
基於Spark的電影推薦系統(推薦系統~2)
第四部分-推薦系統-資料ETL
- 本模組完成資料清洗,並將清洗後的資料load到Hive資料表裡面去
前置準備:
spark +hive
vim $SPARK_HOME/conf/hive-site.xml <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>hive.metastore.uris</name> <value>thrift://hadoop001:9083</value> </property> </configuration>
- 啟動Hive metastore server
[root@hadoop001 conf]# nohup hive --service metastore &
[root@hadoop001 conf]# netstat -tanp | grep 9083
tcp 0 0 0.0.0.0:9083 0.0.0.0:* LISTEN 24787/java
[root@hadoop001 conf]#
測試:
[root@hadoop001 ~]# spark-shell --master local[2]
scala> spark.sql("select * from liuge_db.dept").show; +------+-------+-----+ |deptno| dname| loc| +------+-------+-----+ | 1| caiwu| 3lou| | 2| renli| 4lou| | 3| kaifa| 5lou| | 4|qiantai| 1lou| | 5|lingdao|4 lou| +------+-------+-----+
==》保證Spark SQL 能夠訪問到Hive 的元資料才行。
然而我們採用的是standalone模式:需要啟動master worker
[root@hadoop001 sbin]# pwd
/root/app/spark-2.4.3-bin-2.6.0-cdh5.7.0/sbin
[root@hadoop001 sbin]# ./start-all.sh
[root@hadoop001 sbin]# jps
26023 Master
26445 Worker
Spark常用埠
8080 spark.master.ui.port Master WebUI 8081 spark.worker.ui.port Worker WebUI 18080 spark.history.ui.port History server WebUI 7077 SPARK_MASTER_PORT Master port 6066 spark.master.rest.port Master REST port 4040 spark.ui.port Driver WebUI
這個時候開啟:http://hadoop001:8080/
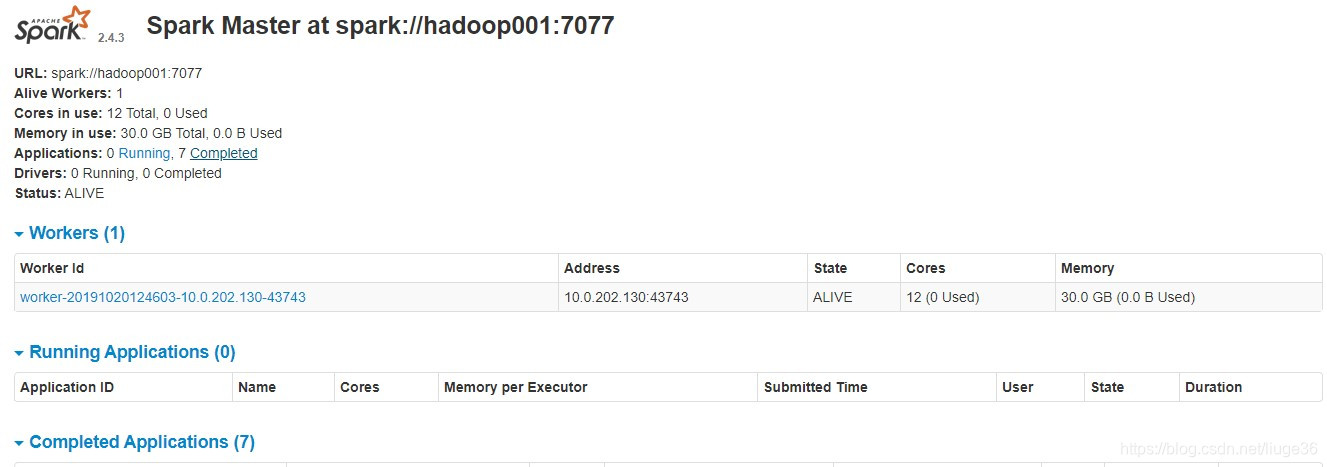
開始專案Coding
IDEA+Scala+Maven進行專案的構建
步驟一: 新建scala專案後,可以參照如下pom進行配置修改
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.csylh</groupId>
<artifactId>movie-recommend</artifactId>
<version>1.0</version>
<inceptionYear>2008</inceptionYear>
<properties>
<scala.version>2.11.8</scala.version>
<spark.version>2.4.3</spark.version>
</properties>
<repositories>
<repository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-8_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>1.1.1</version>
</dependency>
<!--// 0.10.2.1-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.39</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
</dependencies>
<build>
<!--<sourceDirectory>src/main/scala</sourceDirectory>-->
<!--<testSourceDirectory>src/test/scala</testSourceDirectory>-->
<plugins>
<plugin>
<!-- see http://davidb.github.com/scala-maven-plugin -->
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.1.3</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.13</version>
<configuration>
<useFile>false</useFile>
<disableXmlReport>true</disableXmlReport>
<!-- If you have classpath issue like NoDefClassError,... -->
<!-- useManifestOnlyJar>false</useManifestOnlyJar -->
<includes>
<include>**/*Test.*</include>
<include>**/*Suite.*</include>
</includes>
</configuration>
</plugin>
</plugins>
</build>
</project>
步驟二:新建com.csylh.recommend.dataclearer.SourceDataETLApp
import com.csylh.recommend.entity.{Links, Movies, Ratings, Tags}
import org.apache.spark.sql.{SaveMode, SparkSession}
/**
* Description:
* hadoop001 file:///root/data/ml/ml-latest 下的檔案
* ====> SparkSQL ETL
* ===> load data to Hive資料倉庫
*
* @Author: 留歌36
* @Date: 2019-07-12 13:48
*/
object SourceDataETLApp{
def main(args: Array[String]): Unit = {
// 面向SparkSession程式設計
val spark = SparkSession.builder()
