
文字自動生成研究進展與趨勢
摘要
我們期待未來有一天計算機能夠像人類一樣會寫作,能夠撰寫出高質量的自然語言文字。文 本自動生成就是實現這一目的的關鍵技術。按照不同的輸入劃分,文字自動生成可包括文字 到文字的生成、意義到文字的生成、資料到文字的生成以及影象到文字的生成等。上述每項 技術均極具挑戰性,在自然語言處理與人工智慧領域均有相當多的前沿研究,近幾年業界也 產生了若干具有國際影響力的成果與應用。本文對上述前沿技術的國內外研究現狀進行了全 面總結,並對發展趨勢進行了展望。
關鍵詞:自然語言生成、文字到文字的生成、意義到文字的生成、資料到文字的生成、影象到文字的生成
Abstract
We expect that computers can write high-quality natural language texts like human beings in the near future. Automatic text generation is the key technique for achieving this goal. According to different data types of inputs, automatic text generation techniques include text-to-text generation, meaning-to-text generation, data-to-text generation and image-to-text generation. All the above text generation techniques are very challenging, and they are the frontier research topics in the natural language processing and artificial intelligence fields. In recent years, a few internationally influential achievements and applications have been yielded in academia and industry. In this article, we conduct a comprehensive survey of recent advances of automatic text generation at home and abroad. We also discuss the research and development trends.
Keywords: natural language generation, text-to-text generation, meaning-to-text generation, data-to-text generation, image-to-text generation
1. 引言
文字自動生成是自然語言處理領域的一個重要研究方向,實現文字自動生成也是人工智慧走向成熟的一個重要標誌。簡單來說,我們期待未來有一天計算機能夠像人類一樣會寫作,能夠撰寫出高質量的自然語言文字。文字自動生成技術極具應用前景。例如,文字自動生成技術可以應用於智慧問答與對話、機器翻譯等系統,實現更加智慧和自然的人機互動;我們也可以通過文字自動生成系統替代編輯實現新聞的自動撰寫與釋出,最終將有可能顛覆新聞出版行業;該項技術甚至可以用來幫助學者進行學術論文撰寫,進而改變科研創作模式。
按照不同的輸入劃分,文字自動生成可包括文字到文字的生成(text-to-text generation)、意義到文字的生成(meaning-to-text generation)、資料到文字的生成(data-to-text generation) 以及影象到文字的生成(image-to-text generation)等。上述每項技術均極具挑戰性,在自然語言處理與人工智慧領域均有相當多的前沿研究,近幾年業界已產生了若干具有國際影響力的成果與應用。最值得一提的是,美聯社自 2014 年 7 月開始已採用新聞寫作軟體自動撰寫新聞稿件來報道公司業績,這大大減少了記者的工作量。美國洛杉磯時報也有一種用來撰寫突發新聞的應用軟體。美國已有多家公司能夠提供新聞寫作軟體與服務,比如美國“自動洞察力”公司(Automated Insights)已採用“語言專家”軟體撰寫了 3 億篇報道,包括橄欖球、財經報道。這些進展標誌著文字自動生成不再屬於紙上談兵的技術,而是已經對人類工作和生活產生了重大影響。
目前國內學界與工業界對文字自動生成技術的重視程度並不夠,普遍缺乏對該方向前沿技術與進展的瞭解。因此,本技術報告將首次對文字自動生成前沿技術進行綜合全面的調研、分析與總結,為國內同行提供一個全面瞭解文字自動生成技術的重要參考。同時,期望學界和工業界一起努力,儘早實現中文文字自動生成系統,搶佔中文文字自動生成技術的制高點。
需要指出的是,自然語言處理領域的自然語言生成技術專指從機器可讀資料生成自然語言文字的技術,而本文所介紹的文字自動生成技術的範疇則更加廣泛,還包括了文字到文字的生成技術、以及影象到文字的生成技術。
2.文字到文字的生成
2.1 國際研究現狀
文字到文字的生成技術主要指對給定文字進行變換和處理從而獲得新文字的技術,具體說來包括文字摘要(Document Summarization)、句子壓縮(Sentence Compression)、句子融合 (Sentence Fusion)、文字複述(Paraphrase Generation)等。國際上對上述不同技術均進行了多年的研究,相關研究成果主要發表在自然語言處理相關學術會議與期刊上,例如 ACL、EMNLP、NAACL、COLING、AAAI、IJCAI、SIGIR、INLG、ENLG 等。國際上幾個主要的研究單位包括密歇根大學、南加州大學、哥倫比亞大學、北德克薩斯大學、愛丁堡大學等。需要指出的是,機器翻譯從某種程度上也可看作是一種從源語言到目標語言的文字生成技術,但由於機器翻譯自身是相對獨立的一個研究領域,因此本文的內容不再涵蓋機器翻譯技術。
