
Attention機制全解
目錄
- 前言
- Seq2Seq
- Attention機制的引入
- Hard or Soft
- Global or Local
- 注意力的計算
- Self-Attention
- 小結
前言
之前已經提到過好幾次Attention的應用,但還未對Attention機制進行系統的介紹,之後的實踐模型attention將會用到很多,因此這裡對attention機制做一個總結。
Seq2Seq
注意力機制(Attention Mechanism)首先是用於解決 Sequence to Sequence 問題提出的,因此我們瞭解下研究者是怎樣設計出Attention機制的。
Seq2Seq,即序列到序列,指的是用Encoder-Decoder框架來實現的端到端的模型,最初用來實現英語-法語翻譯。Encoder-Decoder框架是一種十分通用的模型框架,其抽象結構如下圖所示:

其中,Encoder和Decoder具體使用什麼模型都是由研究者自己定的,CNN/RNN/Transformer均可。Encoder的作用就是將輸入序列對映成一個固定長度的上下文向量C,而Decoder則將上下文向量C作為預測\(Y_1\)輸出的初始向量,之後將其作為背景向量,並結合上一個時間步的輸出來對下一個時間步進行預測。
由於Encoder-Decoder模型在編碼和解碼階段始終由一個不變的語義向量C來聯絡著,這也造成了如下一些問題:
- 所有的輸入單詞 X 對生成的所有目標單詞 Y 的影響力是相同的
- 編碼器要將整個序列的資訊壓縮排一個固定長度的向量中去,使得語義向量無法完全表示整個序列的資訊
- 最開始輸入的序列容易被後輸入的序列給覆蓋掉,會丟失許多細節資訊,這點在長序列上表現的尤為明顯
Attention機制的引入
Attention機制的作用就是為模型增添了注意力功能,使其傾向於根據需要來選擇句子中更重要的部分。
加入加入Attention機制的Seq2Seq模型框架如下圖所示:
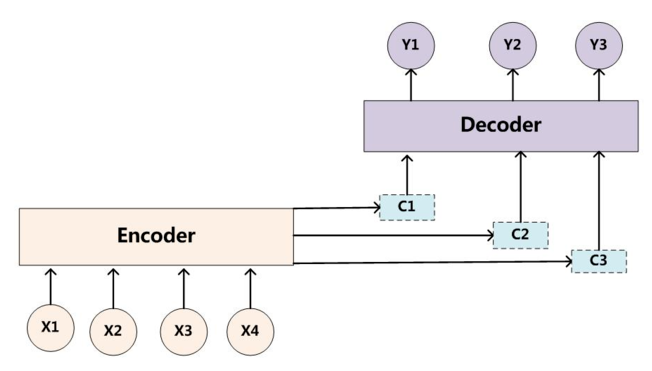
與傳統的語義向量C不同的是,帶有注意力機制的Seq2Seq模型與傳統Seq2Seq模型的區別如下:
- 其為每一次預測都有不同的上下文資訊\(C_i\)\[P(y_i|y_1, y_2, ..., y_{i-1}, X) = P(y_i-1, s_i, c_i)\]
其中\(s_i\)表示Decoder上一時刻的輸出狀態,\(c_i\)為當前的時刻的中間語義向量
- 當前的時刻的中間語義向量\(c_i\)為對輸入資訊注意力加權求和之後得到的向量,即:
\[c_i = \sum_{j=1}^{Tx}\alpha_{ij}h_j\]
其中\(h_j\)為Encoder端的第j個詞的隱向量,\(\alpha_{ij}\)表示Decoder端的第i個詞對Encoder端的第j個詞的注意力大小,即輸入的第j個詞對生成的第i個詞的影響程度。這意味著在生成每個單詞\(Y_i\)的時候,原先都是相同的中間語義表示\(C\)會替換成根據當前生成單詞而不斷變化的\(c_i\)。生成\(c_i\)最關鍵的部分就是注意力權重\(\alpha_{ij}\)的計算,具體的計算方法我們下面再討論。
Hard or Soft
之前我們提到的為Soft Attention的一般形式,還有一種Hard Attention,其與Soft Attention的區別在於,其通過隨機取樣或最大采樣的方式來選取特徵資訊(Soft Attention是通過加權求和的方式),這使得其無法使用反向傳播演算法進行訓練。因此我們常用的通常是Soft Attention
Global or Local
Global Attention 與 Local Attention 的區別在於二者的關注範圍不同。Global Attention 關注的是整個序列的輸入資訊,相對來說需要更大的計算量。而 Local Attention 僅僅關注限定視窗範圍內的序列資訊,但視窗的限定使得中心詞容易忽視不在視窗範圍內的資訊,因此視窗的大小設定十分重要。在實踐中,預設使用的是Global Attention。
