
利用python爬蟲關鍵詞批量下載高清大圖
前言
在上一篇寫文章沒高質量配圖?python爬蟲繞過限制一鍵搜尋下載圖蟲創意圖片!中,我們在未登入的情況下實現了圖蟲創意無水印高清小圖的批量下載。雖然小圖能夠在一些移動端可能展示的還行,但是放到pc端展示圖片太小效果真的是很一般!建議閱讀本文檢視上一篇文章,在具體實現不做太多介紹,只講個分析思路。
當然,本文可能技術要求不是特別高,但可以當作一個下圖工具使用。
環境:python3+pycharm+requests+re+BeatifulSoup+json
 在這裡插入圖片描述
在這裡插入圖片描述
這個確實也屬實有一些勉強,不少童鞋私信問我有木有下載大圖的原始碼,我說可能會有,現在分享給大家。
當然對於一個圖片平臺來說,高質量圖片下載可能是其核心業務
以下幾種方法。
對圖蟲平臺初步分析之後,得到以下觀點:
- 原版高質量無水印圖片下載太貴,由於沒付費下載沒有找到高質量圖的高清無水印原圖真實地址。沒有辦法(能力) 下載原版高清無水印。並且筆者也能猜測這個是一個網站的核心業務肯定也會層層設套。不會輕易獲得,所以並沒有對付費高清高質量無水印圖片窮追不捨。
- 但是高質量展示圖在預覽時候的是可以檢視帶有水印的高清圖的(帶著圖蟲創意水印)。
