
【集合系列】- 深入淺出的分析IdentityHashMap
一、摘要
在集合系列的第一章,咱們瞭解到,Map 的實現類有 HashMap、LinkedHashMap、TreeMap、IdentityHashMap、WeakHashMap、Hashtable、Properties等等。

應該有很多人不知道 IdentityHashMap 的存在,其中不乏工作很多年的 Java 開發者,本文主要從資料結構和演算法層面,探討 IdentityHashMap 的實現。
二、簡介
IdentityHashMap 的資料結構很簡單,底層實際就是一個 Object 陣列,但是在儲存上並沒有使用連結串列來儲存,而是將 K 和 V 都存放在 Object 陣列上。

當新增元素的時候,會根據 Key 計算得到雜湊位置,如果發現該位置上已經有改元素,直接進行新值替換;如果沒有,直接進行存放。當元素個數達到一定閾值時,Object 陣列會自動進行擴容處理。
開啟 IdentityHashMap 的原始碼,可以看到 IdentityHashMap 繼承了AbstractMap 抽象類,實現了Map介面、可序列化介面、可克隆介面。
public class IdentityHashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, java.io.Serializable, Cloneable { /**預設容量大小*/ private static final int DEFAULT_CAPACITY = 32; /**最小容量*/ private static final int MINIMUM_CAPACITY = 4; /**最大容量*/ private static final int MAXIMUM_CAPACITY = 1 << 29; /**用於儲存實際元素的表*/ transient Object[] table; /**陣列大小*/ int size; /**對Map進行結構性修改的次數*/ transient int modCount; /**key為null所對應的值*/ static final Object NULL_KEY = new Object(); ...... }
可以看到類的底層,使用了一個 Object 陣列來存放元素;在物件初始化時,IdentityHashMap 容量大小為64;
public IdentityHashMap() {
//呼叫初始化方法
init(DEFAULT_CAPACITY);
}private void init(int initCapacity) {
//陣列大小預設為初始化容量的2倍
table = new Object[2 * initCapacity];