注意力的計算
我們之前已經討論過,中間語義向量\(c_i\)為對輸入資訊注意力加權求和之後得到的向量,即:
\[c_i = \sum_{j=1}^{Tx}\alpha_{ij}h_j\]
而注意力權重\(\alpha_{ij}\)表示Decoder端的第i個詞對Encoder端的第j個詞的注意力大小,即輸入的第j個詞對生成的第i個詞的影響程度。其基本的計算方式如下:
\[\alpha_{ij} = \frac{exp(e_{ij})}{\sum_{k=1}^{T_x}exp(e_{ik})}\]
\[e_{ij} = Score(s_{i-1}, h_j)\]
其中,\(s_{i-1}\)需要根據具體任務進行選擇,對於機器翻譯等生成任務,可以選取 Decoder 上一個時刻的隱藏層輸出,對於閱讀理解等問答任務,可以選擇問題或問題+選項的表徵,對於文字分類任務,可以是自行初始化的上下文向量。而\(h_j\)為 Encoder 端第j個詞的隱向量,分析上面公式,可以將Attention的計算過程總結為3個步驟:
- 將上一時刻Decoder的輸出與當前時刻Encoder的隱藏詞表徵進行評分,來獲得目標單詞 Yi 和每個輸入單詞對應的對齊可能性(即一個對齊模型),Score(·)為一個評分函式,一般可以總結為兩類:
- 點積/放縮點積:
\[e_{ij} = Score(s_{i-1}, h_j) = s_{i-1} \cdot h_j\]
\[e_{ij} = Score(s_{i-1}, h_j) = \frac{s_{i-1} \cdot h_j}{||s_{i-1}||\cdot||h_j||}\]
- MLP網路:
\[e_{ij} = Score(s_{i-1}, h_j) = MLP(s_{i-1}, h_j)\]
\[e_{ij} = Score(s_{i-1}, h_j) = s_{i-1}Wh_{j}\]
\[e_{ij} = Score(s_{i-1}, h_j) = W|h_j;s_{i-1}|\]
- 點積/放縮點積:
得到對齊分數之後,用Softmx函式將其進行歸一化,得到注意力權重
最後將注意力權重與 Encoder 的輸出進行加權求和,得到需要的中間語義向量\(c_i\)
將公式整合一下:
\[c_{i,j} = Attention(Query, Keys, Values) = Softmax(Score(Query, Keys)) * Values\]
其中,\(Query\)為我們之前提到的\(s_{i-1}\),\(Keys\) 和 \(Values\)為 \(h\)
Self-Attention
重溫一下我們講解Transformer時提到的Self-Attention,其 \(Query\),\(Keys\) 和 \(Values\) 均為Encoder層的詞表徵通過一個簡單的線性對映矩陣得到的,即可將其表示為
\[Attention(Q,K,V) = Attention(W^QX,W^KX,W^VX)\]
從其注意力分數的計算方法上來看也是一種典型的縮放點積,其關鍵在於僅對句子本身進行注意力權值計算,使其更能夠把握句子中詞與詞之前的關係,從而提取出句子中的句法特徵或語義特徵。

小結
這一塊對Attention的原理基本已經全部總結了,主要是對自己只是的鞏固,以及對之後的實踐工作做鋪墊,之後有時間再將Attention這塊相關的程式碼寫出來。
參考連結
https://zhuanlan.zhihu.com/p/31547842
https://zhuanlan.zhihu.com/p/59698165
https://zhuanlan.zhihu.com/p/53682800
https://zhuanlan.zhihu.com/p/4349