- 網站有一些免費的高清大圖圖片可以獲取到。雖然這個
不是精選圖,但是質量也還可以!
下載免費高清大圖
在圖蟲創意有個板塊的圖片是免費開放的。在共享圖片專欄。的圖片可以搜尋下載。
https://stock.tuchong.com/topic?topicId=37 圖蟲創意url地址
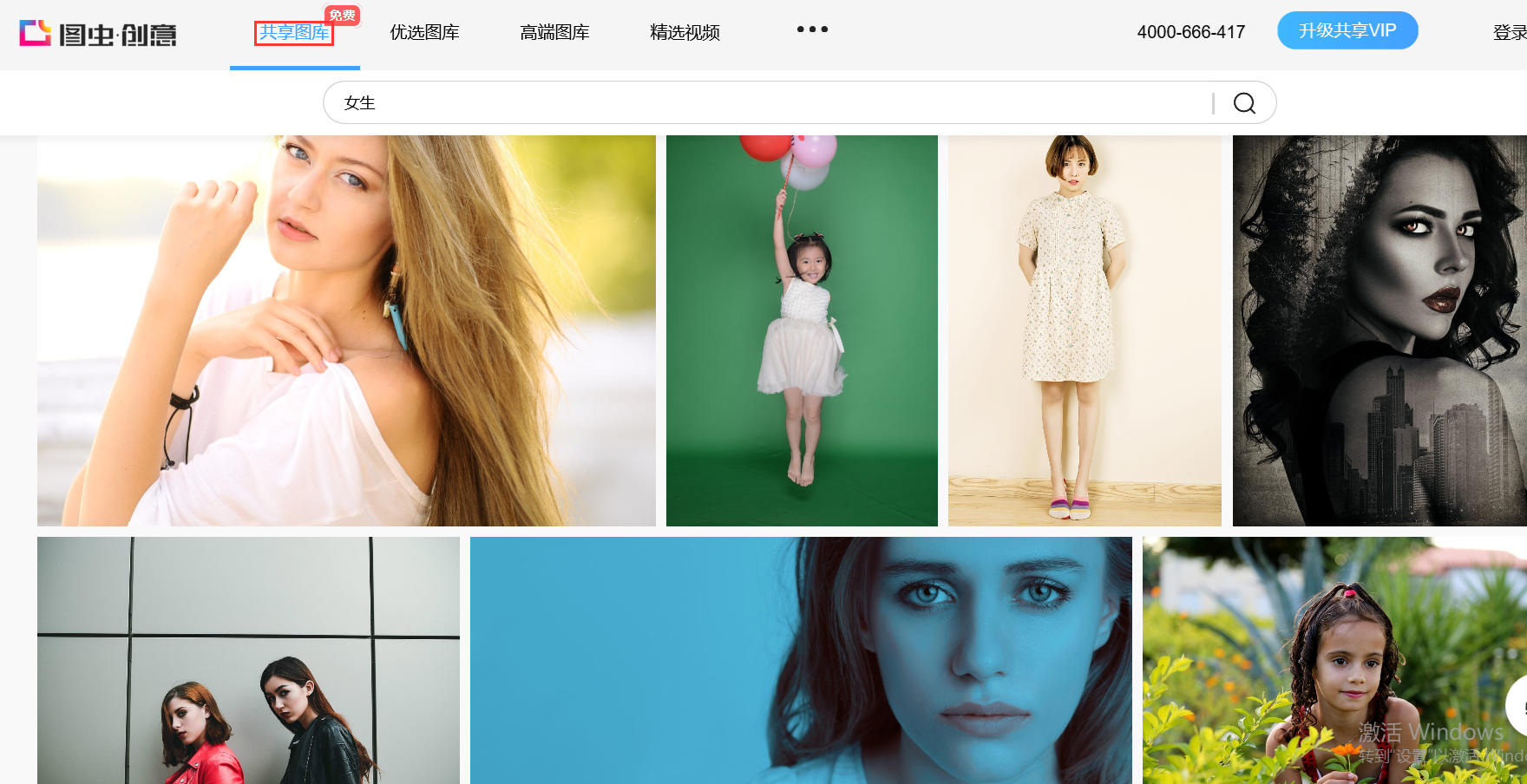 在這裡插入圖片描述
在這裡插入圖片描述
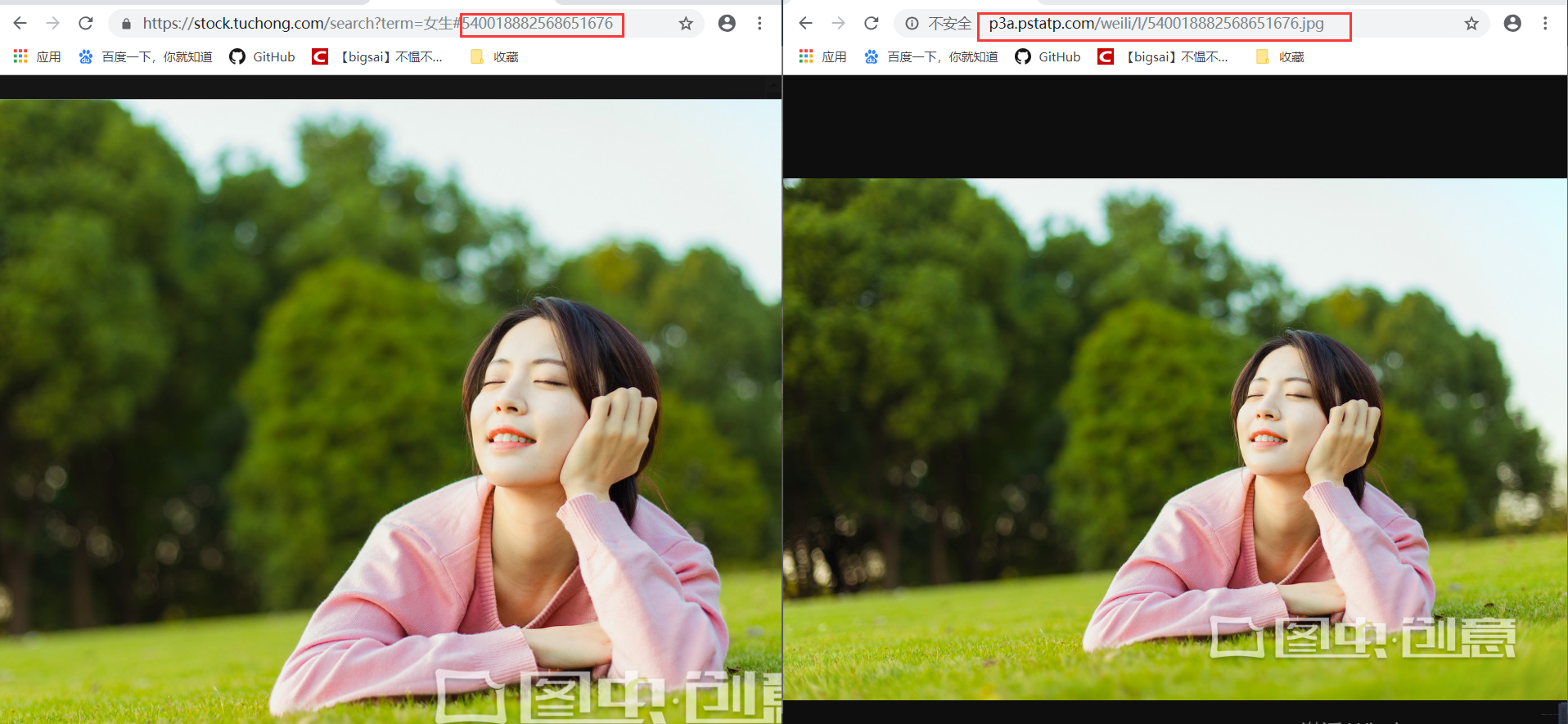
找到一張圖片點進去,檢查地址你可以直接訪問得到。而有相關因素的就是一個圖片伺服器域名+圖片id組成的圖片url地址。