2.1.1 文字摘要
文字摘要技術通過自動分析給定的文件或文件集,摘取其中的要點資訊,最終輸出一篇短小的摘要(通常包含幾句話或上百字),該摘要中的句子可直接出自原文,也可重新撰寫所得。摘要的目的是通過對原文字進行壓縮、提煉,為使用者提供簡明扼要的內容描述。
根據不同的劃分標準,文件摘要可以主要分為以下幾種不同型別:
根據處理的文件數量,摘要可以分為單文件摘要和多文件摘要。單文件摘要只對單篇文件生成摘要,而多文件摘要則對一個文件集生成摘要。
根據是否提供上下文環境,摘要可以分為主題或查詢無關的摘要和主題或查詢相關的摘要。主題或查詢相關的摘要在給定的某個主題或查詢下,能夠詮釋該主題或回答該查詢;而主題或查詢無關的摘要則指不給定主題和查詢的情況下對文件或文件集生成的摘要。
根據摘要所採用的方法,摘要可以分為生成式和抽取式。生成式方法通常需要利用自然語言理解技術對文字進行語法、語義分析,對資訊進行融合,利用自然語言生成技術生成新的摘要句子。而抽取式方法則相對比較簡單,通常利用不同方法對文件結構單元(句子、段落等)進行評價,對每個結構單元賦予一定權重,然後選擇最重要的結構單元組成摘要。抽取式方法應用較為廣泛,通常採用的結構單元為句子。
根據摘要的應用型別,摘要可以分為標題摘要、傳記摘要、電影摘要等。這些摘要通常為滿足特定的應用需求,例如傳記摘要的目的是為某個人生成一個概括性的描述,通常包含該人的各種屬性,例如姓名、性別、地址、出生、興趣愛好等。使用者通過瀏覽某個人的傳記摘要就能對這個人有一個總體的瞭解。
文件自動摘要的研究在圖書館領域和自然語言處理領域一直都很活躍,最早的應用需求來自於圖書館。圖書館需要為大量文獻書籍生成摘要,而人工摘要的方式效率很低,因此亟需自動摘要方法取代人工高效地完成文獻摘要任務。隨著資訊檢索技術的發展,文件自動摘要在資訊檢索系統中的重要性越來越大,逐漸成為研究熱點之一。文件自動摘要技術的第一篇論文來自 Luhn (1958) [[1]],經過數十年的發展,同時在 DUC1與 TAC[2]組織的自動摘要國際評測的推動下,文字摘要技術已經取得長足的進步。值得一提的是,由南加州大學 Chin-Yew Lin 博士(現就職於微軟亞洲研究院)開發的摘要質量自動評估工具 ROUGE[3]的廣泛使用也是自動摘要技術快速發展的一個推動力。國際上文件自動摘要方面比較著名的幾個系統包括 ISI 的NeATS 系統[2],哥倫比亞大學的 NewsBlaster 系統[4] [3],密歇根大學的 NewsInEssence 系統[5] [4] 等。2013 年雅虎耗資 3000 萬美元收購了一項自動新聞摘要應用 Summly,標誌著新聞摘要技術走向成熟。
目前的文字摘要方法主要基於句子抽取,也就是以原文中的句子作為單位進行評估與抽取。這類方法的好處是易於實現,能保證摘要句子具有良好的可讀性。該類方法主要包括兩個步驟:一是對文件中的句子進行重要性計算或排序,二是選擇重要的句子組合成最終摘要。第一個步驟可採用基於規則的方法,利用句子位置或所包含的線索詞來判定句子的重要性;也可採用各種機器學習方法(包括深度學習方法),綜合考慮句子的多種特徵進行句子重要性的分類、迴歸或排序,例如 CRF[5], HMM[6], SVM[7][8], RNN[9]等。第二個步驟則基於上一步結果,需要考慮句子之間的相似性,避免選擇重複的句子(如 MMR 演算法[10]),並進一步對所選擇的摘要句子進行連貫性排列(如自底向上法[11]),從而獲得最終的摘要。近幾年學界進一步提出了基於整數線性規劃的方法[12][13][14]以及次模函式最大化的方法[15][16],可以在句子選擇的過程中同時考慮句子冗餘性。
不同於上述方法,壓縮式文字摘要方法則考慮對句子進行壓縮,以在較短長度限制下讓摘要涵蓋更多的內容。最有代表性的做法為同時進行句子選擇與句子壓縮[17][19][19],能夠取得更優的 ROUGE 效能。除了壓縮之外,部分工作還利用句子融合等技術來對已有句子進行變換,得到新的摘要句子[20][21]。
國際上還有部分研究者研究真正意義上的生成式摘要,也就是通過對原文件進行語義理解,將原文件表示為深層語義形式(例如深層語義圖),然後分析獲得摘要的深層語義表示(例如深層語義子圖),最後由摘要的深層語義表示生成摘要文字。最近的一個嘗試為基於抽象意義表示(Abstract Meaning Representation, AMR)進行生成式摘要[22]。這類方法所得到的摘要句子並不是基於原文句子所得,而是利用自然語言生成技術從語義表達直接生成而得。這類方法相對比較複雜,而且由於自然語言理解與自然語言生成本身都沒有得到很好的解決,因此目前生成式摘要方法仍屬於探索階段,其效能還不盡如人意。
上述摘要方法均面向新聞摘要,而近年來針對學術文獻的摘要越來越受到大家的重視。一方面,可以利用學術文獻之間的引用關係以及引文來幫助進行學術文獻摘要[23];另一方面,對學術文獻進行自動綜述也是一個很有意思的研究問題 [24]。更多的有關文字摘要技術的內容可參考綜述[25]。
2.1.2 句子壓縮與融合
句子壓縮與句子融合技術一般用於文字摘要系統中,用於生成資訊更加緊湊的摘要,獲得更好的摘要效果。
句子壓縮技術基於一個長句子生成一個短句子,要求該短句保留長句中的重要資訊,也就是重要資訊基本不損失,同時要求該短句是通順的。下面給出一個句子壓縮的例子:
原句:But they are still continuing to search the area to try and see if there were, in fact, any further shooting incidents.
壓縮後的句子:They are continuing to search the area to see if there were any further incidents.
