
資訊抽取——實體關係聯合抽取
目錄
- 簡介
- 實體關係聯合抽取
- Model 1: End-to-End Relation Extraction using LSTMs on Sequences and Tree Structures
- Model 2: Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme
- Model 3: Joint entity recognition and relation extraction as a multi-head selection problem
- Model 4: 基於DGCNN和概率圖的輕量級資訊抽取模型
- Model 5: Entity-Relation Extraction as Multi-turn Question Answering
- Model 6: A Novel Hierarchical Binary Tagging Framework for Joint Extraction of Entities and Relations
- 小結
簡介
通常,早期的資訊抽取將實體抽取和關係抽取看作串聯的任務,這樣的串聯模型在建模上相對更簡單,但這樣將實體識別和關係抽取當作兩個獨立的任務明顯會存在一系列的問題:
- 兩個任務的解決過程中沒有考慮到兩個子任務之間的相關性,從而導致關係抽取任務的結果嚴重依賴於實體抽取的結果,導致誤差累積的問題
- 對於一對多的問題,也就是關係重疊問題,串聯模型無法提供較好的解決方案
因此,近年來有許多工作都考慮將實體識別與關係抽取任務進行聯合建模,這種 end-to-end 的模型直覺上會有更優的效果。
實體關係聯合抽取
Model 1: End-to-End Relation Extraction using LSTMs on Sequences and Tree Structures
原文連結:https://www.aclweb.org/anthology/P16-1105/
該論文是經典的 end-to-end 實體關係聯合抽取模型,在此之前,聯合抽取模型通常都是基於人工構造特徵的結構化學習方法,而該論文采用了端到端的神經網路結構來進行建模,該模型基於詞序資訊以及依存樹結構資訊來抽取實體以及實體關係,其主要模型結構如下圖所示:
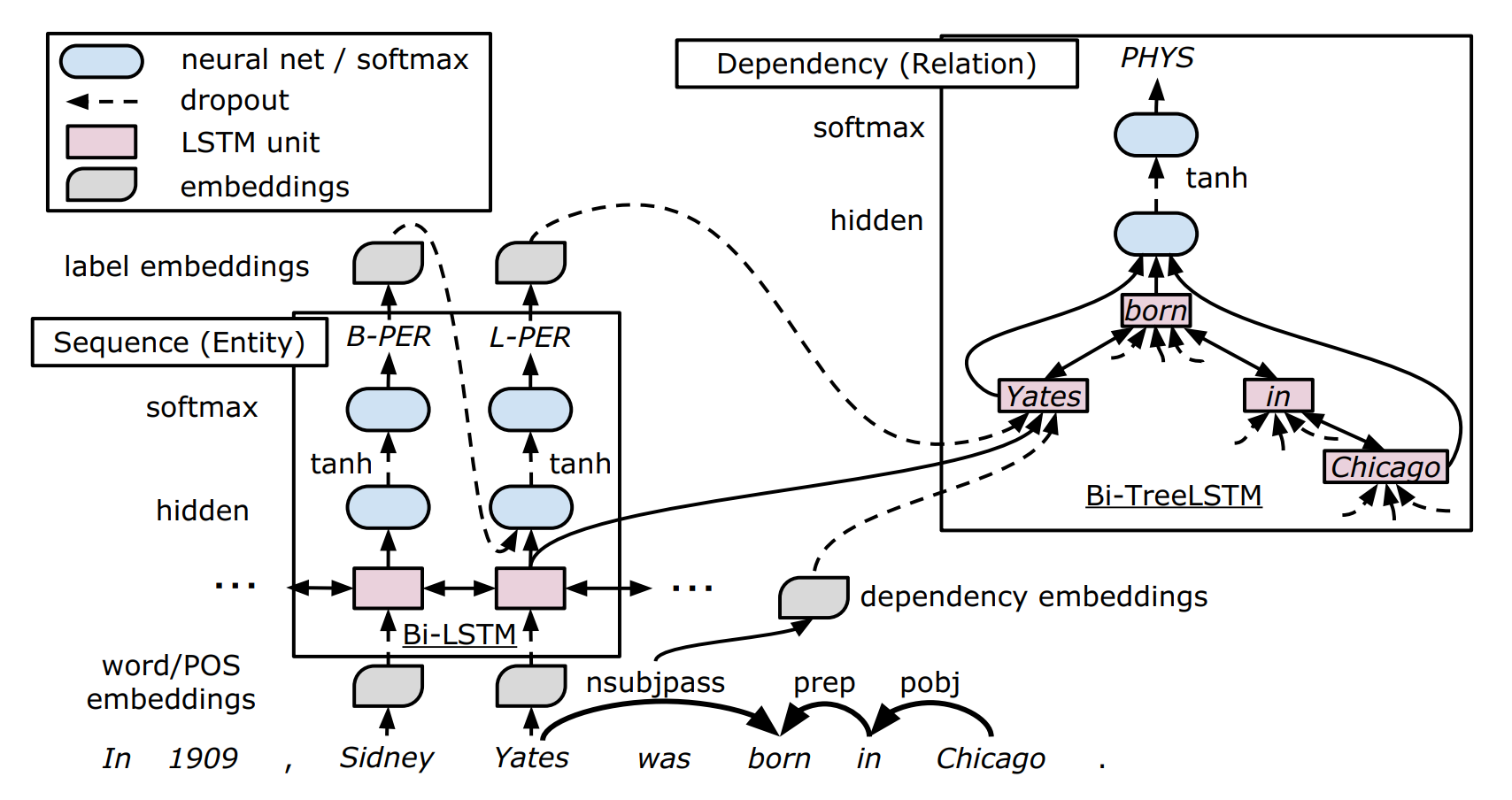
該模型主要分為如下三個部分:
- Embeddings layer:Embedding 層主要用於學習對應表徵,整個模型中主要有四個 Embedding 層,分別用來表示詞嵌入\(v^{(w)}\)、詞性(POS)嵌入\(v^{(p)}\)、依存關係嵌入 \(v^{(d)}\) 以及實體標籤嵌入 \(v^{(e)}\)。注意每個嵌入層是用在模型的不同位置的。
- Sequence Layer:嵌入層的詞嵌入以及POS嵌入作為該層的輸入,即時刻 \(t\) 的輸入為 \(x_t = [v^{(w)}_t, v^{(p)}_t]\),Sequence Layer 主要完成的是實體識別任務,有如下幾個小塊
- 利用 BiLSTM 作為序列編碼器,得到的輸出則是 BiLSTM 在同一個時刻兩個方向上的輸出 \(s_t = [\overrightarrow{h}_t; \overleftarrow{h}_t]\)
