
用go語言爬取珍愛網 | 第三回
前兩節我們獲取到了城市的URL和城市名,今天我們來解析使用者資訊。
用go語言爬取珍愛網 | 第一回
用go語言爬取珍愛網 | 第二回

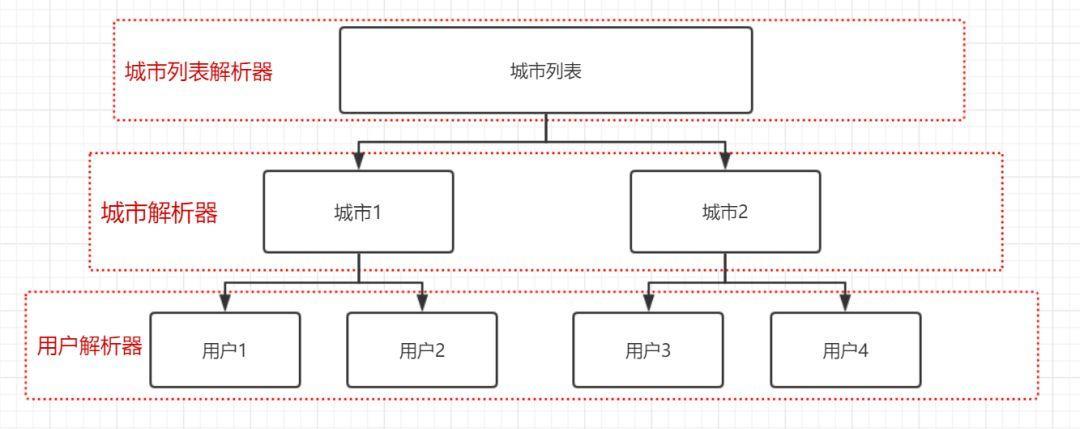
爬蟲的演算法:
我們要提取返回體中的城市列表,需要用到城市列表解析器;
需要把每個城市裡的所有使用者解析出來,需要用到城市解析器;
還需要把每個使用者的個人資訊解析出來,需要用到使用者解析器。
爬蟲整體架構:
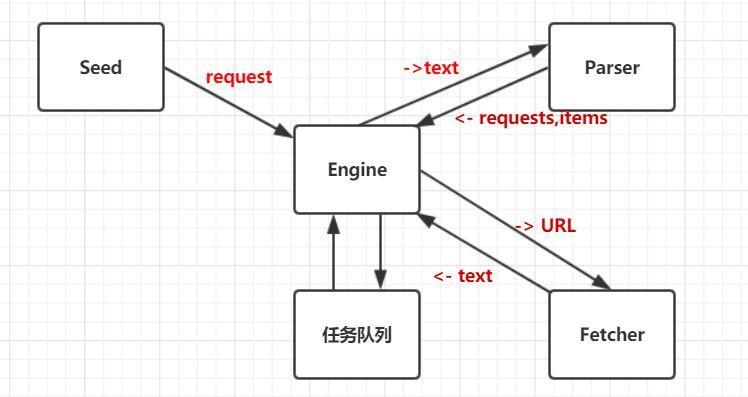
Seed把需要爬的request送到engine,engine負責將request裡的url送到fetcher去爬取資料,返回utf-8的資訊,然後engine將返回資訊送到解析器Parser裡解析有用資訊,返回更多待請求requests和有用資訊items,任務佇列用於儲存待請求的request,engine驅動各模組處理資料,直到任務佇列為空。
程式碼實現:
按照上面的思路,設計出城市列表解析器citylist.go程式碼如下:
package parser import ( "crawler/engine" "regexp" "log" ) const ( //<a href="http://album.zhenai.com/u/1361133512" target="_blank">怎麼會迷上你</a> cityReg = `<a href="(http://album.zhenai.com/u/[0-9]+)"[^>]*>([^<]+)</a>` ) func ParseCity(contents []byte) engine.ParserResult { compile := regexp.MustCompile(cityReg) submatch := compile.FindAllSubmatch(contents, -1) //這裡要把解析到的每個URL都生成一個新的request result := engine.ParserResult{} for _, m := range submatch { name := string(m[2]) log.Printf("UserName:%s URL:%s\n", string(m[2]), string(m[1])) //把使用者資訊人名加到item裡 result.Items = append(result.Items, name) result.Requests = append(result.Requests, engine.Request{ //使用者資訊對應的URL,用於之後的使用者資訊爬取 Url : string(m[1]), //這個parser是對城市下面的使用者的parse ParserFunc : func(bytes []byte) engine.ParserResult { //這裡使用閉包的方式;這裡不能用m[2],否則所有for迴圈裡的使用者都會共用一個名字 //需要拷貝m[2] ---- name := string(m[2]) return ParseProfile(bytes, name) }, }) } return result }
城市解析器city.go如下:
package parser import ( "crawler/engine" "regexp" "log" ) const ( //<a href="http://album.zhenai.com/u/1361133512" target="_blank">怎麼會迷上你</a> cityReg = `<a href="(http://album.zhenai.com/u/[0-9]+)"[^>]*>([^<]+)</a>` ) func ParseCity(contents []byte) engine.ParserResult { compile := regexp.MustCompile(cityReg) submatch := compile.FindAllSubmatch(contents, -1) //這裡要把解析到的每個URL都生成一個新的request result := engine.ParserResult{} for _, m := range submatch { name := string(m[2]) log.Printf("UserName:%s URL:%s\n", string(m[2]), string(m[1])) //把使用者資訊人名加到item裡 result.Items = append(result.Items, name) result.Requests = append(result.Requests, engine.Request{ //使用者資訊對應的URL,用於之後的使用者資訊爬取 Url : string(m[1]), //這個parser是對城市下面的使用者的parse ParserFunc : func(bytes []byte) engine.ParserResult { //這裡使用閉包的方式;這裡不能用m[2],否則所有for迴圈裡的使用者都會共用一個名字 //需要拷貝m[2] ---- name := string(m[2]) return ParseProfile(bytes, name) }, }) } return result }
使用者解析器profile.go如下:
package parser
import (
"crawler/engine"
"crawler/model"
"regexp"
"strconv"
)
var (
// <td><span class="label">年齡:</span>25歲</td>
ageReg = regexp.MustCompile(`<td><span class="label">年齡:</span>([\d]+)歲</td>`)
// <td><span class="label">身高:</span>182CM</td>
heightReg = regexp.MustCompile(`<td><span class="label">身高:</span>(.+)CM</td>`)
// <td><span class="label">月收入:</span>5001-8000元</td>
incomeReg = regexp.MustCompile(`<td><span class="label">月收入:</span>([0-9-]+)元</td>`)
//<td><span class="label">婚況:</span>未婚</td>
marriageReg = regexp.MustCompile(`<td><span class="label">婚況:</span>(.+)</td>`)