也就是我們要批量找到這些圖片的id。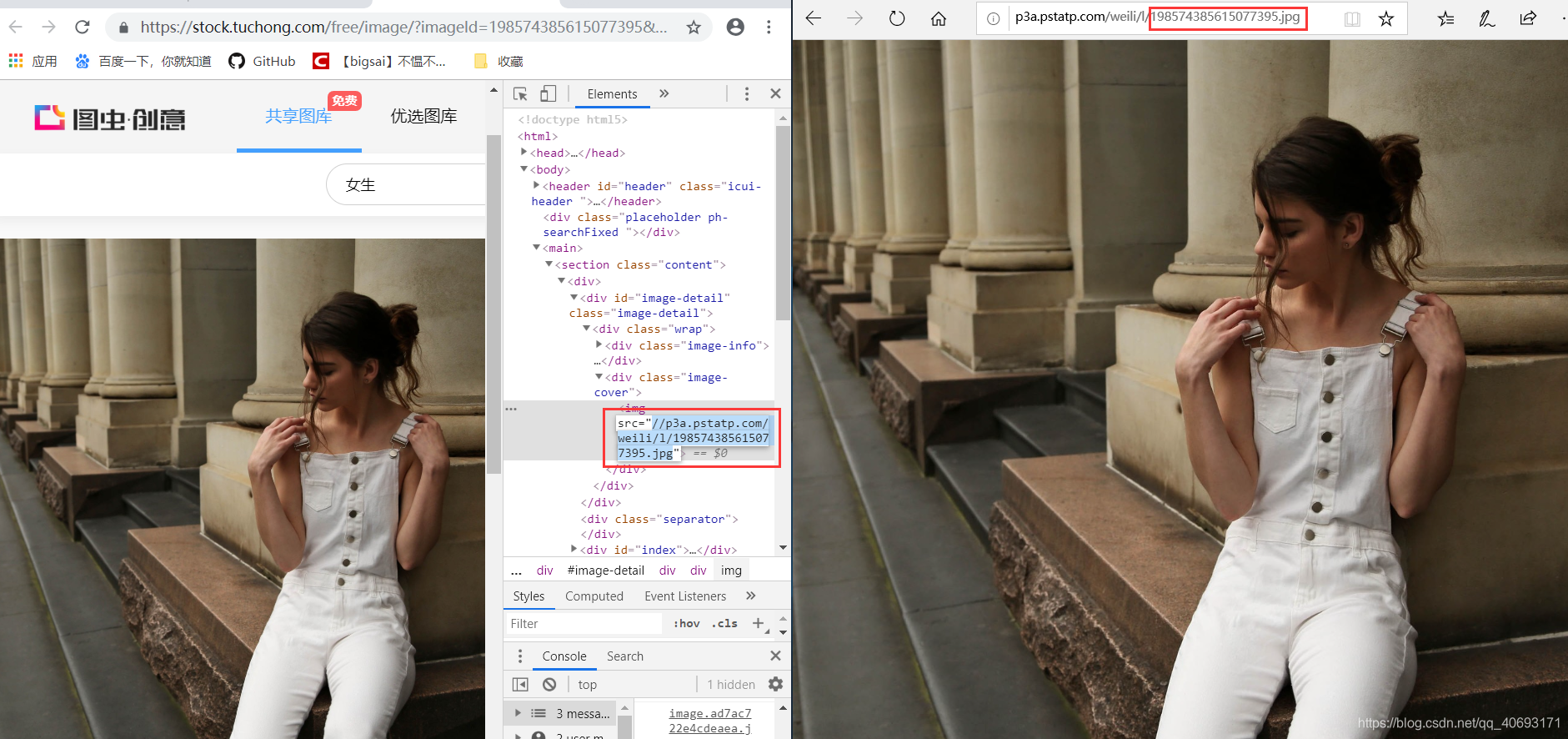 在這裡插入圖片描述
在這裡插入圖片描述
在搜尋介面檢視原始碼,發現這個和前面的分析如出一轍,它的圖片id藏在js裡面。我們只需通過正則解析。拿到id然後拼湊url即可完成所有圖片地址,這個解析方式和上文基本完全一致,只不過是瀏覽器的URL和js的位置有相對的變化只需小量修改,然後直接爬蟲下載儲存即可!而這個搜尋html的url就是https://stock.tuchong.com/free/search/?term=
