
【集合系列】- 深入淺出分析LinkedHashMap
一、摘要
在集合系列的第一章,咱們瞭解到,Map的實現類有HashMap、LinkedHashMap、TreeMap、IdentityHashMap、WeakHashMap、Hashtable、Properties等等。
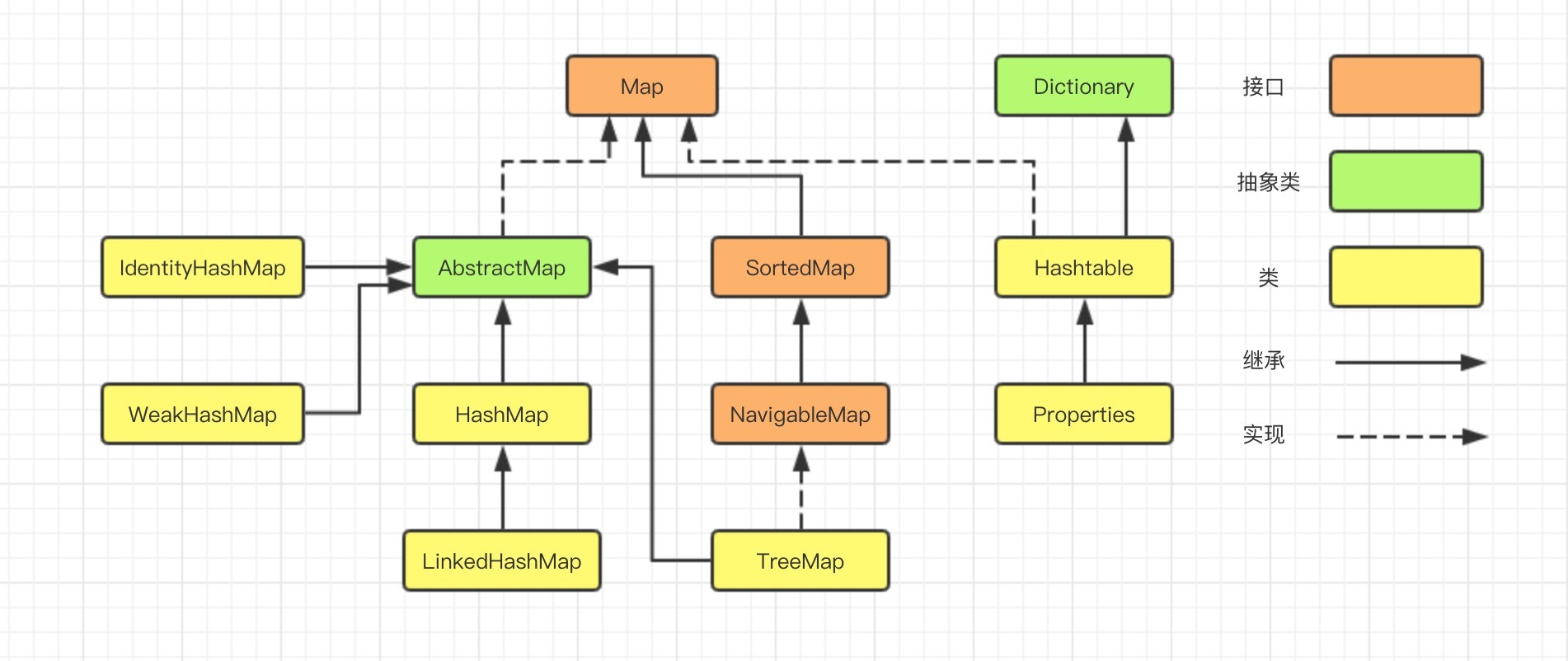
本文主要從資料結構和演算法層面,探討LinkedHashMap的實現。
二、簡介
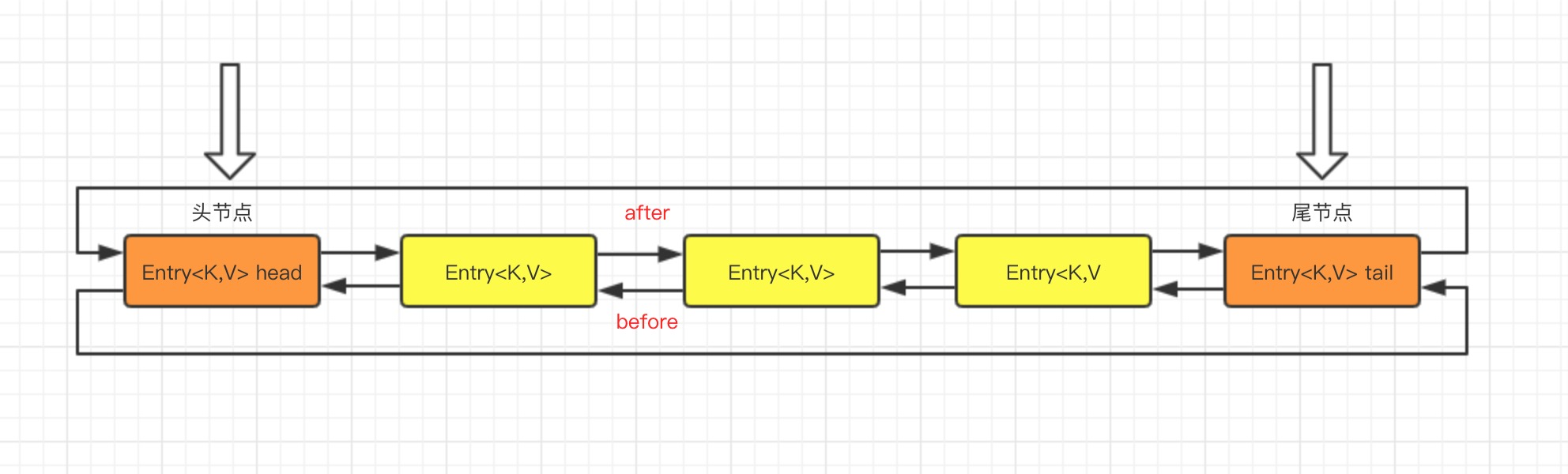
LinkedHashMap可以認為是HashMap+LinkedList,它既使用HashMap操作資料結構,又使用LinkedList維護插入元素的先後順序,內部採用雙向連結串列(doubly-linked list)的形式將所有元素( entry )連線起來。
LinkedHashMap繼承了HashMap,允許放入key為null的元素,也允許插入value為null的元素。從名字上可以看出該容器是LinkedList和HashMap的混合體,也就是說它同時滿足HashMap和LinkedList的某些特性,可將LinkedHashMap看作採用Linked list增強的HashMap。
開啟 LinkedHashMap 原始碼,可以看到主要三個核心屬性:
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V>{ /**雙向連結串列的頭節點*/ transient LinkedHashMap.Entry<K,V> head; /**雙向連結串列的尾節點*/ transient LinkedHashMap.Entry<K,V> tail; /** * 1、如果accessOrder為true的話,則會把訪問過的元素放在連結串列後面,放置順序是訪問的順序 * 2、如果accessOrder為false的話,則按插入順序來遍歷 */ final boolean accessOrder; }
LinkedHashMap 在初始化階段,預設按插入順序來遍歷
public LinkedHashMap() {
super();
accessOrder = false;
}LinkedHashMap 採用的 Hash 演算法和 HashMap 相同,不同的是,它重新定義了陣列中儲存的元素Entry,該Entry除了儲存當前物件的引用外,還儲存了其上一個元素before和下一個元素after的引用,從而在雜湊表的基礎上又構成了雙向連結列表。
