
【CV現狀-3.3】特徵提取與描述
#磨染的初心——計算機視覺的現狀
【這一系列文章是關於計算機視覺的反思,希望能引起一些人的共鳴。可以隨意傳播,隨意噴。所涉及的內容過多,將按如下內容劃分章節。已經完成的會逐漸加上鍊接。】
- 緣起
- 三維感知
- 目標識別
3.0. 目標是什麼
3.1. 影象分割
3.2. 紋理與材質
3.3. 特徵提取與分類 - 目標(和自身)在三維空間中的位置關係
- 目標的三維形狀及其改變、目標的位移
- 符號識別
- 數字影象處理
特徵提取與分類
一定是因為紋理分析與描述以及影象分割沒有取得有效的進展,導致通過材質、形狀、結構進行目標識別的願望落了空。甚至當前最優秀的影象分割演算法都不能產生人類能夠識別的圖斑形狀,此外形狀和結構描述方面也沒有取得多少成果,更遑論有價值的成果。但是機器學習卻取得了長足的進步,各種各樣適合不同分佈模型的監督分類演算法被髮明瞭出來。目標識別也就順其自然地走上了“提取特徵+描述特徵+監督分類”的路線,成就也是顯而易見的,當前落地了的計算機視覺應用背後都得到了“特徵提取與描述”以及分類的加持。隨著卷積神經網路的出現,人工特徵提取與描述都省了,計算機視覺已然有了被機器學習收歸囊下的意思。
然而相對於紙面上的喧囂,卷積神經網路並沒有開拓出實打實的應用領域。在深度學習成為熱詞之前,計算機視覺已經滿足了人臉識別、指紋識別、行人檢測、車輛檢測、質檢、工業控制等場景的應用需求。深度學習火熱之後應用場景沒有增加,需求的滿足水平也沒有本質的提升,唯一改變的是社會對計算機視覺的接受程度——這些應用場景的市場規模被拓展了。
不知道應該用“十字路口”還是應該用“瓶頸”來形容這個現狀,不管怎麼樣,回顧、總結終歸是有用的。就在此回顧、總結一下驅動計算機視覺發展到目前的引擎——“特徵提取與描述”——吧。歸納起來目前能夠提取的特徵有點、線、斑塊三類。點特徵在影象配準、影象幾何校正、影象鑲嵌、多視幾何恢復任務中起到了至關重要的作用。對於線特徵,由於缺乏有效的描述方法以及連線成閉合圖形的方法,目前還沒有什麼廣泛的用處。斑塊特徵是筆者的歸納,也許難以理解,該類特徵直接和間接表示了圖斑之間的位置關係或者圖斑的幾何結構以及圖斑的紋理。比如HAAR和DPM就是斑塊類特徵,HAAR檢測器中兩個區域均值相減的操作就是為了在斑塊邊界上取得足夠的響應;從DPM這個名稱中就可發現其目的是為了對部件(斑塊)的組合有足夠的響應,DPM的基礎——梯度直方圖(HoG)——一定程度上反應了圖斑的紋理。