搜尋內容。這個下載內容的實現在上一篇已經分析過。請自行檢視或看下文程式碼!這樣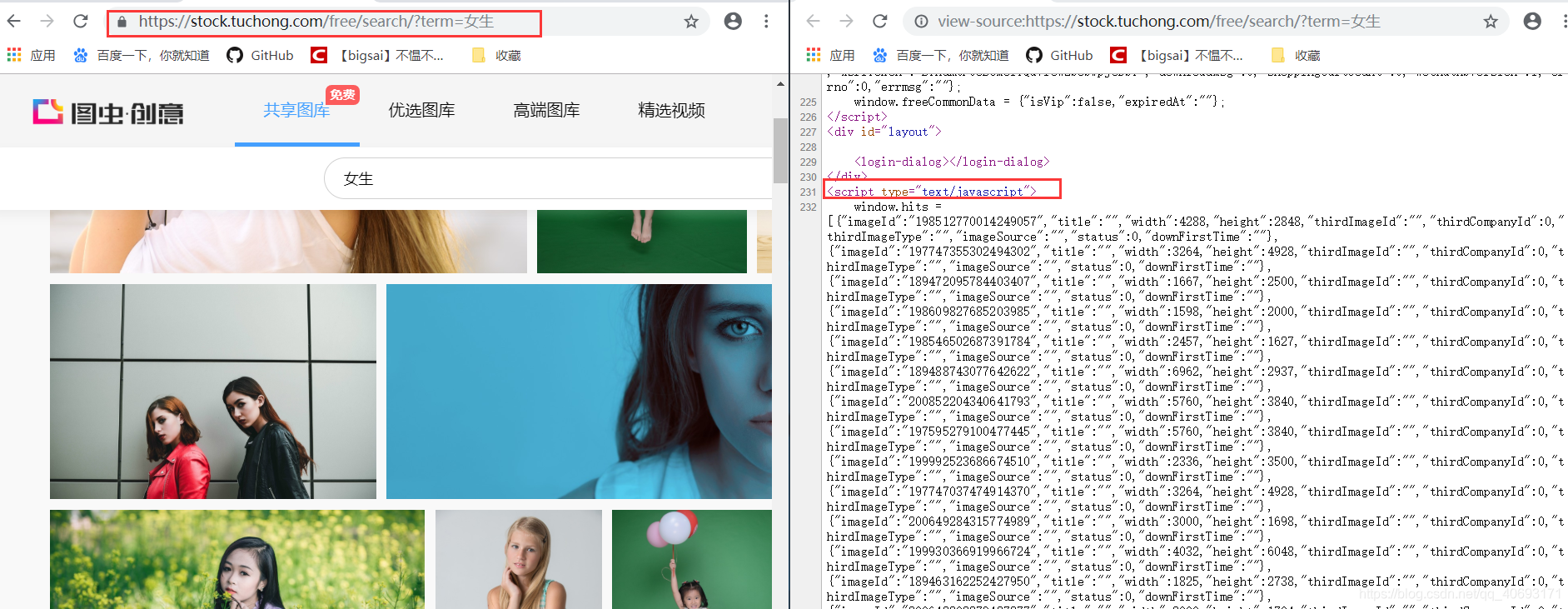 在這裡插入圖片描述
在這裡插入圖片描述
下載帶水印的精選圖
好的圖片都在優選圖片專欄。然而這部分圖片我們可以免費獲取帶水印的圖片。
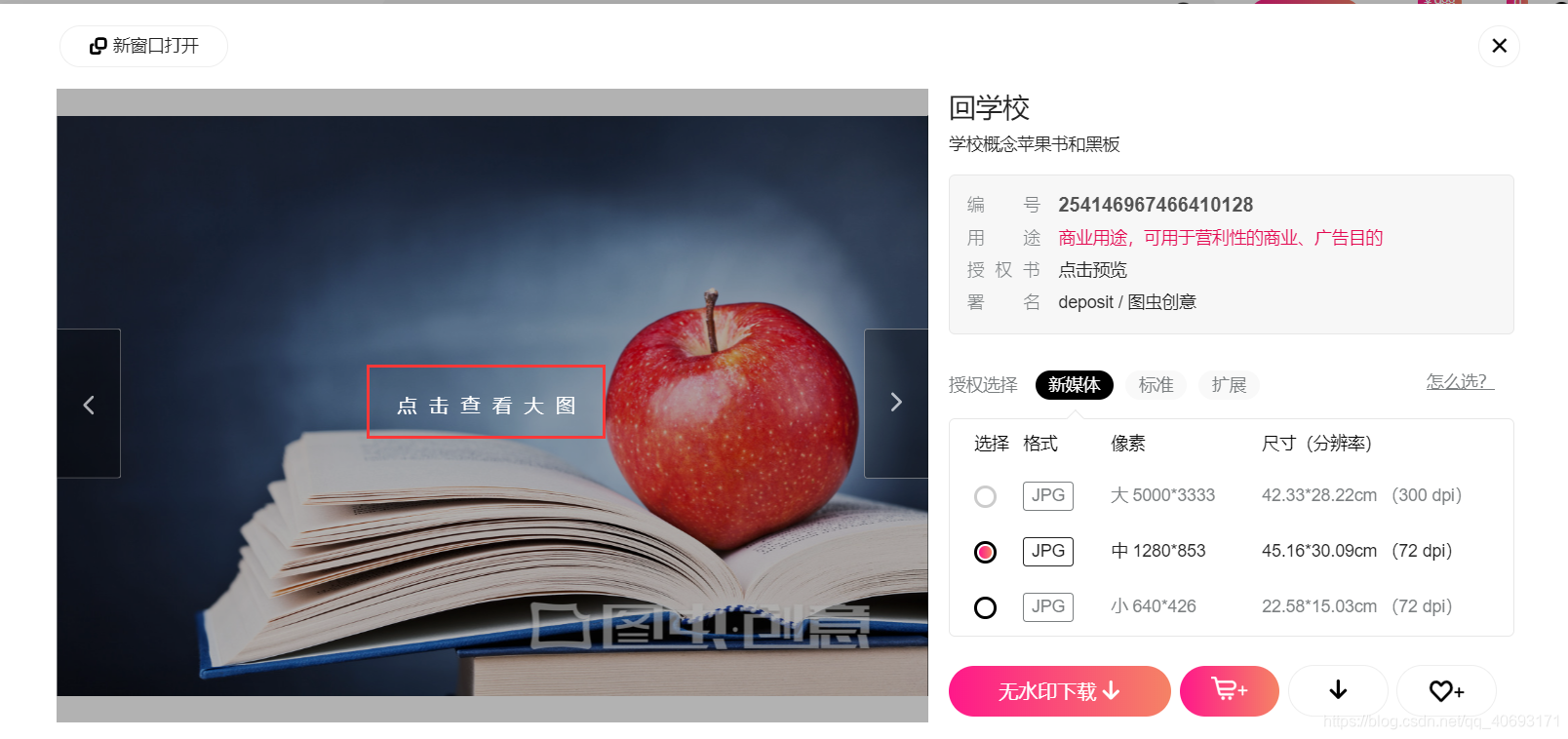
在登入賬號之後點開的圖片預覽,當你點開預覽的時候是可以看得到圖片的。每張圖片對應一個唯一ID,這個地址可以獲得但是比較麻煩。我們嘗試能不能獲得一個簡單通用的url地址呢?
