
etcd-operator快速入門完全教程
Operator是指一類基於Kubernetes自定義資源物件(CRD)和控制器(Controller)的雲原生拓展服務,其中CRD定義了每個operator所建立和管理的自定義資源物件,Controller則包含了管理這些物件所相關的運維邏輯程式碼。
對於普通使用者來說,如果要在k8s叢集中部署一個高可用的etcd叢集,那麼不僅要了解其相關的配置,同時又需要特定的etcd專業知識才能完成維護仲裁,重新配置叢集成員,建立備份,處理災難恢復等等繁瑣的事件。
而在operator這一類拓展服務的協助下,我們就可以使用簡單易懂的YAML檔案(同理參考Deployment)來宣告式的配置,建立和管理我們的etcd叢集,下面我們就來一同瞭解下etcd-operator這個服務的架構以及它所包含的一些功能。

目 標
瞭解etcd-operator的架構與CRD資源物件
部署etcd-operator
使用etcd-operator建立etcd cluster
基於etcd-operator備份和恢復etcd cluster
服務架構
etcd-operator的設計是基於k8s的API Extension機制來進行拓展的,它為使用者設計了一個類似於Deployment的Controller,只不過這個Controller是用來專門管理etcd這一服務的。
使用者預設還是通過kubectl或UI來與k8s的API進行互動,只不過在這個k8s叢集中多了一個使用者自定義的控制器(custom controller),operator controller的服務是以Pod的方式執行在k8s叢集中的,同時這個服務也需要配置所需的RBAC許可權(比如對Pod,Deployment,Volume等使用到的資源進行增刪改查的操作),下面我們用一個簡單的架構圖來進行闡述:
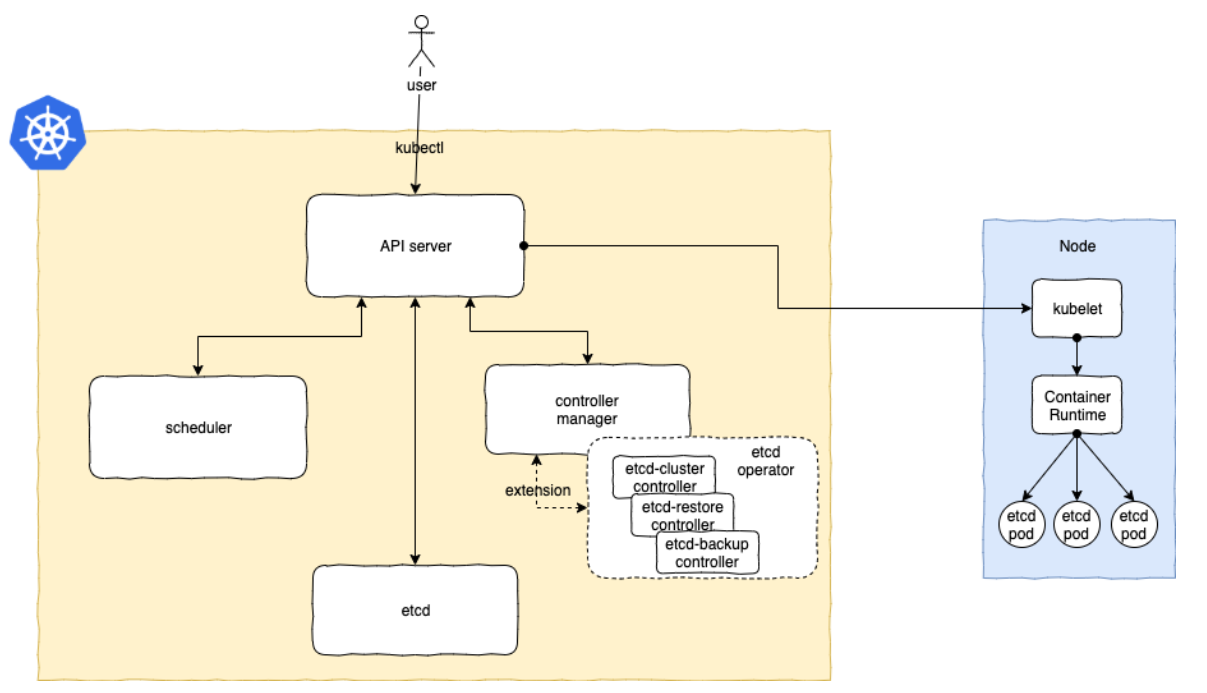
etcd-operator的自定義資源物件(CRD)
在k8s中,所有自定義的Controller和其自定義的資源物件(CRD)都必須滿足k8s API的規範(參考下圖):
apiVersion描述了當前自定義資源物件的版本號Kind表示自定義資源物件的名稱,使用者可通過執行kubectl get $KIND_NAME來獲取所建立的CRD物件Metadata繼承了原生k8s的metadata,用於新增標籤,Annotations等元資料Spec是使用者可自定義設計的服務配置引數,如映象版本號,節點數量,資源配置等等..Status包含了當前資源的的相關狀態,每個operator controller可自定義status所包含的資訊,一般會選擇新增如conditions,updateTime和message等一類的資訊。
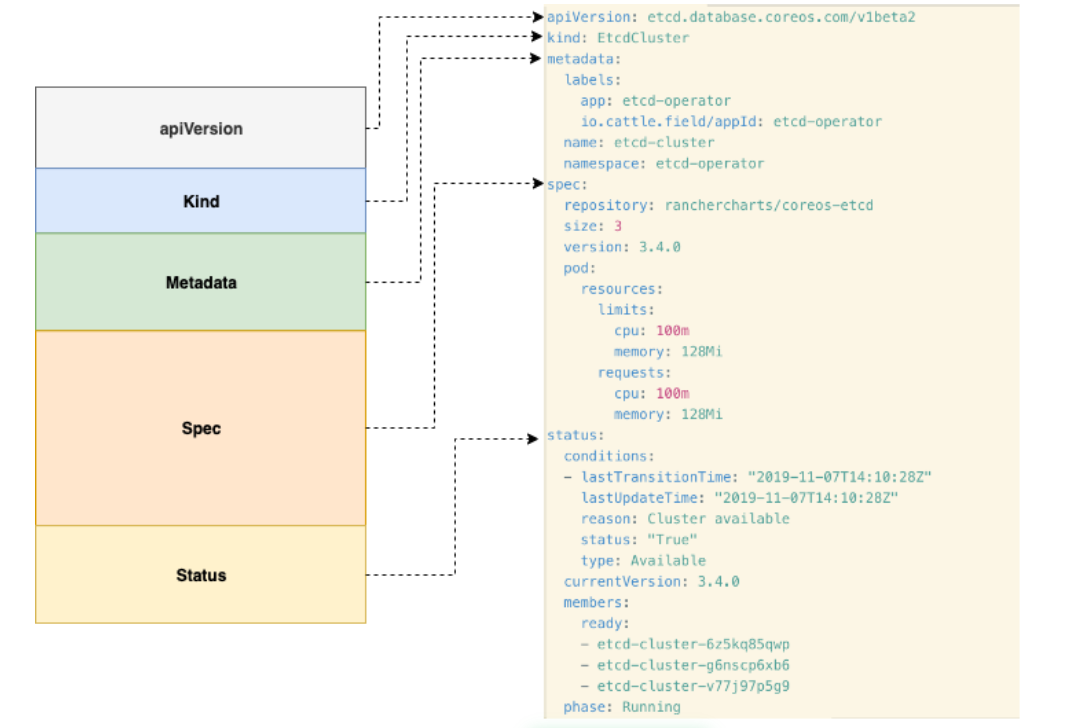
下面先我們來了解一下etcd-operator所包含的幾個自定義資源物件(CRDs):
1、EtcdCluster: etcdcluster用來描述使用者自定義的etcd叢集,可一鍵式部署和配置一個相關的etcd叢集。
apiVersion: etcd.database.coreos.com/v1beta2
kind: EtcdCluster
metadata:
name: etcd-cluster
spec:
size: 3
version: 3.2.252、EtcdBackup: etcdbackup用來描述和管理一個etcd叢集的備份,當前支援定期備份到雲端儲存,如AWS s3, Aliyun oss(oss當前需使用quay.io/coreos/etcd-operator:dev映象)。
apiVersion: etcd.database.coreos.com/v1beta2
kind: EtcdBackup
metadata:
name: etcd-backup