//<td><span class="label">學歷:</span>大學本科</td>
educationReg = regexp.MustCompile(`<td><span class="label">學歷:</span>(.+)</td>`)
//<td><span class="label">工作地:</span>安徽蚌埠</td>
workLocationReg = regexp.MustCompile(`<td><span class="label">工作地:</span>(.+)</td>`)
// <td><span class="label">職業: </span>--</td>
occupationReg = regexp.MustCompile(`<td><span class="label">職業: </span><span field="">(.+)</span></td>`)
// <td><span class="label">星座:</span>射手座</td>
xinzuoReg = regexp.MustCompile(`<td><span class="label">星座:</span><span field="">(.+)</span></td>`)
//<td><span class="label">籍貫:</span>安徽蚌埠</td>
hokouReg = regexp.MustCompile(`<td><span class="label">民族:</span><span field="">(.+)</span></td>`)
// <td><span class="label">住房條件:</span><span field="">--</span></td>
houseReg = regexp.MustCompile(`<td><span class="label">住房條件:</span><span field="">(.+)</span></td>`)
// <td width="150"><span class="grayL">性別:</span>男</td>
genderReg = regexp.MustCompile(`<td width="150"><span class="grayL">性別:</span>(.+)</td>`)
// <td><span class="label">體重:</span><span field="">67KG</span></td>
weightReg = regexp.MustCompile(`<td><span class="label">體重:</span><span field="">(.+)KG</span></td>`)
//<h1 class="ceiling-name ib fl fs24 lh32 blue">怎麼會迷上你</h1>
//nameReg = regexp.MustCompile(`<h1 class="ceiling-name ib fl fs24 lh32 blue">([^\d]+)</h1> `)
//<td><span class="label">是否購車:</span><span field="">未購車</span></td>
carReg = regexp.MustCompile(`<td><span class="label">是否購車:</span><span field="">(.+)</span></td>`)
)
func ParseProfile(contents []byte, name string) engine.ParserResult {
profile := model.Profile{}
age, err := strconv.Atoi(extractString(contents, ageReg))
if err != nil {
profile.Age = 0
}else {
profile.Age = age
}
height, err := strconv.Atoi(extractString(contents, heightReg))
if err != nil {
profile.Height = 0
}else {
profile.Height = height
}
weight, err := strconv.Atoi(extractString(contents, weightReg))
if err != nil {
profile.Weight = 0
}else {
profile.Weight = weight
}
profile.Income = extractString(contents, incomeReg)
profile.Car = extractString(contents, carReg)
profile.Education = extractString(contents, educationReg)
profile.Gender = extractString(contents, genderReg)
profile.Hokou = extractString(contents, hokouReg)
profile.Income = extractString(contents, incomeReg)
profile.Marriage = extractString(contents, marriageReg)
profile.Name = name
profile.Occupation = extractString(contents, occupationReg)
profile.WorkLocation = extractString(contents, workLocationReg)
profile.Xinzuo = extractString(contents, xinzuoReg)
result := engine.ParserResult{
Items: []interface{}{profile},
}
return result
}
//get value by reg from contents
func extractString(contents []byte, re *regexp.Regexp) string {
m := re.FindSubmatch(contents)
if len(m) > 0 {
return string(m[1])
} else {
return ""
}
}engine程式碼如下:
package engine
import (
"crawler/fetcher"
"log"
)
func Run(seeds ...Request){
//這裡維持一個佇列
var requestsQueue []Request
requestsQueue = append(requestsQueue, seeds...)
