
人機對話技術研究進展與思考

嘉賓:袁彩霞 博士 北京郵電大學 副教授
整理:Hoh Xil
來源:阿里小蜜 & DataFun AI Talk
出品:DataFun
注:歡迎轉載,轉載請在留言區內留言。
導讀:本次分享的主題為人機對話技術研究進展與思考。主要梳理了我們團隊近兩年的工作,渴望可以通過這樣的介紹,能給大家一個關於人機對話 ( 包括它的科學問題和應用技術 ) 方面的啟示,幫助我們進行更深入的研究和討論。主要包括:
Spoken dialogue system:a bird view ( 首先我們來看什麼是人機對話,尤其是 Spoken dialogue。其實說 Spoken 的時候,有兩層含義:第一個 spoken 就是 speech,第二個我們處理的語言本身具有 spoken 的特性。但是,稍後會講的 spoken 是指我們已經進行語音識別之後,轉換為文字的一個特殊的自然語言,後面討論的口語對話不過多地討論它的口語特性,主要是講人和機器之間的自然語言對話。)
X-driven dialogue system:緊接著來講解我們近些年的研究主線 X-driven dialogue syatem,X 指構建一個對話系統時,所採用的資料是什麼,從最早的 dialogue -> FAQ -> KB -> KG -> document 以及我們一直在嘗試的圖文多模態資料。
Concluding remarks ( 結束語 )
01
Spoken dialogue system:a bird view
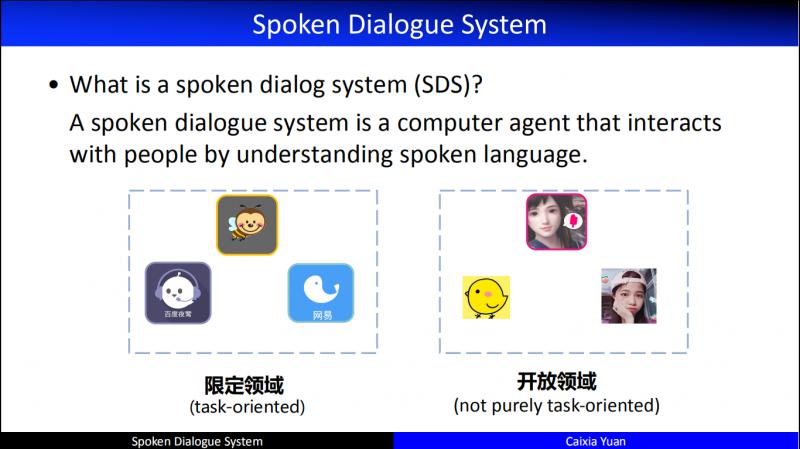
學術界關於對話系統有著不同的劃分,這種劃分目前看來不是非常準確,也不是特別標準的劃分了。但是,接下來的內容,主要是圍繞著這兩個主線:
限定領域,專門指任務型對話 ( 圍繞某一特定使用者對話目標而展開的 )。對於任務型對話,對話系統的優化目標就是如何以一個特別高的回報、特別少的對話輪次、特別高的成功率來達成使用者的對話目標。所以即便是限定領域,我們這裡討論的也是特別限定的、專門有明確的使用者對話目標的一種對話。
開放領域,not purely task-oriented, 已經不再是純粹的對話目標驅動的對話,包括:閒聊、推薦、資訊服務等等,後面逐步展開介紹。

我們在研究一個問題或者做論文答辯和開題報告時,經常討論研究物件的意義在哪裡。圖中,前面講的是應用意義,後面是理論意義。我們實驗室在北京郵電大學叫智慧科學與技術實驗室,其實她的前身叫人工智慧實驗室。所以從名字來看,我們做了非常多的 AI 基礎理論的研究,我們在研究這些理論的時候,也會講 AI 的終極目的是研製一種能夠從事人類思維活動的計算機系統。人類思維活動建立在獲取到的訊號的基礎上。人類獲取訊號的方式大體有五類,包括視覺、聽覺、觸覺、味覺、嗅覺等,其中視覺和聽覺是兩個比較高階的感測器通道,尤其是視覺通道,佔據了人類獲得資訊的80%以上。