
5 分鐘快速學習,快取一致性優化方案!
快取操作
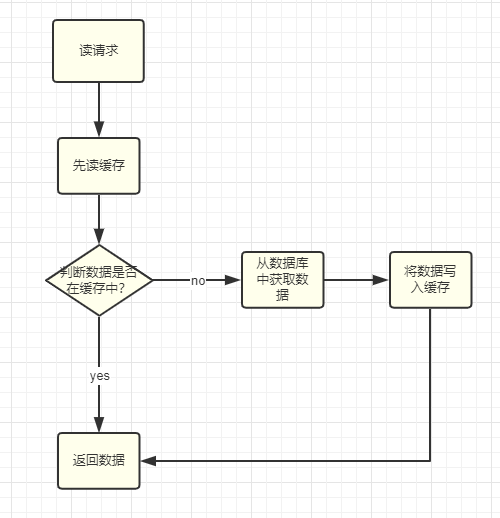
讀快取
讀快取可以分為兩種情況命中(cache hit)和未命中(cache miss):
快取命中
- 首先從快取中獲取資料
- 將快取中的資料返回
快取未命中
- 首先從快取中獲取資料
- 此時快取未命中,從資料庫獲取資料
- 將資料寫入快取
- 返回資料
讀快取的的處理由快取中有沒有資料? 決定,如果快取中有資料那就是快取命中,如果沒有那就是快取未命中:
寫快取
寫快取可以分為更新快取和刪除快取。
更新快取
更新快取時需要分兩種情況:
- 更新簡單資料型別(如string)
- 更新複雜資料型別 (如hash)
對於簡單資料型別可以直接更新快取,如果是複雜資料型別會增加額外的更新開銷:
- 從快取中獲取資料
- 將資料序反列化成物件
- 更新物件資料
- 將更新後的資料序列化存入快取
對複雜資料快取的更新最少需要4步,而且每次寫資料時都需要更新快取,這樣對讀快取較少的場景,可能更新資料7-8次讀快取才發生一次想想就划不來,另外每次更新快取時都要對快取資料進行計算,很明顯寫資料時計算快取資料然後再更新快取是沒必要的,可以將快取的更新,推遲到讀快取(快取未命中)時。
刪除快取
刪除快取也稱為淘汰快取,刪除快取的操作非常簡單的,直接將快取從快取庫中的刪除就可以了。
快取操作順序
快取一般都是配合資料庫一起使用,從資料庫中獲取資料然後再更新快取。為什麼要討論快取操作的順序呢?因為在有些情況下不同的操作順序會產生不一樣的結果,常見的操作順序可以分為:
- 先資料庫,再快取
- 先快取,再資料庫
不管是哪種順序都要經過資料庫、快取兩步操作,這兩操作不是一個原子性的操作在一些情況會出現資料不一致問題。下面來分別說明不同的順序所帶的資料不一致、併發等問題。
先資料庫後快取

如上圖先將資料寫入資料庫,然後再去更新或刪除快取。兩個步驟1、2都可能失敗,如果是第一步失敗可以通過丟擲業務異常,業務呼叫方捕獲異常資訊進行處理,因為這個時候並沒有操作快取可以理解為寫資料庫失敗了。
如果是第一步成功(寫資料庫成功),然後再操作快取的時候失敗,這裡有兩種情況:
- 資料庫回滾:如果是業務需要保證快取與資料庫強一致性時,可以丟擲業務異常給呼叫方。
- 不作處理:與
資料庫回滾相反,業務可以接受在快取過期時間達到之前,快取與資料庫允許資料不一致。
舉個例子,假設有一個字串資料型別的快取資料,它的key為name並且現在資料庫和快取中的值都是arch-digest。
String name = "arch-digest";現在要將name的值更新成juejin,按照先資料庫後快取的順序:
//將name的值更新為juejin
public void update(String name){
db.insert(...); //更新資料庫
cache.delete(name); //更新快取
}正常情況下db.insert(...)和cache.delete(name)都執行成功沒有異議。如果是一些其他原因cache.delete(name)執行失敗,那資料庫中的值是更新後的值juejin,而快取中的資料還是arch-digest這樣在下次讀取快取的時候拿到的值就是arch-digest。
public String getNameFromCache(String name){
String value = cache.get(name); //從快取中獲取資料
...
