
一次線上介面超時的排查過程
1、事件還原
昨天下午,收到一個504的告警,顯然這是一個超時告警。當時由於手頭有其他事情,沒在意,就只是瞄了一眼,但是引起告警的方法很熟悉,是我寫的,第一反應有點詫異。
詫異之後,繼續處理手頭的工作。
一小時過後,又收到同樣的告警,顯然不是偶爾,肯定是哪兒出問題了,於是開始排查。
報警的介面是一個Controller層ControllerA的getControllerAMethod介面,其呼叫了多個微服務,並最終拼裝結果資料進行返回。出問題的是ServiceM,ServiceM服務裡的getServiceMMethod方法邏輯也很簡單,主要是兩次資料庫查詢,從MySQL資料庫取到資料並返回給呼叫方。
呼叫鏈如下圖所示

2、環境介紹
語言:Go
DB:MySQL
資料庫互動:database/sql(公司在此基礎上做了一些定製和封裝,本質還是database/sql)
下面開始介紹這個問題的具體排查過程。
3、本能反應:從sql語句入手
拿到告警,從告警資訊和對應的日誌詳情資訊來看,屬於超時問題。
第一反應是檢視sql語句是否是慢查詢(雖然打心裡知道這個可能性極低),sql語句很簡單,形如
select a, b, c from tableA where a in (a1,a2,a3)
不看執行計劃也知道是可以命中索引的。
但還是看了下執行計劃和真實的執行情況,分析結果和響應時間都相當可觀,沒有任何問題。
本能反應的排查就是這麼索然無味,開始下一步排查。
4、上游排查:是否context時間耗盡
既然是超時問題,有可能是上游超時,也可能是下游超時,第一步排查已經排除了下游因為慢查詢導致超時的可能性。
那會不會是上游超時呢?顯然是有可能的,畢竟我們知道Go的context可以一路傳遞下去,所有服務呼叫都共用設定的總的時間額度。
而且從上圖可以發現ServiceM也是在上游介面的最後一步,所以如果上面的服務佔用耗時過多,就會導致ServiceM的時間額度被壓縮的所剩無幾。
但是從日誌排查可以發現,在ServiceM層看getServiceMethod方法對應sql查詢幾乎都是幾十毫秒返回。
從這個情況來看,不像是因為上游時間不夠導致的超時。
5、下游初步排查:rows成主要懷疑物件
既然上游時間額度充足,那問題還是大概率出在下游服務介面上。
於是開始仔細閱讀getServiceMMethod方法程式碼,下面是程式碼功能的虛擬碼實現
rows, err = db.query(sql1)
if err != nil {
...
}
defer rows.Close()
for rows.Next() {
rows.scan(...)
}
rows, err = db.query(sql2)
if err != nil {
...
}
defer rows.Close()
for rows.Next() {
rows.scan(...)
}
看完程式碼,開始有點小興奮,我想沒錯了,大概就是這個rows的問題了。
在《Go元件學習——database/sql資料庫連線池你用對了嗎》這篇我主要介紹了有關rows沒有正常關閉帶來的坑。所以開始聯想是否是因為在遍歷rows過程中沒有正確關閉資料庫連線,造成連線洩露,以至於後面的查詢拿不到連線導致超時。
原因我已經分析的清清楚楚,但是具體是哪一步除了問題呢,唯一能想到的是這裡兩次查詢使用的是同一個rows物件,是不是某種情況導致在前一次已經關閉了連線而下一次查詢直接使用了關閉的連線而導致超時呢?
