
高德APP全鏈路原始碼依賴分析工程
一、背景
高德 App 經過多年的發展,其程式碼量已達到數百萬行級別,支撐了高德地圖複雜的業務功能。但與此同時,隨著團隊的擴張和業務的複雜化,越來越碎片化的程式碼以及程式碼之間複雜的依賴關係帶來諸多維護性問題,較為突出的問題包括:
不敢輕易修改或下線對外暴露的介面或元件,因為不知道有什麼地方對自己有依賴、會受到影響,於是程式碼變得臃腫,包大小也變得越來越大;
模組在沒有變動的情況下,釋出到新版本的客戶端時,需要全量回歸測試整個功能,因為不知道所依賴的模組是否有變動;
難以判斷 Native 從業務實現轉變為底層支撐的趨勢是否合理,治理是否有效;
這些問題已經達到了我們必須開始治理的程度了,而解決此類問題的關鍵在於需要了解程式碼間的依賴關係。
二、高德 APP 平臺架構
為了消除一些疑惑,在討論依賴分析的實現前,先簡單說明一下高德 APP 的平臺架構,以便對一些名詞和場景有一些背景瞭解。
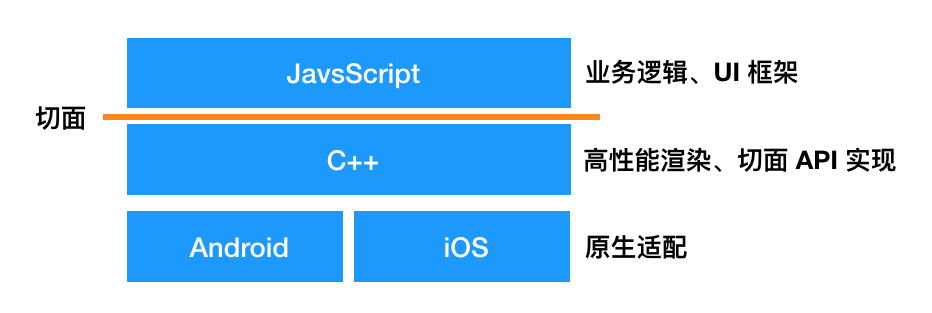
高德 APP 從語言平臺上可以分為 4 個部分,JS 層主要負責業務邏輯和 UI 框架;中間有 C++層做高效能渲染(主要是地圖渲染),同時實現了一些切面 API,這樣可以在雙端只維護一套邏輯了;Android 和 iOS 層主要作為適配層,做一些作業系統介面的對接和雙端差異化的(儘可能)抹平。
這裡的切面是指 JS 層與 Native/C++ 層的分界線,這裡會實現一些切面 API,也就是 JS 層與 Native/C++ 層互動的一系列介面,如藍芽介面、系統資訊介面等,由 Native/C++ 層來實現介面,然後往 JS 層暴露,由 JS 層呼叫。
三、基礎實現原理
整個專案最基本也是最重要的資料就是依賴關係。所謂依賴關係,最簡單的例子就是檔案 A 依賴檔案 B 的某個方法。
要將這個關係查出來,一般來說需要經過兩個步驟。
第一步:編譯原始碼,獲得 AST