學界嘗試了多種方法實現句子壓縮,包括從句子中刪除詞語[26],或對句子中的詞語進行替換、重排序或插入[27]。其中,從句子中直接刪除詞語的做法因其複雜程度較低而成為主流方法。研究人員提出多種方法用於實現基於詞語刪除的句子壓縮,包括噪聲通道模型[28],結構化辨別模型[29],樹到樹的轉換[30], 整數線性規劃[31],等等。但就總體效果而言,對於大部分句子所刪除的詞語一般較少,壓縮效果體現並不明顯。
句子融合技術則是合併兩個或多個包含重疊內容的相關句子得到一個句子。根據目的的不同,一類句子融合只保留多個句子中的共同資訊,而過濾無關的細節資訊(類似於集合運算中的取交集運算),另一類句子融合則只過濾掉多個句子之間的重複內容(類似於集合運算中的取並集運算)。下面給出兩個相關的句子以及人工合併後得到的句子:
句子 1:In 2003, his nomination to the U.S. Court of Appeals for the District of Columbia sailed through the Senate Judiciary Committee on a 16-3 vote.
句子 2:He was nominated to the U.S. Court of Appeals for the District of Columbia Circuit in 1992 by the first President Bush and again by the president in 2001.
合併後的句子(取交集):He was nominated to the U.S. Court of Appeals for the District of Columbia Circuit.
合併後的句子(取並集):In 2003, his nomination by the first President Bush, and again by the second Bush in 2001 to the U.S. Court of Appeals for the District of Columbia sailed through the Senate Judiciary Committee on a 16-3 vote.
針對句子融合問題,MIT 的 Regina Barzilay 和哥倫比亞大學的 Kathleen McKeown 提出一條流水線演算法,包括共同資訊識別(Identification of Common Information)、融合網格計算 (Fusion lattice computation)、網格線性化(Lattice linearization)三個步驟 [20]。研究人員針對句子融合問題提出的其它代表性方法包括基於結構化辨別學習的方法[32], 基於整數線性規劃的方法[33], 基於圖最短路徑的方法[34]等。
上述研究均面向英文,少數研究者在網上公開了所使用的資料集,但這些資料集的規模相對較小,覆蓋面較窄,業界也沒有組織過句子壓縮或融合相關的評測。近些年,與句子壓縮與句子融合技術相關的學術論文比較少見,與上述因素不無關係。
2.1.3 文字複述
文字複述生成技術通過對給定文字進行改寫,生成全新的複述文字,一般要求輸出文字與輸入文字在表達上有所不同,但所表達的意思基本一樣。文字複述生成技術應用相當廣泛,例如,在機器翻譯系統中可利用文字複述技術對複雜輸入文字進行簡化從而方便翻譯,在資訊檢索系統中可利用文字複述技術對使用者查詢進行改寫,在兒童教學系統中可利用文字複述技術將難以理解的文字簡化為兒童容易理解的文字。
根據實際的需求,通過複述生成技術得到的輸出文字與原文字相比,可以只是一兩個詞發生了改變(如例 1),也可以是整段文字面目全非(如例 2)。
例1:all the members of –> all members of
例2:He said there will be major cuts in the salaries of high-level civil servants. =>
He claimed to implement huge salary cut to senior civil servants.
簡單的文字複述生成可以通過同義詞替換來實現,也可以通過人工或自動構建的複述規則來實現[35],例如根據變換狀語位置的一條規則,可以獲得下面句子的簡單複述句子:
輸入:He booked a single room in Beijing yesterday.
輸出:Yesterday, he booked a single room in Beijing.
為了實現複雜的文字複述生成,研究人員提出了基於自然語言生成的方法[36]、基於機器翻譯的方法[37]與基於支點(Pivot)的方法[38][39]等。基於自然語言生成的方法模擬人類的思維方式,首先對輸入句子進行語義理解,獲得該句子的語義表示,然後基於得到的語義表示生成新的句子。基於機器翻譯的方法則將文字複述生成問題看作是單語言機器翻譯問題,從而利用現有機器翻譯模型(例如噪聲通道模型)來為給定文字生成複述文字。基於支點的方法則將當前語言中的輸入文字翻譯到另一種語言(支點),然後將翻譯得到的文字再次翻譯回當前語言。由於每次翻譯過程均要求源語言和目標語言中文字的語義保持一致,因此可以預期最後得到的文字在語義上能跟輸入文字保持一致。注意支點語言可以只採用一種語言,也可採用多種語言。例如,下面的例子中採用義大利語作為支點語言,通過兩次翻譯為輸入的英文句子生成複述文字:
輸入英文句子:What toxins are English most hazardous to expectant mothers?
翻譯後的義大利文句子:Che tossine sono più pericolose alle donne incinte?
再次翻譯後的英文句子:What toxins are more dangerous to pregnant women?
