
nsq (三) 訊息傳輸的可靠性和持久化[一]
上兩篇帖子主要說了一下nsq的拓撲結構,如何進行故障處理和橫向擴充套件,保證了客戶端和服務端的長連線,連線保持了,就要傳輸資料了,nsq如何保證訊息被訂閱者消費,如何保證訊息不丟失,就是今天要闡述的內容。
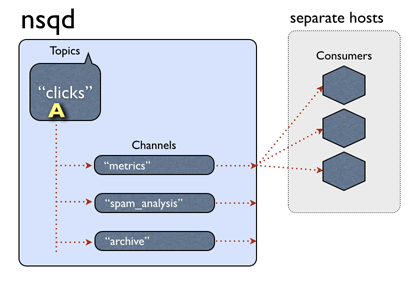
nsq topic、channel、和消費我客戶端的結構如上圖,一個topic下有多個channel每個channel可以被多個客戶端訂閱。
訊息處理的大概流程:當一個訊息被nsq接收後,傳給相應的topic,topic把訊息傳遞給所有的channel ,channel根據演算法選擇一個訂閱客戶端,把訊息傳送給客戶端進行處理。
看上去這個流程是沒有問題的,我們來思考幾個問題
- 網路傳輸的不確定性,比如超時;客戶端處理訊息時崩潰等,訊息如何重傳;
- 如何標識訊息被客戶端成功處理完畢;
- 訊息的持久化,
nsq服務端重新啟動時訊息不丟失;
服務端對傳送中的訊息處理邏輯
之前的帖子說過客戶端和服務端進行連線後,會啟動一個gorouting來發送資訊給客戶端
go p.messagePump(client, messagePumpStartedChan)然後會監聽客戶端發過來的命令client.Reader.ReadSlice('\n')
服務端會定時檢查client端的連線狀態,讀取客戶端發過來的各種命令,傳送心跳等。每一個連線最終的目的就是監聽channel的訊息,傳送給客戶端進行消費。
當有訊息傳送給訂閱客戶端的時候,當然選擇哪個client
func (p *protocolV2) messagePump(client *clientV2, startedChan chan bool) { // ... for { // ... case b := <-backendMsgChan: if sampleRate > 0 && rand.Int31n(100) > sampleRate { continue } msg, err := decodeMessage(b) if err != nil { p.ctx.nsqd.logf(LOG_ERROR, "failed to decode message - %s", err) continue } msg.Attempts++ subChannel.StartInFlightTimeout(msg, client.ID, msgTimeout) client.SendingMessage() err = p.SendMessage(client, msg) if err != nil { goto exit } flushed = false case msg := <-memoryMsgChan: if sampleRate > 0 && rand.Int31n(100) > sampleRate { continue } msg.Attempts++ subChannel.StartInFlightTimeout(msg, client.ID, msgTimeout) client.SendingMessage() err = p.SendMessage(client, msg) if err != nil { goto exit } flushed = false case <-client.ExitChan: goto exit } } // ... }
看一下這個方法呼叫subChannel.StartInFlightTimeout(msg, client.ID, msgTimeout),在傳送給客戶端之前,把這個訊息設定為在飛翔中,
// pushInFlightMessage atomically adds a message to the in-flight dictionary
func (c *Channel) pushInFlightMessage(msg *Message) error {
c.inFlightMutex.Lock()
_, ok := c.inFlightMessages[msg.ID]
if ok {
c.inFlightMutex.Unlock()
return errors.New("ID already in flight")
}
c.inFlightMessages[msg.ID] = msg
c.inFlightMutex.Unlock()
return nil
}然後傳送給客戶端進行處理。
在傳送中的資料,存在的各種不確定性,nsq的處理方式是:對傳送給客戶端資訊設定為在飛翔中,如果在如果處理成功就把這個訊息從飛翔中的狀態中去掉,如果在規定的時間內沒有收到客戶端的反饋,則認為這個訊息超時,然後重新歸隊,兩次進行處理。所以無論是哪種特殊情況,nsq統一認為訊息為超時。
服務端處理超時訊息
nsq對超時訊息的處理,借鑑了redis的過期演算法,但也不太一樣redis的更復雜一些,因為redis是單執行緒的,還要處理佔用cpu時間等等,nsq因為gorouting的存在要很簡單很多。
簡單來說,就是在nsq啟動的時候啟動協程去處理channel的過期資料
func (n *NSQD) Main() error {
// ...
// 啟動協程去處理channel的過期資料
n.waitGroup.Wrap(n.queueScanLoop)
n.waitGroup.Wrap(n.lookupLoop)
if n.getOpts().StatsdAddress != "" {
n.waitGroup.Wrap(n.statsdLoop)
}
err := <-exitCh
return err
}當然不是每一個channel啟動一個協程來處理過期資料,而是有一些規定,我們看一下一些預設值,然後再展開講演算法
return &Options{
// ...