遍歷所有原始碼,通過語法分析,生成抽象語法樹(Abstract Syntax Tree, AST)。以 JS 掃描器為例,我採用了 typeScript 模組作為編譯器,它同時支援 JS(X)、TS(X),通過 ts.createSourceFile 來生成 AST。除 JS 外,iOS 採用的是 CLang,Android 採用的是位元組碼分析,C++ 採用的是符號表分析。
第二步:路徑提取,依賴尋路
從 AST 上我們可以找到所有的引用和暴露表示式,以 JS 為例就是 import/ require 和 export/ module.exports。尋找表示式的方法就是遞迴地遍歷所有語法節點,在 JS 中我採用了 TypeScript 編譯器提供的 ts.forEachChild 來進行遍歷,通過 ts.SyntaxKind 進行語法節點型別的識別。
找到表示式後,通過依賴路徑找到具體的依賴檔案。以 JS 為例,我們可以通過 const { identifierName } = require('@bundleName/fileName') 的方式引用其它模組(bundleName)的某個檔案(fileName)的某些識別符號(identifierName),我們就需要根據這表示式來定位到具體的識別符號。
跨切面的依賴會需要多做一步,需要將切面 API 分為呼叫側和宣告側,在 JS 層通過 AST 分析出呼叫側資料,在 Native/C++ 層分析出宣告側資料(對應到具體實現切面 API 的識別符號),將呼叫側和宣告側資料通過版本號關聯到一起,即可實現全依賴鏈路貫通。
我們把這個關係以及一些元資料儲存下來,就可以作為源資料來作資料分析了。
四、專案架構
整體專案架構如下:
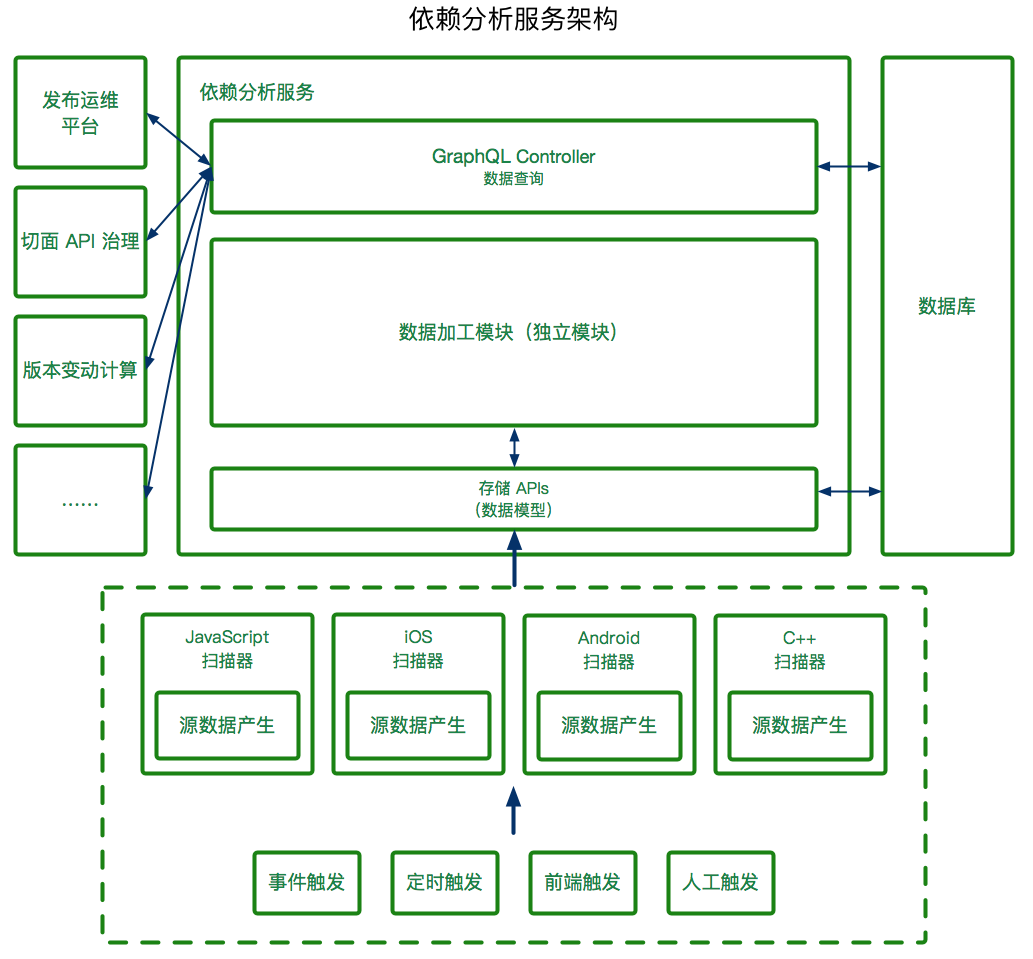
我們使用 Node.js 和集團的 egg.js 框架搭建了本依賴分析工程服務,並且考慮到資料使用場景的多變性和多樣性,我選用了 GraphQL 作為查詢介面,輸出我們定義的資料型別,由上層應用自行封裝,如果出現多個上層應用同時需要類似的資料,我們也會進行整合複用。
其中資料加工模組是獨立模組,由 Node.js 編寫,支援其它專案複用,未來會計劃在 IDE 等專案複用。
