
靈魂拷問:Java 的 substring() 是如何工作的?
在逛 programcreek 的時候,我發現了一些小而精悍的主題。比如說:Java 的 substring() 方法是如何工作的?像這類靈魂拷問的主題,非常值得深入地研究一下。
另外,我想要告訴大家的是,研究的過程非常的有趣,就好像在迷宮裡探寶一樣,起初有些不知所措,但經過一番用心的摸索後,不但會找到寶藏,還會有一種茅塞頓開的感覺,非常棒。
對於絕大多數的初級程式設計師或者說不重視“內功”的老鳥來說,往往停留在“知其然不知其所以然”的層面上——會用,但要說底層的原理,可就只能撓撓頭雙手一攤一張問號臉了。
很長一段時間內,我也一直處於這種層面上。但我決定改變了,因為“內功”就好像是在打地基,只有把地基打好了,才能蓋起經得住考驗的高樓大廈。藉此機會,我就和大家一起,對“Java 的 substring() 是如何工作的”進行一次深入地研究。注意了,準備打怪升級了!
01、substring() 是幹嘛的
sub 是 subtract 的縮寫,因此 substring 的字面意思就是“把字串做個減法”。這樣一分析,是不是感覺方法的命名還是蠻有講究的?
substring() 的完整寫法是 substring(int beginIndex, int endIndex)。該方法返回一個新的字串,介於原有字串的起始下標 beginIndex 和結尾下標 endIndex-1 之間。
String cmower = "沉默王二,一枚有趣的程式設計師";
cmower = cmower.substring(0, 4);
System.out.println(cmower);
程式輸出的結果為:
沉默王二
為什麼呢?我來簡單解釋一下。
Java 的下標都是從 0 開始編號的(我不確定有沒有從 1 開始的程式語言),這和我們平常生活中從 1 開始編號的習慣不同。Java 這樣做的原因如下:
Java 是基於 C 語言實現的,而 C 語言的下標是從 0 開始的——這聽起來好像是一句廢話。真正的原因是下標並不是下標,在指標(C)語言中,它實際上是一個偏移量,距離開始位置的一個偏移量。第一個元素在開頭,因此它的偏移量就為 0。
此外,還有另外一種說法。早期的計算機資源比較匱乏,0 作為起始下標相比較於 1 作為起始下標,編譯的效率更高。
知道了這層原因後,再來看上面這段程式碼,就會豁然開朗。對於“沉默王二,一枚有趣的程式設計師”這串字元來說,“沉”的下標為 0,“默”的下標為 1,“王”的下標為 2,“二”的下標為 3,所以 cmower.substring(0, 4)
02、substring() 在被呼叫的時候究竟發生了什麼?