// .master("local[2]")
.enableHiveSupport() //開啟訪問Hive資料, 要將hive-site.xml等檔案放入Spark的conf路徑
.getOrCreate()
val sc = spark.sparkContext
// 設定RDD的partitions 的數量一般以叢集分配給應用的CPU核數的整數倍為宜, 4核8G ,設定為8就可以
// 問題一:為什麼設定為CPU核心數的整數倍?
// 問題二:資料傾斜,拿到資料大的partitions的處理,會消耗大量的時間,因此做資料預處理的時候,需要考量會不會發生資料傾斜
val minPartitions = 8
// 在生產環境中一定要注意設定spark.sql.shuffle.partitions,預設是200,及需要配置分割槽的數量
val shuffleMinPartitions = "8"
spark.sqlContext.setConf("spark.sql.shuffle.partitions",shuffleMinPartitions)
/**
* 1
*/
import spark.implicits._
val links = sc.textFile("file:///root/data/ml/ml-latest/links.txt",minPartitions) //DRIVER
.filter(!_.endsWith(",")) //EXRCUTER
.map(_.split(",")) //EXRCUTER
.map(x => Links(x(0).trim.toInt, x(1).trim.toInt, x(2).trim.toInt)) //EXRCUTER
.toDF()
println("===============links===================:",links.count())
links.show()
// 把資料寫入到HDFS上
links.write.mode(SaveMode.Overwrite).parquet("/tmp/links")
// 將資料從HDFS載入到Hive資料倉庫中去
spark.sql("drop table if exists links")
spark.sql("create table if not exists links(movieId int,imdbId int,tmdbId int) stored as parquet")
spark.sql("load data inpath '/tmp/links' overwrite into table links")
/**
* 2
*/
val movies = sc.textFile("file:///root/data/ml/ml-latest/movies.txt",minPartitions)
.filter(!_.endsWith(","))
.map(_.split(","))
.map(x => Movies(x(0).trim.toInt, x(1).trim.toString, x(2).trim.toString))
.toDF()
println("===============movies===================:",movies.count())
movies.show()
// 把資料寫入到HDFS上
movies.write.mode(SaveMode.Overwrite).parquet("/tmp/movies")
// 將資料從HDFS載入到Hive資料倉庫中去
spark.sql("drop table if exists movies")
spark.sql("create table if not exists movies(movieId int,title String,genres String) stored as parquet")
spark.sql("load data inpath '/tmp/movies' overwrite into table movies")
/**
* 3
*/
val ratings = sc.textFile("file:///root/data/ml/ml-latest/ratings.txt",minPartitions)
.filter(!_.endsWith(","))
.map(_.split(","))
.map(x => Ratings(x(0).trim.toInt, x(1).trim.toInt, x(2).trim.toDouble, x(3).trim.toInt))
.toDF()
println("===============ratings===================:",ratings.count())
ratings.show()
// 把資料寫入到HDFS上
ratings.write.mode(SaveMode.Overwrite).parquet("/tmp/ratings")
// 將資料從HDFS載入到Hive資料倉庫中去
spark.sql("drop table if exists ratings")
spark.sql("create table if not exists ratings(userId int,movieId int,rating Double,timestamp int) stored as parquet")
spark.sql("load data inpath '/tmp/ratings' overwrite into table ratings")
/**
* 4
*/
val tags = sc.textFile("file:///root/data/ml/ml-latest/tags.txt",minPartitions)
.filter(!_.endsWith(","))
.map(x => rebuild(x)) // 注意這個坑的解決思路
.map(_.split(","))
.map(x => Tags(x(0).trim.toInt, x(1).trim.toInt, x(2).trim.toString, x(3).trim.toInt))
.toDF()
tags.show()
// 把資料寫入到HDFS上
tags.write.mode(SaveMode.Overwrite).parquet("/tmp/tags")
// 將資料從HDFS載入到Hive資料倉庫中去
spark.sql("drop table if exists tags")
spark.sql("create table if not exists tags(userId int,movieId int,tag String,timestamp int) stored as parquet")
spark.sql("load data inpath '/tmp/tags' overwrite into table tags")
}
/**
* 該方法是用於處理不符合規範的資料
* @param input
* @return
*/
