
RALM: 實時 Look-alike 演算法在微信看一看中的應用

嘉賓:劉雨丹 騰訊 高階研究員
整理:Jane Zhang
來源:DataFunTalk
出品:DataFun
注:歡迎關注DataFunTalk同名公眾號,收看第一手原創技術文章。
導讀:本次分享是微信看一看團隊在 KDD2019 上發表的一篇論文。長尾問題是推薦系統中的經典問題,但現今流行的點選率預估方法無法從根本上解決這個問題。文章在 look-alike 方法基礎上,針對微信看一看的應用場景設計了一套實時 look-alike 框架,在解決長尾問題的同時也滿足了資訊推薦的高時效性要求。
▌背景
微信大家可能都用過,微信中的“看一看”是 feed 推薦流的形式,涵蓋了騰訊整個生態鏈的內容分發平臺,包括騰訊新聞、公眾號文章、騰訊視訊等。每天總分發量在千萬級以上,面對如此大的分發量,要滿足不同興趣偏好的使用者需求,使用傳統的方法時遇到了一些問題。我們針對發現的問題做了優化和改進,接下來分享下我們優化的過程。
▌未緩解的馬太效應
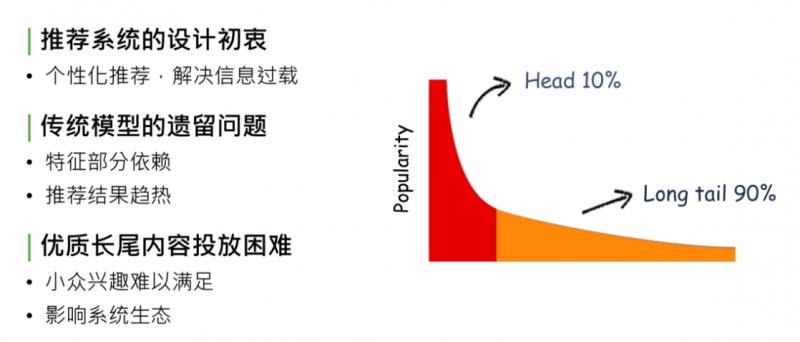
馬太效應,簡單解釋,在內容的生態系統中,自然分發狀態會造成一種現象:頭部10%的內容佔據了系統90%的流量、曝光量or點選量,剩下90%的內容,集中在長尾的10%裡。這對於內容的生產方、內容系統的生態和使用系統的使用者來說,都是不健康的狀態。造成這種現象的原因,是因為系統分發能力不夠強,無法處理資訊過載的現象,推薦系統設計的初衷就是為了解決馬太效應問題。
回顧推薦系統的發展,從最開始的規則匹配 -> 協同過濾 -> 線性模型 -> deep learning,逐步緩解了馬太效應現象,但沒有完全解決。
造成這個現象的原因是傳統模型、CTR 預估和 deep model,都對部分特徵有依賴,沒有把特徵完全發掘出來,導致模型推薦結果是趨熱的,使生態系統內優質長尾內容投放依然困難。因為 CTR model 最終趨向於行為特徵,或者後驗結果較好的資料,對於優質長尾內容,如小眾興趣的音樂、電影、深度報道的新聞專題等,獲得的相應曝光依舊困難,處於馬太效應 long tail 90%的部分,這會影響推薦系統的生態,導致推薦系統內容越來越窄。
▌為什麼無法準確投放長尾?
怎樣解決這個問題?這個問題歸根結底是對內容的建模不夠完整。我們嘗試分析下問題出在哪:
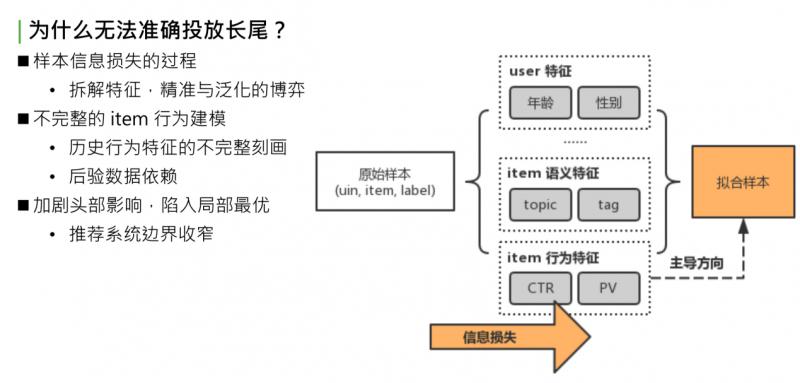
先看下推薦系統建模流程。首先得到原始樣本,這是業務下的訓練資料,形式是三元組:userid,itemid 和 label。如果是 timeline 的樣本,那就是點選或者不點選。原始樣本中,一條樣本可以完整表示一個使用者在某個時間點對一個 item 產生了一次行為,把這個三元組當作資訊的最完整形式。對於這個完整形式,直接建模很簡單,如傳統的 item CF,或者協同過濾。協同過濾是最初級的方法,直接對 uid,itemid,label 做擬合,因為可以完全利用初始樣本的資訊,擬合的準確性非常好。弱點也很明顯,對原始樣本中沒有包含的 userid 或者 itemid,沒有泛化推理能力,後續新曝光的 user 和 item 是無法處理的。這個問題,就是我們要做的第二步驟,對原始樣本做抽象。既然無法獲取所有的 userid 和 itemid,那就要對 user 或者 item 做一層抽象,如 user 抽象成基礎畫像:年齡、性別或所處地域;item 抽象成語義特徵:topic、tag 等;item 歷史行為特徵,簡單做統計:過去一段時間的點選率、曝光率、曝光次數。最後基於泛化過的特徵做擬合,得到最終模型。
問題出在哪?做原始特徵抽象,抽象意味著發生了資訊損失,這部分資訊損失導致模型擬合時走向了比較偏的道路。舉個簡單的例子:同一個 item,有相同的 topic tag,歷史點選率和歷史曝光次數和點選次數也相同,可以說這兩個 item 是相同的嗎?顯然有可能是不同的。使用統計特徵無法完整表達,同樣的 item 點選都是0.5,PV 都是1000 or 2000。有些 item 被這群使用者看過,有些 item 被那群使用者看過。儘管語義特徵和行為特徵都相同,但兩群 user 不同,Item 的受眾也不同。這裡說的抽象的方式,是不完整的 item 行為建模,也是對 item 歷史行為不完整的刻畫,這就導致了整個 model,對 item 後驗資料十分依賴,導致推薦結果趨向於 CTR 表現好或者 PV 表現好的 item。最終後驗資料表現好的資料又會更進一步被模型推薦且曝光,這樣會造成惡性迴圈:一方面,加劇了頭部效應的影響,使模型陷入區域性最優;另一方面,整個推薦系統邊界效應收窄,使用者趨向於看之前表現好的資料,很少看到能拓寬推薦系統邊界或者使用者視野的長尾資料。