總體而言,現有方法能夠為給定文字生成具有較小差別的複述文字,但是難以有效生成高質量的具有很大差別的複述文字,原因在於對於改寫甚多的複述文字而言,一方面難以保證其與原文字的語義一致性,另一方面則難以保證該文字的可讀性。近幾年已經極少在自然語言處理重要會議上看到文字複述生成相關的學術論文,表明針對該問題的研究已經遇到了瓶頸。
需要指出的是,句子簡化(Sentence Simplification)可以看作是一類特殊的複述生成問題,其目的是將複雜的長句改寫成簡單、可讀性更好、易於理解的多個短句,方便使用者快速閱讀。在實現上仍可採用上述各類方法,例如基於單語言機器翻譯的方法[40],基於樹轉換的方法 [41] 等。針對句子簡化問題的很多研究都採用維基百科[6]以及對應的簡單維基百科[7]資料來進行學習和測試。簡單維基百科面向的閱讀物件為兒童以及正在學習英語的成人,簡單維基百科的作者要求使用簡單的詞彙和簡短的句子來撰寫文章。一個簡單維基百科文章一般對應一個普通維基百科文章,因此通過這種文字之間的對齊關係能夠獲取大量的有用語料。愛丁堡大學的 Kristian Woodsend 與 Mirella Lapata 則提出基於準同步文法(Quasi-synchronous grammar) 與整數線性規劃模型將普通維基百科文章簡化為簡單維基百科文章[42]。
2.2 國內研究現狀
2.2.1 文字摘要
相比機器翻譯、自動問答、知識圖譜、情感分析等熱門領域,文字摘要在國內並沒有受到足夠的重視。在文字摘要方面從事過研究的單位包括北京大學計算機科學技術研究所、北京大學計算語言所、哈工大資訊檢索實驗室、清華大學智慧技術與系統國家重點實驗室等。其中,北京大學計算機科學技術研究所在文字摘要方面進行了長期深入的研究,提出了多種基於圖排序的自動摘要方法[43][44][45][46]與壓縮式摘要方法[47],並且探索了跨語言摘要、比較式摘要、演化式摘要等多種新穎的摘要任務[4[8]][4[9]][50]。在學術文獻摘要方面,則分別提出基於有監督學習和整數線性規劃模型的演示幻燈片的自動生成方法[51]與學術論文相關工作章節的自動生成方法[52]。
國內早期的基礎資源與評測8舉辦過單文件摘要的評測任務,但測試集規模比較小,而且沒有提供自動化評價工具。2015 年 CCF 中文資訊科技專委會組織了 NLPCC 評測9,其中包括了面向微博的新聞摘要任務,提供了規模相對較大的樣例資料和測試資料,並採用自動評價方法,吸引了多支隊伍參加評測,目前這些資料可以公開獲得。但上述中文摘要評測任務均針對單文件摘要任務,目前還沒有業界認可的中文多文件摘要資料,這在事實上阻礙了中文自動摘要技術的發展。
近些年,市面上出現了一些文字挖掘產品,能夠提供文件摘要功能(尤其是單文件摘要),例如方正智思、拓爾思(TRS),海量科技等公司的產品。百度等搜尋引擎都能為檢索到的文件提供簡單的單文件摘要。這些文件摘要功能均被看作是系統的附屬功能,其實現方法均比較簡單。由於這些模組均未參加公開評測,因此其效能不得而知。
2.2.2 句子壓縮與融合
國內有少數單位與學者對句子壓縮問題進行了研究,例如北京大學語言計算與網際網路挖掘研究室提出基於對偶分解的句子壓縮方法[53],清華大學智慧資訊獲取研究小組提出基於馬爾科夫邏輯網的句子壓縮方法[54], 等等。而對於句子融合問題的研究,國內單位和學者基本沒有涉獵。
國內學者的上述研究仍面向英文資料,主要原因在於缺少相關的中文評測資料,而構建一個高質量的中文句子壓縮或融合評測資料集並不簡單,需要依靠對語言有深刻理解的標註者。
2.2.3 文字複述
國內有少數單位和學者對文字複述生成進行了一些研究,例如哈工大資訊檢索中心與微軟亞洲研究院、百度等單位合作,提出利用多種資源(包括多種詞典、平行語料等在內)改進基於機器翻譯的複述生成方法[55]、利用多種機器翻譯引擎的複述生成方法[56],以及面向不同應用的複述生成方法[57]。
上述研究仍面向英文領域,採用英文資料進行評測,而中文複述生成技術則極少有人涉足,這是一件很令人遺憾的事情。
2.3 發展趨勢與展望
文字到文字的生成包括多項任務,這些任務之間具有緊密的聯絡,很多方法也都對不同任務具有通用性。在未來幾年,隨著深層語義分析技術的發展,研究者可以在研究過程中充分利用深層語義分析結果,此外,深度學習技術的成熟則為我們的研究打開了另外一扇門,但是大家需要認真思考如何才能用好深層語義分析技術與深度學習技術。而隨著社交媒體的廣泛使用,我們也可充分利用社交媒體資料為我們的研究服務。
為了更好的推動文字到文字的生成技術的發展,業界可從以下幾個方面著手:
其一,構建大規模評測資料集。資料是研究的基石,大規模、高質量的評測資料集對於研究工作至關重要,而目前上述多個任務均缺少大規模評測資料集,尤其是中文評測資料集。資料集的構建需要耗費大量人力物力,因此一個可行的途徑就是採用眾包的方式。
其二,構建開源平臺。儘管針對上述各項任務業界均提出了多種解決方法,但很多方法並不易實現。業界需要為每個任務構建一個開源平臺,將主流演算法整合到該平臺中,將會極大方便後來者的研究,推動研究的發展。
3.意義到文字的生成
3.1 國際研究現狀