 在這裡插入圖片描述
在這裡插入圖片描述
經過嘗試發現這個圖片的url可以在我們上面的免費高清大圖url地址共用!也就是我們可以得到這個ID通過上個url來批量獲取下載圖片!下載圖片的方法一致不需要重複造輪子。而id的獲取方法我們在下載高清小圖就已經詳細介紹過了也是一樣的。那麼分析就已經成功了,程式碼將在後面給出,這樣我們可以下載帶水印的高清大圖了!
##js的解析規則:
#----
js=soup.select('script') js=js[4]
pattern = re.compile(r'window.hits = (\[)(.*)(\])')
va = pattern.search(str(js)).group(2)#解析js內容
#-------
 在這裡插入圖片描述
在這裡插入圖片描述
當然,就配圖而言還是高質量圖的質量高很多,如果可以接受的話可以使用。唯一缺點就是圖創水印。
程式碼與總結
import requests
from urllib import parse
from bs4 import BeautifulSoup
import re
import json
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36',
'Cookie': 'wluuid=66; ',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'Accept-encoding': 'gzip, deflate, br',
'Accept-language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'connection': 'keep-alive'
, 'Host': 'stock.tuchong.com',
'Upgrade-Insecure-Requests': '1'
}
def mkdir(path):
import os# 引入模組
path = path.strip()# 去除首位空格
path = path.rstrip("\\") # 去除尾部 \ 符號
isExists = os.path.exists(path) # 判斷路徑是否存在 # 存在 True # 不存在 False
if not isExists: # 判斷結果
os.makedirs(path)# 如果不存在則建立目錄 # 建立目錄操作函式
return True#print (path + ' 建立成功')
else:
# 如果目錄存在則不建立,並提示目錄已存在
#print(path + ' 目錄已存在')
return False
def downloadimage(imageid,imgname):##下載大圖和帶水印的高質量大圖
url = 'https://weiliicimg9.pstatp.com/weili/l/'+str(imageid)+'.webp'
url2 = 'https://icweiliimg9.pstatp.com/weili/l/'+str(imageid)+'.webp'
b=False
r = requests.get(url)
print(r.status_code)
if(r.status_code!=200):
r=requests.get(url2)
with open(imgname+'.jpg', 'wb') as f:
f.write(r.content)
print(imgname+" 下載成功")
def getText(text,free):
texturl = parse.quote(text)
url="https://stock.tuchong.com/"+free+"search?term="+texturl+"&use=0"
print(url)
req=requests.get(url,headers=header)
soup=BeautifulSoup(req.text,'lxml')
js=soup.select('script')
path=''
if not free.__eq__(''):
js=js[1]
path='無水印/'
else:
js=js[4]
path='圖蟲創意/'
print(js)
pattern = re.compile(r'window.hits = (\[)(.*)(\])')
va = pattern.search(str(js)).group(2)#解析js內容
print(va)
va = va.replace('{', '{').replace('}', '},,')
print(va)
va = va.split(',,,')
print(va)
index = 1
for data in va:
try:
dict = json.loads(data)
print(dict)
imgname='img2/'+path+text+'/'+dict['title']+str(index)
index+=1
mkdir('img2/'+path+text)
imgid=dict['imageId']
downloadimage(imgid,imgname)
except Exception as e:
print(e)
if __name__ == '__main__':
num=input("高質量大圖帶水印輸入1,普通不帶水印輸入2:")
num=int(num)
free=''
if num==2:
free='free/'
text = input('輸入關鍵詞:')
getText(text,free)
這樣,整個流程就完成了,對於目錄方面,我也對圖蟲有水印的和沒水印的進行了區分,供大家使用。在使用方面,先輸入1或2(1代表有水印高質量圖,2代表共享圖),在輸入關鍵詞即可批量下載。
 在這裡插入圖片描述
在這裡插入圖片描述 在這裡插入圖片描述
在這裡插入圖片描述
最後,如果感覺可以的話歡迎點讚唄!歡迎關注筆者公眾號:bigsai
IT圈不嫌多一個朋友,筆者也希望能成為你的朋友,共同學習,共同進步!