▌Look-alike 模型
問題就是這樣產生的, 可以思考一下,問題的本質是什麼?就是因為模型無法對 item 行為完整建模,這一步資訊損失太大,怎麼解決這個問題呢?我們首先想到了一種方案:look-alike。
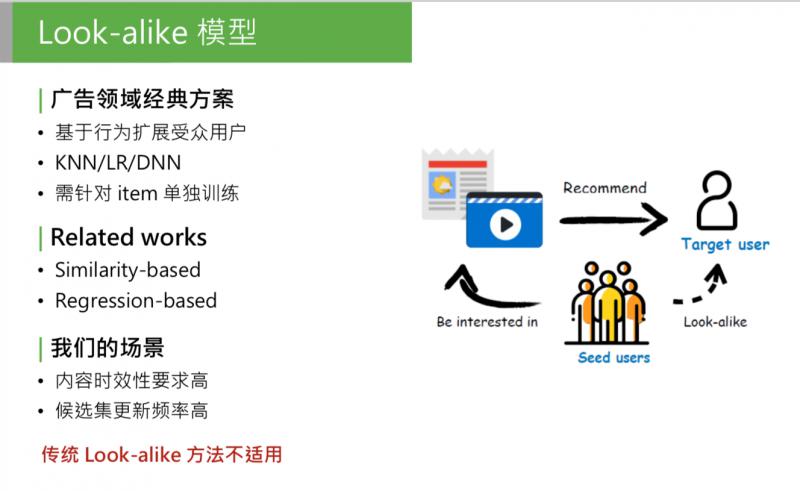
這是廣告領域的經典方案,這類模型的方法也很簡單,首先可以有一個候選集合的 item,我們要推這部分 item,怎麼推呢?第一個步驟:找到歷史上已知的、廣告主提供的對 item 表達過興趣的使用者,這部分使用者稱為種子使用者。然後使用使用者相似度法方法,找到和種子使用者最相似的目標人群,稱為目標使用者,把這部分 item 直接推給目標使用者。這個方法在廣告系統中,是用來做定向投放的,效果很好。為什麼呢?我們來看下模型的整體思路。
把相關的 item 找到對它發生過歷史行為的種子使用者,直接用種子使用者的特徵,作為模型的輸入,這是正樣本;從全域性使用者中負取樣一部分使用者作為負樣本。用歷史行為的使用者的特徵來學習 item 的歷史行為,相當於把不同使用者看過的 item 區分開,其實是對 item 的歷史行為特徵的完整建模。之前提到,行為樣本是資訊量最大的樣本,它們沒有經過抽象,如果能完整的用受眾使用者的行為來計算 item 的特徵,可以說是最完整的 item 歷史特徵的建模。
Look-alike 在廣告領域的應用已經很完善,也有很多方式。可以把 look-alike 相關的研究分成兩個方向:第一種是基於相似度的 look-alike,這種 look-alike 比較簡單,大體思路是把所有使用者做 user embedding,對映到低維的向量中,對它做基於 k-means 或者區域性敏感 hash 做聚類,根據當前使用者屬於哪個聚類,把這個種子使用者的類感興趣的內容推給目標使用者。這種方法的特點:效能強。因為簡單,只需要找簇中心,或者向量相似度的計算,因為簡單、效能好,模型準確性低。
第二種是和第一種相反的,基於迴歸。包括 LR,或者樹模型,或者 DNN or deep model 的方法,主要思路是直接建模種子使用者的特徵。把種子使用者當做模型的正樣本, 針對每個 item 訓練一個迴歸模型,做二分類,得出種子使用者的特徵規律。這種方法的優點是:準確性高,因為會針對每個 item 建模。缺點也明顯:訓練開銷大,針對每個 item 都要單獨訓練一個模型。對於廣告來說,可以接受,因為廣告的候選集沒有那麼大,更新頻率也沒那麼高。
但是對於我們的推薦場景,有一些問題:1. 對內容時效性要求高,如推薦的新聞專題,必須在5分鐘或10分鐘內要觸達使用者;2. 候選集更新頻率高,我們每天的候選集上千萬,每分鐘、每一秒都有新內容,如果新內容無法進入推薦池,會影響推薦效果。
▌核心需求

在我們的場景下,如果還用廣告領域的經典的 look-alike,是無法解決的。如果要對每個候選集建模,採用 regression-base 的方法,如每分鐘都要對新加進來的候選集做建模,包括積累種子使用者、做負取樣、訓練,等模型收斂後離線預測 target user 的相似分,這對於線上的時效性是不能接受的。
對於 similarity base 的方法,它的問題是計算過於簡單,如果直接和 CTR 模型 PK,核心指標會下降,得出來的結論是:傳統的 look-alike 不能直接照搬到我們的系統中。
針對我們的需求,我們整理出來了應該滿足的3點核心需求:
實時。新 item 分發不需要重新訓練模型,要能實時完成種子使用者的擴充套件;
高效。因為線上加到 rank 模型 CTR 的後面, 要保持模型核心指標 CTR 的前提下,再去加強長尾內容分發,這樣模型才有意義。要學習準確性和多樣性的使用者表達方式。