HTTPClientConnectTimeout: 2 * time.Second,
HTTPClientRequestTimeout: 5 * time.Second,
// 記憶體最大佇列數
MemQueueSize: 10000,
MaxBytesPerFile: 100 * 1024 * 1024,
SyncEvery: 2500,
SyncTimeout: 2 * time.Second,
// 掃描channel的時間間隔
QueueScanInterval: 100 * time.Millisecond,
// 重新整理掃描的時間間隔
QueueScanRefreshInterval: 5 * time.Second,
QueueScanSelectionCount: 20,
// 最大的掃描池數量
QueueScanWorkerPoolMax: 4,
// 標識百分比
QueueScanDirtyPercent: 0.25,
// 訊息超時
MsgTimeout: 60 * time.Second,
MaxMsgTimeout: 15 * time.Minute,
MaxMsgSize: 1024 * 1024,
MaxBodySize: 5 * 1024 * 1024,
MaxReqTimeout: 1 * time.Hour,
ClientTimeout: 60 * time.Second,
// ...
}這些引數都可以在啟動nsq的時候根據自己需要來指定,我們主要說一下這幾個:
QueueScanWorkerPoolMax就是最大協程數,預設是4,這個數是掃描所有channel的最大協程數,當然channel的數量小於這個引數的話,就調整協程的數量,以最小的為準,比如channel的數量為2個,而預設的是4個,那就調掃描的數量為2個QueueScanSelectionCount每次掃描最大的channel數量,預設是20,如果channel的數量小於這個值,則以channel的數量為準。QueueScanDirtyPercent標識髒資料channel的百分比,預設為0.25,eg:channel數量為10,則一次最多掃描10個,檢視每個channel是否有過期的資料,如果有,則標記為這個channel是有髒資料的,如果有髒資料的channel的數量 佔這次掃描的10個channel的比例超過這個百分比,則直接再次進行掃描一次,而不用等到下一次時間點。QueueScanInterval掃描channel的時間間隔,預設的是每100毫秒掃描一次。QueueScanRefreshInterval重新整理掃描的時間間隔 目前的處理方式是調整channel的協程數量。
這也就是nsq處理過期資料的演算法,總結一下就是,使用協程定時去掃描隨機的channel裡是否有過期資料。
func (n *NSQD) queueScanLoop() {
workCh := make(chan *Channel, n.getOpts().QueueScanSelectionCount)
responseCh := make(chan bool, n.getOpts().QueueScanSelectionCount)
closeCh := make(chan int)
workTicker := time.NewTicker(n.getOpts().QueueScanInterval)
refreshTicker := time.NewTicker(n.getOpts().QueueScanRefreshInterval)
channels := n.channels()
n.resizePool(len(channels), workCh, responseCh, closeCh)
for {
select {
case <-workTicker.C:
if len(channels) == 0 {
continue
}
case <-refreshTicker.C:
channels = n.channels()
n.resizePool(len(channels), workCh, responseCh, closeCh)
continue
case <-n.exitChan:
goto exit
}
num := n.getOpts().QueueScanSelectionCount
if num > len(channels) {
num = len(channels)
}
loop:
// 隨機channel
for _, i := range util.UniqRands(num, len(channels)) {
workCh <- channels[i]
}
numDirty := 0
for i := 0; i < num; i++ {
if <-responseCh {
numDirty++
}
}
if float64(numDirty)/float64(num) > n.getOpts().QueueScanDirtyPercent {
goto loop
}
}
exit:
n.logf(LOG_INFO, "QUEUESCAN: closing")
close(closeCh)
workTicker.Stop()
refreshTicker.Stop()
}在掃描channel的時候,如果發現有過期資料後,會重新放回到佇列,進行重發操作。
func (c *Channel) processInFlightQueue(t int64) bool {
// ...