所以我們從這兩個角度,設立了兩個研究物件:第一個是語言,第二個是影象。而我們在研究語言的時候,發現語言有一個重要的屬性,叫互動性,互動性最典型的一個體現就是對話;同時,語言不是一個獨立的模態,語言的處理離不開跟它相關的另一個通道,就是視覺通道。所以我們早期更多是為了把互動和多模態這樣的屬性納入到語言建模的範圍,以其提升其它自然語言處理系統的效能,這就是我們研究的一個動機。
- Block diagram
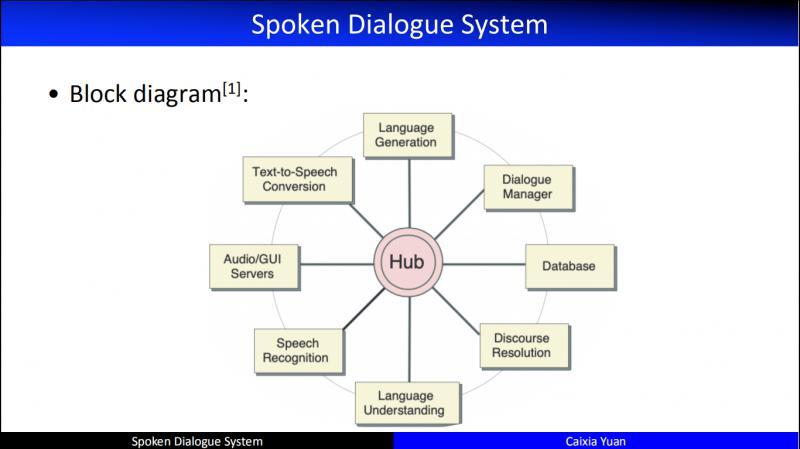
上圖為 CMU 等在1997年提出來的人機對話方塊架,基於這個框架人們開發出了非常多優秀的應用系統,比如應用天氣領域的 "Jupiter"。這個框架從提出到商業化應用,一直到今天,我們都還沿著這樣的一個系統架構在進行開發,尤其是任務驅動的對話。
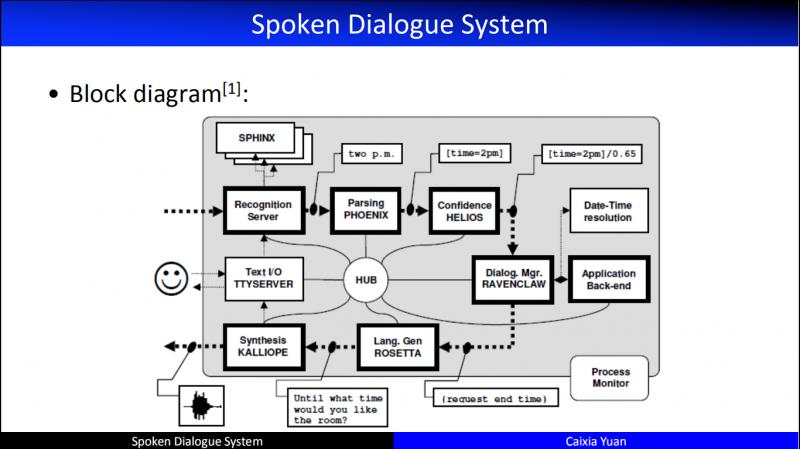
這就是具體的對話系統的技術架構。
- Specific domain
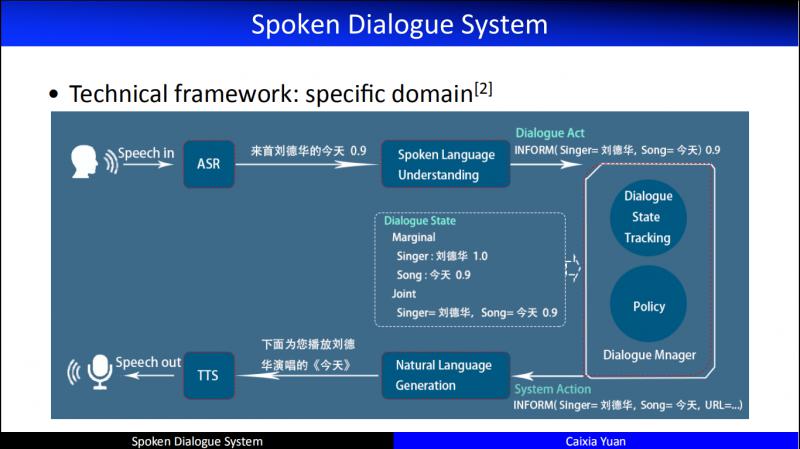
這個架構發展到現在,在功能模組上,已經有了一個很清晰的劃分:
首先進行語音識別,然後自然語言理解,緊接著做對話管理,將對話管理的輸出交給自然語言生成模組,最後形成自然語言應答返回給使用者。這就是一個最典型的 specific domain 的架構。早期 task 限定的 dialogue,基本上都是按照這個架構來做的。這個架構雖然是一個 Pipeline,但是從研究的角度來講,每一個模組和其它模組之間都會存在依賴關係。因此,我們試圖從研究的角度把不同的功能模組進行統一建模。在這個建模過程中,又會產生新的學術性問題,我們旨在在這樣的問題上可以產生驅動性的技術。
- Open domain
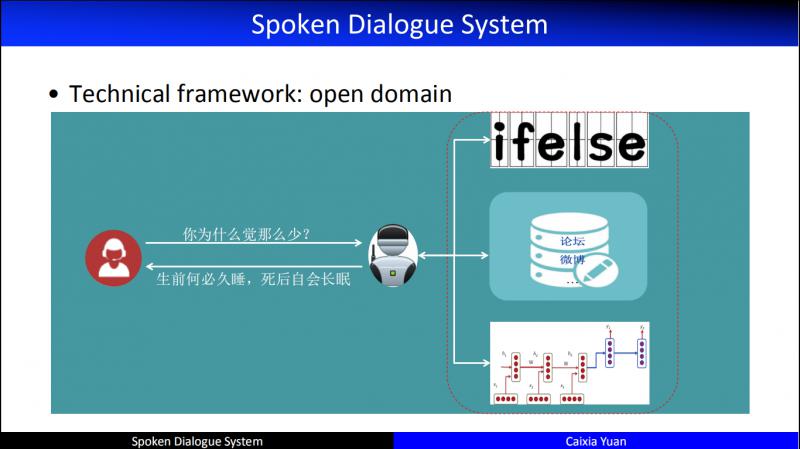
Open domain,也就是“閒聊”,實現上主要分為途徑:
第一個是基於匹配/規則的閒聊系統;第二個是基於檢索的閒聊系統;第三個是基於編解碼結構的端到端對話系統。當然,實際情境中,這幾個途徑往往結合在一起使用。
02
X-Driven dialogue system
目前無論是任務型對話還是閒聊式對話,都採用資料驅動的方法,因此依據在構建人機對話系統時所用到的資料不同,建模技術和系統特性也就體現出巨大的不同。我們把使用的資料記為 X,於是就有了不同的 X 驅動的對話。
- Our roadmap
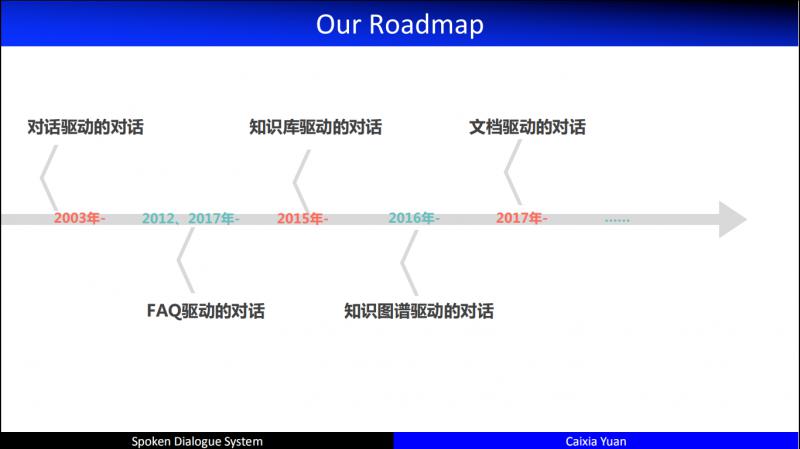