快速。Look-alike 模型要部署到線上,實時預測種子使用者和目標使用者群體的相似度,要滿足線上實時計算的耗時效能要求,也要精簡模型預測的計算次數。
▌RALM:Real-time Attention based Look-alike Model
基於這三個核心需求,我們提出了一個新的方法,全稱是 real-time attention based look-alike model,簡稱 RALM。我先簡單講下 RALM 核心的三個點。
- 核心點
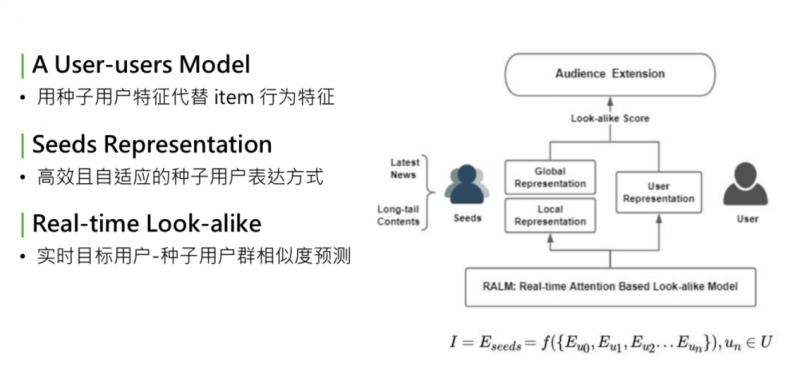
① 模型可總結為 user-users 的 model。回想下經典的 CTR 預估模型,是 user2item 的 point-wise 的處理流程建模。User、item、label,我們做的最大的變化,是借鑑了 look-alike 的思想,把 item 替換成種子使用者。用種子使用者的使用者特徵,代替 item 的行為特徵。所以模型從 user2item 的 model,變成 user2user 的 model。圖中右側是 target user,左側是 seeds。
② 完善的 seeds representation。用種子使用者代替 item 行為特徵。這樣面臨的問題是:怎樣更好地表達一個人群。這個 seeds representation,是我們研究中的核心步驟,要得到一個高效、自適應更新的種子使用者的表達方式。
③ real-time。最終目標是部署在線上,實時預測種子使用者群體相似度,需要是能夠實現 real-time 的框架。
上述是模型表達的思路。I 是一個 item,把 item 用 seeds 的 embedding 的集合來表示,seeds embedding,是組成這個種子使用者的每個使用者的 embedding 的函式。學習了 seeds representation,就是這個函式 f。
- 整體結構
接下來看下離線訓練部分,這是離線訓練的整體結構。
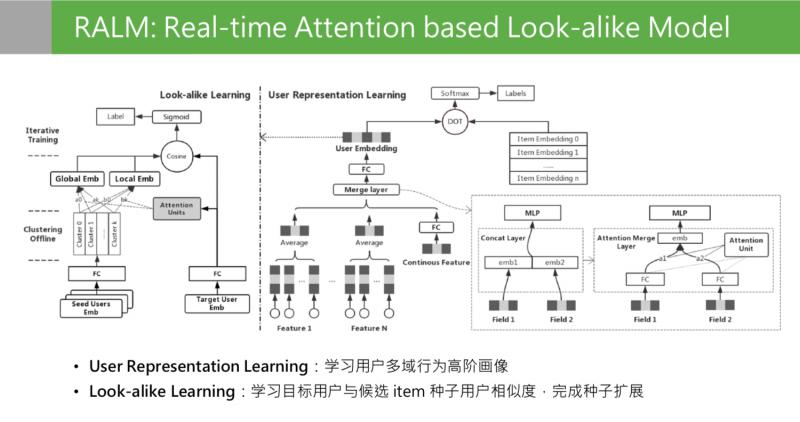
模型離線訓練分成兩個階段:右側 user representation learning, 左側第二階段是 look alike learning。user representation learning 模型結構,最後的目標是通過一個使用者在不同領域的行為,學習到使用者在所有領域的多樣性且兼顧準確性的使用者興趣的高階畫像。這個畫像在這個位置是低維特徵,向量特徵通過 user presentation learning 的目標學到了所有使用者的 embedding 之後,第二階段是 look alike learning。Look alike learning 模型,是一個 user to user 的 model,右側是目標使用者的特徵輸入,左側是種子使用者人群的 embedding 輸入,左邊種子使用者是一群使用者的 embedding 堆疊到一起,輸入其實是一個矩陣。這兩邊的輸入來源都是第一階段 representation learning 輸出的 embedding。Look alike 的目標是學習目標使用者和候選 item 種子使用者的相似度,最上面是學習兩次相似分的,最後完成種子使用者的擴充套件。
▌User Representation Learning
按順序來分析下,第一階段,是使用者的表示學習,user representation learning。
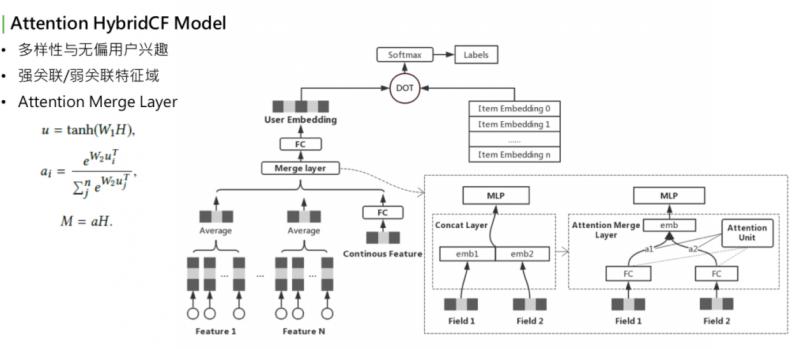
這個模型大家看著會比較眼熟,它是用 Youtube 的 representation model 中演化過來的。Youbute 的基礎模型很簡單,下面是使用者在不同領域的行為,下面的基礎特徵可能會有離散值,也可能是連續值。如果是離散值,可以通過 embedding lookup,再過一個 pooling,再和所有領域的特徵做 merge,上面過一個全連線,最後輸出 embedding。右側是感興趣的 item,也會做一些 embedding lookup,整個做 sce loss,或者是多分類。要預測的是:使用者在點選了這麼多 item 之後,下一個要點選的 item,最後要預測的就是表達使用者興趣的 embedding。這層 merge layer,最初 Youtube 的版本是用一個 concat。可以看到最初版模型在訓練時遇到了一個問題,最下層是用到了使用者很多個域 ( 每個 field 稱為一個域,可能是每個使用者在每個分佈下的行為,如電商購物下行為,或者是公眾號閱讀的行為 )。