目前點特徵提取演算法的核心思路有三種,其代表演算法分別是Harris、FAST、SUSAN。Harris演算法所基於的現象是——角點處更多方向上的梯度將會取得較大值,在判別的時候採用了DoH(Determinant of Hessian),採用此思路的角點檢測演算法有SIFT、SURF、KAZE。FAST演算法所基於的現象是——以角點為中心的圓環上有更長連續畫素點的取值與中心點的取值差異較大,最直接的判別依據為圓環上與中心點取值不同的連續畫素點的數目,具體實現時採用了不同的優化手段,採用此思路的角點檢測演算法有AGAST、BRISK、ORB、FREAK。SUSAN演算法所基於的現象是——以角點為中心的中心對稱區域中與角點取值相同的畫素最少,判別依據為與角點取值相同的畫素數量。有些演算法在採用這些思想時會進行近似計算、縮減計算規模等操作,看起來像是脫離了這三種思路,尤其是SIFT和SURF,他們分別採用LoG和Haar小波來近似梯度的計算。另外在多個尺度上應用具體的角點檢測方法是很自然的事情,雖然建立尺度集的具體方法不一定是容易想到的。
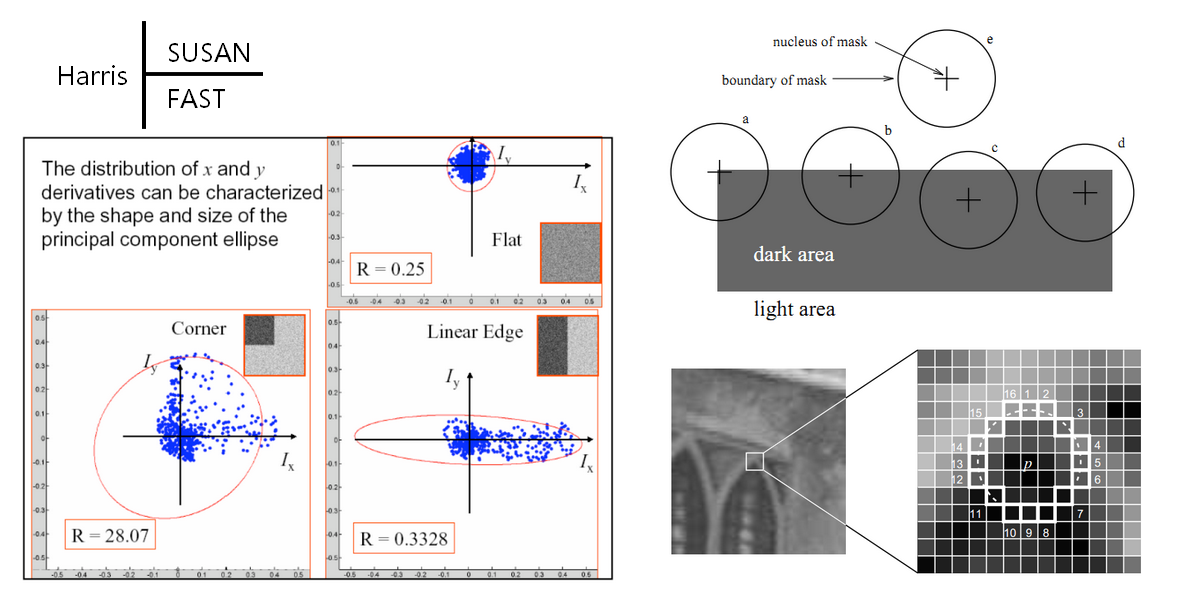
要在影象配準、影象幾何校正、影象鑲嵌、多視幾何恢復等任務中應用點特徵,必須匹配相同或相似的點。因此需要基於某種測度方法對特徵的內涵進行量化,這就叫做特徵的描述。常用的點特徵描述方法有BRIEF、ORB(Steered BRIEF)、BRISK、SIFT、SURF等。其中BRIEF、ORB(Steered BRIEF)、BRISK描述方法在特徵點周圍採用一定的方式採集一些點對,然後針對具體的特徵點使用二值方式編碼點對間像元值的差異,量化的結果是二值串,一般採用漢明距離比較相似程度;當然具體的點對採集方式和點對像元值差異編碼方式各不相同。SIFT、SURF描述方法對特徵點周圍的梯度按照方向進行統計形成了梯度直方圖(HoG),量化結果是多維向量,在比較相似度時是當作空間座標進行處理的。這些點特徵描述方法不是隻能用於描述提取出來的特徵點,還可以對影象上任意畫素的區域性特徵進行描述。還有其他一些區域性特徵描述方法,用來描述特徵點時全域性區分度不夠,一般用在三維重建的密集匹配過程中。
