
倒排索引的 MR 實現 demo
InverseIndexStepOne
import java.io.IOException; import org.apache.commons.lang.StringUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.InputSplit; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.FileSplit; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import cn.itcast.hadoop.mr.flowsort.SortMR; import cn.itcast.hadoop.mr.flowsort.SortMR.SortMapper; import cn.itcast.hadoop.mr.flowsort.SortMR.SortReducer; import cn.itcast.hadoop.mr.flowsum.FlowBean; /** * 倒排索引步驟 ——job * * @author [email protected] * */ public class InverseIndexStepOne { public static class StepOneMapper extends Mapper<LongWritable, Text, Text, LongWritable> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 拿到一行資料 String line = value.toString(); //切分出各個單詞 String[] fields = StringUtils.split(line, " "); // 獲取這一行資料所在的檔案切片 FileSplit inputSplit = (FileSplit) context.getInputSplit(); // 從檔案切片中獲取檔名 String fileName = inputSplit.getPath().getName(); for (String field : fields) { // 封裝 kv 輸出,k: hello-->a.txt v: 1 context.write(new Text(field + "-->" + fileName), new LongWritable(1)); } } } public static class StepOneReducer extends Reducer<Text, LongWritable, Text, LongWritable> { // <hello-->a.txt,{1,1,1....}> @Override protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException { long counter = 0; for (LongWritable value : values) { counter += value.get(); } context.write(key, new LongWritable(counter)); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(InverseIndexStepOne.class); job.setMapperClass(StepOneMapper.class); job.setReducerClass(StepOneReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); FileInputFormat.setInputPaths(job, new Path(args[0])); //檢查一下,引數所指定的輸出路徑是否存在,如果已經存在,先刪除 Path output = new Path(args[1]); FileSystem fs = FileSystem.get(conf); if (fs.exists(output)) { fs.delete(output, true); } FileOutputFormat.setOutputPath(job, output); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
打 jar 包,先 put 上去。
一頓操作:30.00
InverseIndexStepTwo
import java.io.IOException; import org.apache.commons.lang.StringUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Mapper.Context; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.Reducer; import cn.itcast.hadoop.mr.ii.InverseIndexStepOne.StepOneMapper; import cn.itcast.hadoop.mr.ii.InverseIndexStepOne.StepOneReducer; public class InverseIndexStepTwo { public static class StepTwoMapper extends Mapper<LongWritable, Text, Text, Text>{ //k: 行起偏移量 v: {hello-->a.txt 3} @Override protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException { String line = value.toString(); String[] fields = StringUtils.split(line, "\t"); String[] wordAndfileName = StringUtils.split(fields[0], "-->"); String word = wordAndfileName[0]; String fileName = wordAndfileName[1]; long count = Long.parseLong(fields[1]); context.write(new Text(word), new Text(fileName+"-->"+count)); //map輸出的結果是這個形式: <hello,a.txt-->3> } } public static class StepTwoReducer extends Reducer<Text, Text,Text, Text>{ @Override protected void reduce(Text key, Iterable<Text> values,Context context) throws IOException, InterruptedException { //拿到的資料 <hello,{a.txt-->3,b.txt-->2,c.txt-->1}> String result = ""; for(Text value:values){ result += value + " "; } context.write(key, new Text(result)); //輸出的結果 k: hello v: a.txt-->3 b.txt-->2 c.txt-->1 } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); //構造job_one // Job job_one = Job.getInstance(conf); // // job_one.setJarByClass(InverseIndexStepTwo.class); // job_one.setMapperClass(StepOneMapper.class); // job_one.setReducerClass(StepOneReducer.class); //...... //構造job_two Job job_tow = Job.getInstance(conf); job_tow.setJarByClass(InverseIndexStepTwo.class); job_tow.setMapperClass(StepTwoMapper.class); job_tow.setReducerClass(StepTwoReducer.class); job_tow.setOutputKeyClass(Text.class); job_tow.setOutputValueClass(Text.class); FileInputFormat.setInputPaths(job_tow, new Path(args[0])); //檢查一下引數所指定的路徑是否存在,如果已存在,先刪除 Path output = new Path(args[1]); FileSystem fs = FileSystem.get(conf); if(fs.exists(output)){ fs.delete(output, true); } FileOutputFormat.setOutputPath(job_tow, output); //先提交 job_oneִ 執行 // boolean one_result = job_one.waitForCompletion(true); // if(one_result){ System.exit(job_tow.waitForCompletion(true)?0:1); // } } }
相關推薦
倒排索引 mr實現
Map階段 <0,"this is google"> .... context.write("google ->a.txt",1); context.write("google -&g
MapReduce 倒排索引的實現
package cheryl.dhcc.mapreduce; import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configu
倒排索引C++實現
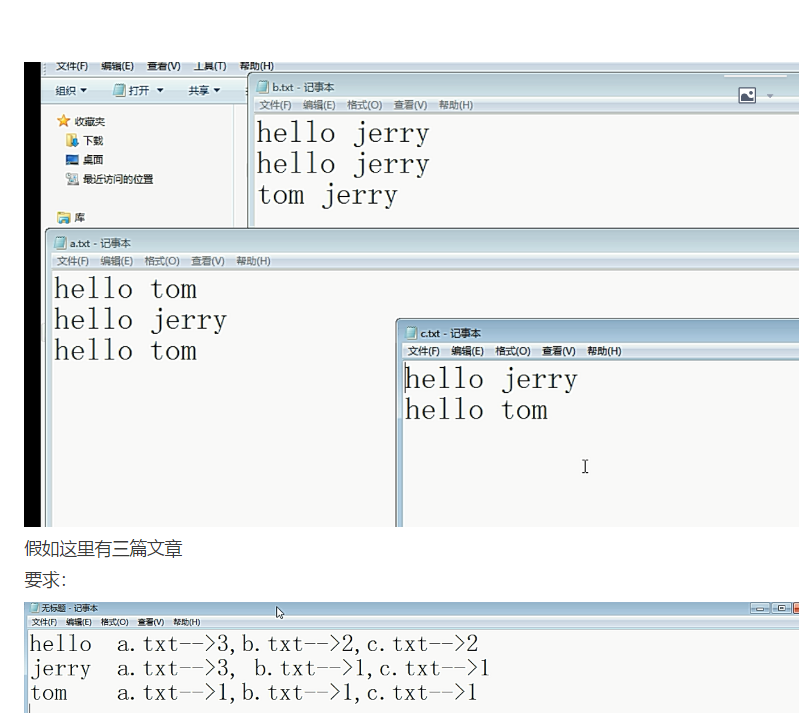
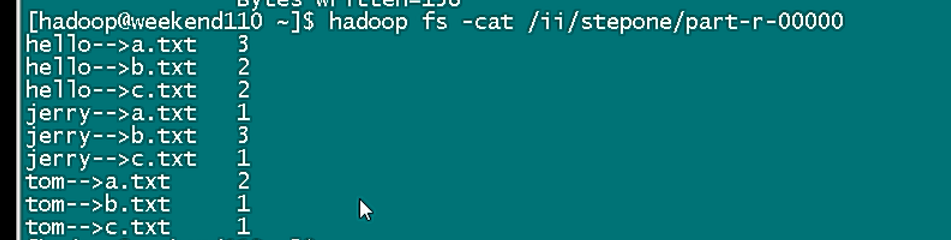
倒排索引原理:根據屬性的值來查詢記錄位置。 假設有3篇文章,file1, file2, file3,檔案內容如下: file1 (單詞1,單詞2,單詞3,單詞4....) file2 (單詞a,單詞b
倒排索引的實現
https://blog.csdn.net/xn4545945/article/details/8791484倒排索引(英語:Inverted index),也常被稱為反向索引、置入檔案或反向檔案,是一種索引方法,被用來儲存在全文搜尋下某個單詞在一個文件或者一組文件中的儲存位
C++ 倒排索引的實現
1.1基本介紹 倒排索引的概念很簡單:就是將檔案中的單詞作為關鍵字,然後建立單詞與檔案的對映關係。當然,你還可以新增檔案中單詞出現的頻數等資訊。倒排索引是搜尋引擎中一個很基本的概念,幾乎所有的搜尋引擎都會使用到倒排索引。 1.2 準備工作 ² 5個原始檔 Test0
倒排索引的 MR 實現 demo
InverseIndexStepOne import java.io.IOException; import org.apache.commons.lang.StringUtils; import org.apache.hadoop.conf.Configuration;
我愛分享----百萬商業圈C語言實現的倒排索引算法(含全部源碼)
db4 cover cst via com deb nio main 20M PAT-1134VertexCover(圖的建立+set容器) 刷題——POJ2395OutofHay QGC之QGCView.qml HDU-2049不容易系列之四(考新郎) 2e5訟矣屎htt
大資料入門(12)mr倒排索引.