訓練時看到一個現象,有些域的行為學的非常強,引數來看學的非常充分,某些 field 引數分佈不大,最後的權重值較小,對最終預估的分數沒有影響。這裡有兩個名詞:強關聯和弱關聯。最終預估結果關係比較大的 field、引數學習較強的,稱為強關聯特徵域;相反,學的不充分的、對最終結果影響小的,稱為弱關聯特徵域。對於強關聯和弱關聯,如果看到引數分佈是這樣的,是不是就表明弱關聯特徵不重要呢?並不是。舉例來說,representation learning 如果訓練目標是在“看一看”中的閱讀行為,對於某些經常使用微信公眾號、或者閱讀的使用者來說,他們在公眾號平臺的閱讀歷史就是非常強的關聯特徵,能夠決定再看一看中的興趣。對於這些特徵來說,這些特徵是很強的,對於其他的如在電商中的購物或者是在搜尋中的 query,這些是比較弱的,對看一看的影響很有限。再思考另一種 case,比如,看一看通過某種形式,吸引了很多新使用者。新使用者進來之後,沒有在公眾號平臺的閱讀歷史,但是他們在購物或者搜尋中有歷史行為,此時這些歷史行為會影響他下一次閱讀的文章,或者感興趣的 item。這些特徵對這些使用者來說是非常重要的。但目前,顯然這些使用者是沒有學到這些變化的。
排查了下模型訓練的過程,可以把結果集中在這一點上,就是這個 merge layer,其實是負責把使用者不同域的特徵 merge 到一起。Merge layer,可以看到右側的圖,原始的 deep model 用的是左側的實現方法,直接用 concat。Concat 的優點是,可以學到所有 field 的引數,缺點是,無法根據輸入的不同分佈,來調整權重值。也就是說,如果80%的使用者的閱讀歷史都是看一看的種子使用者,閱讀歷史都是很豐富的,就很有可能對所有使用者都把這個特徵學的很強。如果是少量使用者,就學不到了,少量使用者關注對其它特徵的啟發作用,concat layer 是學不到的。因為它對於大部分使用者來說,已經把引數學的非常重了,小部分使用者不足以對它產生影響。所以需要一個機制,針對不同使用者的特徵域的輸入動態調整 merge layer 的方式,我們想到的最好的辦法是 attention。Attention 是最近在 NLP 中非常火的,很多模型都會用到。為什麼要用 attetnion?
右下角的結構,就是 attention。我們用到的 attention 是把使用者的輸入的所有的域當做 attention 的 query,key 和 value 都是自身 field 的本身。這是一個典型的 self-attetnion,我們最後要做的是,讓模型根據使用者自己的輸入領域的情況,動態調整不同領域的融合方式,相對於之前的 concat 的方式來說,concat 其實是把所有領域的 field 強行放在同一個向量空間中來學習,自然會有學習不充分的情況。Self-attenion merge 是讓不同的域在自己的向量空間中學習充分,再通過不同的權重組合在一起。其實是相當於讓使用者能有屬於自己的表達,而不是被歷史豐富的使用者帶著走。這是一個優化,可以明顯改善強弱特徵、訓練不均衡的問題。
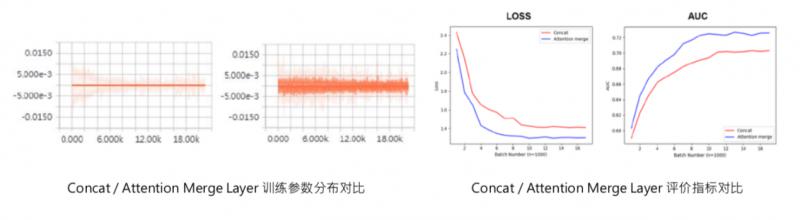
可以看一下這是我之前訓練的時候在某個特徵域用 tensorboard 打出來的引數分佈的情況,可以看到 attention merge layer 前後,訓練引數有很大變化,之前這些引數基本上都是0,之後會激活出一些值,這個是最後 user presentat learning 的值:precession、recall、auc。也可以看到模型加完 attention 之後,在 auc 和 loss 上都有所優化。
經過 user representation learning 之後,我們現在擁有了所有使用者的兼顧多樣性和準確性的 embedding 表達。接下來要做的是怎麼用 embedding 來表達種子使用者人群?
