找不到。繼續讀下一位“10”,找不到,繼續讀下一位“100”,此時對應字元‘c’。
那麼清零,繼續讀第一位“1”,直至讀到“111”,對應‘d’。
繼續清零,繼續讀第一位‘0’,直至讀到“101”,對應‘b’。
... ...
讀到最後,得“cdbedfaabca”。
二、需要特別注意的坑
1、windows的'\r\n'問題
c++在windows系統中,在讀寫檔案時,有兩種格式,分別是文字檔案和二進位制檔案,它們的區別只有一點。
文字檔案表示換行會用'\r\n',上文我們已經證明了,在txt檔案換行後,用軟體檢視其二進位制儲存形式,發現換行是'\r\n'對應的Ascii碼。也就是,寫入時寫入'\r\n',然後在讀取時會把'\r\n'轉化成換行。
你應該沒意識到這對Huffman壓縮有什麼影響,那麼我們舉四個例子來進一步說明吧。
我用二進位制形式寫入‘\n’時,txt文字開啟沒有換行,也沒有其它改變。但用c++讀取時讀到‘\n’,會換行。
我用二進位制形式寫入‘\r’時,txt文字開啟沒有換行,也沒有其它改變。但用c++讀取時讀到‘\r’,沒有任何操作。
我用二進位制形式寫入‘\r\n’時,txt文字開啟換行。但用c++讀取時只讀到‘\n’,(沒有讀到'\r' !!!),會換行。
我用二進位制形式寫入‘\n\r’時,txt文字開啟沒有換行,也沒有其它改變。用c++讀取時讀到‘\n\r’,會換行('\n'實現的)。
為什麼要特意強調這點呢?
因為我們在進行Huffman壓縮的過程中,我們可能會儲存“11111111”(-1),“00001010”(\n),“00001101”(\r)這樣比較特殊的字元。-1經常被用於證明檔案讀到末尾,\n、\r與換行關係密切。
事實證明,“11111111”並沒有影響,即便程式讀到了-1,它依然會繼續讀取,所以不需要考慮。
而根據上面的四個例子,讀取到‘\n’,‘\r’,‘\n\r’時都不會有影響,但若是讀取到‘\r\n’,恭喜你,出錯了,這時候‘\r’不會被讀取到。後果就是譯碼時會出錯,譯碼到那裡時就開始跟原文不同了。
怎麼解決呢?
我給出的方案是:進行Huffman編碼和譯碼時,避免使用文字檔案來讀寫,採用二進位制檔案。在讀取原檔案和輸出譯碼後的檔案時,用文字檔案,而不用二進位制檔案,這樣才能保證檔案開啟時能正常顯示換行。
如圖:
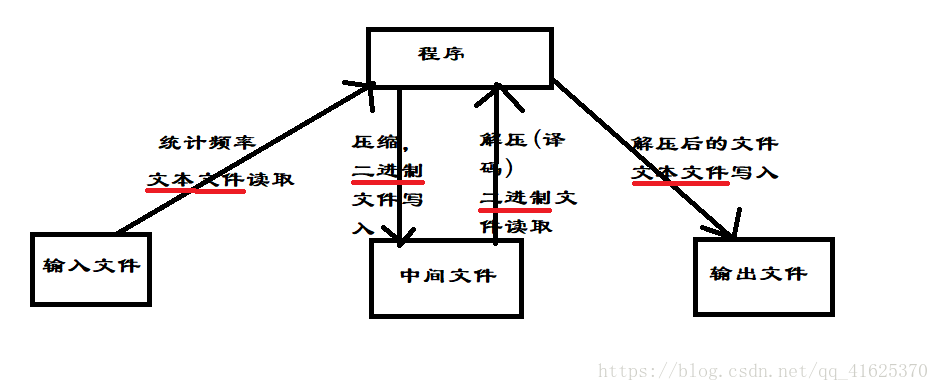
2、檔案讀取末尾問題
讀取檔案判斷末尾,c++用eof()或fail()方法都行,“11111111”並不會造成影響。
ifstream in("E:\fin.txt");
char ch;
while(!in.eof())
{
in.get(ch);
cout<<ch;
//其它操作......
}但是有點問題,就是最後一個字元會被讀取兩次,這是因為當檔案輸入流讀取不到時,它才會停止讀取。所以當讀取到最後一個字元時,in.eof()返回仍為false,所以會再執行in.get(ch),此時輸入流指標讀取不到,in.eof()才返回true。但ch未改變,導致檔案最後一個字元會被讀取兩遍。
最簡單的解決方案如下:
ifstream in("E:\fin.txt");
char ch;
while(!in.eof())
{
in.get(ch);
if(!in.eof()){ //再判斷一次
cout<<ch;
//其它操作......