不同於文字到文字的生成,意義到文字的生成這一任務的輸入在學界並沒有達成一致,其根本在於不論是哲學家還是語言學家對何為自然語言的語義都未能形成較為一致的定義。
在計算語言學領域,研究人員普遍遵循的語義研究原則建立在“真值條件(Truth Condition)” 的基礎上,認為尋找到了能夠使自然語言語句成真的條件,即是在某種程度上刻畫了自然語言的語義。在真值條件假設基礎上,學者普遍採用邏輯的方法來對語義進行表徵,並分別從模型論(Model Theory)和證明論(Proof Theory)兩個角度來展開研究,很多學者也常常稱這型別的語義為邏輯語義。目前已有的意義到文字的生成研究,普遍假設使用邏輯語義表徵——以邏輯表示式為代表——作為輸入,而以自然語言語句作為輸出,本文也圍繞這些研究展開介紹。圖 3.1 給出了一個基於型別 λ 演算進行語義表徵的例項,在該例子中,問題的輸入是一個 λ 表示式,而輸出是一個英語句子。

圖3.1 λ表示式到文字的生成例項
意義到文字的生成和組合語義分析(Compositional Semantic Parsing)密切相關,語義分析旨在對線性的詞序列進行自動句法語義解析並得到其真值條件。因為在分析過程中遵循了弗雷格所提之組合原則(Principle of Compositionality),因而稱為組合語義分析,以與分散式語義(Distributional Semantics)相區別。組合語義分析是自然語言處理的一項核心技術,是邁向深度語義理解的一座重要橋樑,在多個自然語言處理核心任務中有著潛在應用,如智慧問答、機器翻譯等。從問題自身的定義來看,意義到文字的生成與組合語義分析是一對互逆的自然語言處理任務。在當前的國際研究中,僅專注於意義到文字的生成這一任務的學者並不多,部分以句法語義分析研究為主的學者會兼顧這方面的研究。
3.1.1 基於深層語法的文字生成
在早期的自然語言處理研究中,計算語言學發揮了很大的作用,計算語言學家從形式化、可計算的角度對自然語言進行建模,提出一系列的旨在解釋語言運作機理的句法語義模型,並根據這些模型構建自然語言處理系統。相關研究在上個世紀八九十年代取得了豐碩的研究成果,一系列兼具語言本體解釋力和可計算性的語法正規化(Grammar Formalism)被提出,如組合範疇語法(Combinatory Categorial Grammar;簡稱 CCG)[59]和中心語驅動的短語結構語法(Head-driven Phrase-Structure Grammar;簡稱 HPSG)[60]等。不同於目前句法分析所主要使用的上下文無關文法(Context-Free Grammar;簡稱 CFG),上述語法正規化具有超越上下文無關的表達能力,其語法推導過程往往更復雜,蘊含更多的資訊,而這些資訊可以用來做更透明的語義分析,簡單而言,這些深層語法正規化能夠更好地支援句法語義同步的語言分析。在深層語法的支撐下,通過句法語義的協同推導可以獲取自然語言的組合語義;而當以語義表徵作為輸入,通過其逆過程可以完成意義到文字的生成。
Shieber [61]提出了一個統一的框架用於進行句法語義分析與生成。在這一框架中,Shieber 將語言處理統一理解為邏輯推演(Deduction)過程,其差別在於推演的始點——公理——與推演的終點——目標——不同。在這一視角下,傳統的句法分析(Parsing)技術可以移植到文字生成上來,如線圖分析法(Chart Parsing)技術可以轉化為線圖生成(Chart Generation)技術[62]。Shieber 後續又同其他學者合作,將推演的思想細化,利用合一語法來表達句法語義介面(Syntax-Semantics Interface),提出了語義中心驅動的生成[63]。
深層語法複雜度較高,如何構造對錯綜複雜的語言現象具有高覆蓋度(Broad Coverage)的語法規則本身是一個極大的難題。以上研究主要是對原型演算法進行討論,而因為真實可用的大型深層語法當時沒有得到很好的開發,以上研究並沒有呈現極具代表性意義的經驗結果。經過十餘年的漫長開發,研究人員在 HPSG 理論的基礎上開發了英語資源語法(English Resource Grammar;簡稱 ERG)[10] [64],它是一個比較成功的具有較高覆蓋率的深層語法規則系統,而圍繞的 ERG 所展開的文字生成研究也取得了有益的進展。Carroll 和 Oepen [65]基於ERG 和真實測試資料重新討論了基於線圖的生成技術,給出了極具參考意義的經驗評估;另外,他們也提出了兩項新的技術來改進基於合一語法的可行解緊緻表示(Compact Representation)及其相關解碼演算法——Selective Unpacking,尤其後者,有效地利用了判別式學習模型來改進文字生成過程中所遇到的歧義消解。
組合範疇語法是一個廣受自然語言處理領域學者關注的語法正規化,其設計遵循了型別透明(Type Transparency)的原則,具有精簡的語法語義介面,常常被語義分析[66]和文字生成[67]模型所採用。White 和 Baldridge [67]討論瞭如何將線圖生成法與組合範疇語法結合,並開發了開源的基於組合範疇語法的句子實現(Realization)工具——OpenCCG[11]。White 又同其他學者聯合提出了一些進一步改進文字生成的演算法[68][69][70]。