▌Look-alike learning
Look-alike 要做的第一步就是如何表達 seeds user。
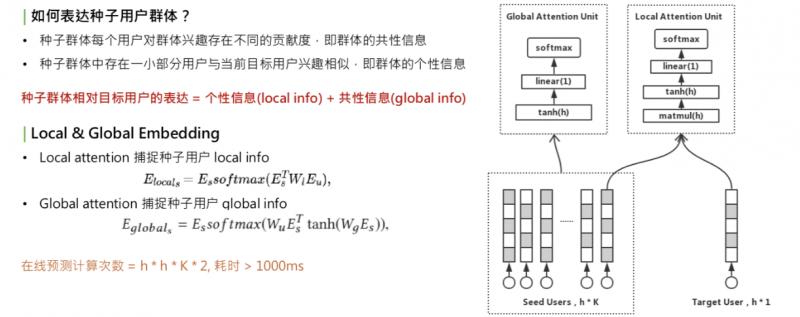
一個種子使用者應該包含什麼資訊,這裡我們做兩點假設:
每個使用者都有自己的興趣,但對整個群體的人群資訊存在不同的貢獻度,我們稱為群體的共性資訊:global info。共性資訊和目標使用者無關,只和使用者群體自身有關。
種子使用者群體的個性資訊。種子群體中一定存在一小部分使用者和 target 使用者興趣相似,這時,當 target 人群變化時,資訊會變化,稱為 local info。
種子使用者的相對錶達=個性資訊+共性資訊。怎樣學習 local info 和 global info 呢?我們想到的是用不同的 attention 機制,學習出兩個 embedding:local & global embedding,分別表示這兩種資訊。對於 local embedding,是右上角的圖,稱為 local attention unit,這個 attention,是一個乘法開始,它的公式是把種子使用者的矩陣乘以 w,再乘以 target user 的 embedding,再做一層 softmax,再乘以種子使用者自己,這是一個典型的乘法 attention。它的作用是提取種子使用者群體中和 target user 相關的部分。捕獲種子使用者的 local info。
第二部分是 global info,用 global attention,只和 user 相關,和 attention merge 的方法類似,也是一個 self-attention。作用是把種子使用者乘以矩陣轉換,再乘以種子使用者自己,所做的就是捕捉使用者群體自身內部的興趣分佈。得到的這兩種 local & global embedding 之後,進行加權和,這就是種子使用者群體的全部資訊。另一個問題來了,採用兩種 attention union 來捕獲資訊,這意味著要計算很多次矩陣乘法,對線上開銷很大。兩個 embedding 需要多少次計算?這裡有個表達公式,這個 h 是 embedding 的維度,K 是種子使用者使用者的數量,總的計算次數 = h * h * K * 2。對於線上耗時,一次預測超過 1000ms,無法接受。
優化耗時,第一個方法是減少種子使用者的數量,這樣會影響種子使用者的表達完整性;另一種是我們線上採取的方式,使用聚類。找到種子使用者內部比較相似的,把它們聚在一起。這種方法:1. 減少 key 的數量,2. 保持種子使用者的全部資訊。聚類的方式比較簡單,用的是 k-means。
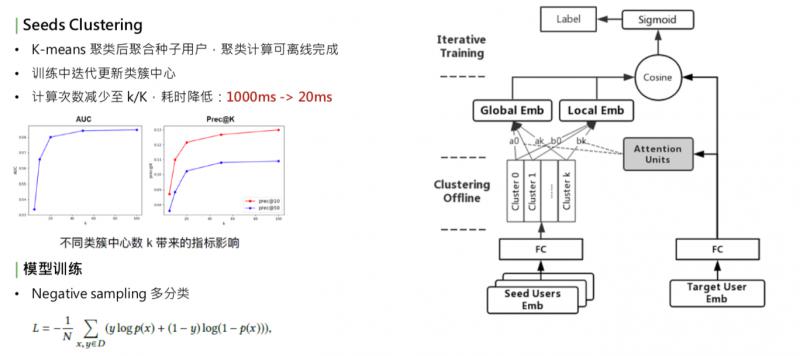
簡單看下這個模型,右側是 target user embedding,經過全連線,左邊是 series user embedding 矩陣,兩邊都經過 embedding 之後,首先對種子使用者的 embedding 做聚類,得到 k 個聚類中心,把種子使用者的向量根據 k 個聚類中心做聚和,在類似中心內部做類似於 average 的聚和,然後得到 k 個向量,在這 k 個向量之上,一邊做 global embedding,另一邊和 target user 做 local embedding。有了這兩個 embedding 之後,通過加權和的方式,做 cosine,再去擬合 user 到 item 的 label。這裡的 label 用的是點選。
細節:
聚類的過程需要迭代,比較耗時,並非每個 batch 都去更新聚類中心,而是採取迭代更新的方式,比如把1000個 batch 一輪,訓練完1000個 batch 之後,這1000個 batch 中,不更新聚類中心;到了第二輪,根據全連線引數的變化,再去更新種子使用者的聚類中心,每通過一輪更新一次聚類中心,保證和核心引數是同步的。這樣既保證了訓練的效率,也保證了訓練的準確性。聚類的優化,使線上的計算次數減小到了 k/K 中,之前 K 是萬級別的數量,現在 k 是百級別的數量,耗時也下降了很多。