for len(requestsQueue) > 0 {
//取第一個
r := requestsQueue[0]
//只保留沒處理的request
requestsQueue = requestsQueue[1:]
log.Printf("fetching url:%s\n", r.Url)
//爬取資料
body, err := fetcher.Fetch(r.Url)
if err != nil {
log.Printf("fetch url: %s; err: %v\n", r.Url, err)
//發生錯誤繼續爬取下一個url
continue
}
//解析爬取到的結果
result := r.ParserFunc(body)
//把爬取結果裡的request繼續加到request佇列
requestsQueue = append(requestsQueue, result.Requests...)
//列印每個結果裡的item,即列印城市名、城市下的人名...
for _, item := range result.Items {
log.Printf("get item is %v\n", item)
}
}
}Fetcher用於發起http get請求,這裡有一點注意的是:珍愛網可能做了反爬蟲限制手段,所以直接用http.Get(url)方式發請求,會報403拒絕訪問;故需要模擬瀏覽器方式:
client := &http.Client{}
req, err := http.NewRequest("GET", url, nil)
if err != nil {
log.Fatalln("NewRequest is err ", err)
return nil, fmt.Errorf("NewRequest is err %v\n", err)
}
req.Header.Set("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36")
//返送請求獲取返回結果
resp, err := client.Do(req)最終fetcher程式碼如下:
package fetcher
import (
"bufio"
"fmt"
"golang.org/x/net/html/charset"
"golang.org/x/text/encoding"
"golang.org/x/text/encoding/unicode"
"golang.org/x/text/transform"
"io/ioutil"
"log"
"net/http"
)
/**
爬取網路資源函式
*/
func Fetch(url string) ([]byte, error) {
client := &http.Client{}
req, err := http.NewRequest("GET", url, nil)
if err != nil {
log.Fatalln("NewRequest is err ", err)
return nil, fmt.Errorf("NewRequest is err %v\n", err)
}
req.Header.Set("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36")
//返送請求獲取返回結果
resp, err := client.Do(req)
//直接用http.Get(url)進行獲取資訊,爬取時可能返回403,禁止訪問
//resp, err := http.Get(url)
if err != nil {
return nil, fmt.Errorf("Error: http Get, err is %v\n", err)
}
//關閉response body
defer resp.Body.Close()
if resp.StatusCode != http.StatusOK {
return nil, fmt.Errorf("Error: StatusCode is %d\n", resp.StatusCode)
}
//utf8Reader := transform.NewReader(resp.Body, simplifiedchinese.GBK.NewDecoder())
bodyReader := bufio.NewReader(resp.Body)
utf8Reader := transform.NewReader(bodyReader, determineEncoding(bodyReader).NewDecoder())
return ioutil.ReadAll(utf8Reader)
}
/**
確認編碼格式
*/
func determineEncoding(r *bufio.Reader) encoding.Encoding {