在此之前,我們已經瞭解到:[字串是不可變的](),因此當呼叫 substring() 方法的時候,返回的其實是一個新的字串。那麼變數 cmower 的地址引用就會發生如下圖所示的變化。
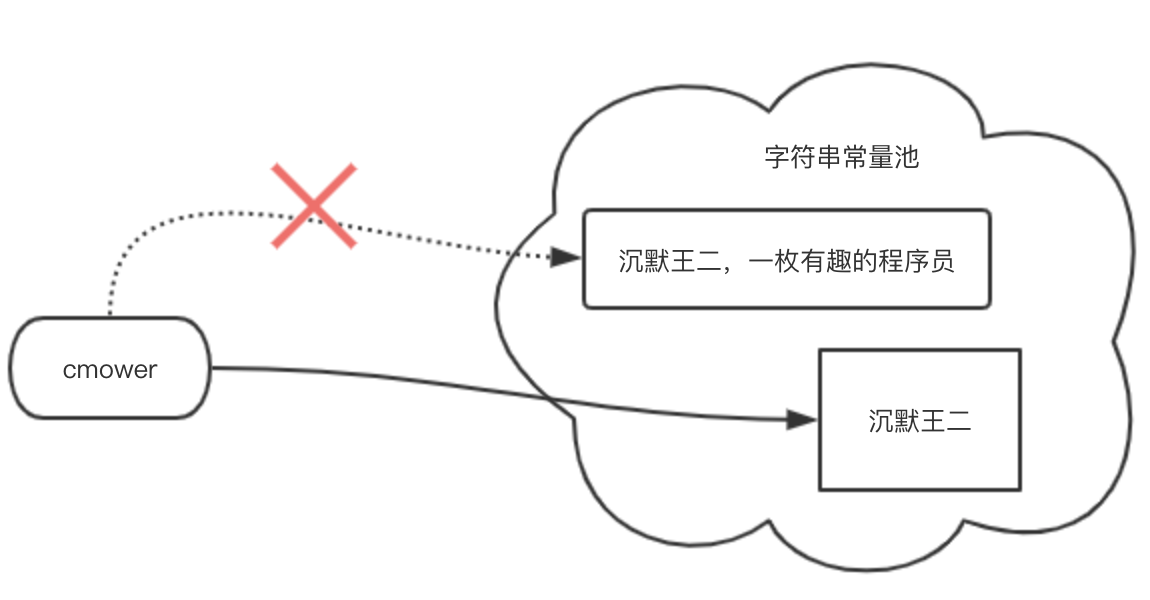
為了證明上圖是完全正確的,我們來看一下 JDK 7 中 substring() 的原始碼。
public String(char value[], int offset, int count) {
//check boundary
this.value = Arrays.copyOfRange(value, offset, offset + count);
}
public String substring(int beginIndex, int endIndex) {
//check boundary
int subLen = endIndex - beginIndex;
return new String(value, beginIndex, subLen);
}
可以看得出,substring() 通過 new String() 返回了一個新的字串物件,在建立新的物件時通過 Arrays.copyOfRange() 複製了一個新的字元陣列。
但 JDK 6 就有所不同。說到 JDK 6,可能有些讀者表示不服,JDK 6?什麼年代了,JDK 13 都出來了好不好?但我想告訴大家的是,對比著剖析 JDK 的原始碼,對學習大有裨益。
不是有那麼一句話嘛,要想了解一個成功人士,不能只關注他發跡以後的事,更要關注他之前做了什麼。
就請隨我來,看看 JDK 6 中的 substring() 的原始碼吧。
//JDK 6
String(int offset, int count, char value[]) {
this.value = value;
this.offset = offset;
this.count = count;
}
public String substring(int beginIndex, int endIndex) {
//check boundary
return new String(offset + beginIndex, endIndex - beginIndex, value);
}
substring() 方法本身和 JDK 7 並沒有很大的差別,都通過 new String() 返回了一個新的字串物件。但是 String() 這個建構函式有很大的差別,JDK 6 只是簡單地更改了一下兩個屬性(offset 和 count)的值,value 並沒有變。