將實體識別任務看作是一個序列標註任務,實體標籤採用 BILOU(Begin, Inside, Last, Outside, Unit) 的標註方式,而實體類別接續在實體標籤之後 (標準方法可以參考我關於序列標註的第一篇文章)。利用兩個全連線層來實現實體識別
顯然,在每個詞的標籤預測時,將考慮到上一個詞的預測結果,從而考慮到標籤上的依賴性。
\[\begin{aligned} h^{(e)}_t &= tanh(W^{(e_h)}[s_t; v_{t-1}^{(e)}] + b^{(e_h)})\\ y_t &= softmax (W^{(e_y)}h^{(e)}_t + b^{(e_y)}) \end{aligned}\]
Dependency layer:該層主要關注兩個實體在依存樹的最短路徑(shortest path),最短路徑在做個關係分類研究中已被證明是十分有效的。作者採用了雙向樹結構的 BiLSTM 來捕捉兩個實體之間的關係。從論文中的表示式來看,樹結構的 LSTM 與傳統 LSTM 的區別在於,其接受多個子節點的隱藏資訊,而不僅僅是上一個時刻的隱藏資訊。作者提出一種新的基於樹結構的 LSTM,其相同型別的子節點共享引數矩陣,同時允許可變數量的子節點(感興趣的讀者可以去原文看看模型細節,公式較多這裡就不做詳細介紹了)。該層以對應 Sequence Layer 對應時刻的隱藏狀態、依存關係嵌入和實體標籤嵌入的拼接作為模型輸入,即
\[x_t = [s_t; v_t^{(d)}; v_t^{(e)}]\]作者將 Dependency layer 堆疊在 Sequence layer 上,因此 Dependency layer 可以依賴 Sequence layer 的輸出,或者說實體識別的結果間接地對關係分類的結果加以影響。
對於構造的樹結構的 BiLSTM,存在兩個傳輸方向,即從子節點到根節點方向 "\(\uparrow\)",和從根節點到子節點方向 "\(\downarrow\)",最終用於關係分類的輸入,為根節點位置 \(\uparrow\) 方向上的隱藏狀態,和兩個實體的 \(\downarrow\) 方向上的隱藏狀態的拼接,即
\[d_p = [\uparrow h_{pa}; \downarrow h_{p1}; \downarrow h_{p2}]\]此外,考慮到每個輸出都是隻考慮到單詞之間的關係,而無法利用整個實體的資訊,為了緩解這個問題,作者將 Sequence layer 上對應實體的隱藏層求平均拼接到 \(d_p\) 上,即
\[d_p' = [d_p;\frac{1}{|I_{p_1}|}\sum_{i\in I_{p_1}}s_i;\frac{1}{|I_{p_2}|}\sum_{i\in I_{p_2}}s_i]\]其中,\(I_{p_1}\) 和 \(I_{p_2}\) 分別表示實體 1 和實體 2 的單詞集合,將該向量直接輸入與 Sequence layer 中類似的分類器進行分類,即
\[\begin{aligned} h^{(r)}_p &= tanh(W^{(r_h)}d_p' + b^{(r_h)})\\ y_p &= softmax (W^{(r_y)}h^{(r)}_t + b^{(r_y)}) \end{aligned}\]