for {
c.inFlightMutex.Lock()
msg, _ := c.inFlightPQ.PeekAndShift(t)
c.inFlightMutex.Unlock()
if msg == nil {
goto exit
}
dirty = true
_, err := c.popInFlightMessage(msg.clientID, msg.ID)
if err != nil {
goto exit
}
atomic.AddUint64(&c.timeoutCount, 1)
c.RLock()
client, ok := c.clients[msg.clientID]
c.RUnlock()
if ok {
client.TimedOutMessage()
}
//重新放回佇列進行消費處理。
c.put(msg)
}
exit:
return dirty
}客戶端對訊息的處理和響應
之前的帖子中的例子中有說過,客戶端要消費訊息,需要實現介面
type Handler interface {
HandleMessage(message *Message) error
}在服務端傳送訊息給客戶端後,如果在處理業務邏輯時,如果發生錯誤則給伺服器傳送Requeue命令告訴伺服器,重新發送訊息進處理。如果處理成功,則傳送Finish命令
func (r *Consumer) handlerLoop(handler Handler) {
r.log(LogLevelDebug, "starting Handler")
for {
message, ok := <-r.incomingMessages
if !ok {
goto exit
}
if r.shouldFailMessage(message, handler) {
message.Finish()
continue
}
err := handler.HandleMessage(message)
if err != nil {
r.log(LogLevelError, "Handler returned error (%s) for msg %s", err, message.ID)
if !message.IsAutoResponseDisabled() {
message.Requeue(-1)
}
continue
}
if !message.IsAutoResponseDisabled() {
message.Finish()
}
}
exit:
r.log(LogLevelDebug, "stopping Handler")
if atomic.AddInt32(&r.runningHandlers, -1) == 0 {
r.exit()
}
}服務端收到命令後,對飛翔中的訊息進行處理,如果成功則去掉,如果是Requeue則執行歸隊和重發操作,或者進行defer佇列處理。
訊息的持久化
預設的情況下,只有記憶體佇列不足時MemQueueSize:10000時,才會把資料儲存到檔案內進行持久到硬碟。
select {
case c.memoryMsgChan <- m:
default:
b := bufferPoolGet()
err := writeMessageToBackend(b, m, c.backend)
bufferPoolPut(b)
c.ctx.nsqd.SetHealth(err)
if err != nil {
c.ctx.nsqd.logf(LOG_ERROR, "CHANNEL(%s): failed to write message to backend - %s",
c.name, err)
return err
}
}
return nil如果將 --mem-queue-size 設定為 0,所有的訊息將會儲存到磁碟。我們不用擔心訊息會丟失,nsq 內部機制保證在程式關閉時將佇列中的資料持久化到硬碟,重啟後就會恢復。
nsq自己開發了一個庫go-diskqueue來持久會訊息到記憶體。這個庫的程式碼量不多,理解起來也不難,程式碼邏輯我想下一篇再講。
看一下儲存在硬碟後的樣子:

相關推薦
nsq (三) 訊息傳輸的可靠性和持久化[一]
上兩篇帖子主要說了一下nsq的拓撲結構,如何進行故障處理和橫向擴充套件,保證了客戶端和服務端的長連線,連線保持了,就要傳輸資料了,nsq如何保證訊息被訂閱者消費,如何保證訊息不丟失,就是今天要闡述的內容。 nsq topic、channel、和消費我客戶端的結構如上圖,一個topic下有多個channel
剖析nsq訊息佇列(三) 訊息傳輸的可靠性和持久化[二]diskqueue
上一篇主要說了一下nsq是如何保證訊息被消費端成功消費,大概提了一下訊息的持久化,--mem-queue-size 設定為 0,所有的訊息將會儲存到磁碟。 總有人說nsq的持久化問題,消除疑慮的方法就是閱讀原碼做benchmark測試,個人感覺nsq還是很靠譜的。 nsq自己實現了一個先進先出的訊息檔案佇列g
redis(三):redis事務和持久化
1. redis事務 1.1. redis資料庫相關特性 redis資料庫:redis總共有16個數據庫,編號分別為0-15,可以選擇資料庫:select 0,第一個資料庫。 移動key:move keyName 2,將keyName移動到第三個資料庫。 檢視型別:t
20181104-訊息中介軟體(一)-ActiveMQ安全認證和持久化
一、ActiveMQ安全認證 1.在conf/activemq.xml中開啟認證,即在broker標籤中新增以下程式碼 <plugins> <!-- use JAAS to authenticate using t
activemq訊息機制和持久化介紹