}三、常用方法介紹
3.1、put方法
put 方法是將指定的 key, value 對新增到 map 裡。該方法首先會對map做一次查詢,通過==
key,如果有,則將舊value返回,將新value覆蓋舊value;如果沒有,直接插入,陣列長度+1,返回null。
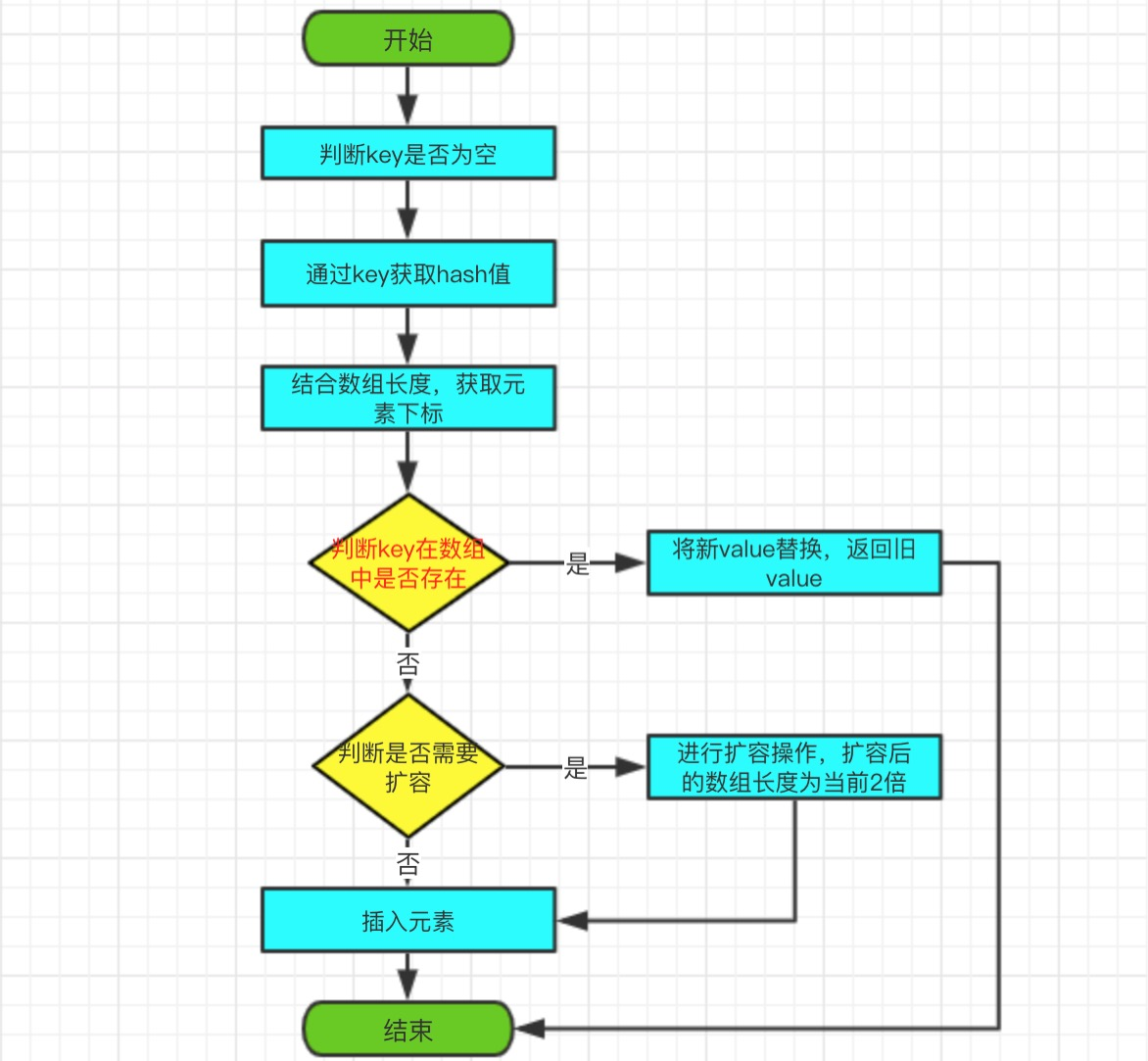
原始碼如下:
public V put(K key, V value) {
//判斷key是否為空,如果為空,初始化一個Object為key
final Object k = maskNull(key);
retryAfterResize: for (;;) {
final Object[] tab = table;
final int len = tab.length;
//通過key、length獲取陣列小編
int i = hash(k, len);
//迴圈遍歷是否存在指定的key
for (Object item; (item = tab[i]) != null;
i = nextKeyIndex(i, len)) {
//通過==判斷,是否陣列中是否存在key
if (item == k) {
V oldValue = (V) tab[i + 1];
//新value覆蓋舊value
tab[i + 1] = value;
//返回舊value
return oldValue;
}
}
//陣列長度 +1
final int s = size + 1;
//判斷是否需要擴容
if (s + (s << 1) > len && resize(len))
continue retryAfterResize;
//更新修改次數
modCount++;
//將k加入陣列
tab[i] = k;
//將value加入陣列
tab[i + 1] = value;
size = s;
return null;
}
}maskNull 函式,判斷 key 是否為空
private static Object maskNull(Object key) {
return (key == null ? NULL_KEY : key);
}hash 函式,通過 key 獲取 hash 值,結合陣列長度通過位運算獲取陣列雜湊下標
private static int hash(Object x, int length) {
int h = System.identityHashCode(x);
// Multiply by -127, and left-shift to use least bit as part of hash
return ((h << 1) - (h << 8)) & (length - 1);