3.1.2 基於同步文法的文字生成
在過去的二十年間,統計句法分析與統計機器翻譯是公認的兩個取得長足進步的自然語言處理任務。除了從成熟的統計句法分析中借鑑成功經驗——如判別式消歧——之外,不少學者也嘗試複用成功的機器翻譯模型來完成文字生成。機器翻譯的目標是將某種自然語言語句翻譯成另外一種自然語言的語句,並儘量保持意義不變;而文字生成則可以視為將某種形式語言語句翻譯成一種自然語言語句,二者具有極強的可比性。
Chiang [71]提出了層級基於短語的翻譯模型(Hierarchical Phrase-based Model),其核心是利用同步上下文無關文法(Synchronous Contex-Free Grammar)來協同源語言語句的解析和目標語言語句的生成。目前同步文法也已經被借鑑到文字生成的研究中[72][58]。Wong 與Mooney [72]兩位作者討論了兩種形式語言用於表徵意義:第一種是用於指揮機器人動作的形式語言,第二種是一種無變數的資料庫檢索語言;而 Lu 與 Ng [58] 則針對表達能力極強的型別 λ 表示式(Typed λ-expression)展開研究。兩項研究的共同點是構建形式語言的基於樹的結構,在將相關結構與待生成的自然語言的樹結構建立一致性對應,從而完成文字生成任務;另一個共同點則是廣泛地使用了現有的機器翻譯技術(包括開源軟體等)來進行文法抽取、解碼等。
3.2 國內研究現狀
國內語言學界與計算語言學界針對自然語言語義的形式化研究較少,針對漢語進行全方面組合語義刻畫的研究目前尚屬空白。另一方面,從事自然語言處理的研究人員也較少涉獵深層語言結構處理問題,而對意義到文字的生成研究則更是鮮有,很少能見到相關學術成果發表在重要學術會議和期刊上。
3.3 發展趨勢與展望
隨著深層自然語言理解的發展,研究者將越來越多的目光投向了意義到文字的生成這一自然語言生成核心任務上。意義到文字的生成這一任務隨著意義表徵體系的不同問題的複雜度也會隨之變化,傳統的基於深層語法分析的生成方法面臨的解碼效率差、語法魯棒性不夠等問題仍需要更好的技術解決方案。近些年來,有零星的一些工作嘗試將較為成熟的組合優化技術應用到在句法分析和機器翻譯,如拉格朗日鬆弛[73][74],嘗試去求解一些所涉及到的NP 難問題。應對意義到文字的生成這一複雜度高的問題,我們也可以嘗試應用相關技術。而針對深層語法魯棒性不夠的問題,基於資料驅動的語法近似(Grammar Approximation)[75] 取得了不錯的結果,結果顯示低階語法近似能夠有效改進深層語法分析的魯棒性,如何應用相關思想來解決文字生成中所遇到的問題也是一個非常值得研究的方向。
而就針對漢語的文字生成研究來說,需要國內外學界做出更大的努力。首先,在語言本體分析方面,需要學者們建立相關的語義表徵體系及針對漢語的特殊語言現象的分析,以支援漢語的深層處理。其次,在文字生成演算法方面,也需要我們投入更多的科研精力設計適合漢語自動生成的模型演算法等。
4.資料到文字的生成
4.1 國際研究現狀
資料到文字的生成技術指根據給定的數值資料生成相關文字,例如基於數值資料生成天氣預報文字、體育新聞、財經報道、醫療報告等。資料到文字的生成技術具有極強的應用前景,目前該領域已經取得了很大的研究進展,業界已經研製出面向不同領域和應用的多個生成系統。針對資料到文字的生成技術的研究單位主要集中少數幾個單位,例如英國阿伯丁大學、英國布萊頓大學、愛丁堡大學等,相關研究成果主要發表在 INLG、ENLG 這幾個專業學術會議上。
英國阿伯丁大學的 Ehud Reiter 在三階段流水線模型[76]的基礎上提出了資料到文字的生成系統的一般框架,見下圖:

圖4.1 資料到文字的生成系統的一般框架
其中:
訊號分析模組(Signal Analysis)的輸入為數值資料,通過利用各種資料分析方法檢測資料中的基本模式,輸出離散資料模式。例如股票資料中的峰值,較長期的增長趨勢等。該模組與具體應用領域和資料型別相關,針對不同的應用領域與資料型別所輸出的資料模式是不同的。
資料闡釋模組(Data Interpretation)的輸入為基本模式與事件,通過對基本模式和輸入事件進行分析,推斷出更加複雜和抽象的訊息,同時推斷出它們之間的關係,最後輸出高層訊息以及訊息之間的關係。例如針對股票資料,如果跌幅超過某個值則可以建立一條訊息。還需要檢測訊息之間的關係,例如因果關係、時序關係等。值得說明的是,資料闡釋模組並不是在所有文字生成系統中都需要,例如,在天氣預報文字生成系統中,基本的模式足以滿足要求,因此並不需要採用資料闡釋模組。
文件規劃模組(Document Planning)的輸入為訊息及關係,分析決定哪些訊息和關係需要在文字中提及,同時要確定文字的結構,最後輸出需要提及的訊息以及文件結構。從更高的層次來說,訊號分析與資料闡釋模組會產生大量的訊息、模式和事件,但文字通常長度受限,只能描述其中的一部分,因此文件規劃模組必須確定文字中需要說明的訊息。一般可根據專家知識、訊息的重要性、新穎性等來進行選擇和確定。當然,該模組與領域也很相關,不同領域中對訊息的選擇所考慮的因素不一樣,文件的結構也會不一樣。