影象中明顯的線特徵就是邊緣和細線狀要素,都可以通過邊緣檢測演算法提取出來。梯度運算元對邊緣有很高的響應,因此梯度運算元也會叫做邊緣檢測運算元,然而用梯度運算元對影象做卷積絕對不能稱作邊緣檢測,這是流傳甚廣的錯誤。即使不要求獲得邊緣點組成的座標串,邊緣檢測演算法也應該獲得去除了非邊緣點的影象而不是邊緣被顯示增強的影象。符合這個要求的邊緣檢測演算法有兩種——Marr-Hildreth和Canny。Canny演算法提取出來的邊緣點是一階梯度的區域性極大值點,Marr-Hildreth演算法提取出來的是二階梯度的過零點。Canny演算法的效果雖然明顯優於Marr-Hildreth,但是也有自身的缺點——強弱邊緣梯度的閾值難以確定。在影象中提取出不封閉的特徵線,好像實在沒有太大的用處,甚至Canny演算法的提取效果已經遠遠超過當前的應用需要了。如果說要提取出封閉的特徵線,那就是影象分割的任務了;另外如果觀察過很多影象,肯定會同意影象上很多線要素都不是封閉的。關於線提取還有另外一種方法,就是先二值化再應用骨架提取演算法;這種方法應用在成像環境和成像物件高度受控的場景,如指紋識別、工業質檢等。影象上的直線和圓弧是高度特殊的一類特徵線,線上特徵提取演算法的基礎上再將這些可以簡單引數化表示的線提取出來的演算法叫霍夫變換(Hough Transform),在車道線檢測、機場跑道識別等任務上有一定的用處。
當然最近也有不少基於深度學習的點、線提取演算法被提了出來,就筆者而言,這不過是“茴”字的另外幾種寫法而已。因為從一定程度上來說,點、線特徵提取是已經解決了的問題,如果智商有餘額應當去定義和解決真正的問題。
斑塊特徵的作用在於目標檢測(目標識別、影象分類),這也是卷積神經網路發揮巨大作用的領域。對於圖斑來說,不像點、線一樣,要將其提取出來;而是採用逆向思維,直接設計一種適合具體任務的描述圖斑所蘊含特徵的方法。比如,利用Haar特徵進行人臉檢測時,設計幾個Haar-like filter(box filter)採用如下圖的佈局進行組合,在影象上滑動的時候每個Haar-like filter在其所處的位置上計算出一個值,多個Haar-like filter的計算結果形成特徵向量。利用監督分類演算法訓練出針對此特徵向量的分類器,用於判別滑動視窗之下是否是人臉。
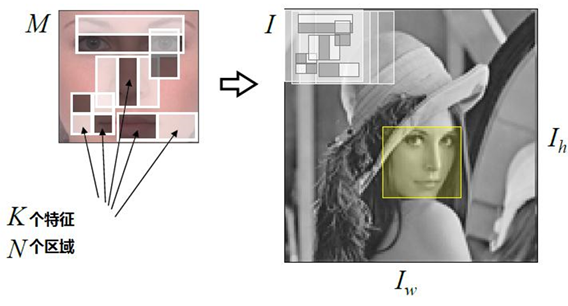
至於DPM,思路是類似的,採用HoG方法計算出視窗內的特徵向量,然後訓練一個打分器,視窗內如果是要檢測的目標得分就越高。當然DPM採用了一個根打分器和多個部件打分器,結合部件偏移損失將部件得分和根得分綜合到一起作為最終得分,如果最終得分高於閾值就認為根視窗和部件視窗的組合區域中是要檢測的目標。
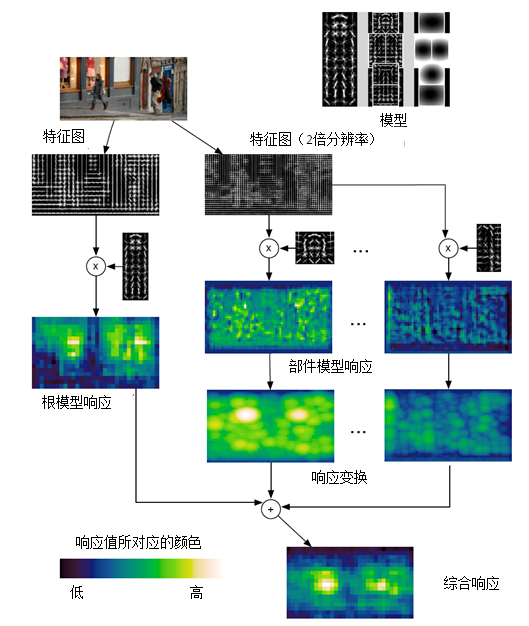