}nextKeyIndex 函式,通過 hash 函式計算得到的陣列雜湊下標,進行加2;因為一個 key、value 都存放在陣列中,所以一個 map 物件佔用兩個陣列下標,所以加2。
private static int nextKeyIndex(int i, int len) {
return (i + 2 < len ? i + 2 : 0);
}resize 函式,通過陣列長度,進行擴容處理,擴容之後的長度為當前長度的2倍
private boolean resize(int newCapacity) {
//擴容後的陣列長度,為當前陣列長度的2倍
int newLength = newCapacity * 2;
Object[] oldTable = table;
int oldLength = oldTable.length;
if (oldLength == 2 * MAXIMUM_CAPACITY) { // can't expand any further
if (size == MAXIMUM_CAPACITY - 1)
throw new IllegalStateException("Capacity exhausted.");
return false;
}
if (oldLength >= newLength)
return false;
Object[] newTable = new Object[newLength];
//將舊陣列內容轉移到新陣列
for (int j = 0; j < oldLength; j += 2) {
Object key = oldTable[j];
if (key != null) {
Object value = oldTable[j+1];
oldTable[j] = null;
oldTable[j+1] = null;
int i = hash(key, newLength);
while (newTable[i] != null)
i = nextKeyIndex(i, newLength);
newTable[i] = key;
newTable[i + 1] = value;
}
}
table = newTable;
return true;
}3.2、get方法
get 方法根據指定的 key 值返回對應的 value。同樣的,該方法會迴圈遍歷陣列,通過==判斷是否存在key,如果有,直接返回value,因為 key、value 是相鄰的儲存在陣列中,所以直接在當前陣列下標+1,即可獲取 value;如果沒有找到,直接返回null。