相關推薦
利用python爬蟲關鍵詞批量下載高清大圖
前言 在上一篇寫文章沒高質量配圖?python爬蟲繞過限制一鍵搜尋下載圖蟲創意圖片!中,我們在未登入的情況下實現了圖蟲創意無水印高清小圖的批量下載。雖然小圖能夠在一些移動端可能展示的還行,但是放到pc端展示圖片太小效果真的是很一般!建議閱讀本文檢視上一篇文章,在具體實現不做太多介紹,只講個分析思路。 當然,本
如何免登入批量下載特定使用者的微博高清大圖?
早年人人還有這個功能:批量下載某個使用者的所有圖片,而且都是高清大圖。但是到了微博,官方似乎沒有這項功能,難道需要一張張右鍵另存為?這裡有個java程式可以解決你的問題。 git clone https://github.com/yAnXImIN/weiboPicDownl
python妹子圖爬蟲5千張高清大圖突破防盜鏈福利5千張福利高清大圖
服務 usr 繞過 盜鏈 ext 思路 推薦 class h+ meizitu-spider python通用爬蟲-繞過防盜鏈爬取妹子圖 這是一只小巧方便,強大的爬蟲,由python編寫 所需的庫有 requests BeautifulSoup os lxm
利用runLoop加載高清大圖
sde log 完成 red get 網絡 server lease 技術分享 一、什麽是runLoop 1、說白了,runloop就是運行循環 2、runloop,他是多線程的法寶 通常來講,一個線程一次只能執行一個任務,執行完之後就退出線程。但是,對於主
CAD轉換為JPG高清大圖?一鍵教你快速簡單操作
點擊 如何快速 轉換 迅捷 解決 樣式 現在 質量 下載 在這個快速化的時代,一切都講究速度,那我們如何快速的解決問題呢?很簡單的例子,現在幾乎都用得到CAD相關轉換的問題,那如何快速的將CAD圖紙文件轉換為JPG圖片樣式呢?不需要下載任何軟件,下面將進行演示方法。步驟一:
Android之打造自己載入高清大圖及瀑布流框架.解決錯位等問題.
首先看效果圖如下: 本框架支援本地圖片和網路圖片的獲取.採用LruCache演算法,最少使用的最先釋放.有效的避免OOM,專案結構圖: 核心載入類在於ImageLoader.採用了TreadPool去做併發請求.UI處理採用Handler
18大產業的產業鏈全景圖!(高清大圖)
origin: http://mt.sohu.com/20160824/n465750822.shtml 內容涵蓋: 1.全球手機產業鏈 2.全球汽車產業鏈 3.飛機產業鏈 4.VR產業鏈 5.新能源汽車產業鏈 6.無人機產業鏈 7
IOS 多個UIImageView 載入高清大圖時記憶體管理
當我們在某一個View 多個UIImageView,且UIImageView都顯示的是高清大圖,就有可能出現記憶體警告的問題。如果第一次進入這個view,沒有發生記憶體警告,當再次進入這個view,如果上一次的記憶體沒有及時釋放,這一次次的累加,便可導致記憶體崩潰。 1,
淺談android中載入高清大圖及圖片壓縮方式(二)
這一講就是本系列的第二篇,一起來聊下關於android中載入高清大圖的問題,我們都知道如果我們直接載入原圖的話,一個是非常慢,需要等待一定時間,如果沒有在一定的時間內給使用者響應的話,將會極大影響使用者的體驗。另一個是如果你的手機記憶體小的話,可能會直接崩潰。這也就是直
runloop實戰應用——載入高清大圖
問題描述 在用tableVIew或者scrollView載入多張高清大圖的時候,頁面會卡頓。如下圖 原因 runloop在一次渲染中,需要渲染十幾張高清大圖,所以卡主了 解決思路 每次Runloop迴圈,只渲染一張大圖!! 1.
