
理解Spark SQL(一)—— CLI和ThriftServer
Spark SQL主要提供了兩個工具來訪問hive中的資料,即CLI和ThriftServer。前提是需要Spark支援Hive,即編譯Spark時需要帶上hive和hive-thriftserver選項,同時需要確保在$SPARK_HOME/conf目錄下有hive-site.xml配置檔案(可以從hive中拷貝過來)。在該配置檔案中主要是配置hive metastore的URI(Spark的CLI和ThriftServer都需要)以及ThriftServer相關配置項(如hive.server2.thrift.bind.host、hive.server2.thrift.port等)。注意如果該臺機器上同時執行有Hive ThriftServer和Spark ThriftServer,則hive中的hive.server2.thrift.port配置的埠與spark中的hive.server2.thrift.port配置的埠要不一樣,避免同時啟動時發生埠衝突。
啟動CLI和ThriftServer之前都需要先啟動hive metastore。執行如下命令啟動:
[root@BruceCentOS ~]# nohup hive --service metastore &
成功啟動後,會出現一個RunJar的程序,同時會監聽埠9083(hive metastore的預設埠)。


先來看CLI,通過spark-sql指令碼來使用CLI。執行如下命令:
[root@BruceCentOS4 spark]# $SPARK_HOME/bin/spark-sql --master yarn
上述命令執行後會啟動一個yarn client模式的Spark程式,如下圖所示:

同時它會連線到hive metastore,可以在隨後出現的spark-sql>提示符下執行hive sql語句,比如:

其中每輸入並執行一個SQL語句相當於執行了一個Spark的Job,如圖所示:

也就是說執行spark-sql指令碼會啟動一個yarn clien模式的Spark Application,而後出現spark-sql>提示符,在提示符下的每個SQL語句都會在Spark中執行一個Job,但是對應的都是同一個Application。這個Application會一直執行,可以持續輸入SQL語句執行Job,直到輸入“quit;”,然後就會退出spark-sql,即Spark Application執行完畢。
另外一種更好地使用Spark SQL的方法是通過ThriftServer,首先需要啟動Spark的ThriftServer,然後通過Spark下的beeline或者自行編寫程式通過JDBC方式使用Spark SQL。
通過如下命令啟動Spark ThriftServer:
[root@BruceCentOS4 spark]# $SPARK_HOME/sbin/start-thriftserver.sh --master yarn
執行上面的命令後,會生成一個SparkSubmit程序,實際上是啟動一個yarn client模式的Spark Application,如下圖所示:

而且它提供一個JDBC/ODBC介面,使用者可以通過JDBC/ODBC介面連線ThriftServer來訪問Spark SQL的資料。具體可以通過Spark提供的beeline或者在程式中使用JDBC連線ThriftServer。例如在啟動Spark ThriftServer後,可以通過如下命令使用beeline來訪問Spark SQL的資料。
[root@BruceCentOS3 spark]# $SPARK_HOME/bin/beeline -n root -u jdbc:hive2://BruceCentOS4.Hadoop:10003
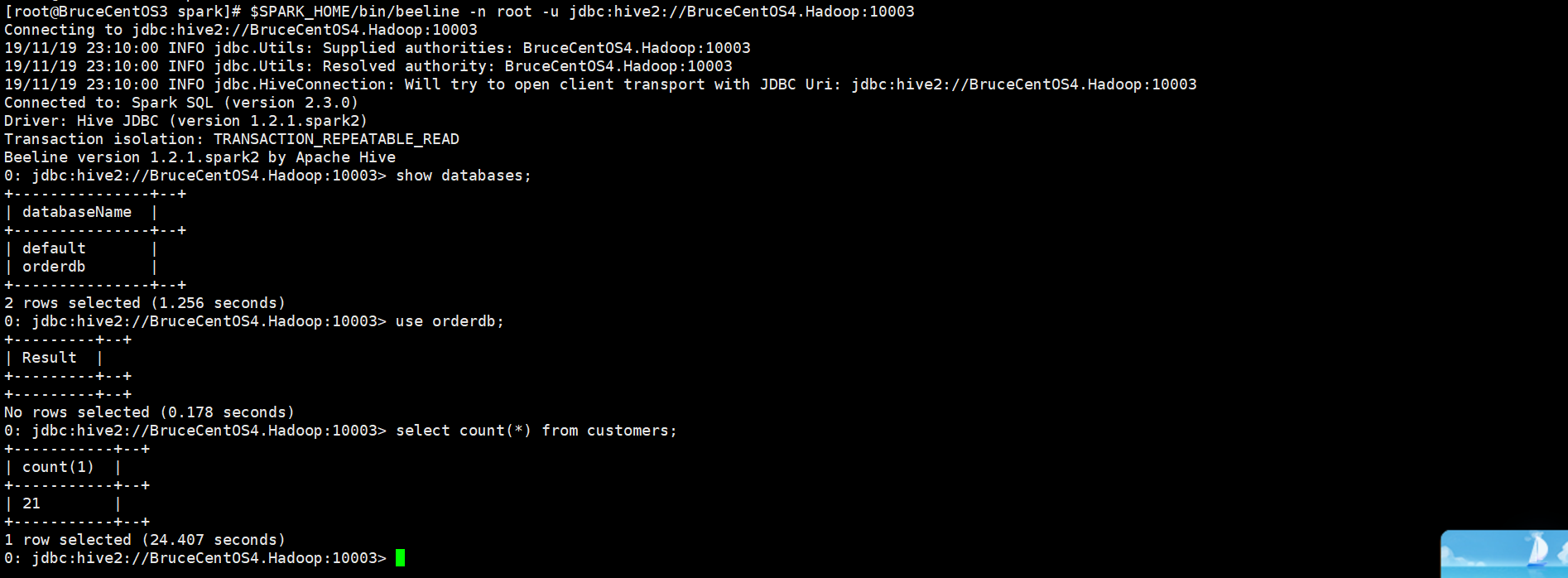
上述beeline連線到了BruceCentOS4上的10003埠,也就是Spark ThriftServer。所有連線到ThriftServer的客戶端beeline或者JDBC程式共享同一個Spark Application,通過beeline或者JDBC程式執行SQL相當於向這個Application提交併執行一個Job。在提示符下輸入“!exit”命令可以退出beeline。
最後,如果要停止ThriftServer(即停止Spark Application),需要執行如下命令:
[root@BruceCentOS4 spark]# $SPARK_HOME/sbin/stop-thriftserver.sh

綜上所述,在Spark SQL的CLI和ThriftServer中,比較推薦使用後者,因為後者更加輕量,只需要啟動一個ThriftServer(對應一個Spark Application)就可以給多個beeline客戶端或者JDBC程式客戶端使用SQL,而前者啟動一個CLI就啟動了一個Spark Application,它只能給一個使用者使用。
&n