左側是我們的資料消費方,這裡只列舉了幾個;右側是我們的資料庫,用於儲存分析結果;下側是四端掃描器和觸發器,四端分別對自己平臺的原始碼進行源資料生產,觸發器支援釋出流程觸發事件觸發、定時觸發、前端觸發(應用側前端,不是 Web 前端)和人工觸發等。
五、應用場景及實現原理
全鏈路依賴關係的使用場景有無窮的想象力,這裡挑幾個來舉例。
影響範圍判斷(逆向依賴分析)
第一個我們能想到的應用場景就是影響範圍判斷,這也是我們這個專案的第一個抓手。大家都能想到,如果維護一個介面(或元件),我們會發現當越來越多地方用的時候,迭代它的風險會隨之而越來越高,我們需要明確地知道到底有哪些地方呼叫了這個介面,以確定到底要回歸測試多少功能、要怎麼做釋出、怎麼做相容等。而這就需要進行逆向依賴分析了。
逆向依賴是相對掃描器中分析出來的依賴關係的,掃描器分析出來的我們稱之為正向依賴,它主要表示「此模組依賴了哪些別的模組」;而逆向依賴則指的是「此模組被哪些模組依賴了」。所以很自然地,我們的逆向依賴就是基於正向依賴關係做的資料加工。
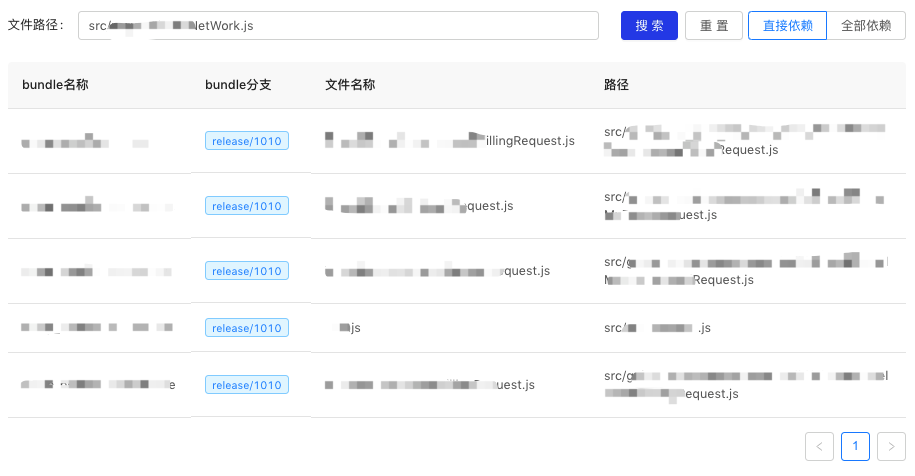
(逆向依賴查詢頁面)
基於逆向依賴資料,結合多個版本的資料,我們還能算出「連續未被引用的版本數」,以衡量下線介面的安全性。

(一些切面 API 的連續未被使用的版本數)
元件庫、框架和切面 API 的維護者是這個能力的重度使用者,這個能力為他們帶來了資料支撐,明確了自己的修改將會影響多少的其它模組,從而進行變更、釋出決策和迴歸測試。
版本間變動分析
版本提測時,我們可以對兩個版本進行依賴鏈比對,分析出檔案的變動及其整個影響鏈路,為 QA 提供一些資料支援,能更精確地知道有哪些功能要進行迴歸測試,有哪些不需要。
版本間變動分析有很多場景,除了正常的版本迭代的場景之外,還有一個常見的場景:模組在未變動的情況下被整合到新版本的高德 APP 中,那就會出現「釋出程式碼不變,而所依賴的其它模組有變動」的情況,尤其有是 Native/C++ 和公用模組。測試環境需要知道的是,當前模組所依賴的其它模組到底有哪些變動、這些變動對此模組的影響是什麼、需要回歸測試哪些功能點等。