spec:
etcdEndpoints: [<etcd-cluster-endpoints>]
storageType: OSS #options are S3/ABS/GCS/OSS
backupPolicy:
backupIntervalInSecond: 125
maxBackups: 4
oss:
#"<oss-bucket-name>/<path-to-backup-file>"
path: <full-oss-path>
ossSecret: <oss-secret>
# Details about regions and endpoints, see https://www.alibabacloud.com/help/doc-detail/31837.htm
endpoint: <endpoint> 3、EtcdRestore:etcdrestore用來幫助將etcdbackup服務所建立的備份恢復到一個指定的etcd的叢集。
apiVersion: etcd.database.coreos.com/v1beta2
kind: EtcdRestore
metadata:
# name must be same to the spec.etcdCluster.name
name: example-etcd-cluster
spec:
etcdCluster:
name: example-etcd-cluster
backupStorageType: OSS
oss:
path: <full-oss-path>
ossSecret: <oss-secret>
endpoint: <endpoint>如何部署和使用etcd-operator
1、部署etcd-operator
在Rancher最新的stable v2.3.2 的版本中,使用者可通過應用商店(Catalog)來一鍵式部署 etcd-operator v0.9.0版本,同時原生k8s也可下載rancher/charts到本地後通過helm install的方式進行部署。

1)(可選)部署etcd-operator時可選擇同時建立一個etcd叢集(此叢集在etcd-operator被刪除時會被一同移除),當然使用者也可待etcd-operator部署完成通過kubectl apply -f myetcd.yaml來建立一個新的etcd叢集。
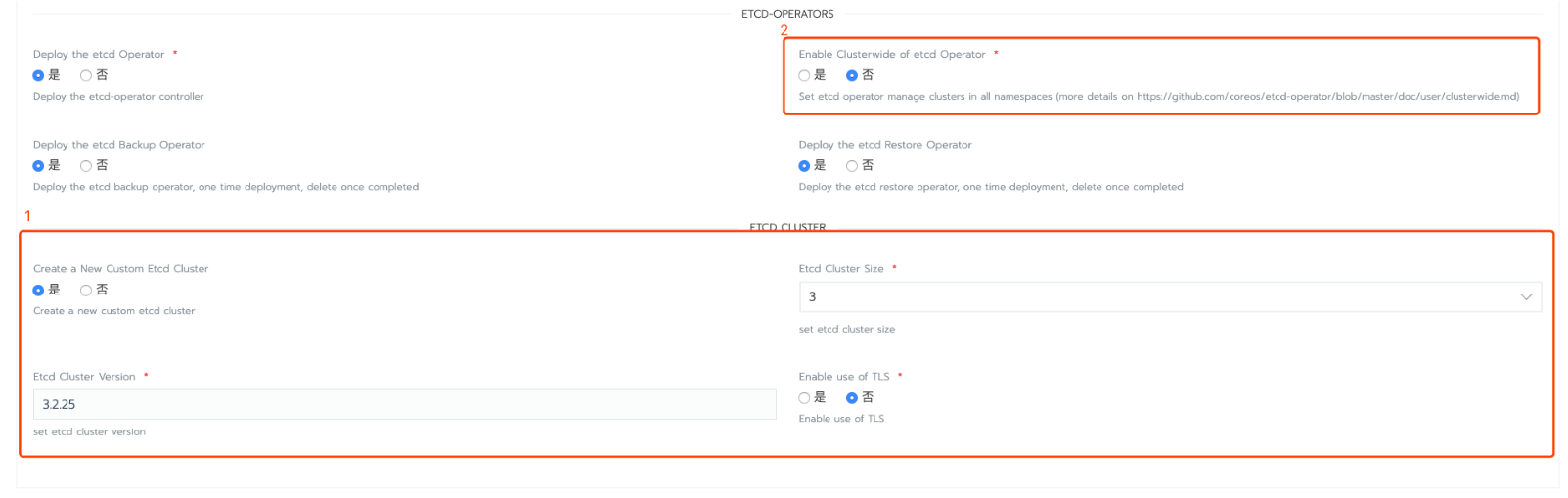
2)部署時,如果使用者選擇啟動Enable Clusterwide of etcd Operator這個選項,那麼這個etcd-operator將作為叢集層級物件來使用(否則為namespaced隔離),如果enable這個選項,那麼在建立etcd叢集時需新增以下注釋才能建立建立:
kind: EtcdCluster
metadata:
name: etcd-cluster
# add this annotation when the clusterWide is enabled
annotations:
etcd.database.coreos.com/scope: clusterwide2、建立etcd叢集
接下來我們就可以使用上述的CRD自定義資源物件對來建立和管理我們的etcd叢集了。
2.1 手動建立etcd叢集
cat <<EOF | kubectl apply -f -
apiVersion: etcd.database.coreos.com/v1beta2
kind: EtcdCluster
metadata:
name: "etcd-cluster"
spec:
size: 3 # 預設etcd節點數
version: "3.2.25" # etcd版本號
EOF2.2 部署後可通過CRD物件來檢視我們建立的etcd叢集和pod狀態
$ kubectl get etcdcluster
NAME AGE
etcd-cluster 2m