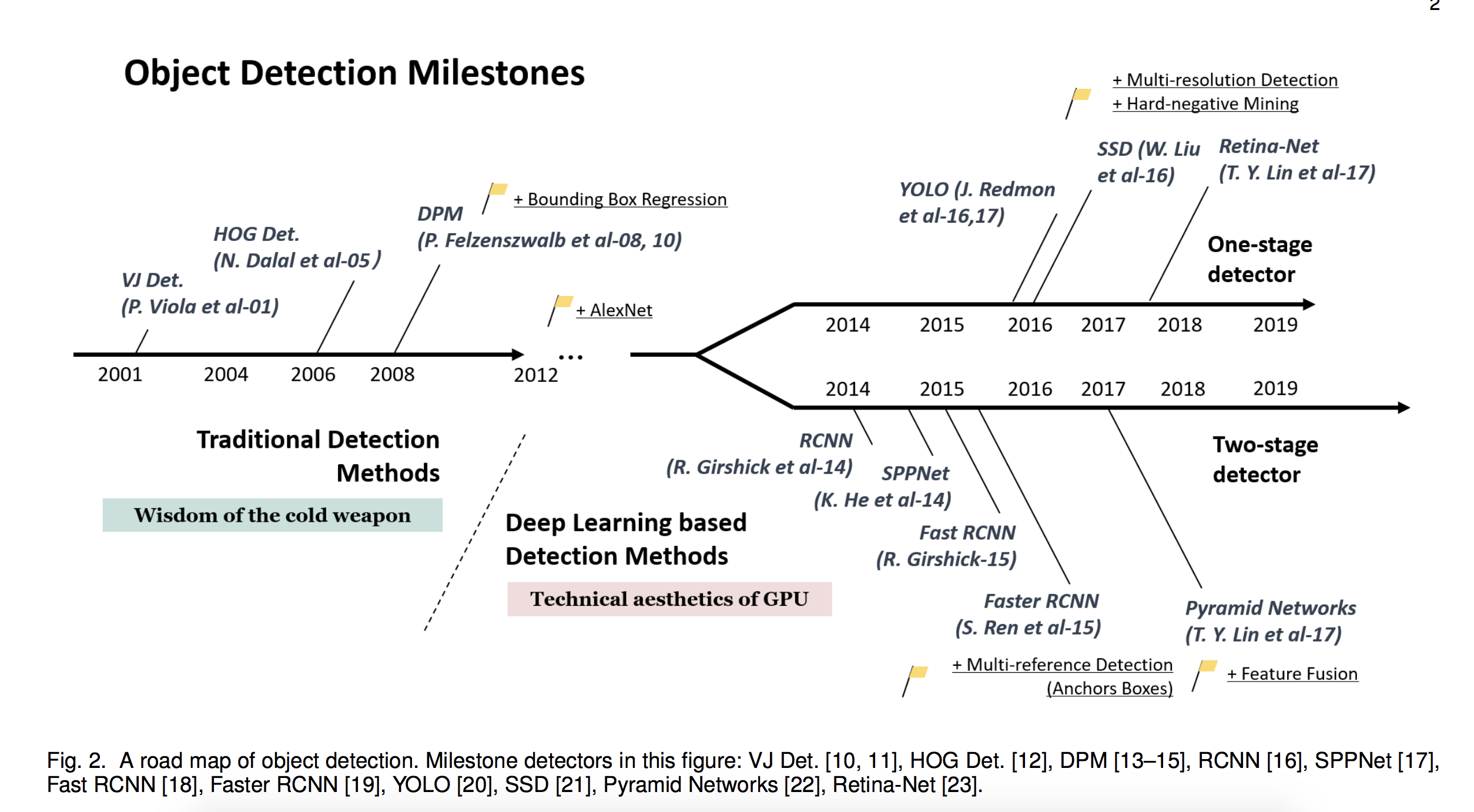
就筆者所知,適用於目標檢測的人工特徵描述方法就只有Haar和HoG了,之後舞臺就交給了CNN。不可否認CNN使目標檢測的效果得到了跨越式提升,很多優秀的結構被提了出來,也解決了很多實質問題,如殘差網路、錨點框、One-Stage、FPN、FocusLoss等。
然而CNN並非沒有缺陷,除了截至目前還無法解決的遷移和泛化問題之外,CNN的正方形感受野使其在識別狹長形目標時顯得力不從心,如果狹長形目標是緊挨在一起的形勢就更加嚴峻了。這種情況在航空影像和衛星影像上尤為常見,如下圖所示,狹長的大汽車是較難識別的目標,港口的輪船是更難識別的目標。飛機靠氣動外形才能飛,樣式都是一樣的;船體不管什麼樣的只要排水量超過自重就能漂起來航行,在衛星影像上幾乎沒有兩艘船是一樣的。航空影像和衛星影像上最容易識別的就是飛機,接下來是體育場,他們都佔據方方正正的空間,外觀也比較單一。這也是很多機構只公開飛機和體育場檢測效果的原因。


相關推薦
【CV現狀-3.3】特徵提取與描述
#磨染的初心——計算機視覺的現狀 【這一系列文章是關於計算機視覺的反思,希望能引起一些人的共鳴。可以隨意傳播,隨意噴。所涉及的內容過多,將按如下內容劃分章節。已經完成的會逐漸加上鍊接。】 緣起 三維感知 目標識別 3.0. 目標是什麼 3.1. 影象分割 3.2. 紋理與材質 3.3. 特徵提取與分類 目標
《python+opencv實踐》四、影象特徵提取與描述——30Harris 角點檢測
目標• 理解Harris 角點檢測的概念 • 學習函式:cv2.cornerHarris(),cv2.cornerSubPix() 原理 在上一節我們已經知道了角點的一個特性:向任何方向移動變化都很大。Chris_Harris 和Mike_Stephens 早在1988 年
python opencv-3.0 SIFT/SURF 特徵提取與匹配
一、環境準備 目前 Opencv 有2.x 和 3.x 版本,兩個版本之間的差異主要是一些功能函式被放置到了不同的功能模組,因此大多數情況兩個版本的程式碼並不能通用。建議安裝 Anaconda,自行
【Mark Schmidt課件】機器學習與資料探勘——特徵選擇
本課件的主要內容如下: 上次課程回顧:尋找“真實”模型 資訊準則 貝葉斯資訊準則 關於食物過敏 特徵選擇 全基因組關聯分析 “迴歸權重”方法 搜尋評分法 評分函式的選擇 “特徵數量”懲罰
【經典數據結構】B樹與B+樹(轉)