根據實驗結果,確定不同聚類中心數 k 帶來的影響,選擇了合適的 k。實驗中,k=20,線上 k 是100左右。模型訓練的 label 優化方式,是一個多分類。對不同的種子使用者人群選擇最相似的使用者。多分類的優化方式和 deep model 相似,採用 negative sampling 的方式。
▌系統架構
線上需要實現實時預測,系統實際部署到線上,需要整套系統架構。簡單介紹下 RALM 的配套體系。
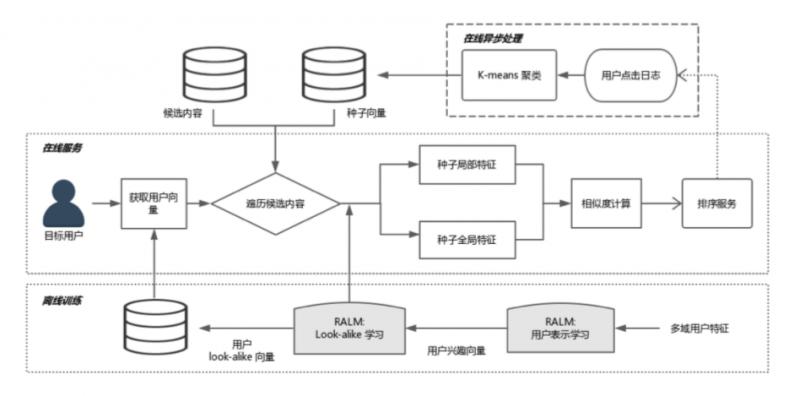
大體過程,分成三個模組,從最底下的離線訓練,到線上非同步處理,到線上服務,接下來分別講一下。
- 離線訓練
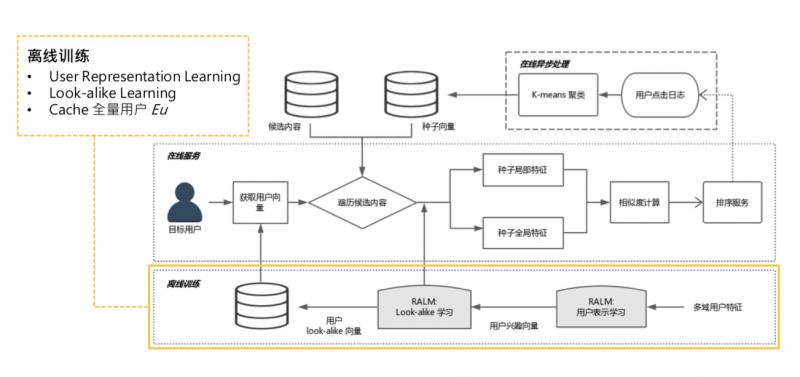
離線訓練,就是兩個階段的訓練,representation learning,look alike learning,需要一提的是,進行完 look alike learning 之後,可以把 user 經過全連線層的 user 表達快取起來。全量使用者,有10多億,可以 catch 到 KV 中。可以提供給線上服務做快取,線上不用做實時全量傳播。
2.線上非同步處理

離線訓練結束後,是線上非同步處理,主要作用是某些可以離線且和線上請求無關的計算,可以先計算完,如更新種子使用者。每個 item 候選集都會對應一個種子使用者列表,更新種子使用者列表,可以每一分鐘更新一次,這和訪問使用者無關,只和候選集的 item 有關。可以實時拉取使用者的點選日誌,更新點選某個候選集的種子列表。
① 可以把 global embedding 預計算 ( gl 只和種子使用者有關,是 self-attenion,可線上做非同步處理,如每隔一分鐘算一次 )。
② 計算 k-means 聚類中心,也是隻和種子使用者有關,可以提前計算好,如推到推薦系統記憶體中。
③ 所有的東西都是定時更新,不需要線上實時計算。
3.線上服務
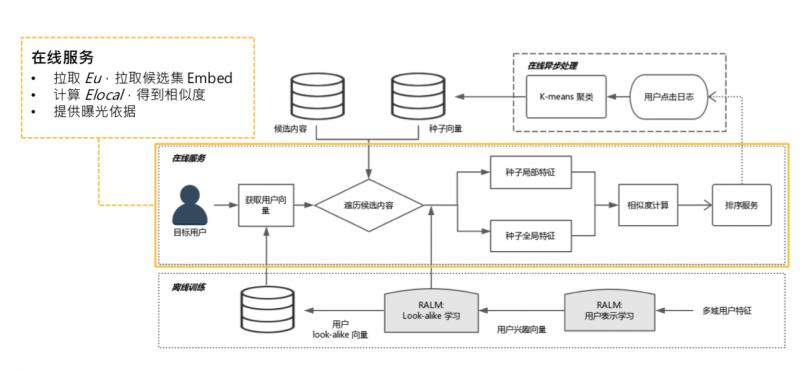
線上把聚類中心、global embedding 和所有使用者的 embedding 都已快取好,只需要拉取 user embedding,和候選集的 global embedding 和聚類中心。線上只需要計算 local embedding,是 target user 到種子使用者的 attention,這需要根據線上請求的 urn 來實時計算。再計算一次 cosine,就可以得到相似度,這個計算量很小。
▌實驗結果

算出 look alike 相似度之後,相似度的分數,可直接給到排序服務,做曝光依據。這是當時寫論文之前做的 ABtest,對比的是使用者畫像匹配推送的策略,上線之後,在擴大曝光規模的前提下,CTR 基本取向穩定,而且有微小提升,多樣性也提升了很多,這都是相對提升。
▌一些細節和思考

特徵:
為什麼要用第一階段的 user representation learning 得到使用者的高階畫像?高階畫像的作用:包含了使用者在某個領域的全部資訊,資訊量很大,結合 look alike learning 中的行為,需要去學習使用者群體的特徵。不用高階特徵,怎樣學習使用者群體?比較簡單的方法是通過統計的方式:平均年齡分佈和平均閱讀傾向。這些都是基於離散的統計,資訊損失很大。如果有了高階的特徵,高階特徵也是從低階特徵,如基礎畫像、年月分佈,這些都是可以學到高階特徵中。如果能夠直接輸出所有領域的高階特徵,之後的利用、或者作為召回、作為 CTR 特徵,都很方便。
模型調優:
① 防止模型過擬合。look alike 的結構很簡單,這樣做的原因: 直接使用使用者的高階特徵,使用了使用者特徵,如果模型不做處理,容易對高階特徵過擬合。採取了2種方式:
儘量保證 look alike learning 結構簡單;
全連線層做 dropout。
② 採用 stacking model 的形式。看一看閱讀、電商、新聞、音樂領域都做一次 user representation learning,這些特徵用 stacking 的模式都放到 look alike model 中學習,這就是不同特徵根據不同目標來訓練的,更加減少了在同一個模型中過擬合的防線。
冷啟動曝光:
Look alike model 中用了種子使用者的表達,如果線上有新的 item,怎樣做曝光?