此時報警開始越來越頻繁,於是將這裡兩次查詢由原來的一個rows接收改為使用兩個rows分別接收並關閉,然後提交程式碼,測試通過後開始上線。
6、短暫的風平浪靜
程式碼上線後,效果立竿見影。
告警立馬停止,日誌也沒有再出現超時的資訊了,一切又恢復到了往日的平靜,這讓我堅信,我應該是找到原因並解決問題了吧。
回到家後,心裡還是有些不踏實,從11點開始,我拿出電腦,開始各種模擬、驗證和還原告警的原因。
7、三小時後,意識到風平浪靜可能是假象
從11點開始,一直到兩點,整整三個小時,我不但沒有找到原因,反而發現我的解決方式可能並沒有解決問題。
因為出問題的程式碼並不複雜,如上所示,即只有兩個Select查詢。
於是我寫了一段一樣的程式碼在本地測試,跑完後並沒有出現超時或者拿不到連線的情況。甚至,我將maxConn和IdleConn都設定為1也無不會出現超時。
除非,像文章《Go元件學習——database/sql資料庫連線池你用對了嗎》裡說的一樣,在row.Next()過程中提前退出且沒有rows.Close()語句,才會造成下一次查詢拿不到連線的情況,即如下程式碼所示
func oneConnWithRowsNextWithError() {
db, _ := db.Open("mysql", "root:rootroot@/dqm?charset=utf8&parseTime=True&loc=Local")
db.SetMaxOpenConns(1)
rows, err := db.Query("select * from test where name = 'jackie' limit 10")
if err != nil {
fmt.Println("query error")
}
i := 1
for rows.Next() {
i++
if i == 3 {
break
}
fmt.Println("close")
}
row, _ := db.Query("select * from test")
fmt.Println(row, rows)
}
但是原來的程式碼是有defer rows.Close()方法的,這個連線最終肯定是會關閉的,不會出現記憶體洩露的情況。
這一刻,我想到了墨菲定律(因為沒有真正解決問題,問題還回再次出現)。
於是,我又開始扒原始碼,結合日誌,發現一條重要線索,就是很多查詢任務都是被主動cancel的。沒錯,這個cancel就是context.Timeout返回的cancel(這段程式碼是我司在database/sql基礎上豐富的功能)。
cancel觸發的條件是執行database/sql中的QueryContext方法返回了err
// QueryContext executes a query that returns rows, typically a SELECT.
// The args are for any placeholder parameters in the query.
func (db *DB) QueryContext(ctx context.Context, query string, args ...interface{}) (*Rows, error) {
var rows *Rows
var err error
for i := 0; i < maxBadConnRetries; i++ {
rows, err = db.query(ctx, query, args, cachedOrNewConn)
if err != driver.ErrBadConn {
break
}
}
if err == driver.ErrBadConn {
return db.query(ctx, query, args, alwaysNewConn)
}
return rows, err
}