PS:value 是真正儲存字元的陣列,offset 是陣列中第一個元素的下標,count 是陣列中字元的個數。
這意味著什麼呢?
呼叫 substring() 的時候雖然建立了新的字串,但字串的值仍然指向的是記憶體中的同一個陣列,如下圖所示。
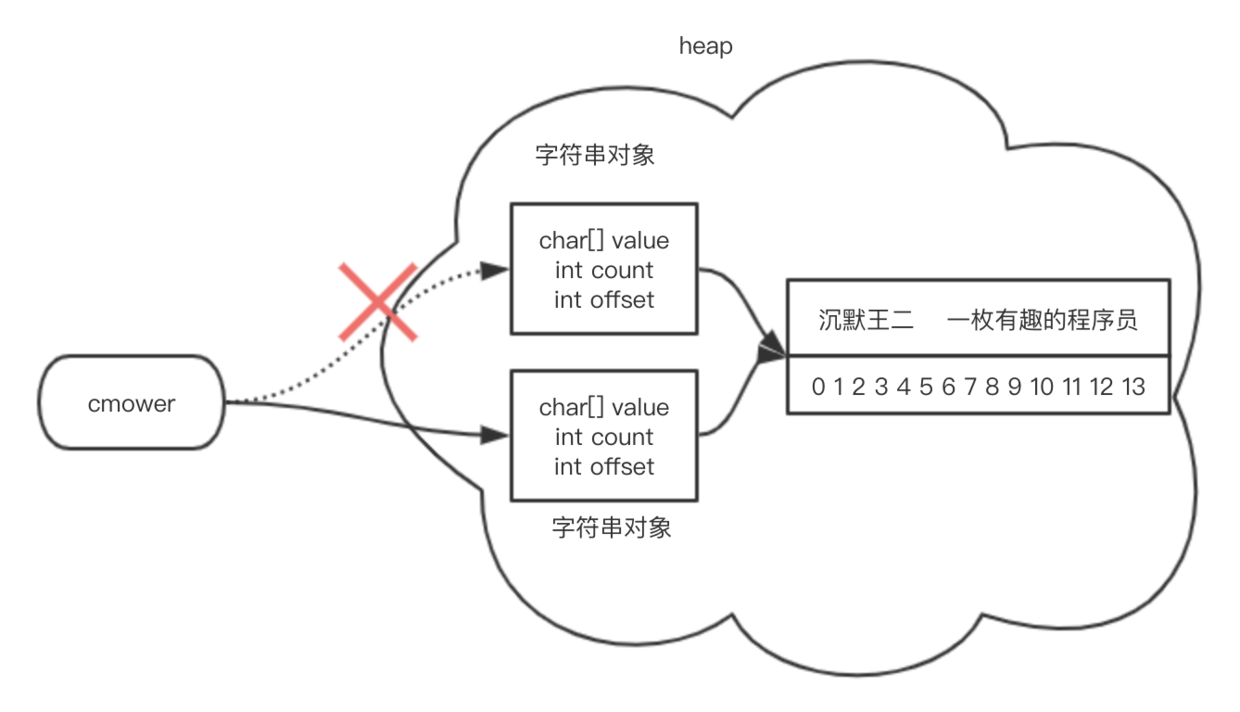
03、為什麼 JDK 7 的建構函式發生了變化
看了 JDK 6 和 JDK 7 原始碼之後,大家可能產生這樣一個疑惑:為什麼 JDK 7 要做出改變呢?大家共用同一個字串陣列不是挺好的嘛,省得佔用新的記憶體空間。事實上呢?
如果有一個很長很長的字串,可以繞地球一週,當我們需要呼叫 substring() 擷取其中很小一段字串時,就有可能導致效能問題。由於這一小段字串引用了整個很長很長的字元陣列,就導致很長很長的這個字元陣列無法被回收,記憶體一直被佔用著,就有可能引發記憶體洩露。
PS:記憶體洩露是指由於疏忽或錯誤造成程式未能釋放已經不再使用的記憶體。
那 JDK 7 出現之前,這個隱患怎麼應對呢?答案如下。
cmower = cmower.substring(0, 4) + "";
為什麼,為什麼,為什麼,多一個 “+ ""” 就能解決記憶體洩漏的問題?有些讀者可能不太相信,我來帶大家分析一下。
首先呢,我們通過 JAD 對位元組碼反編譯一下,上面這行程式碼就變成了如下內容。
cmower = (new StringBuilder(String.valueOf(cmower.substring(0, 4)))).toString();
“+”號操作符就相當於一個語法糖,加上空的字串後,會被 JDK 轉化為 StringBuilder 物件,該物件在處理字串的時候會生成新的字元陣列,所以 cmower = cmower.substring(0, 4) + ""; 這行程式碼執行後,cmower 就指向了和 substring() 呼叫之前不同的字元陣列。
PS:如果不明白“+”號操作符的工作原理,請查閱我之前寫的文章《羞,Java 字串拼接竟然有這麼多姿勢》,這裡就不再贅述,免得被老讀者捶。
04、最後
總結一下,JDK 7 和 JDK 6 的 substring() 方法本身並沒有多大的改變,但 String 類的建構函式有了很大的區別,JDK 7 會重新複製一份字元陣列,而 JDK 6 不會,因此 JDK 6 在執行比較長的字串 substring() 時可能會引發記憶體洩露的問題。
好了各位讀者朋友們,以上就是本文的全部內容了。能看到這裡的都是最優秀的程式設計師,二哥必須要為你點個贊