如果想讓機器學會像人一樣對話,我們可以提供的最自然的資料就是 dialogue。我們從2003年開始做對話驅動的對話;2012年開始做 FAQ 驅動的對話;2015年開始做知識庫 ( KB ) 驅動的對話;2016年開始做知識圖譜 ( KG ) 驅動的對話,相比於 KB,KG 中的知識點產生了關聯,有了這種關聯人們就可以在大規模的圖譜上做知識推理;2017年開始做文件驅動的對話。這就是我們研究的大致脈絡。
- Dialogue-driven dialogue
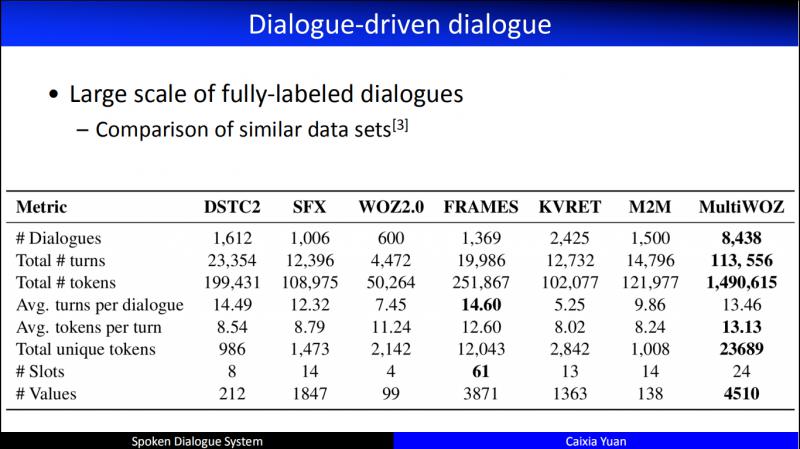
早期在做 Dialogue driven 的時候,多依賴人工採集資料,但是,從2013年以來,逐步開放了豐富的涵蓋多領域多場景的公開資料集。比如最近的 MultiWOZ,從 task specific 角度講,資料質量足夠好、資料規模足夠大,同時涵蓋的對話情景也非常豐富。但是,目前公開的中文資料集還不是很多。
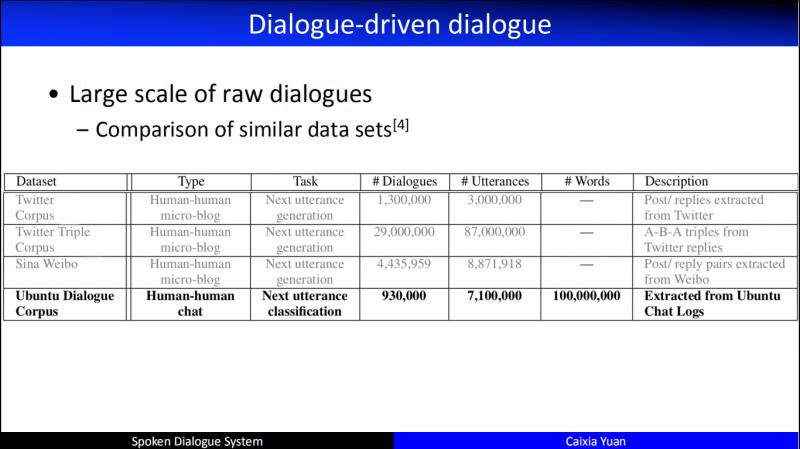
這個是和任務型對話無關的資料集,也就是採集的人與人對話的資料集。尤其以 Ubuntu 為例,從15年更新至今,已經積累了非常大規模的資料。
以 Dialogue 為輸入,我們開展了任務型和非任務型兩個方向的工作。先來看下任務型對話:
2.1 NLU

當一個使用者輸入過來,第一個要做的就是自然語言理解 ( NLU ),NLU 要做的三件事為:Domain 識別;Intent 識別;資訊槽識別或叫槽填充。這三個任務可以分別獨立地或採用管道式方法做,也可以聯合起來進行建模。在聯合建模以外,我們還做了一些特別的研究。比如我們在槽識別的時候,總是有新槽,再比如有些槽值非常奇怪,例如 "XX手機可以一邊打電話一邊視訊嗎?",對應著槽值 "視訊電話",採用序列標註的方式,很難識別它,因為這個槽值非常不規範。使用者輸入可能像這樣語義非常鬆散,不連續,也可能存在非常多噪音,在進行聯合建模時,傳統的序列標註或分類為思想,在實際應用中已經不足以解決問題了。
我們針對這個問題做了比較多的探討,右圖為我們2015年的一個工作:在這三個任務聯合建模的同時,在槽填充這個任務上將序列標註和分類進行同時建模,來更好地完成 NLU。
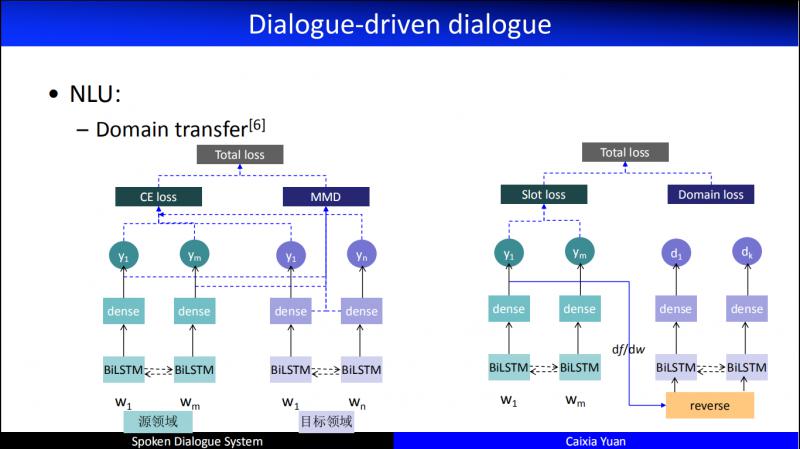
在 NLU 領域還有一個非常重要的問題,隨著開發的業務領域越來越多,我們發現多領域對話產生了諸多非常重要的問題,例如在資料層有些 domain 資料可能很多,有些 domain 資料可能很少,甚至沒有,於是就遇到冷啟動的問題。因此,我們做了非常多的 domain transfer 的工作。上圖為我們2016年的一個工作,我們會把資料比較多的看成源領域,資料比較少的看成目標領域。於是,嘗試了基於多種遷移學習的 NLU,有的是在特徵層進行遷移,有的是在資料層遷移,有的是在模型層進行遷移。圖中是兩個典型的在特徵層進行遷移的例子,不僅關注領域一般特徵,而且關注領域專門特徵,同時採用了對抗網路來生成一個虛擬的特徵集的模型。