private def rebuild(input:String): String ={
val a = input.split(",")
val head = a.take(2).mkString(",")
val tail = a.takeRight(1).mkString
val tag = a.drop(2).dropRight(1).mkString.replaceAll("\"","")
val output = head + "," + tag + "," + tail
output
}
}再有一些上面主類引用到的case 物件,你可以理解為Java 實體類
package com.csylh.recommend.entity
/**
* Description: 資料的schema
*
* @Author: 留歌36
* @Date: 2019-07-12 13:46
*/
case class Links(movieId:Int,imdbId:Int,tmdbId:Int)package com.csylh.recommend.entity
/**
* Description: TODO
*
* @Author: 留歌36
* @Date: 2019-07-12 14:09
*/
case class Movies(movieId:Int,title:String,genres:String)
package com.csylh.recommend.entity
/**
* Description: TODO
*
* @Author: 留歌36
* @Date: 2019-07-12 14:10
*/
case class Ratings(userId:Int,movieId:Int,rating:Double,timestamp:Int)
package com.csylh.recommend.entity
/**
* Description: TODO
*
* @Author: 留歌36
* @Date: 2019-07-12 14:11
*/
case class Tags(userId:Int,movieId:Int,tag:String,timestamp:Int)
步驟三:將建立的專案進行打包上傳到伺服器
mvn clean package -Dmaven.test.skip=true
[root@hadoop001 ml]# ll -h movie-recommend-1.0.jar
-rw-r--r--. 1 root root 156K 10月 20 13:56 movie-recommend-1.0.jar
[root@hadoop001 ml]# 步驟四:提交執行上面的jar,編寫shell指令碼
[root@hadoop001 ml]# vim etl.sh
export HADOOP_CONF_DIR=/root/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop
$SPARK_HOME/bin/spark-submit --class com.csylh.recommend.dataclearer.SourceDataETLApp --master spark://hadoop001:7077 --name SourceDataETLApp --driver-memory 10g --executor-memory 5g /root/data/ml/movie-recommend-1.0.jar
步驟五:sh etl.sh 即可
先把資料寫入到HDFS上
建立Hive表
load 資料到表
sh etl.sh之前:
[root@hadoop001 ml]# hadoop fs -ls /tmp
19/10/20 19:26:58 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 2 items
drwx------ - root supergroup 0 2019-04-01 16:27 /tmp/hadoop-yarn
drwx-wx-wx - root supergroup 0 2019-04-02 09:33 /tmp/hive
[root@hadoop001 ml]# hadoop fs -ls /user/hive/warehouse
19/10/20 19:27:03 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[root@hadoop001 ml]#sh etl.sh之後:
這裡的shell 是 ,spark on standalone,後面會spark on yarn。其實也沒差,都可以
[root@hadoop001 ~]# hadoop fs -ls /tmp
19/10/20 19:43:17 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 6 items
drwx------ - root supergroup 0 2019-04-01 16:27 /tmp/hadoop-yarn
drwx-wx-wx - root supergroup 0 2019-04-02 09:33 /tmp/hive
drwxr-xr-x - root supergroup 0 2019-10-20 19:42 /tmp/links
drwxr-xr-x - root supergroup 0 2019-10-20 19:42 /tmp/movies
drwxr-xr-x - root supergroup 0 2019-10-20 19:43 /tmp/ratings
drwxr-xr-x - root supergroup 0 2019-10-20 19:43 /tmp/tags
[root@hadoop001 ~]# hadoop fs -ls /user/hive/warehouse
19/10/20 19:43:32 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 4 items
drwxr-xr-x - root supergroup 0 2019-10-20 19:42 /user/hive/warehouse/links
drwxr-xr-x - root supergroup 0 2019-10-20 19:42 /user/hive/warehouse/movies
drwxr-xr-x - root supergroup 0 2019-10-20 19:43 /user/hive/warehouse/ratings
drwxr-xr-x - root supergroup 0 2019-10-20 19:43 /user/hive/warehouse/tags
[root@hadoop001 ~]# 這樣我們就把資料etl到我們的資料倉庫裡了,接下來,基於這份基礎資料做資料加工
有任何問題,歡迎留言一起交流~~
更多文章:基於Spark的電影推薦系統:https://blog.csdn.net/liuge36/column/info/29