小結:總的來說,該任務通過在實體識別和關係抽取任務中共享 Embedding layer 和 Sequence layer 引數的方法,加強兩個任務之間的相關性,確實存在一定的創新,且設計了樹結構的 LSTM 模型用於關係分類任務中。但是其模型設計上還存在很大的缺陷,如實體抽取任務上忽略了標籤之間的長依賴關係,此外實體與關係的抽取還是存在先後性,兩個任務並不是完全同步進行的。這篇論文首次將神經網路模型用於解決實體關係聯合抽取任務,屬於這塊領域的開山之作,之後很多工作都在此基礎上進行改進,或與該工作的結果進行對比
Model 2: Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme
原文連結:https://arxiv.org/abs/1706.05075
該篇論文被評為 ACL2017 傑出論文,其主要做法是將實體關係聯合抽取任務看作一個序列標註任務來處理,取得了非常好的效果。
作者認為,之前的做法多數都需要大量複雜的特徵工程,並且十分依賴其他的 NLP 工具,這將導致誤差傳播問題。雖然 Model 1 通過共享引數的方法將兩個任務整合到同一個模型當中,但是實體抽取與關係識別任務仍然是兩個分離的過程,這將造成產生大量的冗餘資訊。
作者認為,實體關係聯合抽取的關鍵就是要得到實體對以及它們之間關係組成的三元組。因此作者的做法是直接對三元組進行建模,而不是分別提取實體和關係。為了解決這個問題,作者設計了一種新穎的標註方案,它包含實體資訊和它們所持有的關係,對於系列標註問題,很容易使用神經網路來建模,而不需要複雜的特徵工程。
論文的主要貢獻有如下幾點:
- 提出了一種新的標註方案,聯合提取實體和關係,可以很容易地將提取問題轉化為標註任務。
- 基於我們的標註方案,我們研究了不同型別的端到端模型來解決問題。基於標記的方法比大多數現有的流水線和聯合學習方法要好。
- 此外,我們還開發了具有偏置損失函式的端到端模型,以適應新型標註。它可以增強相關實體之間的關聯。

下面簡單介紹一下論文如何將提取問題轉換為基於本文標註方法的標註問題,簡單的標註例項如上圖所示
- 需要抽取的三元組可以表示為:(Entity1, RelationType, Entity2),其中,Entity1 和 Entity2 需要抽取的文中的實體,RelationType 為預定義的 Entity1 和 Entity2 之間的關係
- 非抽取物件用標籤 "O" 標註,表示 "Other"
- 實體物件的標籤由三部分組成:單詞位置、關係型別、關係角色
- 單詞位置使用 "BIES" 的方式來標註,表示單詞在實體中的位置資訊
- 關係型別直接從預定義的關係集合中獲得
- 關係角色直接用 "1" 和 "2" 表示,用於表示實體在三元組中的位置
- 標籤的總數為 $2 \times 4 \times|R| + 1 $,其中 \(|R|\) 是預定義的關係集的大小
- 對於已標註的序列,根據就近原則將其合併為需要抽取的三元組

端到端模型的基本架構如上圖所示,主要包括如下幾個部分:
- BiLSTM Encoder layer: 將傳統的 BiLSTM 作為序列編碼層,並將對應時刻的雙向隱藏輸出拼接得到對應詞的編碼結果,即 \(h_t = [\overrightarrow{h}_t; \overleftarrow{h}_t]\)