第一反應還是上游時間不夠,直接cancel context導致的,但是這個原因我們在前面已經排除了。
於是把這段程式碼一直往下翻了好幾層,還一度懷疑到我們自研程式碼中的一個引數叫QueryTimeout是否配置過小,但是去看了一眼配置(這一眼很重要,後面會說),發現是800ms,顯然是足夠的。
帶著越來越多的問題,我心不甘情不願的去睡覺了。
8、墨菲定律還是顯靈了
今天下午一點,我又收到了這個熟悉的告警,該來的總會來的(但是隻收到一次告警)。
前面說了,這個cancel可能是一個重要資訊,所以問題的原因是沒跑了,肯定是因為超時,超時可能是因為拿不到連線。
因為getServiceMMethod已經排查一通了,並沒有連線洩露的情況,但是其他地方會不會有洩漏呢?於是排查了ServiceM服務的所有程式碼,對於使用到rows物件的程式碼檢查是否有正常關閉。
排查後,希望破滅。
到此為止,我打心裡已經排除了是連線洩露的問題了。
期間,我還問了我們DBA,因為我翻了下日誌,今天上午8點左右有幾條查詢都在幾百毫秒,懷疑是DB狀態異常導致的。DBA給我的回覆是資料庫非常正常。
我自己也看了監控,DB的狀態和往日相比沒有什麼流量異常,也沒有連線池數量的大起大落。
同事說了前幾天上了新功能,量比以前大,於是我也看了下新功能對應的程式碼,也沒發現問題。
9、準備"曲線救國"
我想要的根本原因還沒有找到,於是開始想是否可以通過其他方式來規避這個未知的問題呢。畢竟解決問題的最好方式就是不解決(換另一種方式)。
準備將ServiceM方法的超時時間調大。
也準備在ServiceM服務的getServiceMMethod方法新增快取,通過快取來抵擋一部分請求量。
行吧,就到此為止,明天先用這兩招試試看。
於是,我準備站起來活動活動,順便在腦海裡盤點下這個告警的來龍去脈。
10、靈機一動,我找到了真相
上游告警,下游超時 ->
排除上游時間不夠 ->
排除下游rows未關閉 ->
排除資料庫狀態不穩定 ->
確定是下游超時 ->
懷疑是拿不到連線 ->
拿不到連線,拿不到連線, 拿不到連線
於是又去翻資料庫引數配置,剛上面是為了翻QueryTimeout引數,依稀記得這裡的連線池設定不大。翻到配置看了下,idleConn=X,maxConn=Y。
再去看了一眼getServiceMMethod方法的QPS監控,我覺得我找到了真相。
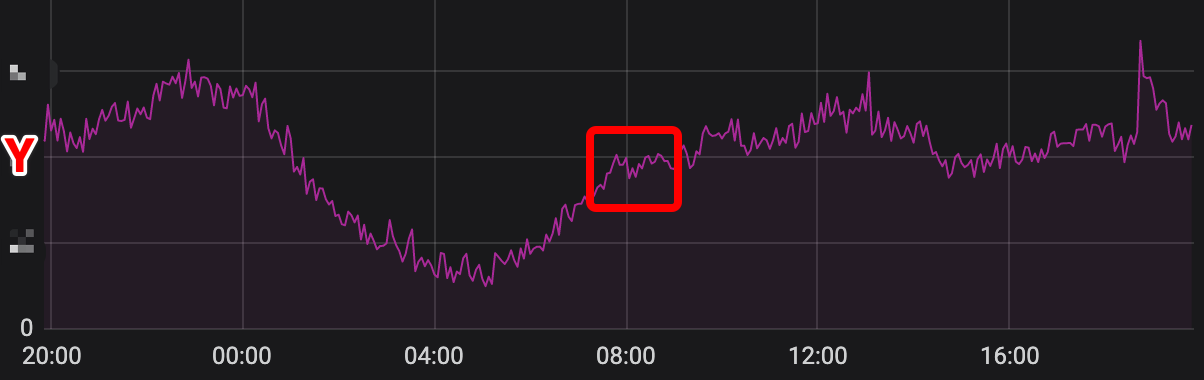
從凌晨到早上八點,QPS一直在上升,一直到8點左右,突破Y,而maxConn=Y。
所以應該是超過maxConn,導致後面的查詢任務拿不到連線只能等待,等待到超時時間後還是沒有拿到連線,所以觸發上面說的cancel,從而也導致在上游看到的超時告警都是ServiceM的getServiceMMethod執行了超時時間,因為一直在等待。
那麼為什麼圖中有超過Y的時候沒有一直報警呢,我理解應該是這期間有其他任務已經執行完查詢任務將連線放回連線池,後面來的請求就可以直接使用了,畢竟還會有一個超時時間的等待視窗。
那麼為什麼之前沒有出現這種報警呢,我理解是之前量比較小,最近同事上線了新功能,導致該介面被呼叫次數增加,才凸顯了這個問題。
11、 總結
其實,最後原因可能很簡單,就是量起來了,配置的連線數顯得小了,導致後來的查詢任務拿不到連線超時了。
但是這個超時橫跨Controller層到Service以及最底層的DB層,而每一層都可能會導致超時,所以排查相對比較困難。
下面是一些馬後炮要點
- 最近改動的程式碼需要格外重視。如果以前長時間沒有告警,最近上完新程式碼告警了,大概率和上線有關係(本次超時其實和新上線程式碼也有關係,雖然程式碼本身沒有問題,但是新上線後流量變大了)
- 善用工具。用好監控和日誌等系統工具,從中找出有用的線索和聯絡。
- 自上而下排查並追蹤。針對不好定位的bug,可以按照一定順序比如呼叫順序依次檢查、驗證、排除,直到找到原因。
&n