值得注意的地方是,在迴圈遍歷中,是通過==判斷當前元素是否與key相同,如果相同,則返回value。咱們都知道,在 java 中,==對於物件型別引數,判斷的是引用地址,確切的說,是堆記憶體地址,所以,這裡判斷的是key的引用地址是否相同,如果相同,則返回對應的 value;如果不相同,則返回null。
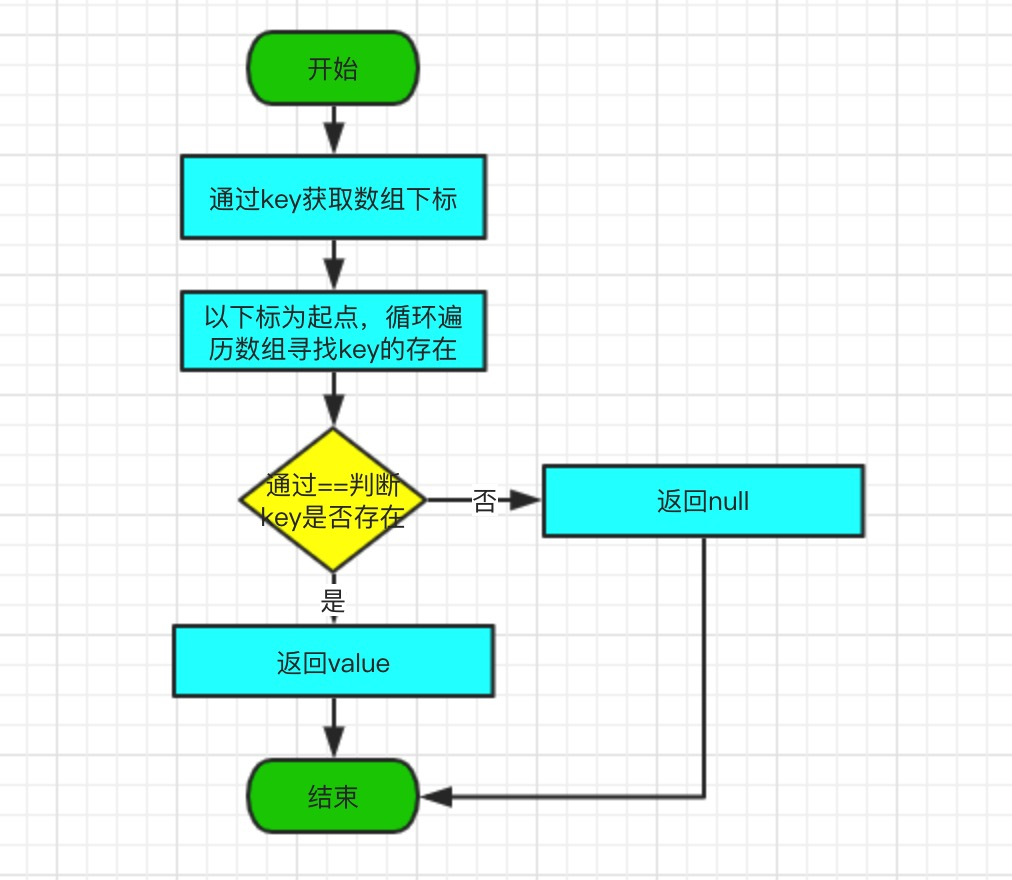
原始碼如下:
public V get(Object key) {
Object k = maskNull(key);
Object[] tab = table;
int len = tab.length;
int i = hash(k, len);
//迴圈遍歷陣列,直到找到key或者,陣列為空為值
while (true) {
Object item = tab[i];
//通過==判斷,當前陣列元素與key相同
if (item == k)
return (V) tab[i + 1];
//陣列為空
if (item == null)
return null;
i = nextKeyIndex(i, len);
}
}3.3、remove方法
remove 的作用是通過 key 刪除對應的元素。該方法會迴圈遍歷陣列,通過==判斷是否存在key,如果有,直接將key、value設定為null,對陣列進行重新排列,返回舊 value。
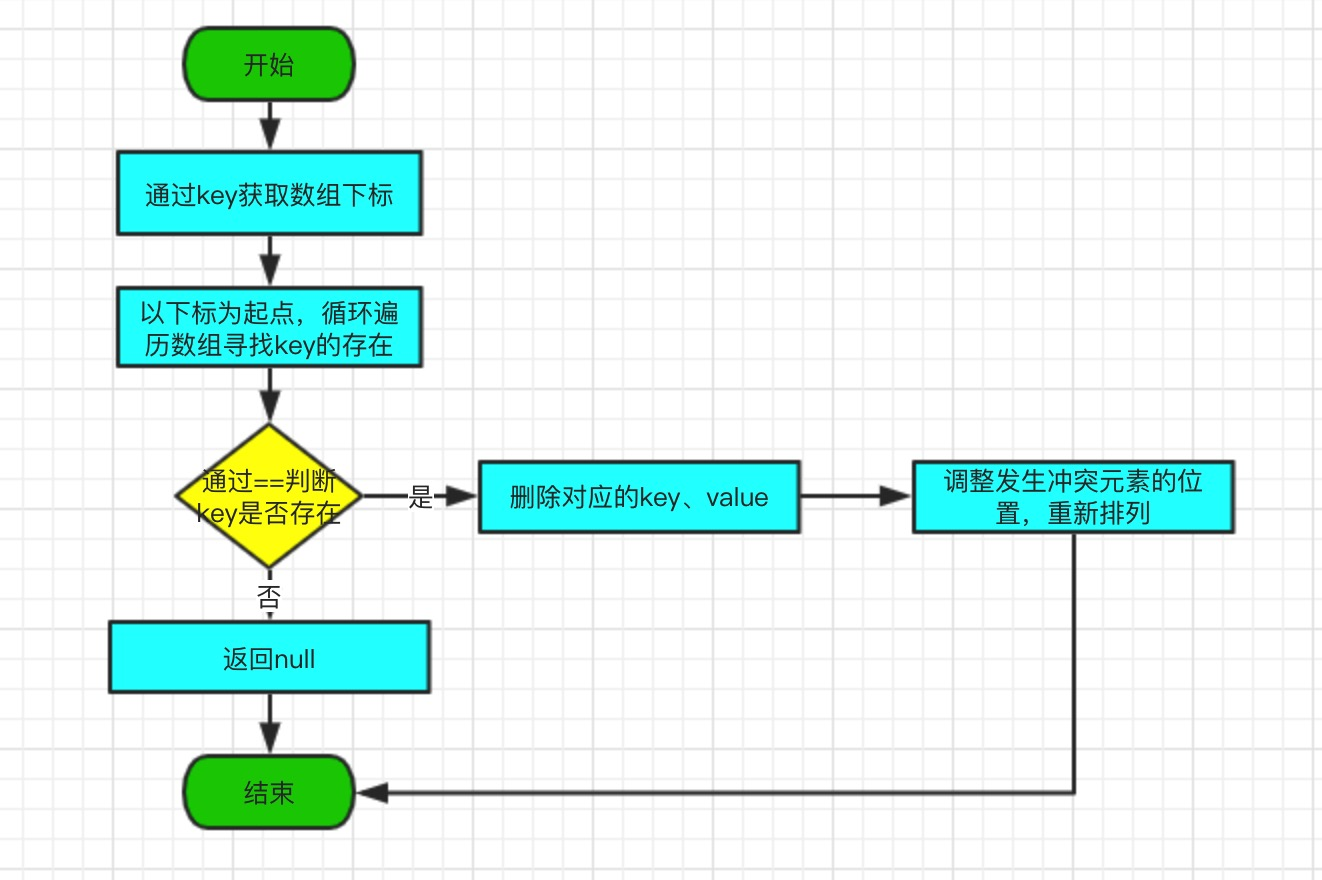
原始碼如下:
public V remove(Object key) {
Object k = maskNull(key);
Object[] tab = table;
int len = tab.length;
int i = hash(k, len);
while (true) {
Object item = tab[i];
if (item == k) {
modCount++;
//陣列長度減1
size--;
V oldValue = (V) tab[i + 1];
//將key、value設定為null
tab[i + 1] = null;
tab[i] = null;
//刪除該元素後,需要把原來有衝突往後移的元素移到前面來
closeDeletion(i);
return oldValue;
}
if (item == null)
return null;
i = nextKeyIndex(i, len);
}
}closeDeletion 函式,刪除該元素後,需要把原來有衝突往後移的元素移到前面來,對陣列進行重寫排列;
private void closeDeletion(int d) {
// Adapted from Knuth Section 6.4 Algorithm R
Object[] tab = table;
int len = tab.length;
