
網際網路面試開小灶系列之訊息佇列(一)
目錄
- 背景
- 為什麼使用訊息佇列
- 訊息佇列有什麼優缺點
- 訊息佇列的選型
- 重複消費你們是怎麼解決的?
@(目錄)
背景
程式設計師不懂點訊息佇列的知識,怎麼能證明你經歷過高併發系統的洗禮呢?看起來你的專案經歷比較單一和簡單嘛,面試官在心裡應該有點看低你這位候選人了。就算你的專案裡沒有用到,為了面試,你也得懂得一些訊息佇列的基本原理及常見面試套路吧!
為什麼使用訊息佇列
你們的專案中有用到訊息佇列嗎?為什麼要使用訊息佇列呢?
都說學以致用,不少候選人為了豐富自己的簡歷,會說自己精通XXX語言,專案中使用了Redis、MQ,知道已經使用,但如果為為何使用,就回答不出什麼道道來。
這種情況下,面試官會以為,你只是一個普通幹活的,平時可能只是CURD操作,修補bug,只是瞭解專案一些細枝末節,對於專案的整體設計架構,沒有自己的獨立思考,這樣人想達到中級工程師的水平也有點難啊,面試官會在心裡對你的整體印象大大打折。
訊息佇列的為什麼使用必須結合專案的場景來說。專案場景有高併發,低延遲的需求,可能需要引入訊息佇列,但引入訊息佇列同時也會帶來一些問題,這是下一個需要考慮的問題。
訊息佇列引入的主要原因有三個:解耦、非同步和削峰。
解耦
一般公司的專案,在構建初期,一個服務裡面就揉進去很多功能,敏捷開發嘛,快速迭代上線。舉個例子,S1系統產生的使用者資料源,可能會被S2、S3系統呼叫,後來又新增了S4系統,每次有系統的增刪,負責S1系統的開發人員都需要修改程式碼,測試,上線,簡直煩不勝煩。
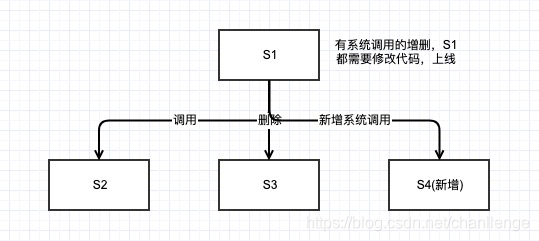
如果改為S1系統將資料打入訊息佇列,哪個系統想要使用資料,直接消費訊息佇列就ok了,世界真清淨。誰來接入我誰來負責,我只用管打入訊息佇列是ok的就行。S1系統的開發人員可以悠閒喝茶知道別人怎麼接入了!
非同步
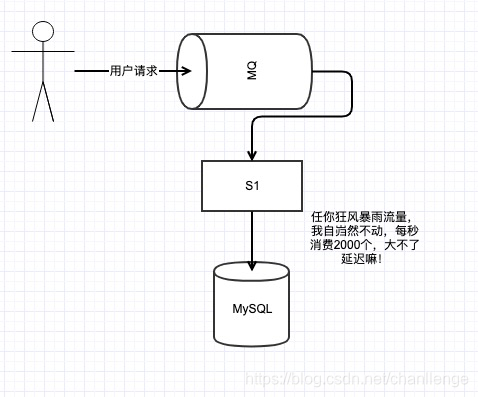
一般的服務,肯定會與儲存打交道,涉及到儲存一般有MySQL、MongoDB、Hbase或其他儲存。如下圖,假設,S1系統只是一些本地記憶體操作,耗時5ms,S2、S3寫庫為MySQL和Hbase,耗時分別是50ms和80ms,那系統的總耗時就是5+50+80=135ms。
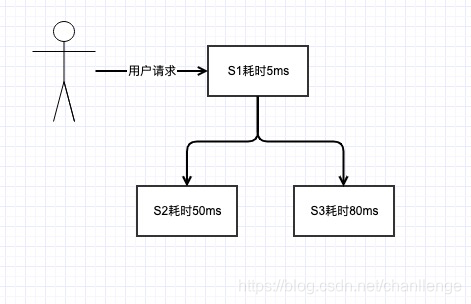
雖然當前使用者訪問延時為135ms,速度也還可以了,但如果又增加了S4、S5系統呢,訪問延遲是逐漸增加的啊,到時候就會有人抱怨你的系統做的太爛了。如果改為訊息佇列呢,S1將資料打入MQ,耗時5ms,總的系統延遲就是5+5=10ms,而且解耦了,再增加其他服務訪問延遲還是10ms,網站做的666啊,速度飛快。
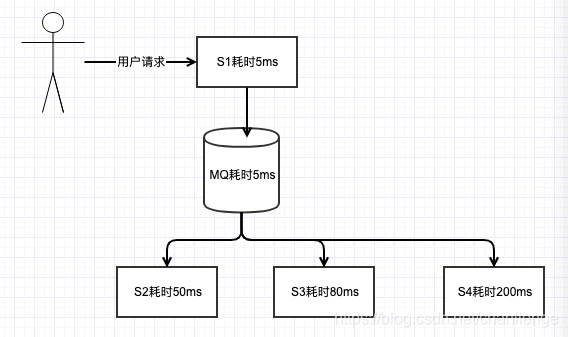
削峰
任何公司的任何業務,都會有流量的高峰和低谷,每天00:00-6:00,系統訪問低谷,請求併發量可能就幾十個,一切很美好。但到了12:30-13:00,訪問流量竟然能達到10000/s,也是佩服公司的運營人員和公司的產品啊,產品訪問量大好啊,說明業務蒸蒸日上,但開發哥哥就沒這麼好過了,併發量大,對資料持久層的訪問時個考驗。
假設當前S1系統訪問的MySQL還沒有做分庫分表的優化,那能抗住的QPS的上線就是2000左右。
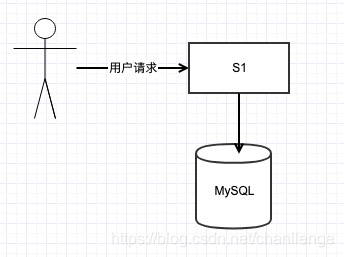
高峰達到了10000/s啊,去做分庫分表,申請資源又有些浪費,因為在流量低谷時,只有幾十的qps,這時候使用訊息佇列就比較合適了。這裡只是舉簡單的例子,實際的系統處理起來肯定沒這麼簡單了。延遲太多使用者可要被搶走了!