linux 每分鐘 www 數據 csapp png 感知 轉動 繼續 本文轉載自:http://www.cnblogs.com/yangecnu/p/Introduce-B-Tree-and-B-Plus-Tree.html 維基百科對B樹的定義為“在計算機科學中,B
【編程工具配置】Pycharm安裝與修改中文界面教程
激活 load com down col section 復制 工具配置 鏈接 【windows】 1.到官網下載Pycharm最新版 https://www.jetbrains.com/pycharm/download/#section=windows 2
Python之路【第十九篇】:sys與os模塊
改變 python 隱藏 post 系統 rmdir 最大的 mman 就是 與解釋器相關的一些操作在sys模塊中,與系統相關的一些操作在os模塊中 sys模塊 sys.argv 命令行參數List,第一個元素是程序本身路徑 sys.exit(n)
【經典數據結構】B樹與B+樹
觸發 每分鐘 存儲結構 內容 修改 lar 命中率 system gif 本文轉載自:http://www.cnblogs.com/yangecnu/p/Introduce-B-Tree-and-B-Plus-Tree.html 維基百科對B樹的定義為“在計算機科學中,
【Mark Schmidt課件】機器學習與資料探勘——非線性迴歸
本課件主要內容包括: 魯棒迴歸 體育運動中的非線性級數 自適應計數/距離法 線性模型的侷限性 非線性特徵變換 一般多項式特徵(d = 1) 英文原文課件下載地址: http://page5.dfpan
【Mark Schmidt課件】機器學習與資料探勘——數值優化與梯度下降
本課件主要包括以下內容: 優化簡介 上次課程回顧:線性迴歸 大規模最小二乘 尋找區域性最小值的梯度下降法 二維梯度下降 存在奇異點的最小二乘 魯棒迴歸 基於L1-範數的迴歸 L1-範數的平滑近似
【Mark Schmidt課件】機器學習與資料探勘——正規方程組
本課件的主要內容包括: d維資料的梯度和臨界點 最小二乘偏導數 矩陣代數回顧 線性最小二乘 線性和二次梯度 正規方程組 最小二乘問題的不正確解 最小二乘解的非唯一性 凸函式 如何判斷函式的
【Mark Schmidt課件】機器學習與資料探勘——普通最小二乘
本課件主要內容包括: 有監督學習:迴歸 示例:依賴與解釋變數 數字標籤的處理 一維線性迴歸 最小二乘目標 微分函式最小化 最小二乘解 二維最小二乘 d維最小二乘 偏微分