}
}二、Huffman的實現(上程式碼)
編碼篇
1、統計頻率
//讀取原檔案,統計頻率並加入map中
void read_count(const char* fin) //char * fin為檔案路徑
{
char ch;
string s;
ifstream in(fin);
if(!in.good())
{
printf("Cannot open the file %s\n",fin );
return ;
}
while(!in.eof())
{
in.get(ch);
//該判斷用於避免讀取不存在的下一位
if(!in.eof()){
s=ch;
//這種查詢會增添新元素
map1[s]=map1[s]+1;
}
}
}2、建立Huffman樹
以下部分為所有的全域性變數(兩條線以內)
============================================================================
#define MAX 100000
//huffman樹 結點
struct Huffman
{
Huffman(string c,int n):num(n),ch(c),lchild(NULL),rchild(NULL) {}
Huffman():ch(""),lchild(NULL),rchild(NULL) {}
int num; //儲存頻數
string ch=""; //儲存字元
Huffman *lchild; //左子樹
Huffman *rchild; //右子樹
};
typedef Huffman* Node;//比較器,用於優先佇列
class Compare
{
public:
bool operator()(const Node& c1, const Node& c2) const
{
return (*c1).num > (*c2).num;
}
};//map對映,用於key與value的相互轉化,進行編解密
map<string,int>map1;
map<string,string>map2;
map<string,string>map3;
map<string,int>::iterator l_it; //迭代器,用於map的遍歷//優先佇列,輔助huffman樹的建立
priority_queue< Node, vector<Node>, Compare > pq;
string str="";
string result="";============================================================================
//得到初始的優先佇列
void getArray()
{
for(l_it = map1.begin(); l_it != map1.end(); l_it++)
{
Node node=new Huffman(l_it->first,l_it->second);
pq.push(node);
}
}//得到Huffman樹
void getTree()
{
while(pq.size()>1)
{
Node node1=pq.top(); //從優先佇列中彈出最小的數
pq.pop();
Node node2=pq.top(); //彈出最小的數
pq.pop();
string key=node1->ch+node2->ch;
int value=node1->num+node2->num; //新結點的頻數為兩個葉子結點的頻數和
Node node=new Huffman(key,value); //new新結點
node->lchild=node1; //左子樹
node->rchild=node2; //右子樹
pq.push(node); //將新結點加入優先佇列中
//printf("%s %d\n",node.ch.c_str(),node.num);
}
}3、獲取Huffman編碼表
//獲取Huffman編碼表
void getMap(string code,Node node)
{
//當遍歷結束時,返回
if(!node||node->ch=="")
{
return;
}
//當遇到葉子結點時,獲取huffman編碼並放入map2
if(node->ch.length()==1)
{
map2[node->ch]=code;
}
if(node->rchild)
{
//右結點+‘1’
Node right=node->rchild;
getMap(code+"1",right);
}
if(node->lchild)
{
//左結點+‘0’
Node left=node->lchild;
getMap(code+"0",left);
}
} 4、編碼
void compress(const char* fin,const char* fout)
{
//以二進位制形式開啟輸出檔案,且如果檔案已存在,則清空後再寫入
ofstream file(fout,ios_base::trunc|ios_base::binary);
//判斷檔案是否正常開啟
if(!file.good())
{
printf("Cannot open the file%s\n",fout );
return ;
}
//開啟輸入檔案
ifstream in(fin);
//判斷檔案是否正常開啟
if(!in.good())
{
printf("Cannot open the file%s\n",fin );
return ;
}
//迭代器,用於map的遍歷
map<string,string>::iterator l_it1;
//寫入huffman編碼個數
file<<map2.size()<<" ";
//遍歷map2中huffman結點並寫入檔案
for(l_it1 = map2.begin(); l_it1 != map2.end(); l_it1++)
{
//假如編碼的key為‘\n’時做的額外處理。因為此時'\n'要作為字元,而非隔離變數的標誌,可以去掉此句自行測試,看看會怎麼樣
if(l_it1->first.c_str()[0]=='\n'){
file<<endl;
}
//將編碼的key與value寫入檔案
file<<l_it1->first.c_str()<<l_it1->second.c_str()<<" ";
}
char ch;
string s;
string cs="";
int length=cs.length();