Android_效能優化之ViewPager載入成百上千高清大圖oom解決方案
歡迎加入技術談論群:714476794一、背景最近做專案需要用到選擇圖片上傳,類似於微信、微博那樣的圖片選擇器,ContentResolver讀取本地圖片資源並用RecyclerView+Glide載入圖片顯示就搞定列表的顯示,這個沒什麼大問題,重點是,點選圖片進入大圖瀏覽,
載入高清大圖長圖
Android 高清載入巨圖方案 拒絕壓縮圖片 一、概述 距離上一篇部落格有段時間沒更新了,主要是最近有些私事導致的,那麼就先來一篇簡單一點的部落格脈動回來。 對於載入圖片,大家都不陌生,一般為了儘可能避免OOM都會按照如下做法: 對於圖片顯示:根據需要顯示圖片控
IOS多個UIImageView載入高清大圖時記憶體管理
當我們在某一個View 多個UIImageView,且UIImageView都顯示的是高清大圖,就有可能出現記憶體警告的問題。如果第一次進入這個view,沒有發生記憶體警告,當再次進入這個view,如果上一次的記憶體沒有及時釋放,這一次次的累加,便可導致記憶體崩潰。
windows系統平臺下的PE檔案格式和資料定義詳解(附帶詳細高清大圖)
PE(Portable Executable)格式,是微軟Win32環境可移植可執行檔案(如exe、dll、vxd、sys和vdm等)的標準檔案格式。 PE格式衍生於早期建立在VAX(R)VMS(R)上的COFF(Common Object File Format)檔案格式
爬蟲高玩教你用Python每秒鐘下載一張高清大圖,快不快?
on() print async tpc 多說 xxx ima 所有 mkdir 如果爬蟲需要展現速度,我覺得就是去下載圖片吧,原本是想選擇去煎蛋那裏下載圖片的,那裏的美女圖片都是高質量的,我稿子都是差不多寫好了的,無奈今天重新看下,妹子圖的入口給關了。 至於
一步步分析百度音樂的播放地址,利用Python爬蟲批量下載
百度音樂不需要登入也可以下載?聽到這個訊息是不是很興奮呢, 接下來我們開啟百度音樂,隨便開啟一首歌,切換到百度播放頁面:如圖 我這裡用的是Firfox 瀏覽器,開啟firebug 先清空所有的請求,如圖: 現在我們重新重新整理下頁面,看到這個.mp3的地址就是百度音樂的
利用Python爬蟲批量下載網易雲音樂歌單歌曲
from tkinter import * import requests from bs4 import BeautifulSoup from urllib.request import urlretrieve def download(): url = ent
Python實現簡單爬蟲功能--批量下載百度貼吧裡的圖片
在上網瀏覽網頁的時候,經常會看到一些好看的圖片,我們就希望把這些圖片儲存下載,或者使用者用來做桌面桌布,或者用來做設計的素材。 我們最常規的做法就是通過滑鼠右鍵,選擇另存為。但有些圖片滑鼠右鍵的時候並沒有另存為選項,還有辦法就通過就是通過截圖工具擷取下來,但這樣就降低圖片的清晰度
[Python] [爬蟲] 5.批量政府網站的招投標、中標資訊爬取和推送的自動化爬蟲——網頁下載器
目錄 1.Intro 2.Source 1.Intro 檔名:pageDownloader.py 模組名:網頁下載器 引用庫: selenium random sys socket tim
深度學習入門:基於Python的理論與實現 高清中文版PDF電子版下載附原始碼
本書特色1.日本深度學習入門經典暢銷書,原版上市不足2年印刷已達100 000冊。長期位列日亞“人工智慧”類圖書榜首,超多五星好評。2.使用Python 3,儘量不依賴外部庫或工具,從零建立一個深度學習模型。3.示例程式碼清晰,原始碼可下載,需要的執行環境非常簡單。讀者可以一邊讀書一邊執行程式,簡單易上手。4