
一文徹底搞定譜聚類
Clustering 聚類
譜聚類
上文我們引入了是聚類,並介紹了第一種聚類演算法K-means。今天,我們來介紹一種流行的聚類演算法——譜聚類(Spectral Clustering),它的實現簡單,而且效果往往好於傳統的聚類演算法,如k-means,但是其背後的原理涉及了很多重要而複雜的知識,如圖論,矩陣分析等。別擔心,今天小編就帶你一舉攻克這些難關,拿下譜聚類演算法。
Q:什麼是譜聚類?
A:譜聚類是最流行的聚類演算法之一,它的實現簡單,而且效果往往勝過傳統的聚類演算法,如K-means。它的主要思想是把所有資料看作空間中的點,這些點之間用帶權重的邊相連,距離較遠的點之間的邊權重較低,距離較近的點之間邊權重較高,通過對所有資料點和邊組成的圖進行切圖,讓切圖後不同子圖間邊權重和儘可能低,而子圖內邊權重和儘可能高來達到聚類的目的。
接下來我們先介紹圖的基礎知識以及圖拉普拉斯,然後引入譜聚類演算法,最後從圖分割的角度來解釋譜聚類演算法。
圖的概念
對於一個圖G,我們通常用G(V,E)來表示它,其中V代表資料集合中的點{v1,v2,...vn},E代表邊集(可以有邊相連,也可以沒有)。在接下來的內容中我們用到的都是帶權重圖(即兩個頂點vi和vj之間的連邊帶有非負權重wij>0).由此可以得到一個圖的加權鄰接矩陣W=(Wij)i,j=1,...n。如果Wij=0代表兩個頂點之間無邊相連。無向圖G中wij=wji,所以權重矩陣是對稱的。
對於圖中的任意一個點vi,定義它的度為與它相連的所有邊的權重之和,即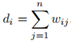
給定點的一個子集A屬於V,定義A的補集為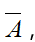 A的指示向量為
A的指示向量為 如果fi=1,則頂點vi在子集A中,否則為0。為了方便,在下文中,我們使用
如果fi=1,則頂點vi在子集A中,否則為0。為了方便,在下文中,我們使用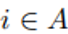 來表示頂點i在集合A中。對於兩個不相交子集A,B屬於V,我們定義
來表示頂點i在集合A中。對於兩個不相交子集A,B屬於V,我們定義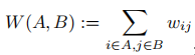 表示兩個子集之間的權重和。
表示兩個子集之間的權重和。
有兩種度量V中子集A大小的方法:|A|表示A中頂點的個數,vol(A)表示A中頂點的度的和。
相似圖
思考我們構建相似性圖的目的是什麼?是為了對點之間的區域性鄰域關係建模。那麼根據我們所關注的鄰域關係,相似性圖的定義也可以不同,以下提到的圖都經常在譜聚類中使用:
ε鄰域圖:將所有距離小於ε的點相連,由於有邊相連的點之間都差不多,加權邊不會包含關於圖中資料點更多的關係,因此,這種圖常常是無權重的;
k近鄰圖:將vi與它前k近的頂點相連,要注意,這種定義的圖是有向圖,因為k近鄰關係並不是對稱的(A是B的k近鄰,而B不一定是A的k近鄰)。我們可以通過兩種方式將它變成無向圖:一種是隻要A是B的k近鄰,AB之間就會連一條邊;另一種是必須同時滿足A,B是彼此的k近鄰,才能在AB之間連一條邊。在構建好圖之後,在根據點的相似性給邊賦權重;
全連線圖:任意兩點之間都連一條邊,並根據兩點之間的相似性給邊賦權重。由於圖必須能代表區域性鄰居關係,所以使用的相似性度量方法必須能對這種關係建模。比如,高斯相似性方程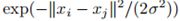 ,其中引數σ控制鄰域的寬度(作用類似ε鄰域圖中的ε引數)。
,其中引數σ控制鄰域的寬度(作用類似ε鄰域圖中的ε引數)。
圖拉普拉斯矩陣及其基本性質
圖拉普拉斯矩陣是譜聚類的主要工具,對這些矩陣的研究有一個專門的領域,叫做譜圖理論,感興趣的同學可以去了解下。在這章中我們定義不同的圖拉普拉斯並介紹它們最重要的性質。
在接下來的介紹中,我們定義的圖G是無向的,帶權重的(權重矩陣為W),我們假定所有特徵向量都是標準化的(如常向量C和aC是一樣的),特徵值是有序且可重複的,如果提到了前k個特徵向量,就意味著這k個特徵向量對應k個最小的特徵值。D代表上文提到的度矩陣,W代表權重矩陣。
非規範化圖拉普拉斯矩陣:
非規範化圖拉普拉斯矩陣定義為L:D-W,它具有如下重要特性:
1. 對於任意特徵向量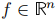 ,有:
,有:
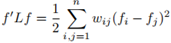 ;
;
證明:
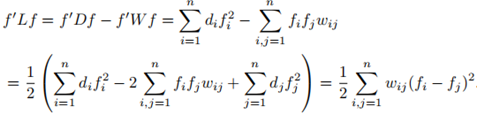
2. L是對稱半正定的;
證明:D,W都是對稱的,且特性1的證明表明L是半正定的;
3. L的最小特徵值是0,對應的特徵向量是單位向量;
4. L有n個非負的實值特徵向量:
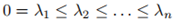
證明:由前三個特性可以直接得出;
注意非規範化圖拉普拉斯矩陣以及它的特徵向量,特徵值可以被用在描述圖的很多特性,其中在譜聚類中的一個重要性質如下:
連通分量數與L的普:G是一個非負權重無向圖,那麼L的特徵值0的重數k就等於圖中聯通分量A1,...Ak的個數,特徵值0的特徵空間由這些聯通分量的指示向量 表示;
表示;
證明:以k=1為例,代表這是一個連通圖,假設特徵值0對應的特徵向量為f,則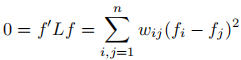 ,由於權重w是非負的,要使和為0當且僅當每一項都為0。因此,如果兩個頂點vi和vj有邊相連(wij>0),fi必須等於fj,從這裡可以看出如果圖中的頂點可以有一條路徑相連,那麼f必須是常向量。此外,由於無向圖中連通分量的所有頂點都可以通過一條路徑相連,所以f在整個連通分量上必須是常數。因此在只有一個連通分量的圖中,只有一個常向量作為0的特徵向量(作為唯一一個聯通部分的指示向量)。
,由於權重w是非負的,要使和為0當且僅當每一項都為0。因此,如果兩個頂點vi和vj有邊相連(wij>0),fi必須等於fj,從這裡可以看出如果圖中的頂點可以有一條路徑相連,那麼f必須是常向量。此外,由於無向圖中連通分量的所有頂點都可以通過一條路徑相連,所以f在整個連通分量上必須是常數。因此在只有一個連通分量的圖中,只有一個常向量作為0的特徵向量(作為唯一一個聯通部分的指示向量)。
現在考慮k大於1的場景,不失一般性,我們假設頂點是按照它們所屬的連通分量排序的,在這種情形下,鄰接權重矩陣W可以寫成分塊對角矩陣的形式,同樣,L可以寫作
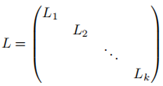
注意,每一個塊Li 也是一個圖拉普拉斯矩陣,分別對應圖的第i個連通分量,L的普就由Li的普組合而成,而且L對應的特徵向量就是Li的特徵向量。由於Li一個連通圖的圖拉普拉斯矩陣,而每一個Li有重數為1的特徵值0,也就是對應第i個聯通子圖的常向量。
規範化圖拉普拉斯矩陣
規範化圖拉普拉斯矩陣有如下兩種定義:

我們先來介紹它們的性質:
1. 對任意特徵向量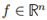 ,我們有:
,我們有:
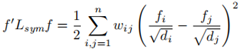 ;
;
2. λ是Lrw的特徵向量u的特徵值 當且僅當 λ是Lsym的特徵向量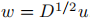 的特徵值;
的特徵值;
3. λ是Lrw的特徵向量u的特徵值當且僅當λ和u滿足Lu=λDu;
4. 0是Lrw的常數特徵向量 的特徵值,那麼0也是Lsym的特徵向量
的特徵值,那麼0也是Lsym的特徵向量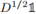 的特徵值。;
的特徵值。;
5. Lsym和Lrw是半正定的且有n個非負的實特徵值;
與非規範化圖拉普拉斯矩陣相同,Lsym和Lrw的0特徵值的重數k就等於圖中聯通分量的個數,證明與上面類似,不再贅述。
譜聚類演算法
現在我們來介紹最常見的譜聚類演算法。
解釋:首先構建相似性圖,並用W表示權重鄰接矩陣,構建度矩陣D,求出拉普拉斯矩陣L;計算L的前m個特徵向量,以這m個特徵向量作為列組成n*m的矩陣U,其中每一行作為一個m維的樣本,共n個,對這n個行向量進行kmeans聚類。
對於規範化的譜聚類有兩種不同的版本,依賴於兩種標準化圖拉普拉斯矩陣。
第一種是:

注意這裡使用的是generalized eigenvectors(廣義特徵向量),即矩陣Lrw對應的特徵向量,所以這一演算法針對的是標準化的拉普拉斯矩陣Lrw。
下一個演算法也是標準化的譜聚類,不過用的是Lsym,該演算法介紹了一種額外的行標準化步驟:

上面三種演算法的步驟其實都差不多,只不過是使用的拉普拉斯矩陣有差別。在演算法中,主要的工作就是將x抽象表徵為k維的資料點(降維),接下來我們將揭曉為什麼這樣做能提高聚類的效果。我們將從圖分割的角度來介紹譜聚類的工作原理。