原始碼如下:
static class Entry<K,V> extends HashMap.Node<K,V> { //before指的是連結串列前驅節點,after指的是連結串列後驅節點 Entry<K,V> before, after; Entry(int hash, K key, V value, Node<K,V> next) { super(hash, key, value, next); } }
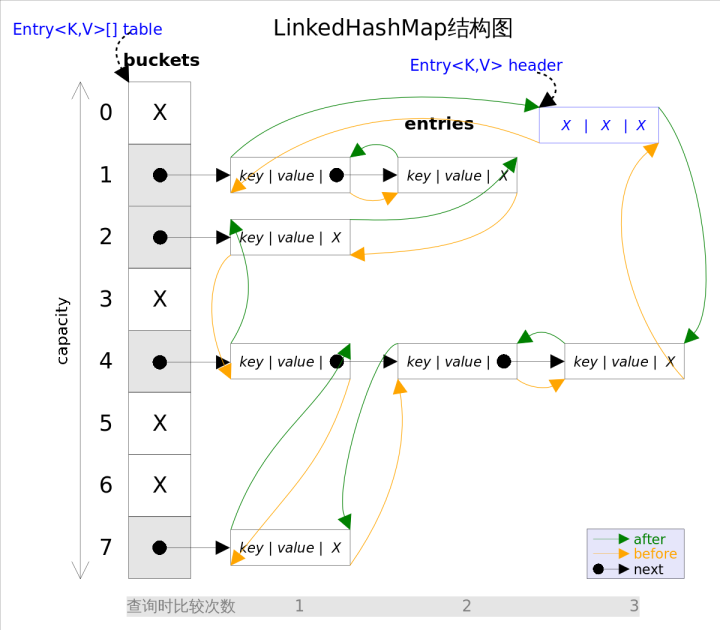
可以直觀的看出,雙向連結串列頭部插入的資料為連結串列的入口,迭代器遍歷方向是從連結串列的頭部開始到連結串列尾部結束。
除了可以保迭代歷順序,這種結構還有一個好處:迭代LinkedHashMap時不需要像HashMap那樣遍歷整個table,而只需要直接遍歷header指向的雙向連結串列即可,也就是說LinkedHashMap的迭代時間就只跟entry的個數相關,而跟table的大小無關。
三、常用方法介紹
3.1、get方法
get方法根據指定的key值返回對應的value。該方法跟HashMap.get()方法的流程幾乎完全一樣,預設按照插入順序遍歷。
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}如果accessOrder為true的話,會把訪問過的元素放在連結串列後面,放置順序是訪問的順序
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}測試用例:
public static void main(String[] args) {
//accessOrder預設為false
Map<String, String> accessOrderFalse = new LinkedHashMap<>();
accessOrderFalse.put("1","1");
accessOrderFalse.put("2","2");
accessOrderFalse.put("3","3");
accessOrderFalse.put("4","4");
System.out.println("acessOrderFalse:"+accessOrderFalse.toString());