微規劃與實現(Microplanning and Realisation)模組的輸入為選中的訊息及結構,通過自然語言生成技術輸出最終的文字。該模組主要涉及到對句子進行規劃以及句子實現,要求最終實現的句子具有正確的語法、形態和拼寫,同時採用準確的指代表達。所採用的技術在學術界有相當多的研究,具體可參考本文第 3 節“意義到文字的生成”。
目前,業界已經研製了面向多個領域的資料到文字的生成系統,這些系統的框架與上述一般框架並無大的差別,部分系統將上述框架中的兩個模組合併為一個模組,或者省去了其中一個模組。
資料到文字的生成技術在天氣預報領域應用最為成功,業界研製了多個系統對天氣預報資料進行總結,生成天氣預報文字。例如,FoG 系統[78]能夠從使用者操作過的資料中生成雙語天氣預報文字;SumTime 系統[79]能夠生成海洋天氣預報文字,實驗評測表明使用者有時候更傾向於閱讀 SumTime 所生成的天氣預報,而非專家撰寫的天氣預報[80]。此外,英國阿伯丁大學的 Anja Belz 提出概率生成模型進行天氣語言文字的生成[81]。Anja Belz 和 Eric Kow 進一步基於天氣預報資料分析對比了多種資料到文字的生成系統,結果表明採用自動化程度較高的方法並不會降低文字生成質量,同時文字質量的自動評價方法會低估基於手工規則構建的系統,而高估自動化系統[82]。
業介面向其他領域也研製多個文字生成系統,例如針對空氣質量的文字生成系統[83],
針對財經資料的文字生成系統[84],面向醫療診斷資料的文字生成系統 TOPAZ[85]、Suregen [86]、
BT-45 [87]等。其中 BT-45 能夠為新生兒重症監護病房(NICU)的監控資料生成文字摘要,幫助醫生進行決策。下面兩張圖分別給出了 BT-45 系統的輸入樣例與生成得到的文字。
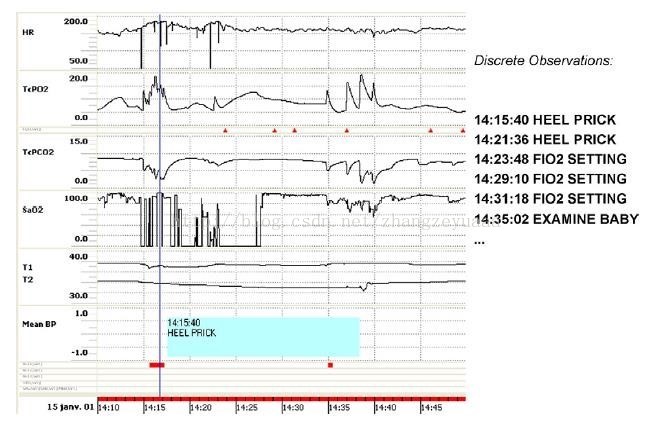
圖4.2 NICU 資料樣例,從上到下分別表示 HR, TcPO2, TcPCO2, SaO2, T1 & T2, and Mean BP [Portet et al., 2009]

圖4.3 BT-45 系統生成的對應文字 [Portet et al., 2009]
由於資料到文字的生成技術的巨大應用價值,工業界成立了多家從事文字生成的公司,能夠為多個行業基於行業資料生成行業報告或新聞報道,從而節省大量的人力。比較知名的公司有 ARRIA[12]、AI[13]、NarrativeScience[14]等。其中 ARRIA 是一家總部設在歐洲的公司,其前稱為 Data2Text,由來自阿伯丁大學的兩名教授 Ehud Reiter 與 Yaji Sripada 創辦,後來自然語言生成領域的另一位科學家 Robert Dale 也加入了該公司,該公司的核心技術為 ARRIA NLG 引擎。AI (Automated Insights) 則是一家美國人工智慧公司,由一名思科的前工程師 Robbie Allen 所創辦,最早基於體育資料生成文字摘要,目前能為包括金融、個人健身、商業智慧、網站分析等在內的多個領域內的資料生成文字報告,其核心技術為 WordSmith NLG 引擎。目前,AI 公司已經為美聯社等多家單位生成數億篇新聞報道,造成了巨大的影響力。NarrativeScience 則是根據美國西北大學的一個研究專案 StatsMonkey 發展而來,其核心技術為 Quill NLG 引擎。Forbes 是 NarrativeScience 的一個典型客戶,在網站上有個 NarrativeScience 專頁[15],全部文章都是由 NarrativeScience 自動生成。下面給出一篇自動生成的樣例新聞:
圖4.4 NarrativeScience 自動生成的樣例新聞
4.2 國內研究現狀
國內學術界對資料到文字的生成鮮有研究,也很少見到相關學術成果發表在重要學術會議和期刊上。國內工業界則有部分單位研製了基於模板的文字生成系統。例如新華社已開發了從財報資料生成企業財報年報的系統,該系統基於人工模板,將需要的資料填入寫好的模板中,從而生成財報年報。由於採用的模板比較固定,所以為不同企業生成的財報年報都比較類似,而不夠生動。
4.3 發展趨勢與展望
從資料到中文文字的生成技術很有研究意義,同時實用性很強。如果能實現從資料到中文新聞的生成,那麼將極大緩解編輯和記者的負擔,實現媒體、出版行業的變革。而實現這樣的系統,必須依靠科研院所和新聞出版機構的合作,新聞出版機構能夠提供大量的資料和專家知識,而科研院所則擅長自然語言理解與生成的理論與方法。
此外,要研製一套通用的面向不同領域的資料到文字的生成系統相當複雜和困難,因此一個更好的做法是先選擇一兩個領域(如財經、體育)進行系統研製,待系統成熟後再考慮將系統遷移到其他領域。
5.影象到文字的生成
5.1 國際研究現狀