初始投放策略。使用基於 user item 的語義特徵做線性模型的預測,當做冷啟動 item 的初始投放。這個初始投放不需要積累很多種子使用者,大概到百級別的種子使用者就可以切到 look alike 邏輯了。
Look alike 出來的相似度分數,怎麼做曝光的依據?如果直接用相似度分數,需要確定曝光閾值,如對於某個 item,高於多少分才曝光。我們使用的是線上試探曝光機制:最初給1000條流量,做曝光,這次曝光後,收集在使用者側的打分,取打分的分佈統計,根據不同業務的要求,曝光 top 5% 或者 top10%, 來砍一個閾值分數,最後取曝光閾值。
本次分享就到這裡,謝謝大家。
▌Q & A
Q:這個演算法有沒有在召回環節用,曝光該如何理解?
A:目前的策略有兩種方式:
直接採用召回的方式,定一個曝光閾值,直接確定是否曝光;
把相似分數給到下游的 CTR model 作為參考。
Q:能否將兩階段學習合併成一個端到端學習?
A:End-to-End 方式存在兩個問題:
整個模型引數量很大,結構比較複雜,採用 End-to-End 方式不一定能學習到或者學習的很充分;
剛剛講到的 stacking 方式,我們最後需要的是儘可能全的表達使用者的方式,所以右側的 user representation learning 並不是從單一業務領域得出的結果,有可能是在多個領域得到的結果,比如在看一看訓練一版 user representation learning,然後用社交或者電商上的行為,再做一版使用者的表示,最後用 stacking 的方式把它們拼接起來,作為特徵輸入,這樣達到的效果會更好。
Q:如果將第一階段使用者表徵學習換成其他通用能學習表徵使用者向量的模型,效果會有什麼影響?
A:我們單獨用 user representation learning 和其它模型做過對比,比如 CTR 中的 user embedding,是針對當前業務比較精準化的表達,所在在泛化性上沒有 user representation learning 效果好。
▌參考資料
Real-time Attention Based Look-alike Model for Recommender System
https://arxiv.org/abs/1906.05022

相關推薦
RALM: 實時 Look-alike 演算法在微信看一看中的應用
嘉賓:劉雨丹 騰訊 高階研究員 整理:Jane Zhang 來源:DataFunTalk 出品:DataFun 注:歡迎關注DataFunTalk同名公眾號,收看第一手原創技術文章。 導讀:本次分享是微信看一看團隊在 KDD2019 上發表的一篇論文。長尾問題是推薦系統中的經典問題,但現今流行的點選率預估
微信看片群
微信看片群微信看片群【加群主微信:KP8226】微信群2017,微信啪啪啪福利群,微信福利群二維碼【加群主微信:KP8226】福利、短片群、視頻群、宅男福利群、色群、黃群、交友群、我們做最開放、最真實、最有效的微信群推薦平臺!天翼高清·浙江IPTV首屆廣場舞大賽火熱報名中!微信看片群
微信掃一掃,手機就能看遠程視頻監控直播
ima 對比 遠程 log 微信 發的 center 遠程監控 htm 眼見為實,為多幼兒園、食品安全、養殖場、交通路況、景點直播等已經安裝過監控攝像頭領域提供實時視頻、微信直播。 目前市場上監控廠商提供手機遠程監控太多了,但沒有提供微信視頻監控
微博 Qzone 微信 看某明星偷稅不如看老司機談Kafka的Broker和叢集是什麼回事
一個獨立的伺服器被稱之為Broker。Broker接收來自生產者的訊息,為訊息設定偏移量,並提交訊息到磁碟儲存。Broker為消費者提供服務,對讀取分割槽的請求做出響應,返回已經提交到磁碟上的訊息。根據特點的硬體及其特性特徵,單個Broker可以輕鬆的處理數千個分割槽以及每秒
新手看完Python實現微信跳一跳自動執行,再忍不住了
我相信現在很多人都在玩微信的跳一跳小遊戲,前面幾天,很多人在朋友圈晒「跳一跳」人工智慧開掛教程:如何讓電腦自己玩微信跳一跳。 很多朋友表示不太懂這是什麼。 首先,這不是一個「破解外掛」安裝教程,而是一個「破解軟體」製作教程,要靠自己用程式碼一點點寫出來,你需要有一定的程式設計基礎,這裡用的是
微信跳一跳輔助之JAVA版(最容易理解的演算法)實現原理分析
上幾周更新微信後,進入歡迎介面就提示出讓玩一把微信小遊戲《跳一跳》。一向不愛玩遊戲的我(除了經典QQ飛車、CS外),當時抱著沒興趣的態度簡單看了下,沒有玩。與朋友玩耍時,常聽他們聊起這個小遊戲,偶爾也在網頁和微信公眾號上看見些關於這個小遊戲的一些話題,為了不落伍,我決定繼續
實時開發檢視天氣微信小程式——檢視天氣小程式(1)