return value;
}讀取快取的時候在getNameFromCache方法中,如果name快取沒有過期那會一直拿到arch-digest,這樣情況就會導致使用者看到的資料不一致。
先快取後資料庫
先快取後資料庫和之前說到的先資料庫後快取差不多除了會可能導致資料不一致外,還會有併發問題。
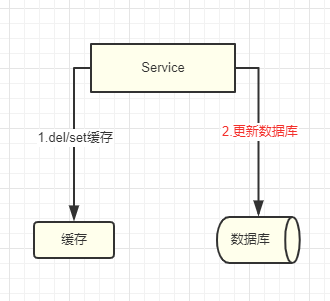
如上面現在是更新資料,如果是在更新資料庫的時候失敗會發生什麼呢?這裡要根據快取的操作分兩種情況:
- 更新快取:更新快取資料,快取中為最新資料,資料庫中是老資料,下次讀取時會拿到快取中的新資料(資料不一致)。
- 刪除快取:刪除快取中的資料,下次讀取時從資料庫中獲取(資料一致)。
更新快取和刪除快取操作上面已經介紹過了,不多做解釋了。很明顯關於更新快取和刪除快取在這種情況先刪除快取更合適,沒有資料不一致的問題,但是在使用刪除快取時也要注意會引發併發問題:
- 執行緒A刪除快取成功
- 執行緒B讀取快取未命中
- 執行緒B從資料庫中獲取資料
- 執行緒B將資料庫中的資料寫入快取
- 執行緒A寫入資料庫成功
在高併發場景下,快取和資料庫資料不一致的情況還是會出現。那要解決資料庫和快取的資料一致性有哪些解決方案呢?
資料一致性優化方案
這裡說的是優化方案不是解決方案哦,因為在分散式環境下事務是個難題,現在也沒有好的解決方案。只能找到最適合業務的優化方案,使資料不一致的可能性或延遲降到一個業務可接受的範圍內。
常見的幾種優化方案可以包括:
- 不處理
- 延時雙刪
- 訂閱Binglog
3 種方案從簡單到複雜,可以根據業務需要選擇最合適的優化方案。
不處理
不處理是最簡單的方式了,即資料庫與快取中的資料不一致時在業務允許的情況下不做處理。雖然有點不合適,但是很香!
延時雙刪
延時雙刪可以用來優化在先快取後資料庫中的併發問題:
- 執行緒A刪除快取成功
- 執行緒B讀取快取未命中
- 執行緒B從資料庫中獲取資料
- 執行緒B將資料庫中的資料寫入快取
- 執行緒A寫入資料庫成功
- 執行緒A休眠1秒然後刪除快取
這種方案增加第6步,寫入資料庫完成後使寫入執行緒休眠1秒,然後再將快取資料刪除掉,使其他執行緒再次讀取資料時導致快取未命中從資料庫獲取資料並更新快取。
這個1秒怎麼確定的,具體該休眠多久呢?
針對上面的情形,應該自行評估自己的專案的讀資料業務邏輯的耗時。然後寫資料的休眠時間則在讀資料業務邏輯的耗時基礎上,加幾百ms即可。這麼做的目的,就是確保讀請求結束,寫請求可以刪除讀請求造成的快取髒資料。
採用這種同步淘汰策略,吞吐量降低怎麼辦?
第二次刪除作為非同步的。自己起一個執行緒,非同步刪除。這樣,寫的請求就不用沉睡一段時間後了,再返回。這麼做,加大吞吐量。
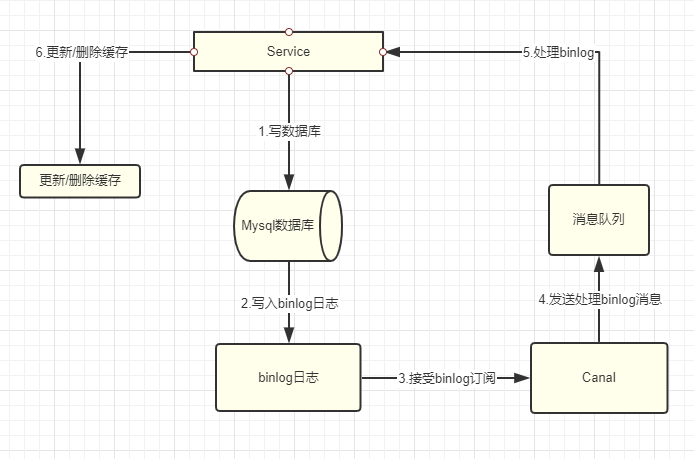
binlog訂閱
使用binlog訂閱,這樣一旦MySQL中產生了新的寫入、更新、刪除等操作,就可以把binlog相關的訊息推送至Redis,Redis再根據binlog中的記錄,對Redis進行更新。
其實這種機制,很類似MySQL的主從備份機制,因為MySQL的主備也是通過binlog來實現的資料一致性。
這裡可以結合使用canal(阿里的一款開源框架),通過該框架可以對MySQL的binlog進行訂閱,而canal正是模仿了mysql的slave資料庫的備份請求,使得Redis的資料更新達到了相同的效果。
當然,這裡的訊息推送工具你也可以採用別的第三方:kafka、rabbitMQ等來實現推送更新快取。
每天一篇架構領域重磅好文,涉及一線網際網路公司應用架構(高可用、高效能、高穩定)、大資料、機器學習、Java架構等各個熱門領域。