訊息佇列有什麼優缺點
假如你說了這些,面試官心裡應該默默讚許,小夥子不錯嘛,優點基本都答出來了,那再問問你缺點。
萬事都有兩面性,有好就有壞。缺點大致有以下幾個:
可用性降低
服務中引入的依賴越多,引入的外部元件越多,維護的成本就越高,本來你只是S1呼叫S2、S3服務即可。引入了訊息佇列,訊息佇列打入失敗怎麼辦?訊息佇列掛了怎麼辦?怎麼保證訊息佇列的穩定性?這些就需要後面再說了!
複雜度變高
訊息重複消費怎麼辦?訊息丟失怎麼辦?如果要求消費的訊息有序又怎麼搞?本來在一個S1裡,這些問題都好解決,加了一個MQ,這下麻煩大了!
一致性
使用者請求S1返回成功,是真的成功了嗎?當然不是,這只是代表打入MQ成功了啊。但這是如果消費MQ的某個服務掛了怎麼辦?你怎麼監控,怎麼處理資料一致性問題,真是搞的頭都大了。
引入訊息佇列,有很多優點,但同時也帶來了很多缺點,但是為了提高系統的響應速度,高併發情況下還是要用的。
訊息佇列的選型
缺點說的也頭頭是道嘛,面試官已經悄悄的在背後豎起了大拇指,小夥子不錯,有一定的架構思維,之道引入一個元件的優缺點。並不是只知其一不知其二,只知道幹活的人!
那你們關於訊息佇列是怎麼選型的呢?
這就要從各個訊息佇列的一些特性說起了。
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
|---|---|---|---|---|
| 單機吞吐量 | 萬級,比 RocketMQ、Kafka 低一個數量級 | 同 ActiveMQ | 10 萬級,支撐高吞吐 | 10 萬級,高吞吐,一般配合大資料類的系統來進行實時資料計算、日誌採集等場景 |
| topic 數量對吞吐量的影響 | topic 可以達到幾百/幾千的級別,吞吐量會有較小幅度的下降,這是 RocketMQ 的一大優勢,在同等機器下,可以支撐大量的 topic | topic 從幾十到幾百個時候,吞吐量會大幅度下降,在同等機器下,Kafka 儘量保證 topic 數量不要過多,如果要支撐大規模的 topic,需要增加更多的機器資源 | ||
| 時效性 | ms 級 | 微秒級,這是 RabbitMQ 的一大特點,延遲最低 | ms 級 | 延遲在 ms 級以內 |
| 可用性 | 高,基於主從架構實現高可用 | 同 ActiveMQ | 非常高,分散式架構 | 非常高,分散式,一個數據多個副本,少數機器宕機,不會丟失資料,不會導致不可用 |
| 訊息可靠性 | 有較低的概率丟失資料 | 基本不丟 | 經過引數優化配置,可以做到 0 丟失 | 同 RocketMQ |
| 功能支援 | MQ 領域的功能極其完備 | 基於 erlang 開發,併發能力很強,效能極好,延時很低 | MQ 功能較為完善,還是分散式的,擴充套件性好 | 功能較為簡單,主要支援簡單的 MQ 功能,在大資料領域的實時計算以及日誌採集被大規模使用 |
對比之後:
一般來說,現在選擇RocketMQ,阿里出品,也已經捐獻給Apache,社群還算活躍。單機吞吐量及可用性也都可以滿足需求,後續分散式擴充套件功能支援也較好。
如果資料量非常大,偏向於大資料領域的實時計算及日誌採集處理,且要求高可用,Kafka絕對是不二選擇!
重複消費你們是怎麼解決的?
面試官又丟給你一個問題,重複消費,其實也就是訊息冪等處理的問題?
首先什麼情況會造成重複消費呢?
Kafka的consumer消費有個offset的概念,consumer消費資料之後,定期提交offset,如果提交過程中,系統無故宕機或重啟或網路原因,提交失敗,那consumer就還會從上一個offset開始消費資料,這就是重複消費。
重複消費是訊息佇列中非常常見的問題,只要保證冪等處理就可以,比如你可以用Redis或MySQL記錄下以處理訊息的唯一id,碰到重複處理的訊息,直接忽略即可!
小夥子,你知道的太多了,我都想讓你明天直接來上班了,但是不行,還是得讓下一位面試官來做做面試的樣子!