2.2 NLU+DM
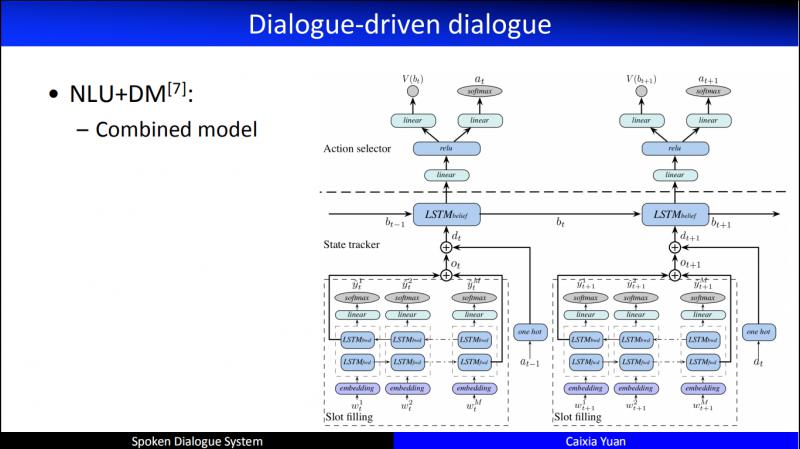
緊接著,我們研究了 NLU 和對話管理 ( DM ) 進行聯合建模,因為我們發現人人對話的時候,不見得是聽完對方說完話,理解了對方的意圖,然後才形成對話策略,有可能這兩個過程是同時發生的。甚或 DM 還可以反作用於 NLU。早期我們基於的一個假設是, NLU 可能不需要一個顯式的過程,甚至不需要一個顯式的 NLU 的功能,我們認為 NLU 最終是服務於對話管理 ( DM ),甚至就是對話管理 ( DM ) 的一部分。所以,2013年的時候,我們開始了探索,有兩位特別優秀的畢業生在這兩個方面做了特別多的工作。比如,如何更好地聯合建模語言理解的輸出和對話管理的策略優化。這是我們在 NLU 和 DM 聯合建模的工作,同時提升了 NLU 和 DM 的效能。

在聯合模型中,我們發現,DM 的建模涉及到非常多的 DRL ( 深度強化學習 ) 的工作,訓練起來非常困難,比如如何設計一個好的使用者模擬器,基於規則的,基於統計的,基於語言模型的,基於 RL 的等等我們嘗試了非常多的辦法,也取得了一系列有趣的發現。2018年時我們研究一種不依賴於規則的使用者模擬器,業界管這個問題叫做 "Self"-play,雖然我們和 "Self"-play 在網路結構上差異挺大的,但是我們還是借鑑了 "Self"-play 訓練的特性,把我們自己的系統叫做 "Self"-play。在這樣的機制引導下,我們研究了不依賴於規則,不依賴於有標記資料的使用者模擬器,使得這個使用者模擬器可以像 Agent 一樣,和我們所構造的對話的 Agent 進行互動,在互動的過程中完成對使用者的模擬。
在訓練過程中還有一個重要的問題,就是 reward 怎麼來,我們知道在 task oriented 時,reward 通常是人類專家根據業務邏輯/規範制定出來的。事實上,當我們在和環境互動的時候不知道 reward 有多大,但是環境會隱式地告訴我們 reward 是多大,所以我們做了非常多的臨接對和 reward reshaping 的工作。
2.3 小結

Dialogue-driven dialogue 這種形式的對話系統,總結來看:
優點:
定義非常好,邏輯清晰,每一個模組的輸入輸出也非常清晰,同時有特別堅實的數學模型可以對它進行建模。
缺點:
由於非常依賴資料,同時,不論是在 NLU 還是 NLG 時,我們都是採用有監督的模型來做的,所以它依賴於大量的、精細的標註資料。
而 DM 往往採用 DRL 來做。NIPS2018 時的一個 talk,直接指出:任何一個 RL 都存在的問題,就是糟糕的重現性、複用性、魯棒性。
- FAQ-driven dialogue
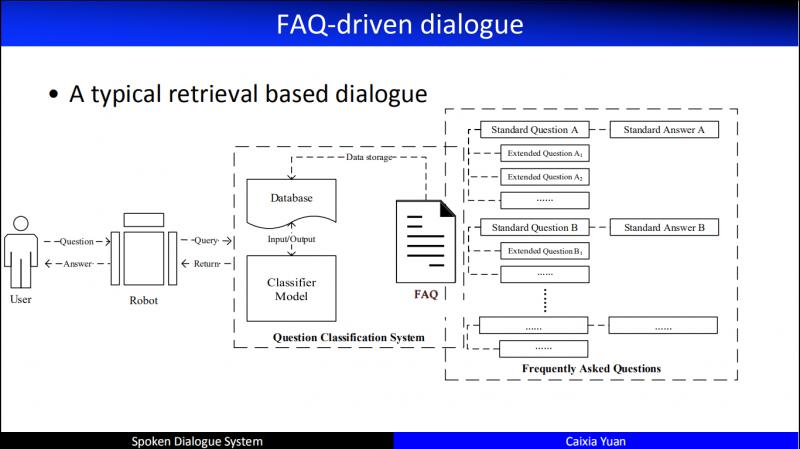