//這裡的r讀取完得保證resp.Body還可讀
body, err := r.Peek(1024)
//如果解析編碼型別時遇到錯誤,返回UTF-8
if err != nil {
log.Printf("determineEncoding error is %v", err)
return unicode.UTF8
}
//這裡簡化,不取是否確認
e, _, _ := charset.DetermineEncoding(body, "")
return e
}main方法如下:
package main
import (
"crawler/engine"
"crawler/zhenai/parser"
)
func main() {
request := engine.Request{
Url: "http://www.zhenai.com/zhenghun",
ParserFunc: parser.ParseCityList,
}
engine.Run(request)
}最終爬取到的使用者資訊如下,包括暱稱、年齡、身高、體重、工資、婚姻狀況等。
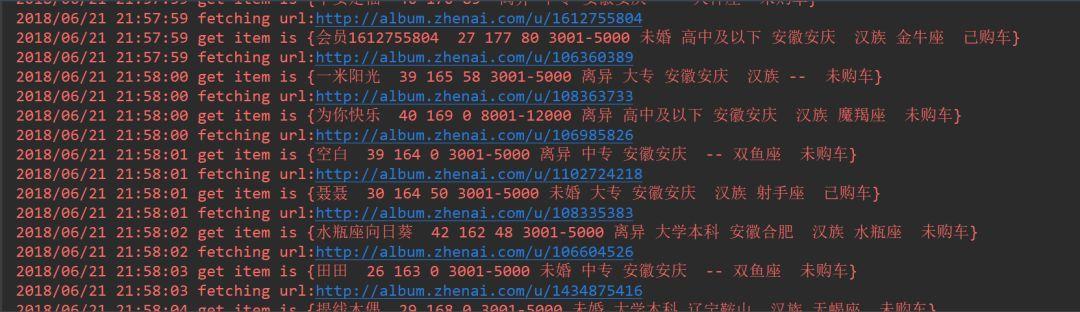
如果你想要哪個妹子的照片,可以點開url檢視,然後打招呼進一步發展。
至此單任務版的爬蟲就做完了,後面我們將對單任務版爬蟲做效能分析,然後升級為多工併發版,把爬取到的資訊存到ElasticSearch中,在頁面上查詢
本公眾號免費提供csdn下載服務,海量IT學習資源,如果你準備入IT坑,勵志成為優秀的程式猿,那麼這些資源很適合你,包括但不限於java、go、python、springcloud、elk、嵌入式 、大資料、面試資料、前端 等資源。同時我們組建了一個技術交流群,裡面有很多大佬,會不定時分享技術文章,如果你想來一起學習提高,可以公眾號後臺回覆【2】,免費邀請加技術交流群互相學習提高,會不定期分享程式設計IT相關資源。
掃碼關注,精彩內容第一時間推給你

本公眾號免費提供csdn下載服務,海量IT學習資源,如果你準備入IT坑,勵志成為優秀的程式猿,那麼這些資源很適合你,包括但不限於java、go、python、springcloud、elk、嵌入式 、大資料、面試資料、前端 等資源。同時我們組建了一個技術交流群,裡面有很多大佬,會不定時分享技術文章,如果你想來一起學習提高,可以公眾號後臺回覆【2】,免費邀請加技術交流群互相學習提高,會不定期分享程式設計IT相關資源。
掃碼關注,精彩內容第一時間推給你

相關推薦
用go語言爬取珍愛網 | 第三回
前兩節我們獲取到了城市的URL和城市名,今天我們來解析使用者資訊。 用go語言爬取珍愛網 | 第一回 用go語言爬取珍愛網 | 第二回 爬蟲的演算法: 我們要提取返回體中的城市列表,需要用到城市列表解析器; 需要把每個城市裡的所有使用者解析出來,需要用到城市解析器; 還需要把每個使用者的個人資訊解析出來,
用go語言爬取珍愛網 | 第一回
我們來用go語言爬取“珍愛網”使用者資訊。 首先分析到請求url為: http://www.zhenai.com/zhenghun 接下來用go請求該url,程式碼如下: package main import ( "fmt" "io/ioutil" &
用go語言爬取珍愛網 | 第二回
昨天我們一起爬取珍愛網首頁,拿到了城市列表頁面,接下來在返回體城市列表中提取城市和url,即下圖中的a標籤裡的href的值和innerText值。 提取a標籤,可以通過CSS選擇器來選擇,如下: $('#cityList>dd>a');就可以獲取到470個a標籤: 這裡只提供一個思
爬取珍愛網後用戶資訊展示
golang爬取珍愛網,爬到了3萬多使用者資訊,並存到了elasticsearch中,如下圖,查詢到了3萬多使用者資訊。 先來看看最終效果: 利用到了go語言的html模板庫: 執行模板渲染: func (s SearchResultView) Render (w io.Writer, data mo
go語言爬取椎名真白
regexp highlight defer reg write rul png span link 單任務版: package main import ( "net/http" "regexp" "io/ioutil" "os" "strconv" "ti
go 語言爬取百度貼吧中的內容
涉及到的知識點有 通道chan ,切片的使用 ,os,http 包的使用 package main import ( "fmt" "net/http" "os" "strconv" ) func pachong(start, end int) { //明確爬的地址 url :=
【go語言爬蟲】go語言爬取豆瓣電影top250