圖切分的觀點
聚類演算法的思想就是根據資料點之間的相似性將它們劃分到不同組。當我們的資料以相似性圖的形式給出時,聚類問題又可以這樣解釋:我們想要找到圖的一種劃分,不同組點的邊之間有很低的權重而同一個組中點之間的邊有較高的權重。在本節中,我們將介紹如何將譜聚類問題近似於圖的劃分問題。
給定一個相似性圖,鄰接權重矩陣W,最簡單直接的方法來建立一個圖的分割就是解決最小割問題。前面我們已經提到過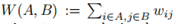 和A的補集的概念。給定子集個數k,最小割方法就是選擇一種劃分A1,...,Ak使得
和A的補集的概念。給定子集個數k,最小割方法就是選擇一種劃分A1,...,Ak使得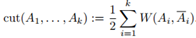 最小。特別是對k=2,最小割問題相對是一個簡單的問題,可以被有效地解決。然而在實際中,最小割的解並不能很好地將圖劃分,因為它只是簡單地將一個獨立的點從剩餘的圖中劃分出來,這顯然不符合聚類的需求。解決這種問題的一種方法是必須保證子集A1,...,Ak足夠大,實現這一限制的最常見的目標函式有兩種:RatioCut和Ncut。RatioCut用子集A中點的個數表示A的大小,Ncut用子集A中邊的權重和來度量A的大小,它們的定義分別如下:
最小。特別是對k=2,最小割問題相對是一個簡單的問題,可以被有效地解決。然而在實際中,最小割的解並不能很好地將圖劃分,因為它只是簡單地將一個獨立的點從剩餘的圖中劃分出來,這顯然不符合聚類的需求。解決這種問題的一種方法是必須保證子集A1,...,Ak足夠大,實現這一限制的最常見的目標函式有兩種:RatioCut和Ncut。RatioCut用子集A中點的個數表示A的大小,Ncut用子集A中邊的權重和來度量A的大小,它們的定義分別如下:
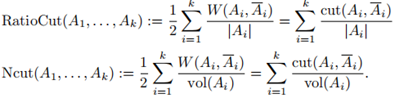
假如簇Ai不是特別小,兩個目標函式的值都會有較小的值,因此這兩種函式都試圖達到聚類的平衡,但是,引入這一“平衡”條件使得之前簡單的最小割問題變成了np難問題。譜聚類就是解決這一問題的一種鬆弛版本,我們將看到鬆弛Ncut將會導致規範化譜聚類,而鬆弛RatioCut將導致非標準化譜聚類。
從RatioCut切圖的角度解釋譜聚類演算法
我們先討論k=2的情形,我們的目標函式是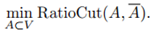 ,首先重寫這個問題。給定子集A,我們定義向量
,首先重寫這個問題。給定子集A,我們定義向量 ,其中
,其中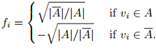
現在RatioCut目標函式可以寫作非規範化圖拉普拉斯矩陣的形式:
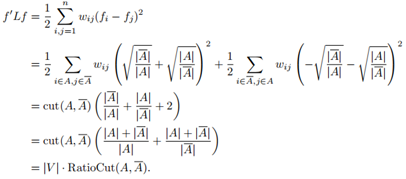
而,
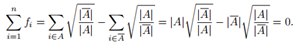
最後,由於f滿足
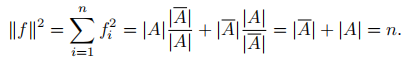
所以,優化問題重寫為:
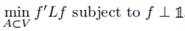
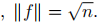
這是一個離散優化問題因為僅允許解向量f中的每一個值只能是兩個特殊值,仍是Np難問題。最常用的鬆弛就是將離散條件改為fi可以取任意實數,鬆弛後的目標函式為
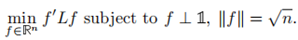
根據Rayleigh-Ritz理論,問題的解f為拉普拉斯矩陣L的第二小的特徵值所對應的特徵向量(最小的特徵值為0,對應常向量)。所以我們可以通過求L的第二特徵向量來解決RatioCut問題。然而我們得到的f是實值向量,要把它轉化為離散的指示向量,最簡單的方式就是使用sign,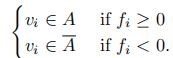
推廣到k>2的場景,將V劃分成k個子集A1,...Ak,我們定義k個指示向量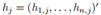 ,其中
,其中 代表每個點的劃分情況。定義矩陣
代表每個點的劃分情況。定義矩陣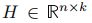 作為以k個指示向量為列向量的矩陣,顯然H中的列相互正交