//accessOrder設定為true
Map<String, String> accessOrderTrue = new LinkedHashMap<>(16, 0.75f, true);
accessOrderTrue.put("1","1");
accessOrderTrue.put("2","2");
accessOrderTrue.put("3","3");
accessOrderTrue.put("4","4");
accessOrderTrue.get("2");//獲取鍵2
accessOrderTrue.get("3");//獲取鍵3
System.out.println("accessOrderTrue:"+accessOrderTrue.toString());
}輸出結果:
acessOrderFalse:{1=1, 2=2, 3=3, 4=4}
accessOrderTrue:{1=1, 4=4, 2=2, 3=3}3.2、put方法
put(K key, V value)方法是將指定的key, value對新增到map裡。該方法首先會呼叫HashMap的插入方法,同樣對map做一次查詢,看是否包含該元素,如果已經包含則直接返回,查詢過程類似於get()方法;如果沒有找到,將元素插入集合。
/**HashMap 中實現*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
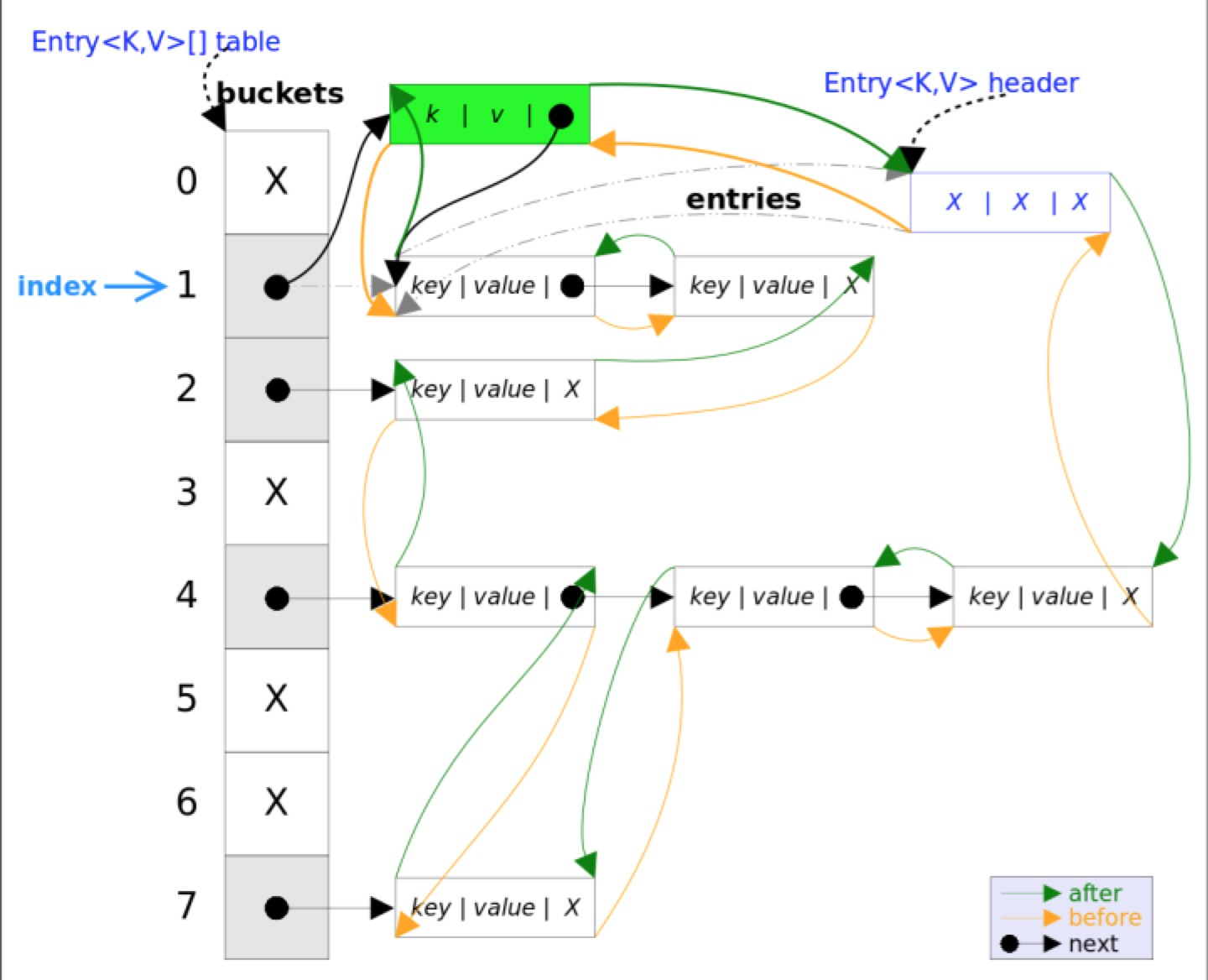
}LinkedHashMap 中覆寫的方法
// LinkedHashMap 中覆寫
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
// 將 Entry 接在雙向連結串列的尾部
linkNodeLast(p);
return p;
}
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
// last 為 null,表明連結串列還未建立
if (last == null)
head = p;
else {
// 將新節點 p 接在連結串列尾部
p.before = last;
last.after = p;
}
}
3.3、remove方法