影象到文字的生成技術是指根據給定的影象生成描述該影象內容的自然語言文字,例如新聞影象附帶的標題、醫學影象附屬的說明、兒童教育中常見的看圖說話、以及使用者在微博等網際網路應用中上傳圖片時提供的說明文字。依據所生成自然語言文字的詳細程度及長度的不同,這項任務又可以分為影象標題自動生成和影象說明自動生成。前者需要根據應用場景突出影象的核心內容,例如,為新聞圖片生成的標題需要突出與影象內容密切關聯的新聞事件,並在表達方式上求新以吸引讀者的眼球;而後者通常需要詳細描述影象的主要內容,例如,為有視力障礙的人提供簡潔詳實的圖片說明,力求將圖片的內容全面且有條理的陳述出來,而在具體表達方式上並沒有具體的要求。
對於影象到文字的自動生成這一任務,人類可以毫不費力地理解影象內容,並按具體需求以自然語言句子的形式表述出來;然而對於計算機而言,則需要綜合運用影象處理,計算機視覺和自然語言處理等幾大領域的研究成果。作為一項標誌性的交叉領域研究任務,影象到文字的自動生成吸引著來自不同領域研究者的關注。自2010年起,自然語言處理界的知名國際會議和期刊ACL、TACL和EMNLP中都有相關論文的發表;而自2013年起,模式識別與人工智慧領域頂級國際期刊IEEE TPAMI以及計算機視覺領域頂級國際期刊IJCV也開始刊登相關工作的研究進展,至 2015 年,計算機視覺領域的知名國際會議 CVPR 中,更是有近10篇相關工作的論文發表,同時機器學習領域知名國際會議ICML中也有2篇相關論文發表。影象到文字的自動生成任務已被認為是人工智慧領域中的一項基本挑戰。
與一般的文字生成問題類似,解決影象到文字的自動生成問題也需要遵循三階段流水線模型[76],同時又需要根據影象內容理解的特點,做出一些調整:
在內容抽取方面,需要從影象中抽取物體、方位、動作、場景等概念,其中物體可以具體定位到影象中的某一具體區域,而其他概念則需要進行語義標引。這部分主要依靠模式識別和計算機視覺技術。
在句子內容選擇方面,需要依據應用場景,選擇最重要(如影象畫面中最突出的,或與應用場景最相關的),且意義表述連貫的概念。這部分需要綜合運用計算機視覺與自然語言處理技術。
最後,在句子實現部分,根據實際應用特點選取適當的表述方式將所選擇的概念梳理為合乎語法習慣的自然語言句子。這部分主要依靠自然語言處理技術。
早期工作主要依照上述三階段的流水線模式來實現。例如,在Yao等人的工作[88]中,影象被細緻的分割並標註為物體及其組成部分,以及影象所表現的場景,並在此基礎上選擇與場景相關的描述模板,將物體識別的結果填充入模板得到影象的描述文字。而 Feng 與Lapata[89][90]則採用概率圖模型對文字資訊和影象資訊同時建模,並從新聞圖片所在的文字報道中挑選合適的關鍵詞作為體現影象內容的關鍵詞,並進而利用語言模型將所選取的內容關鍵詞、及必要的功能詞彙連結為基本合乎語法規則的影象標題。還有一些工作[91] [92][93] [94][95]則依靠計算機視覺領域現有的物體識別技術從影象中抽取物體(包括人物、動物、花草、車、桌子等常見的物體型別),並對其定位以獲得物體之間的上下位關係,進而依賴概率圖模型和語言模型選取適當的描述順序將這些物體概念、介詞短語塊串聯成完整的句子。Hodosh等人[96]則利用基於核函式的典型關聯分析(Kernel Canonical Correlation Analysis,KCCA)來尋找文字與影象之間的關聯,並依據影象資訊對候選句子排序,從而獲得最佳描述句子。值得說明的是,Hodosh等人的工作[96]和Feng與Lapata的工作[90][91]均沒有依靠現有的物體識別技術。
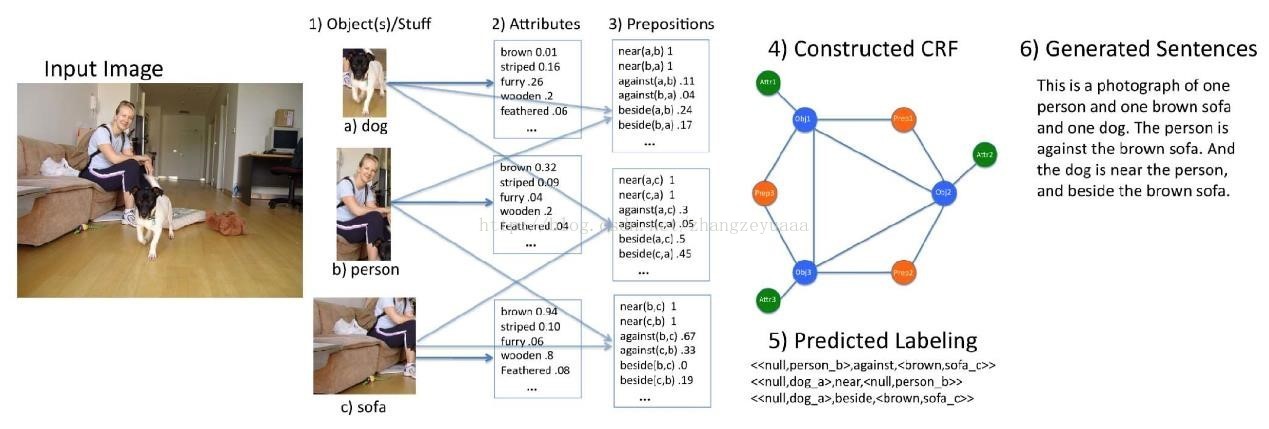
圖5.1 一種典型的流水線模型
隨著深度學習方法在模式識別、計算機視覺及自然語言處理領域的廣泛應用,基於海量資料的大規模影象分類、語義標註技術得到了快速發展;同時,統計機器翻譯等與自然語言生成相關的技術也有了顯著的提高。這也催生了將影象語義標註及自然語言句子生成進行聯合建模的一系列工作,一方面在影象端採用多層深度卷積神經網路(Deep Convolution Neural Network,DCNN)對影象中的物體概念進行建模,另一方面在文字端採用迴圈神經網路(Recurrent Neural Network,RNN)或遞迴神經網路(Recursive Neural Network)對自然語言句子的生成過程進行建模[97]。傳統影象語義標註工作主要關注具體某個物體的識別以及物體之間的相對位置關係,而對動作等抽象概念的關注較少。Socher 等人 [98] 提出利用遞迴神經網路對句子建模,並利用句法解析樹突出對於動作(動詞)的建模,進而將影象端與文字端進行聯合優化,較好的刻畫了物體與動作之間的關係。為了將兩種不同模態的資料統一在一個框架下,Chen與Zitnick[99]將文字資訊與影象資訊融合在同一個迴圈神經網路中,利用影象資訊作為記憶模組,從而指導文字句子的生成,同時又藉助於一個重構影象資訊層,實現了影象到文字、文字到影象的雙方向表示。而Mao等人[100]則通過DCNN得到的影象資訊與文字資訊融合到同一個迴圈神經網路(m-RNN)中,將影象資訊融入到了自然語言句子生成的序列過程中,取得了不錯的結果。類似的想法也被 Donahue 等人[101]應用於動作識別和視訊描述生成過程中。但在m-RNN的句子生成過程中,在影象端並沒有顯著的約束,例如在下圖中,當生成單詞“man”的時候,並沒有與影象資訊中的任務標註發生直接或間接的關聯。