Object item;
for (int i = nextKeyIndex(d, len); (item = tab[i]) != null;
i = nextKeyIndex(i, len) ) {
int r = hash(item, len);
if ((i < r && (r <= d || d <= i)) || (r <= d && d <= i)) {
tab[d] = item;
tab[d + 1] = tab[i + 1];
tab[i] = null;
tab[i + 1] = null;
d = i;
}
}
}四、總結
IdentityHashMap的實現不同於HashMap,雖然也是陣列,不過IdentityHashMap中沒有用到連結串列,解決衝突的方式是計算下一個有效索引,並且將資料key和value緊挨著存在map中,即table[i]=key、table[i+1]=value;IdentityHashMap允許key、value都為null,當key為null的時候,預設會初始化一個Object物件作為key;IdentityHashMap在儲存、刪除、查詢資料的時候,以key為索引,通過==來判斷陣列中元素是否與key相同,本質判斷的是物件的引用地址,如果引用地址相同,那麼在插入的時候,會將value值進行替換;
IdentityHashMap 測試例子:
public static void main(String[] args) {
Map<String, String> identityMaps = new IdentityHashMap<String, String>();
identityMaps.put(new String("aa"), "aa");
identityMaps.put(new String("aa"), "bb");
identityMaps.put(new String("aa"), "cc");
identityMaps.put(new String("aa"), "cc");
//輸出新增的元素
System.out.println("陣列長度:"+identityMaps.size() + ",輸出結果:" + identityMaps);
}輸出結果:
陣列長度:4,輸出結果:{aa=aa, aa=cc, aa=bb, aa=cc}儘管key的內容是一樣的,但是key的堆地址都不一樣,所以在插入的時候,插入了4條記錄。
五、參考
1、JDK1.7&JDK1.8 原始碼
2、簡書 - 騎著烏龜去看海 - IdentityHashMap原始碼解析
3、部落格園 - leesf - IdentityHashMap原始碼解析
作者:炸雞可樂
出處:www.pzblog.cn