前面一節簡單學習了activemq的使用,我們知道activemq的使用方式非常簡單有如下幾個步驟: 建立連線工廠 建立連線 建立會話 建立目的地 建立生產者或消費者 生產或消費訊息 關閉生產
netty 三之訊息推送和心跳檢測
主要參考 https://blog.csdn.net/coder_py/article/details/73441043 有小改動(因使用的是netty4的包 netty-all-4.1.25.Final.jar) 通訊資訊的基類,需要實現序列化,定義了資訊的型別和客戶端ID,方便進行管
activemq 學習系列(三) 訊息持久化到MySql資料庫
ActiveMq 訊息持久化到MySql資料庫 1、修改 conf/activemq.xml配置檔案 <persistenceAdapter> <kahaDB directory="${activemq.data}/kahadb"/> </persistence
如何保證訊息的可靠性傳輸(如何處理訊息丟失的問題)
RabbitMQ 生產者弄丟了資料 生產者將資料傳送到RabbitMQ的時候,可能資料就在半路給搞丟了,因為網路啥的問題,都有可能。 此時可以選擇用RabbitMQ提供的事務功能,就是生產者傳送資料之前開啟RabbitMQ事務(channel.tx
RabbitMQ(三):訊息持久化策略
一、前言 在正常的伺服器執行過程中,時常會面臨伺服器宕機重啟的情況,那麼我們的訊息此時會如何呢?很不幸的事情就是,我們的訊息可能會消失,這肯定不是我們希望見到的結果。所以我們希望AMQP伺服器崩潰了也可以將訊息恢復,這稱之為訊息持久化。RabbitMQ自然存在這種策略可以幫助我們完成這件事情。 二、持
十一、訊息對佇列和消費確認
訊息到佇列 訊息傳送後,如何確定到訊息是否到達了相應的佇列?RabbitMQ預設在傳送訊息時,如果不能根據交換器型別和路由鍵找到相應的佇列,訊息將直接丟棄。而要想知道訊息是否達到佇列或沒到佇列卻不想訊息丟失,RabbitMQ提供有解決方案: 設定mandatory引數 為true時,
MQ入門總結(一)訊息佇列概念和使用場景
一、訊息佇列 訊息即是資訊的載體。為了讓訊息傳送者和訊息接收者都能夠明白訊息所承載的資訊(訊息傳送者需要知道如何構造訊息;訊息接收者需要知道如何解析訊息),它們就需要按照一種統一的格式描述訊息,這種統一的格式稱之為訊息協議。所以,有效的訊息一定具有某一種格式;而
一步一步開發Game伺服器(三)載入指令碼和伺服器熱更新
大家可能對遊戲伺服器的執行不太理解或者說不太清楚一些機制。 但是大家一定會明白一點,當程式在執行的時候出現一些bug,必須及時更新,但是不能重啟程式的情況下。 這裡牽涉到一個問題。比如說在遊戲裡面,,如果一旦開服,錯非完全致命性bug,否則是不能頻繁重啟伺服器程式的, 你重啟一次就可能流失一部分玩家。那
一步一步開發Game伺服器(三)載入指令碼和伺服器熱更新(二)完整版
可是在使用過程中,也許有很多會發現,動態載入dll其實不方便,應為需要預先編譯程式碼為dll檔案。便利性不是很高。 那麼有麼有辦法能做到動態實時更新呢???? 官方提供了這兩個物件,動態編譯原始檔。 提供對 C# 程式碼生成器和程式碼編譯器的例項的訪問。 CSharpCodeProvider
SQL查詢當前資料以及上一條和下一條三條記錄
想查詢某個表當前資料以及上一條和下一條的記錄,網上找了一下解決辦法都不如意,按網上的方法可以查詢出三條資料,但是當查詢的這條資料沒有上一條或下一條記錄時就不行了。現在我把解決問題的sql語句放上 : 理一下思路,明確的查詢三條語句: SELECT * FROM 表名
RabbitMQ原理三--訊息持久化
原文地址:http://www.cnblogs.com/ericli-ericli/p/5938106.html問題及方案描述1.當有多個消費者同時收取訊息,且每個消費者在接收訊息的同時,還要處理其它的事情,且會消耗很長的時間。在此過程中可能會出現一些意外,比如訊息接收到一半
三、Linux系統程式設計-檔案和IO(一)檔案的開啟和關閉
#include <sys/types.h> #include <sys/stat.h> #include <fcntl.h> #include <string.h> #include <stdio.h> #include <stdlib.h
1,2,3……,9組成3個三位數abc,def和ghi,每個數字恰好使用一次,要求abc:def:ghi=1:2:3.輸出所有解的兩種解法
解法1:#include<iostream> #include<cstdio> using namespace std; void result(int num
ActiveMQ使用筆記(二)ActiveMQ訊息持久化一
<persistenceAdapter> <mKahaDB directory="${activemq.base}/data/kahadb"> <filteredPersistenceAdapters> <!-- match all queu
3Sum(在一個數組中找到三個數字的和為0不重複)leetcode15
Given an array nums of n integers, are there elements a, b, c in nums such that a + b + c = 0? Find a
Spark程式設計指引(三)-----------------RDD操作,shuffle和持久化
處理鍵-值對 儘管Spark的大部操作支援包含所有物件型別的RDDs,但是還有一些操作只支援鍵-值對的的RDDs.最常見的是類似"洗牌"的操作,比如以鍵值來分組或聚合所有的元素。 在Scala裡,這些操作對包含2元組的RDD是自動可用的。(Scala語言內建的元組,通過(a