FAQ 是工業界非常常見的一種情景:有大量的標準問,以及這個標準問的答案是什麼。基於這個標準問,一個使用者的問題來了,如何找到和它相似的問題,進而把答案返回給使用者,於是這個 Service 就結束了。
實際中,我們如何建 FAQ?更多的時候,我會把這個問題和我們庫的標準問題做一個相似度的計算或者做一個分類。
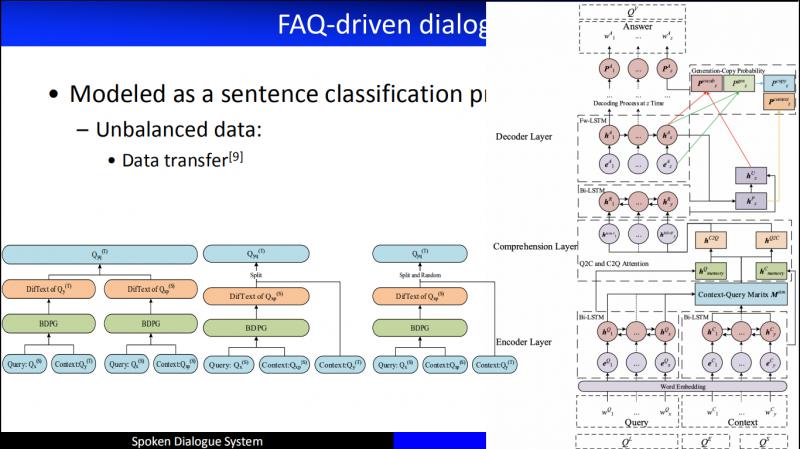
我們在做這個工作的時候發現一個特別大的問題,就是 Unbalanced Data 問題。比如,我們有5000個問題,每個問題都有標準答案,有些問題可能對應的使用者問題特別多,比如 "螢幕碎了" 可能會有1000多種不同的問法,還有些問題,可能在幾年的時間裡都沒有人問到過。所以,面對資料不均衡的問題,我們從2016年開始做了 Data transfer 的工作。
大致的思路是:我有一個標準問題,但是很糟糕,這個標準問題沒有使用者問題,也就是沒有訓練語料。接下來發現另外一個和這個標準問很相似的其它標準問有很多的訓練語料,於是藉助這個標準問,來生成虛擬樣本,進而削弱了 Unbalance。
具體的方法:我們把目標領域的標準問看成 Query,把和它相似的標準問題及其對應的使用者問題看成 Context,採用了 MRC 機器閱讀理解的架構來生成一個答案,作為目標問題的虛擬的使用者問題,取得了非常好的效果,並且嘗試了三種不同的生成使用者問題的方法。
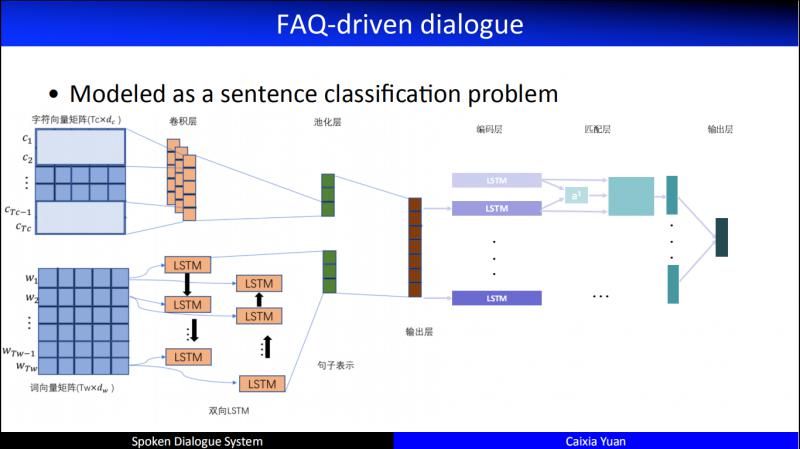
實際專案中,FAQ 中的 Q 可能有非常多的問題,例如3000多個類,需要做極限分類,這就導致效能低下,且非常耗時,不能快速響應使用者的問題。於是我們做了一個匹配和分類進行互動的 model,取得了不錯的效果。

目前,大部分人都認為 FAQ 驅動的 dialogue 不叫 dialogue,因為我們通常說的 dialogue 輪次是大於兩輪的。而 FAQ 就是一個 QA 系統,沒有互動性。有時候帶來的使用者體驗非常不友好,比如當答案非常長的時候,系統要把長長的答案返回,就會一直講,導致使用者比較差的體驗。於是,我們基於 FAQ 發展出了一個多輪對話的資料,如右圖,這是我們正在開展的一個工作。
- KB-driven dialogue
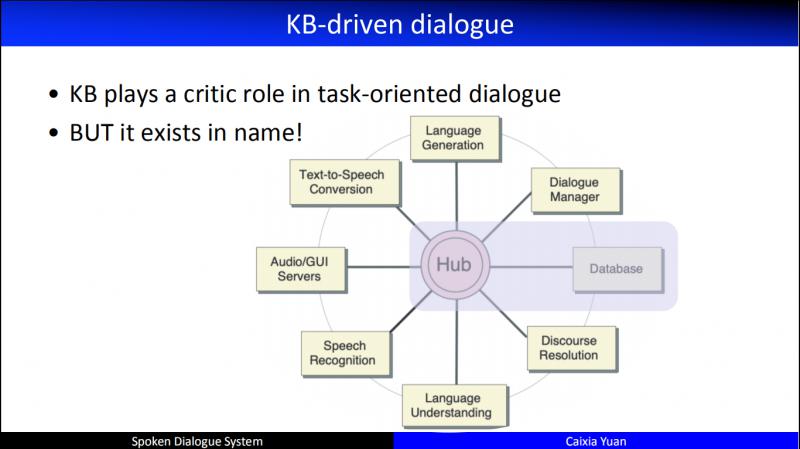
KB 最早人們認為它就是一個結構化的資料庫,通常儲存在關係型資料庫中。比如要訂一個酒店,這個酒店有各種屬性,如位置、名稱、戶型、價格、面積等等。早期 CMU 的對話系統,所有的模組都要和 Hub 進行互動,最後 Hub 和後端的資料庫進行互動。資料庫的價值非常大,但是早期人們在建模人機對話的時候,都忽視了資料庫。這裡就會存在一個問題:機器和使用者互動了很久,而在檢索資料庫時發現沒有答案,或者答案非常多,造成使用者體驗非常糟糕。