第一步,針對小程式中需要實時調整其解析度所產生出的問題: rpx 全稱是什麼?(請填寫英語全稱)responsive pixel rpx(responsive pixel): 可以根據螢幕寬度進行
AI 玩微信跳一跳的正確姿勢:跳一跳 Auto-Jump 演算法詳解
作者丨安捷 & 肖泰洪學校丨北京大學碩士生研究方向丨計算機視覺本文經授權轉載自知乎專欄
一百行java程式碼實現自動玩微信跳一跳遊戲演算法詳解
前兩週用java實現了自動玩微信跳一跳遊戲,經過兩次優化,目前每次計算的準確率得到了大幅提升,跟大家分享一下實現演算法。 首先看一下自動玩微信跳一跳遊戲的實現原理: 手機開啟USB除錯
[今日幹貨]微信搜一搜的文章排名有什麽規則
文章 不能 特定 選擇 nbsp 顯示 表示 公眾號 小程序 昨天有人問到了微信搜一搜的文章排名有什麽規則啥的,今天我來給大家講一下吧~總的來說呢,高排名的文章常常是:擁有高粉絲數、高互動力、原創度高、以及擁有認證、正確關鍵詞的公眾號文章~ 鑒於微信巨大的日活及日均閱讀量
針對微信的一篇推送附有的數據鏈接進行MapReduce統計
全球 tco 大數據 cer 推送 xtend .get ati 適用於 原推送引用:https://mp.weixin.qq.com/s/3qQqN6qzQ3a8_Au2qfZnVg 版權歸原作者所有,如有侵權請及時聯系本人,見諒! 原文采用Excel進行統計數據,這
C#開發微信門戶及應用(47) - 整合Web API、微信後臺管理及前端微信小程序的應用方案
post 裏的 www. 一個數據庫 展開 動態 建立 http 文本 在微信開發中,我一直強調需要建立一個比較統一的Web API接口體系,以便實現數據的集中化,這樣我們在常規的Web業務系統,Winform業務系統、微信應用、微信小程序、APP等方面,都可以直接調用基於
Android 仿微信調用第三方應用導航(百度,高德、騰訊)
detail decorview fcm onclick api 描述 log def repr 實現目標 先來一張微信功能截圖看看要做什麽 其實就是有一個目的地,點擊目的地的時候彈出可選擇的應用進行導航。 大腦動一下,要實現這個功能應該大體分成兩步: 底部彈出可選的地
原創,微信跳一跳外掛源碼、熱門遊戲,輕松上千分
鼠標右鍵 abs control set rsh ptr img left 版本 看到別人跳一跳搞了很多分。 我也跳一下。最高分才十幾分,被別人秒殺。 於是制作這個外掛,能夠輕松上千分。 原理很簡單,計算出兩點距離,測試出按下的時間,就可以了。 現在開始嘍 當然是
python - 微信跳一跳
輸入 mage down 還需要 解壓 環境變量 bsp setup 打開 因為是基於python的腳本所以要先安裝python 這裏有教程:點擊這裏https://jingyan.baidu.com/article/a17d5285ed78e88098c8f222.ht
微信“跳一跳”輔助,小米5配置分享-實測900+
ctr pow pie 後臺 hit python wechat pre round 我的手機屏幕分辨率為1920x1080,所以修改 /config/1920x1080/config.json{ "under_game_score_y": 300
python 微信跳一跳和源碼解讀
shu lan 微信 python class 研究 pytho hub 源碼 剛好周末,想研究一下前陣子很火的微信跳一跳 網上查了一下,好像star最多的是這個項目 github:https://github.com/wangshub/wechat_jump_game
揭密微信跳一跳小遊戲那些外掛
target clear 原創 tps 小遊戲 roi 破解 工具 工作室 WeTest 導讀 張小龍:這個遊戲發布以後,其實它的效果有點超出我們的預期,我們自己開玩笑說,這個遊戲突然變成了有史以來可能用戶規模最大的一個遊戲,因為它的DAU大概到了1點幾億,但同時出現了
用python玩微信跳一跳(win10+安卓)
pos 地址 前言 class 包安裝 align fig 嘗試 usb 一、前言 一場跨年的寒風席卷了整個北方,把我們帶到了雪花爛漫的季節;一場“跳一跳”的風波也席卷了我們年輕人,好友們從此展開了如火如荼的較量。由此我們如何才能輕松戰勝好友呢?這背後少不了我
Python 幫你玩微信跳一跳 GitHub Python腳本
問題 開發者選項 sdk github div 行程 如何 orm bubuko 前言想自己搞遊戲小程序的 本來想自己搞個簡單的八數碼遊戲的,順帶研究下 A*算法的,結果 這個微信 個人號不讓我發布,就很氣,然後再研究了 AutoJS和adb之後,決定懟一波微信很火的小程序