這個資料的主要消費方是 QA 同學,他們利用這個資料可以提高測試效率,也能發現漏考慮的迴歸點。
趨勢變化判斷
前面也提到過,由於高德 APP 時間跨度很大,以及之前未進行限制,所以我們有部分業務邏輯程式碼仍然是通過 Native 來實現的,我們希望逐漸遷移到 JS 或 C++ 層實現,Native 僅作適配。
而要判斷這個治理的進度和效果,需要從兩個方面的資料來支撐,一是各平臺程式碼行數,這個我們另有專門的服務做,暫且不提;二是介面趨勢。介面趨勢也分為呼叫側和宣告側兩種,按照我們治理的方向,我們期望的效果應該是:一條 Native 業務切面 API 的呼叫量按版本/時間不斷減少的曲線,當一些 API 的呼叫量為 0 後就可以把 API 下線掉,這樣就會隨之出現另一條曲線——Native 業務切面 API 的宣告量也不斷減少。
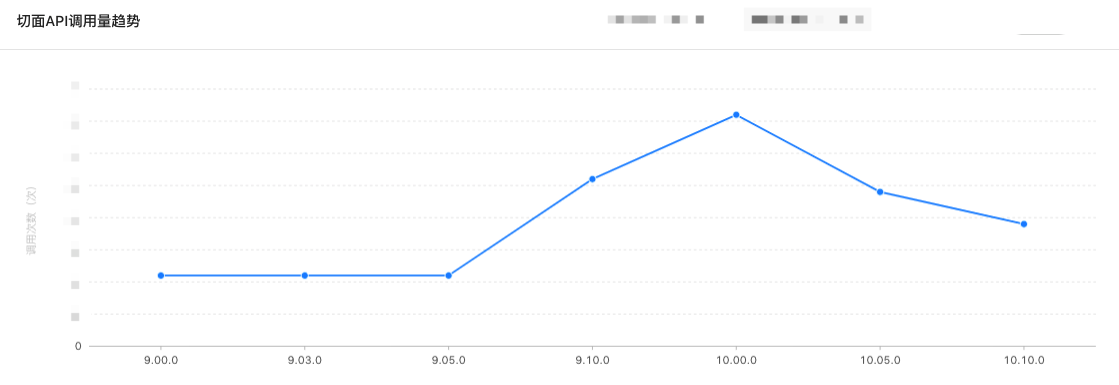
(從某版本開始就不斷減少呼叫的切面 API)
(某版本未被使用的切面 API)
進行架構治理、切面 API 治理的同學是這些資料的主要消費方,有了這些資料他們就能確定架構治理的趨勢是否合理、是否能下線某切面 API 等。
包大小優化——無用、重複檔案查詢
我們也為包大小優化作了貢獻。根據依賴關係資料,我們可以找出一些沒有被引用或者內容完全一樣(md5 值相同)的檔案,這些檔案也佔用了不少體積。
我們利用依賴分析工程找出了上千張這樣的圖片,@1x @2x @3x 檔案是重災區,有很多假裝自己是另一個清晰度的圖片被我們揪出來了(我們甚至因此推動了設計師出圖標準化和增加了檢驗工具)。
六、寫在最後
以上便是高德全鏈路依賴分析工程的基本概述,在具體的實現當中,會有無數的細節需要處理,如各種歷史遺留問題、多級版本處理產生指數級的程式碼快照、變動分析產生指數級的分析結果等,其中也涉及到不少編譯原理、資料結構與演算法(尤其是圖結構)等知識,非常考驗程式設計能力和權衡能力,以及最重要的——韌性。歡迎大家一起討論,一起迸發新的想法、新的場景!