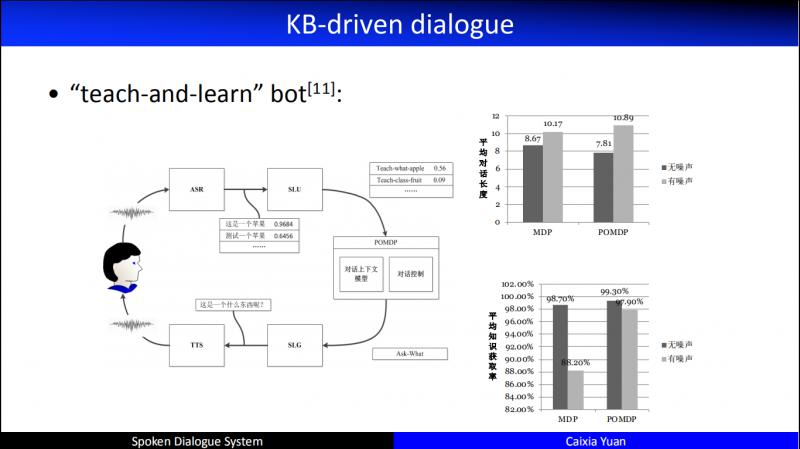
從2012年開始,我們開始把 KB 引入我們的對話系統。圖中的對話系統叫做 "teach-and-learn" bot,這是一個多模態的對話,但是每個涉及到的 object,我們都會把它放到 DB 中。和使用者互動過程中,不光看使用者的對話狀態,還要看資料庫狀態。這個想法把工作往前推進了一些。
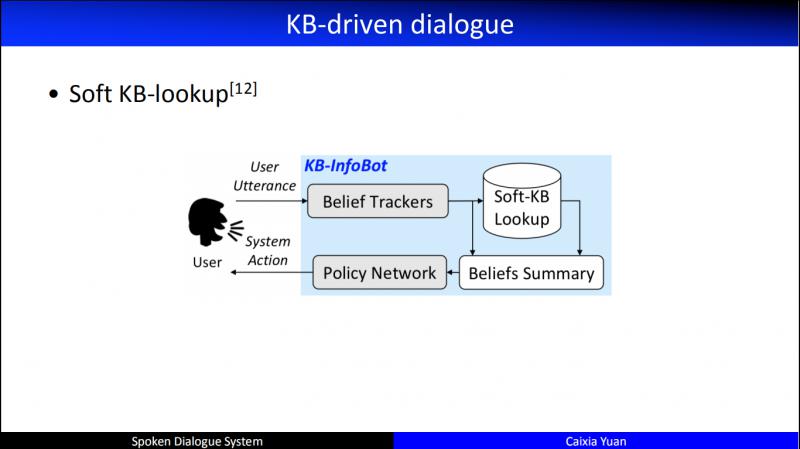
直到2016年,MSR 提出的 KB-InfoBot,第一次提出了進行資料庫操作時,要考慮它的可導性,否則,就沒辦法在 RL 網路中像其它的 Agent action 一樣進行求導。具體的思路:把資料庫的查詢和 Belief State 一起總結起來做同一個 belief,進而在這樣的 belief 基礎上做各種對話策略的優化。
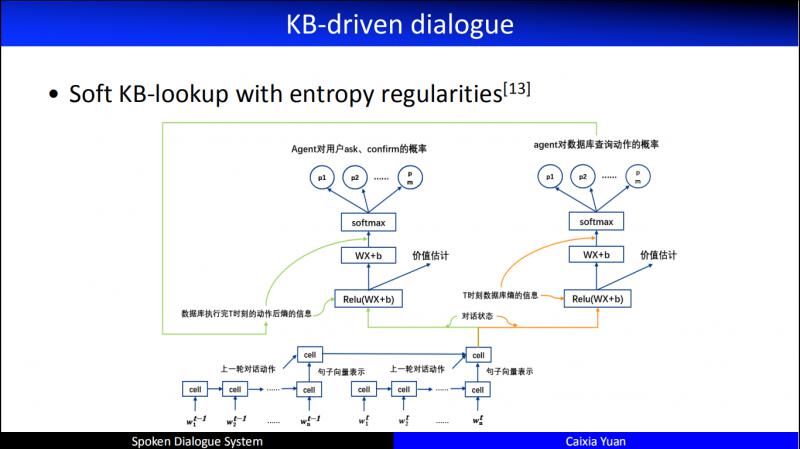
在上述方法的基礎上,我們做了有效的改良,包括 entropy regularities 工作。是每次和使用者進行互動時,資料庫的 entropy 會發生變化。比如當機器問 "你想訂哪裡的酒店?",使用者答 "阿里中心附近的。",於是資料庫立刻進行了一次 entropy 計算進行更新,接著繼續問 "你想訂哪一天的?",使用者答 "訂7月28號的",於是又進行了一次 entropy 計算進行更新。這樣在和使用者進行互動的時候,不光看使用者的 dialogue 輸入,還看 DB 的 entropy 輸入,以這兩項共同驅動 Agent action 進行優化。
這裡我們做了特別多的工作,資訊槽從1個到5個,資料庫的規模從大到小,都做了特別多的嘗試,這樣在和使用者互動的時候,agent 可以自主的查詢檢索,甚至可以填充和修改資料庫。
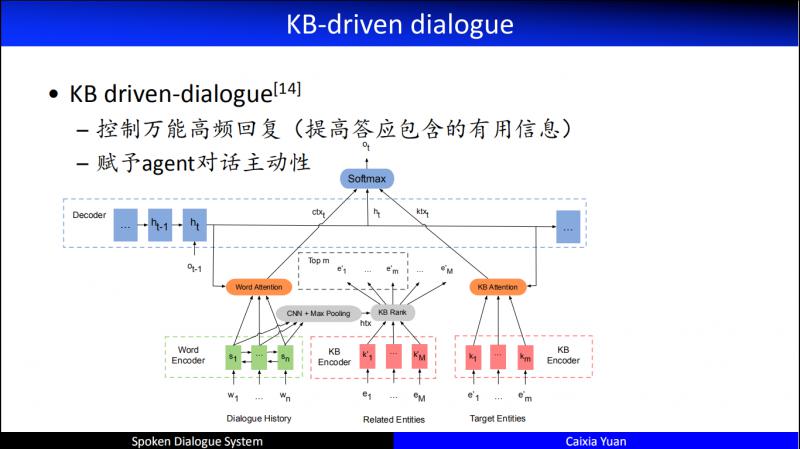
這是我們2017釋出的一個工作,KB driven-dialogue,其優點:
控制萬能高頻回覆 ( 提高答應包含的有用資訊 )
賦予 agent 對話主動性
- KG-driven dialogue
剛剛講的基於 KB 的 dialogue 任務,基本都認為對話任務就是在進行槽填充的任務,如果一個 agent 是主動性的,通過不停的和使用者進行互動來採集槽資訊,所以叫槽填充,當槽填完了,就相當於對話任務成功了。但是,當我們在定義槽的時候,我們認為槽是互相獨立的,並且是扁平的。然而,實際中許多工的槽之間存在相關性,有的是上下位關係,有的是約束關係,有的是遞進關係等等。這樣自然的就引出了知識圖譜,知識圖譜可以較好地描述上述的相關性。於是,產生了兩個新問題:
知識圖譜驅動的對話理解:實體連結