remove(Object key)的作用是刪除key值對應的entry,該方法實現邏輯主要以HashMap為主,首先找到key值對應的entry,然後刪除該entry(修改連結串列的相應引用),查詢過程跟get()方法類似,最後會呼叫 LinkedHashMap 中覆寫的方法,將其刪除!
/**HashMap 中實現*/
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
if (p instanceof TreeNode) {...}
else {
// 遍歷單鏈表,尋找要刪除的節點,並賦值給 node 變數
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode) {...}
// 將要刪除的節點從單鏈表中移除
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node); // 呼叫刪除回撥方法進行後續操作
return node;
}
}
return null;
}LinkedHashMap 中覆寫的 afterNodeRemoval 方法
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
// 將 p 節點的前驅後後繼引用置空
p.before = p.after = null;
// b 為 null,表明 p 是頭節點
if (b == null)
head = a;
else
b.after = a;
// a 為 null,表明 p 是尾節點
if (a == null)
tail = b;
else
a.before = b;
}
四、總結
LinkedHashMap 繼承自 HashMap,所有大部分功能特性基本相同,二者唯一的區別是 LinkedHashMap 在HashMap的基礎上,採用雙向連結串列(doubly-linked list)的形式將所有 entry 連線起來,這樣是為保證元素的迭代順序跟插入順序相同。
主體部分跟HashMap完全一樣,多了header指向雙向連結串列的頭部,tail指向雙向連結串列的尾部,預設雙向連結串列的迭代順序就是entry的插入順序。
五、參考
1、JDK1.7&JDK1.8 原始碼
2、部落格園 - CarpenterLee - Java集合框架原始碼剖析LinkedHashMap
作者:炸雞可樂
出處:www.pzblog.cn