作為以k個指示向量為列向量的矩陣,顯然H中的列相互正交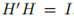 ,於上面的計算類似,我們可以得到
,於上面的計算類似,我們可以得到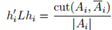 ,進而
,進而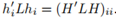 ,然後得到RatioCut問題的定義:
,然後得到RatioCut問題的定義: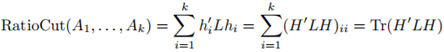
Tr表示矩陣的跡,所以最小化RatioCut問題可以寫作
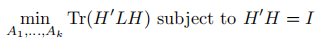
同樣的,我們執行H中的取值為任意實數,鬆弛後的問題為:
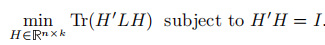
這是跡極小化問題的標準形式,同樣根據Rayleigh-Ritz理論,問題的解就是選擇包含L的前k個特徵向量作為列而組成的H矩陣。其實矩陣H就是上面非標準化譜聚類演算法中提到的矩陣U。然後將實值矩陣轉化成離散的形式。最後用kmeans對U的每一行進行聚類。
從NCut的角度解釋譜聚類演算法:
與在RatioCut中用到的相似的技術同樣可以用到規範化譜聚類作為最小化Ncut的鬆弛。當k=2時我們定義聚類的指示向量f中的每個元素為
和上面類似我們可以檢查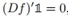 ,
,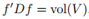 ,以及
,以及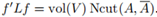 因此,可以重寫最小化Ncut問題為
因此,可以重寫最小化Ncut問題為
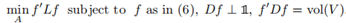
然後對問題進行鬆弛:
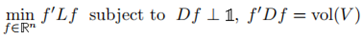
定義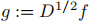 ,有
,有

其中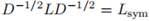 ,
,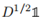 是Lsym的第一特徵向量,vol(V)是常數。因此,上述目標函式符合Rayleigh-Ritz理論,最優解g就是Lrw的第二特徵向量。
是Lsym的第一特徵向量,vol(V)是常數。因此,上述目標函式符合Rayleigh-Ritz理論,最優解g就是Lrw的第二特徵向量。
推廣到k>2的場景,我們定義指示向量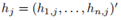 ,且
,且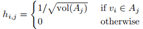
定義H為包含k個指示向量(作為列)的矩陣。顯然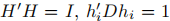 ,
,
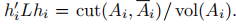
那麼最小化Ncut問題可以寫作
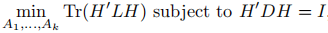 ,鬆弛後為
,鬆弛後為
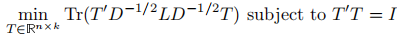
這又是一個標準的跡最小化問題,問題的解T是包含Lsym的前k個特徵向量為列向量的矩陣。再將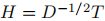 代入,可以發現H包含矩陣Lrw的前k個特徵向量。
代入,可以發現H包含矩陣Lrw的前k個特徵向量。
譜聚類演算法總結
譜聚類的優點:
1. 對於處理稀疏資料的聚類效果很有效;
2. 使用了降維,在處理高維資料聚類時比傳統聚類好;
3. 當聚類的類別個數較小的時候,譜聚類的效果會很好;
4. 譜聚類演算法建立在譜圖理論上,與傳統的聚類演算法相比,具有能在任意形狀的樣本空間上聚類且收斂於全域性最優解。
譜聚類的缺點:
1. 譜聚類對相似圖和聚類引數的選擇非常敏感;
2. 譜聚類適用於均衡分類問題,即簇之間點的個數差別不大,對於簇之間點的個數相差懸殊的問題不適用。

掃碼關注
獲取有趣的演算法知識


&n