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
etcd-cluster-g28f552vvx 1/1 Running 0 2m
etcd-cluster-lpftgqngl8 1/1 Running 0 2m
etcd-cluster-sdpcfrtv99 1/1 Running 0 2m2.3 可以往etcd叢集任意的寫入幾條資料驗證etcd叢集是正常工作的(後續也可用來驗證叢集的備份和恢復功能)
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
etcd-cluster ClusterIP None <none> 2379/TCP,2380/TCP 17h
etcd-cluster-client ClusterIP 10.43.130.71 <none> 2379/TCP 17h
## write data
$ kubectl exec -it any-etcd-pod -- env "ETCDCTL_API=3" etcdctl --endpoints http://etcd-cluster-client:2379 put foo "Hello World"
## get data
$ kubectl exec -it any-etcd-pod -- env "ETCDCTL_API=3" etcdctl --endpoints http://etcd-cluster-client:2379 get foo
foo
Hello World3、基於operator備份etcd cluster
3.1 確認了etcd叢集正常執行後,作為devops後面要考慮的就是如何建立etcd叢集的自動化備份,下面以阿里雲的OSS舉例:
cat <<EOF | kubectl apply -f -
apiVersion: etcd.database.coreos.com/v1beta2
kind: EtcdBackup
metadata:
name: example-etcd-cluster-periodic-backup
spec:
etcdEndpoints: [http://etcd-cluster-client:2379] #內網可使用svc地址,外網可用NodePort或LB代理地址
storageType: OSS
backupPolicy:
backupIntervalInSecond: 120 #備份時間間隔
maxBackups: 4 #最大備份數
oss:
path: my-bucket/etcd.backup
ossSecret: oss-secret #需預先建立oss secret
endpoint: oss-cn-hangzhou.aliyuncs.com
EOF3.2 若OSS Secret不存在,使用者可先手動建立,具體配置可參考如下:
cat << EOF | kubectl apply -f -
apiVersion: v1
kind: Secret
metadata:
name: oss-secret
type: Opaque
stringData:
accessKeyID: myAccessKey
accessKeySecret: mySecret
EOF3.3 待etcdbackup建立成功後,使用者可以通過kubectl describe etcdbackup或檢視etcd-backup controller日誌來檢視備份狀態,如狀態顯示為Succeeded: true,可以前往oss檢視具體的備份內容。

4、基於operator恢復etcd cluster
最後,假設我們要將etcd叢集A的備份資料恢復到另一個新的etcd叢集B,那麼我們先手動建立一個名為etcd-cluster2的新叢集(oss備份/恢復當前需使用quay.io/coreos/etcd-operator:dev映象)。