package com.hadoop.hdfs.mr.flowsort; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; im
倒排索引原理和實現
轉載https://blog.csdn.net/u011239443/article/details/60604017 倒排索引原理和實現 關於倒排索引 場景是:給定幾個關鍵詞,找出包含關鍵詞的文件 倒排索引: 不是由記錄來確定屬性值,而是由屬性值來確定記錄的位置
Lucene全文檢索之倒排索引實現原理、API解析【2018.11】
》 官網 http://lucene.apache.org/ 下載地址:https://mirrors.tuna.tsinghua.edu.cn/apache/lucene/java/7.5.0/ 》 Lucene的全文檢索是指什麼: 程式掃描文件
MapReduce實現倒排索引
倒排索引這個名字讓人很容易誤解成A-Z,倒排成Z-A;但實際上缺不是這樣的。 一般我們是根據問檔案來確定檔案內容,而倒排索引是指通過檔案內容來得到文件的資訊,也就是根據一些單詞判斷他在哪個檔案中。 知道了這一點下面就好做了: 準備一些元資料 下面我們要進行兩次MapR
倒排索引的分散式實現(MapReduce程式)
package aturbo.index.inverted; import java.io.IOException; import java.util.HashSet; import org.apache.commons.lang3.StringUtils; imp
python 實現倒排索引
程式碼如下: #encoding:utf-8 fin = open('1.txt', 'r') ''' 建立正向索引: “文件1”的ID > 單詞1:出現位置列表;單詞2:出現位置列表;…
倒排索引構建演算法SPIMI(已實現,修訂版)
TA011121600045170###347###A0###2###20111214213127###86b4bc20eb98b1eb21932ebf5dcfcca5###1###蘭州###空氣質量# TA011121600045168###347###A0###2###20111215181000###e
Hadoop環境搭建及實現倒排索引
目 錄 1.應用介紹 3 1.1實驗環境介紹 3 1.2應用背景介紹 3 1.3應用的意義與價值 4 2.資料及儲存 5 2.1資料來源及資料量 5 2.2資料儲存解決方案 5 3.分析處理架構 5 3.1架構設計和處理方法
倒排索引的java實現
假設有3篇文章,file1, file2, file3,檔案內容如下: 檔案內容程式碼 file1 (單詞1,單詞2,單詞3,單詞4....) file2 (單詞a,單詞b,單
倒排索引詳解及C++實現
1.介紹 倒排索引是現代搜尋引擎的核心技術之一,其核心目的是將從大量文件中查詢包含某些詞的文件集合這一任務用O(1)或O(logn)的時間複雜度完成,其中n為索引中的文件數目。也就是說,利用倒排索引技術,可以實現與文件集大小基本無關的檢索複雜度,這一點對於
一些演算法的MapReduce實現——倒排索引實現
/** * input format * docid<tab>doc content * * output format * (term:docid)<tab>(tf in this doc) * */ public s
Hadoop 文件倒排索引實現
在上黃宜華老師的MapReduce的課程中,會有實驗讓實現帶詞頻的文件倒排索引。一般情況下根據他的書就能實現基本的東西,但是根據書上的程式碼,執行的時候可能會有一些小的trick,會報出一些異常。其實如果參照這個文章 《Hadoop之倒排索引》就能實現所需要的功能了。但是本
檔案倒排索引演算法及其hadoop實現
什麼是檔案的倒排索引? 簡單講就是一種搜尋引擎的演算法。過倒排索引,可以根據單詞快速獲取包含這個單詞的文件列表。倒排索引主要由兩個部分組成:“單詞”和對應出現的“倒排檔案”。 MapReduce的設計思路 整個過程包含map、combiner、reduce三個階段,