知識圖譜驅動的對話管理:圖路徑規劃
這裡主要講下第二個問題。
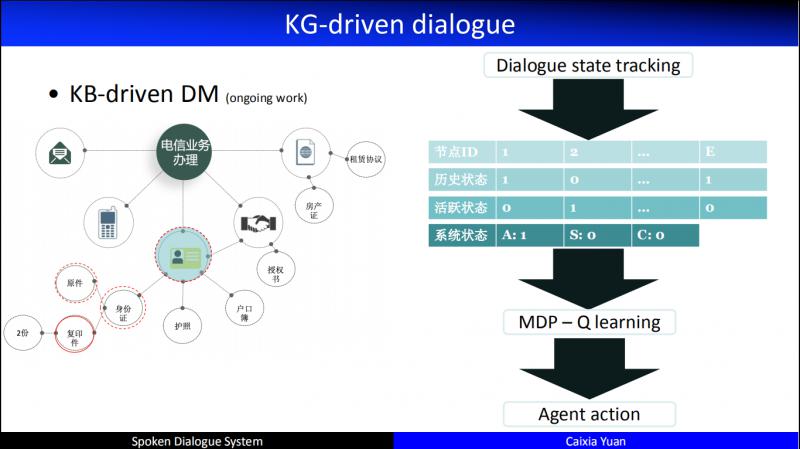
舉個例子,我們在辦理電信業務,開通一個家庭寬頻,需要提供相關的證件,是自己去辦,還是委託人去辦,是房東還是租戶等等,需要提供各種不同的材料。於是這個情景就產生了條件的約束,某一個 node 和其它 node 是上下位的關係,比如證件可以是身份證,也可以是護照或者戶口簿等等。所以我們可以通過知識圖譜來進行處理。
當一個使用者的對話過來,首先會連結到不同的 node,再基於 node 和對話歷史構造一個對話的 state,我們會維持一個全域性的 state 和一個活躍的 state,同時活躍的 state 會定義三種不同的操作動作,一個是祖先節點,一個是兄弟節點,還有一個是孩子節點。所以,在這樣的知識圖譜上如何尋優,比如當通過某種計算得到,它應該在某個節點上進行互動的時候,我們就應該輸出一個 action,這個 action 要和使用者確認他是一個租戶,還是自有住房等等。所以,這個 action 是有區別於此前所提到的在特定的、扁平的 slot 槽上和使用者進行資訊的確認、修改等還是有很大不同的。解決這樣的問題,一個非常巨大的挑戰就是狀態空間非常大。比如圖中的節點大概有120個,每個節點有3個不同的狀態,知識從節點的狀態來看就有3的120次冪種可能。這也是我們正在開展的待解決的一個問題。
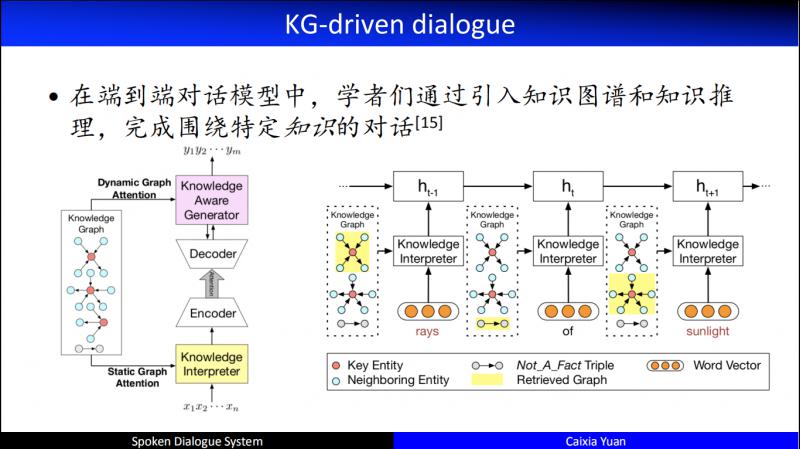
在端到端的對話模型 ( 閒聊 ) 中,也開始逐步地引入知識圖譜。下面介紹兩個比較具有代表性的引入知識圖譜後的人機對話。其中右邊是2018年 IJCAI 的傑出論文,清華大學黃民烈老師團隊的工作,引入了通過 KG 來表示的 Commonsense,同時到底在編碼器端還是在解碼器端引入知識,以及如何排序,排序的時候如何結合對話的 history 做知識的推理等等,都做了特別全面的研究。
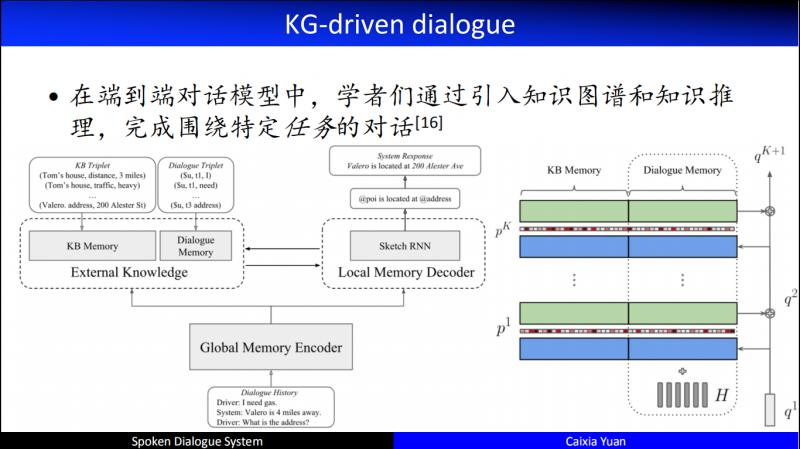
另一個比較有代表性的工作是在 ICLR2019 提出的,在架構中引入了 Local Memory 和 Global Memory 相融合的技術,通過這種融合,在編碼器端和解碼器端同時加入了知識的推理。

總結下 KB/KG-driven dialogue:
優點:
已經有大規模公開的資料 ( e.g.,InCar Assistant,MMD,M2M )。
訓練過程可控&穩定,因為這裡多數都是有監督學習。
缺點:
因為採用有監督的方式進行訓練,所以存在如下問題:
① 環境確定性假設
② 缺少對動作的建模
③ 缺少全域性的動作規劃
Agent 被動,完全依賴於訓練資料,所以模型是不賦予 Agent 主動性的。
構建 KB 和 KG 成本昂貴!