cat <<EOF | kubectl apply -f -
apiVersion: etcd.database.coreos.com/v1beta2
kind: EtcdCluster
metadata:
name: "etcd-cluster2"
spec:
size: 3
version: "3.2.25"
EOF然後通過建立etcdresotre將備份資料恢復到etcd-cluster2叢集
cat <<EOF | kubectl apply -f -
apiVersion: etcd.database.coreos.com/v1beta2
kind: EtcdRestore
metadata:
# name必須與下面的spec.etcdCluster.name保持一致
name: etcd-cluster2
spec:
etcdCluster:
name: etcd-cluster2
backupStorageType: OSS
oss:
path: my-bucket/etcd.backup_v1_2019-08-07-06:44:17
ossSecret: oss-secret
endpoint: oss-cn-hangzhou.aliyuncs.com
EOF待etcdresotre物件建立成功後,可以檢視etcd-operator-restore的日誌,大致內容如下:
$ kubectl logs -f etcd-operator-restore
...
time="2019-08-07T06:50:26Z" level=info msg="listening on 0.0.0.0:19999"
time="2019-08-07T06:50:26Z" level=info msg="starting restore controller" pkg=controller
time="2019-08-07T06:56:25Z" level=info msg="serving backup for restore CR etcd-cluster2"通過kubectl檢視pod我們可以看到etcd-cluster2叢集的etcd節點被刪除重建:
NAME READY STATUS RESTARTS AGE
etcd-cluster2-5tq2d5bvpf 0/1 Terminating 0 93s
etcd-cluster2-kfgvc692pp 1/1 Terminating 0 101s
etcd-cluster2-xqkgz8chb8 0/1 Init:1/3 0 6s
etcd-cluster2-pf2qxgtg9d 1/1 Running 0 48s
etcd-cluster2-x92l9vpx97 1/1 Running 0 40s最後可通過etcdctl來驗證之前的資料是否存在(需設定ETCDCTL_API=3):
$ kubectl exec -it etcd-pod -- env "ETCDCTL_API=3" etcdctl --endpoints http://etcd-cluster2-client:2379 get foo
foo
Hello World小 結
Etcd作為當前非常流行的key-value分散式檔案儲存,它本身的強一致性和較優的效能可以為許多分散式計算解決分散式儲存的需求,如果你的微服務和應用需要用到此類的資料庫,不妨來試試Rancher Catalog應用中的etcd-operator吧,Just do it!
相關資料:
https://github.com/coreos/etcd-operator
https://coreos.com/blog/introducing-the-etcd-operator.html
https://github.com/rancher/charts/tree/master/charts/etcd-operator/v0.