相關推薦
高德APP全鏈路原始碼依賴分析工程
一、背景 高德 App 經過多年的發展,其程式碼量已達到數百萬行級別,支撐了高德地圖複雜的業務功能。但與此同時,隨著團隊的擴張和業務的複雜化,越來越碎片化的程式碼以及程式碼之間複雜的依賴關係帶來諸多維護性問題,較為突出的問題包括: 不敢輕易修改或下線對外暴露的介面或元件,因為不知道有什麼地方對自己有依賴、會受
高德全鏈路壓測平臺TestPG的架構與實踐
導讀 2018年十一當天,高德DAU突破一個億,不斷增長的日活帶來喜悅的同時,也給支撐高德業務的技術人帶來了挑戰。如何保障系統的穩定性,如何保證系統能持續的為使用者提供可靠的服務?是所有高德技術人面臨的問題,也是需要大家一起解決的問題。 高德業務規模 支撐一億DAU的高德服務是什麼體量?可能每個人的答案都不相
高德全鏈路壓測——精準控壓的建設實踐
導讀 作為國民級出行生活服務平臺,高德服務的穩定性不論是平時還是節假日都是至關重要的,服務穩定性一旦出問題,可能影響千萬級甚至上億使用者。春節、十一等節假日激增的使用者使用量,給高德整體服務的穩定性帶來了不小的挑戰。每年在大型節假日前我們都會做整體服務的全鏈路壓測。通過常態化全鏈路壓測專案的推進,已具備了月
短視訊開發:短視訊原始碼可結合全鏈路的視訊雲服務一站式解決
實際上,網際網路的內容行業正在進階,從文字、圖片到視訊、直播,再到能填補使用者碎片時間的短視訊開發,這是一個趨於互動性、實時性的迭代。從4G普及、資費下調、編解碼技術進步和移動硬體的品質提升,也為短視訊的發展提供了良好客觀因素。從產品形態層面看,短視訊本身也擁有創作門檻低、內容精煉、易於發酵等屬性,更易於傳播
億級流量系統架構之如何設計全鏈路99.99%高可用架構【石杉的架構筆記】
歡迎關注個人公眾號:石杉的架構筆記(ID:shishan100) 週一至週五早8點半!精品技術文章準時送上! 一、前情回顧 上篇文章(《億級流量系統架構之如何設計每秒十萬查詢的高併發架構》),聊了一下系統架構中的查詢平臺。 我們採用冷熱資料分離: 冷資料基於HBase+Elasticsearch+純記
【Servicemesh系列】【Envoy原始碼解析(二)】一個Http請求到響應的全鏈路(一)
目錄 1. http連線建立 當有新連線過來的時候,會呼叫上一章節所提及的被註冊到libevent裡面的回撥函式。我們回顧一下,上一章節提及了,會有多個worker註冊所有的listener,當有一個連線過來的時候,系統核心會排程一個執行緒出來交付
北京高電機房|北京高防機房|全球鏈路|動態BGP
北京高電機房 北京高防機房 全球鏈路 動態bgp 網極雲棲致力於打造高數據中心業務服務平臺,不斷整合優化行業資源,力求為企業用戶提供最滿意的互聯網資源,助力企業發展。現有核心運營數據中心5個,分布於北京區各個主要互聯網用戶區域,可根據用戶的多樣化需求,提供快速、高效的應用部署。以北京為核心,輻
技術文章 | 系統穩定性保障核武器——全鏈路壓測
tps alt 系統 f11 技術文章 無限 通過 技術分享 center 為什麽要做全鏈路壓測? 對阿裏巴巴而言,每年最重要的一天莫過於雙11。這是因為在雙11的零點,系統會遭遇史無前例的巨大洪峰流量沖擊,保證雙11當天系統的穩定性對高可用團隊來說是巨大的挑戰。在這個
全鏈路spring cloud sleuth+zipkin
arc owa version public kafka 分享 cli self 兩個 http://blog.csdn.net/qq_15138455/article/details/72956232 版權聲明:@入江之鯨 一、About ZipKi
全鏈路設計與實踐
背景 text 軌跡 nag zipkin www 問題 頁面加載 elastics 背景 隨著公司業務的高速發展,公司服務之間的調用關系愈加復雜,如何理清並跟蹤它們之間的調用關系就顯的比較關鍵。線上每一個請求會經過多個業務系統,並產生對各種緩存或者 DB 的訪問,但是這