- Document-driven dialogue

Document 驅動的對話,具有如下優點:
① 應用場景真實豐富:
情景對話 ( conversation ),比如針對某個熱門事件在微博會產生很多對話,這就是一個情景式的對話。
電信業務辦理 ( service ),比如10086有非常多的套餐,如何從中選擇一個使用者心儀的套餐?每個套餐都有說明書,我們可以圍繞套餐的說明書和使用者進行互動,如 "您希望流量多、還是語音多",如果使用者回答 "流量多",就可以基於文字知道給使用者推薦流量多的套餐,如果有三個候選,機器就可以基於這三個候選和使用者繼續進行互動,縮小候選套餐範圍,直到使用者選出心儀的套餐。
電商產品推薦 ( recommendation ),可以根據商品的描述,進行各種各樣的對話。這裡的輸入不是一個 dialogue,也不是一個 KB,甚至結構化的內容非常少,完全是一個 free document,如何基於這些 document 進行推薦,是一個很好的應用場景。
互動式資訊查詢 ( retrieval ),很多時候,一次查詢的結果可能不能使用者的需求,如何基於非結構化的查詢結果和使用者進行互動,來更好地達成使用者的查詢目的。
......
② 資料獲取直接便捷:
相比於 dialogue、FAQ、KB、KQ 等,Document 充斥著網際網路的各種各樣的文字,都可以看成是文字的資料,獲取方便,成本非常低。
③ 領域移植性強:
基於文字,不再基於專家定義的 slot,也不再基於受限的 KB/KG,從技術上講,所構造的 model 本身是和領域無關的,所以它賦予了 model 很強的領域移植性。

這是我們正在進行的工作,情景對話偏向於閒聊,沒有一個使用者目標。這裡需要解決的問題有兩個:
如何引入文件:編碼端引入文件、解碼端引入文件
如何編碼文件:文件過長、冗餘資訊過多
資料:
我們在 DoG 資料的基礎上模擬了一些資料,形成了如上圖所示的資料集,分 Blind 和 Non-blind 兩種情形構造了不同的資料集。

我們發現,基於文字的端到端的聊天,有些是基於內容的閒聊,有些還需要回答特定的問題。所以,評價的時候,可以直接用 F1 評價回答特定問題,用閒聊通用的評價來評價基於內容的聊天。

剛剛講的是偏閒聊式的對話,接下來講下任務型對話。
這裡的動機分為兩種情況:單文件和多文件,我們目前在挑戰多文件的情況,單文件則採用簡單的多輪閱讀理解來做。
多文件要解決的問題:
如何定義對話動作:因為是基於Document進行互動,而不再是基於slot進行互動,所以需要重新定義對話動作。
如何建模文件差異:以剛剛10086的例子為例,總共有10個業務,通過一輪對話,挑選出3個,這3個業務每個業務可能都有10種屬性,那麼其中一些屬性值相同的屬性,沒必要再和使用者進行互動,只需要互動它們之間不同的點,所以互動的角度需要隨對話進行動態地變化。
資料:
這裡採用的資料是 WikiMovies 和模擬資料,具體見上圖。
- A very simple sketch of dialogue

上圖為任務型對話和非任務型對話的幾個重要節點,大家可以瞭解下。
03
Concluding remarks
任務型對話具有最豐富的落地場景。
純閒聊型對話系統的學術價值尚不清楚。
任務型和非任務型邊界愈加模糊,一個典型的人人對話既包括閒聊,又包括資訊獲取、推薦、服務。
引入外部知識十分必要,外部知識形態各異,建模方法也因而千差萬別。
Uncertainty 和 few-shot 問題,是幾乎所有的對話系統最大的 "卡脖子" 問題。
X-driven dialogue 中的 X 還有哪些可能?剛剛提到的 X 都還是基於文字的。事實上,從2005年開始,我們已經開始做 image 和文字資料融合的對話;從2013年開始做 Visual QA/Dialogue,挑戰了 GuessWhat 和 GuessWhich 任務。
X=multi media ( MM Dialogue ),X 還可以很寬泛的就是指多媒體,不光有 image 還可能有 text,2018年已經有了相關的任務,並且開源了非常多的電商業務。這是一個非常有挑戰性的工作,也使人機對話本身更加擬人化。
04
Reference
這是部分的參考文獻,有些是我們自己的工作,有些是特別傑出的別人的工作。



今天的分享就到這裡,感謝大家的聆聽,也感謝我們的團隊。

歡迎關注DataFunTalk同名公眾號,收看第一手原創技術文章