string str="";
unsigned char byte;
unsigned long temp;
while(!in.eof())
{
// MAX 防止出現string長度超出限制。當檔案很大時,必須要有此句
while(length<MAX&&!in.eof()){
//通過map2的huffman編碼表將原文轉成相應的編碼
in.get(ch);
if(!in.eof()){//防止讀取檔案末尾不存在的一位
s=ch;
cs+=map2[s];
length=cs.length();
}
}
//將轉化後的二進位制編碼串寫入檔案
while(length>=8)
{
//取前8b
str=cs.substr(0,8);
bitset<8> bits(str);
temp=bits.to_ulong();//轉換為long型別
byte=temp;//轉換為char型別
file<<byte;//寫入檔案
//取出剩下的二進位制串
cs=cs.substr(8,length-8);
length=cs.length();
}
}
//假如剩餘不足8位時,補足0並寫入檔案
if(length!=0)
{
str=cs.substr(0,length);
int n=0;
while(n<8-length) //補0
{
str+='0';
n++;
}
bitset<8> bits(str);
temp=bits.to_ulong();//轉換為long型別
byte=temp;//轉換為char型別
file<<byte; //寫入檔案
}
//寫入補0的個數,如果沒有則寫入0
char p=(char)(8-length)%8;
file<<p;
file.close();//關閉檔案
in.close();//關閉檔案
}//將char轉成string二進位制串
string turnachar(unsigned char c)
{
string k="";
int j=128; //後八位為 1000_0000
for(int i=0; i <8; i++)
{
//判斷原char該位數是0或1
k+=(unsigned char)(bool)(c&j)+'0';
j>>=1; //將1右移
}
//cout<<k;
return k;
}譯碼篇
1、獲取Huffman譯碼錶
2、譯碼
//獲取Huffman譯碼錶並進行譯碼
void decompress(const char* fin,const char* fout)
{
//1、獲取Huffman譯碼錶
//以二進位制的形式開啟編碼後的檔案
ifstream in(fin,ios_base::binary);
//假如檔案開啟失敗
if (in.fail()){
cout<<"Fail to open the file1 !!"<<endl;
return;
}
// QFile file;
// file.remove(fout);
//要以文字檔案形式開啟並寫入輸出檔案,不然回車換行不能正常顯示
ofstream out(fout,ios_base::trunc);
//假如檔案開啟失敗
if (out.fail()){
cerr<<"Fail to open the file2 !!"<<endl;
return;
}
map<string,char>map4;
int size;
char key;
char h;
string value;
//如果只是>>這種的話,會讀取不到\n,然後會出錯
in>>size;
in.get(h); //讀取掉空格
while(size>0)
{
in.get(key); //讀取key
in>>value; //讀取value
in.get(h); //讀取掉空格
map4[value]=key; //將key與value寫入map4
size--;
//cout<<value<<">>"<<key<<endl;
}
//2、開始譯碼
char c;
unsigned char c1;
string sc="";
int length=sc.length();
// int end = fgetc(&in);
while(!in.fail())
{
sc.clear();
result.clear();
length=sc.length();
while(length<MAX&&(!in.eof())){
in.get(c); //讀取每一個char
if(!in.eof()){//讀取到檔案末尾時起效,保證讀取正常
c1 = (unsigned char)c; //轉成無符號的
sc+=turnachar(c1); //轉化成原本的二進位制串
length=sc.length();
}
// end = fgetc(in);
}
// cerr<<length<<endl<<sc<<endl;
//當檔案結束時,去除補的0及記錄個數的char
if(in.fail()){
int num=(int)c; //num代表補0個數
sc=sc.substr(0,sc.length()-8-num);
}
string ss="";
int i=1;
bool check=false;
while(sc.length()>0)
{
//開始解碼
ss=sc.substr(0,i);
while(map4.find(ss)==map4.end()) //假如在Huffman表中找不到,繼續讀取下一位
{
i++;
length=sc.length();
//判斷是否超過原字串大小,避免報錯
if(i>length){
check=true;
break;
}
ss=sc.substr(0,i);
}
//用於退出兩層迴圈
if(check==true){
break;
}
//解碼
result+=map4[ss];
//去除已解碼的部分,繼續解碼
sc=sc.substr(i,sc.length()-i);
i=1;
}
//將解碼後的結果寫入檔案
out<<result;
//cerr<<"已經進行一個階段"<<endl;
//end = fgetc(in);
}
//關閉檔案
in.close();
out.close();
}解碼也要用到turnachar()函式,在編碼部分已給出。
最後
程式碼基本全了,不僅給出各個函式,全域性變數也已給出,而主函式只是呼叫他們。
普通字元和中文都能適用,假如想進一步精進,可以使用圖形化介面,真正弄成一個文字檔案壓縮的工具。