抓取欄位:電影名稱、評分、評價人數 二、執行: 正在抓取第0頁…… 肖申克的救贖 9.6 824764人 這個殺手不太冷 9.4 791399人 霸王別姬 9.5 589028人 阿甘正傳 9.4 678850人 美麗人生 9.5 3940
用crawl spider爬取起點網小說信息
models anti arc pub work 全部 see 效率 rand 起點作為主流的小說網站,在防止數據采集反面還是做了準備的,其對主要的數字采用了自定義的編碼映射取值,想直接通過頁面來實現數據的獲取,是無法實現的。 單獨獲取數字還是可以實現的,通過reques
用Python爬蟲爬取廣州大學教務系統的成績(內網訪問)
enc 用途 css選擇器 狀態 csv文件 表格 area 加密 重要 用Python爬蟲爬取廣州大學教務系統的成績(內網訪問) 在進行爬取前,首先要了解: 1、什麽是CSS選擇器? 每一條css樣式定義由兩部分組成,形式如下: [code] 選擇器{樣式} [/code
python之爬蟲的入門05------實戰:爬取貝殼網(用re匹配需要的資料)
# 第二頁:https://hz.zu.ke.com/zufang/pg2 # 第一頁:https://hz.zu.ke.com/zufang/pg1 import urllib.request import random import re def user_ip(): ''
R語言爬取前程無憂網招聘職位
資料的獲取是資料探勘的第一步,如果沒有資料何談資料探勘?有時候在做演算法測試的時候,一個好的資料集也是演算法實驗成功的前提保障。當然我們可以去網上下載大型資料網站整理好的,專業的資料,但是自己動手爬取資料是不是更愜意呢? 說到這裡,給大家推薦一些常用的大型資料集: (1)、Mov
用python來爬取中國天氣網北京,上海,成都8-15天的天氣
2 爬取北京,上海,成都的天氣 from bs4 import BeautifulSoup import random import requests import socket impo
go語言,取linux系統網絡卡MAC和硬碟序列號
利用cgo,實現在go語言中呼叫c語言函式,取MAC和硬碟序列號。cgo中需要注意的:*/和import "C"兩行之間不能有其它內容! package main /* #include <stdio.h> #include <stdlib.h>
windows下用Go語言實現第一個hello world
1,下載go編譯器———go編譯器下載地址https://golang.org/dl/ go編譯器下載地址 2,然後點選進行安裝,由於是msi檔案,如果需要.NET元件請自行下載進行安裝
Python 爬蟲第三步 -- 多執行緒爬蟲爬取噹噹網書籍資訊
XPath 的安裝以及使用 1 . XPath 的介紹 剛學過正則表示式,用的正順手,現在就把正則表示式替換掉,使用 XPath,有人表示這太坑爹了,早知道剛上來就學習 XPath 多省事 啊。其實我個人認為學習一下正則表示式是大有益處的,之所以換成 XPa
用python爬蟲爬取網頁桌布圖片(彼岸桌面網唯美圖片)
今天想給我的電腦裡面多加點桌布,但是嫌棄一個個儲存太慢,於是想著寫個爬蟲直接批量爬取,因為爬蟲只是很久之前學過一些,很多基礎語句都不記得了,於是直接在網上找了個有基礎操作語句的爬蟲程式碼,在這上面進行修改以適應我的要求和爬取的網頁需求 注意:這次爬取的
R語言爬取中國天氣網單個城市實時天氣預報資料
在傳統零售行業,雨天天氣大概會影響晴天30%-40%的銷售業績,所以從網上獲取天氣資料來作分析,並根據天氣資料作出預測,提前做好預防措施和提醒業務人員,把損失減少到最低就顯得十分重要,用R語言的rvest包就可以方便抓取天氣資料: 本文章的例子僅用於學習之用,
用接口爬取今日頭條圖片
b+ req ace nco ext odin api data utf #encoding:utf8import requestsimport jsonimport redemo = requests.get(‘http://www.toutiao.com/api/pc/
scrapy實戰1分布式爬取有緣網:
req 年齡 dict ems arch last rem pen war 直接上代碼: items.py 1 # -*- coding: utf-8 -*- 2 3 # Define here the models for your scraped items
多線程版爬取故事網
實現 exe don comm value obj nco result nic 前言:為了能以更高效的速度爬取,嘗試采用了多線程本博客參照代碼及PROJECT來源:http://kexue.fm/archives/4385/ 源代碼: 1 #! -*- cod