餓了麽全鏈路壓測平臺的實現與原理
test www. 試用 推送 定位 用戶操作 吞吐量 查詢 定期清理 背景 在上篇文章中,我們曾介紹過餓了麽的全鏈路壓測的探索與實踐,重點是業務模型的梳理與數據模型的構建,在形成腳本之後需要人工觸發執行並分析數據和排查問題,整個過程實踐下來主要還存在以下問題: 測試成本
如何開展全鏈路壓測&全鏈路壓測核心要素
腳本 數據清洗 現在 之前 log 梳理 訪問 如何 基礎 之前對全鏈路壓測概念比較懵,現在簡單梳理下,後續有學習到的幹貨再持續補充:可參考:阿裏全鏈路壓測京東全鏈路壓測 1.什麽是全鏈路壓測 基於實際的生產業務場景、系統環境,模擬海量的用戶請求和數據對整個業務鏈進行壓力測
鷹眼系統;全鏈路監控系統;分布式監控系統
tor detail dapper git ans class log bsp http 有一些大公司的開源方案: https://www.jianshu.com/p/a125bea43abe 阿裏的鷹眼系統: https://cn.aliyun.com/aliware/n
短視頻開發:短視頻源碼可結合全鏈路的視頻雲服務一站式解決
視頻源碼 擁有 鏈路 行業 上傳 用戶 自帶 shadow mar 實際上,互聯網的內容行業正在進階,從文字、圖片到視頻、直播,再到能填補用戶碎片時間的短視頻開發,這是一個趨於互動性、實時性的叠代。從4G普及、資費下調、編解碼技術進步和移動硬件的品質提升,也為短視頻的發展提
全鏈路追蹤spring-cloud-sleuth-zipkin
authorize 采樣 quest child 手機號 main rgs lin oot 微服務架構下 多個服務之間相互調用,在解決問題的時候,請求鏈路的追蹤是十分有必要的,鑒於項目中采用的spring cloud架構,所以為了方便使用,便於接入等 項目中采用了sprin
雲上資料庫“全鏈路安全”實踐:保護企業核心資產
資料庫所儲存的是企業最為核心的資產,所以對於企業而言,必須要將資料庫的安全做到位。那麼,如何保證雲上資料庫的安全呢?在本文中,阿里雲資料庫高階產品專家崔京(花名:乙休)就為大家帶來了雲資料庫的“全鏈路安全”。 在大家心中,資料庫安全到底指什麼呢?其實資料庫安全可以分為幾個方面理解,首先是資料連續可用,
消滅毛刺!HBase2.0全鏈路offheap效果拔群
阿里雲HBase2.0版本正式上線 阿里雲HBase2.0版本是基於社群2018年釋出的HBase2.0.0版本開發的全新版本。在社群HBase2.0.0版本基礎上,做了大量的改進和優化,吸收了眾多阿里內部成功經驗,比社群HBase版本具有更好的穩定性和效能,同時具備了HBase2.0提供的全新能力。HBa
全鏈路實施方案參考部落格
最近在做系統全鏈路實施專案,看了些還不錯的部落格,收藏一下。 全鏈路壓測相關文章: 阿里全鏈路壓測 http://www.sohu.com/a/163812216_612370 滴滴全鏈路壓測 https://blog.csdn.net/g6u8w7p06dco99fq3/article/det
每天學點SpringCloud(十二):Zipkin全鏈路監控
Zipkin是SpringCloud官方推薦的一款分散式鏈路監控的元件,使用它我們可以得知每一個請求所經過的節點以及耗時等資訊,並且它對程式碼無任何侵入,我們先來看一下Zipkin給我們提供的UI介面都是提供了哪些資訊。 zipkin首頁為我們提供了對於呼叫鏈路的搜尋查詢
全鏈路壓測平臺(Quake)在美團中的實踐
背景 在美團的價值觀中,以“客戶為中心”被放在一個非常重要的位置,所以我們對服務出現故障越來越不能容忍。特別是目前公司業務正在高速增長階段,每一次故障對公司來說都是一筆非常不小的損失。而整個IT基礎設施非常複雜,包括網路、伺服器、作業系統以及應用層面都可能出現問題。在這種背景下,我們必須對服務進行一次全方位的