【Mark Schmidt課件】機器學習與資料探勘——進一步討論線性分類器
本課件主要內容包括: 上次課程回顧:基於迴歸的分類方法 Hinge損失 Logistic損失 Logistic迴歸與SVMs “黑盒”分類器比較 最大餘量分類器 支援向量機 魯棒性與凸近似 非凸0-
【Mark Schmidt課件】機器學習與資料探勘——線性分類器
本課件主要內容包括: 上次課程回顧:L1正則化 組合特徵選擇 線性模型與最小二乘 梯度下降與誤差函式 正則化 辨識重要郵件 基於迴歸的二元分類? 一維判決邊界 二維判決邊界 感知器演算法
【Mark Schmidt課件】機器學習與資料探勘——多元分類
本課件主要內容: 上次課程回顧:隨機梯度 無限資料的隨機梯度 詞性標註POS POS特徵 多元線性分類 題外話:多標籤分類 多元SVMs 多元Logistic迴歸 題外話:Frobenius範數
【Mark Schmidt課件】機器學習與資料探勘——MLE與MAP
本課件的主要內容包括: 上次課程回顧:多元線性分類器 決策邊界形狀 識別重要電子郵件 Sigmoid函式 最大似然估計MLE 最小化負對數似然NLL 樸素貝葉斯的MLE 有監督學習的MLE Logi
特徵提取與檢測(二) --- SIFT演算法
SIFT(Scale-invariant feature transform)是一種檢測區域性特徵的演算法,該演算法通過求一幅圖中的特徵點(interest points,or corner points)及其有關scale 和 orien
【Mark Schmidt課件】機器學習與資料探勘——主元分析PCA
本課件主要內容包括: 上次課程回顧:MAP估計 人類 vs. 機器感知 隱因子模型 向量量化 向量量化 vs. PCA 主元分析PCA的應用 PCA目標函式 英文原文課件下載地址: h
【Mark Schmidt課件】機器學習與資料探勘——進一步討論PCA
本課件的主要內容包括: 機器學習工程師需要精通的10種演算法 上次課程回顧:隱因子模型 上次課程回顧:主元分析 上次課程回顧:PCA幾何描述 題外話:資料凝聚 PCA計算:交替最小化 PCA計算:預測 PCA
【Mark Schmidt課件】機器學習與資料探勘——稀疏矩陣分解
本課件主要內容包括: 上次課程回顧:基於正交/序貫基的PCA 人眼的顏色對立 顏色對立表示法 應用:人臉檢測 特徵臉 VQ vs. PCA vs. NMF 面部表示 非負最小二乘法 稀疏性與非負最小