LSTM Decoding Layer: 從圖中可以清楚的看到差別,LSTM Decoding Cell 與經典的 LSTM 的區別在於,其當前時刻的輸入除了上一時刻的隱藏狀態 \(h^{(2)}_{t-1}\) 以及當前時刻的輸入 \(h_t\) 之外,還包括上一時刻的預測標籤表示 \(T_{t-1}\),即
\[h_t^{(2)} = LSTM(h_t, [h^{(2)}_{t-1}, T_{t-1}])\]對於時刻 \(t\) 的隱藏狀態,通過一個全連線層得到標籤表示:
\[T_t = W_{ts}h_t^{(2)} + b_{ts}\]
最終將標籤表示輸入經典的全連線層分類器進行分類:
\[\begin{aligned}
y_t &= W_yT_t + b_y\\
p_t^i&=\frac{exp(y_t^i)}{\sum_{j=1}^{N_t}exp(y_t^j)}
\end{aligned}\]
The Bias Objective Function: 定義了一個標籤偏置函式
\[ L = max\ \sum_{j=1}^{|D|}\sum_{t=1}^{L_j}(log(p_t^{(j)}=y_t^{(j)}|x_j, \Theta)\cdot I(O) + \alpha \cdot log(p_t^{(j)}=y_t^{(j)}|x_j, \Theta)\cdot (1- I(O)))\]上式中,\(|D|\) 是訓練集的大小,\(L_j\) 是句子 \(x_j\) 的長度,\(y_t^{(j)}\) 是單詞 \(x_j\) 中詞 \(t\) 的標註,\(p_t^{(j)}\) 是模型輸出的歸一化標註概率。此外,\(I(O)\) 是一個開關函式,以區分標註 ‘O’ 與 其他標註。他被定義如下:
\[I(O) = \begin{cases} 1,\ if\ tag = 'O'\\ 0,\ if\ tag \ne 'O' \end{cases}\]簡單來說,就是使得模型對於實體標籤與其他標籤的關注程度不一樣,而引數 \(\alpha\) 就是偏置權重,\(\alpha\) 越大,模型對於實體的相關標註的偏向性就越大。
小結:這篇論文通過巧妙的設計將實體與關係聯合抽取任務當作一個序列標註任務來處理,大大簡化了工作的複雜性,且其模型效能優於之前的工作。此外,模型的缺陷也是比較明顯的,其無法考慮到實體關係重疊的問題,也就是說一個實體在上下文中可能與多個實體有不同的關係。
Model 3: Joint entity recognition and relation extraction as a multi-head selection problem
原文連結:https://arxiv.org/abs/1804.07847
論文指出了目前的實體關係抽取任務存在的一些問題:
- 目前 State-of-the-art 的聯合抽取模型依賴外部的NLP工具提取特徵,模型效能嚴重依賴 NLP 工具的效能;
- 之前的工作沒有考慮實體關係重疊問題,即一個實體可能與上下文中的多個實體有不同的關係。
該論文創新點在於其將實體關係聯合抽取問題看作是一個 multi-head selection 的問題,即任何一個實體都可能與其他實體存在關係,目的是解決關係重疊問題。
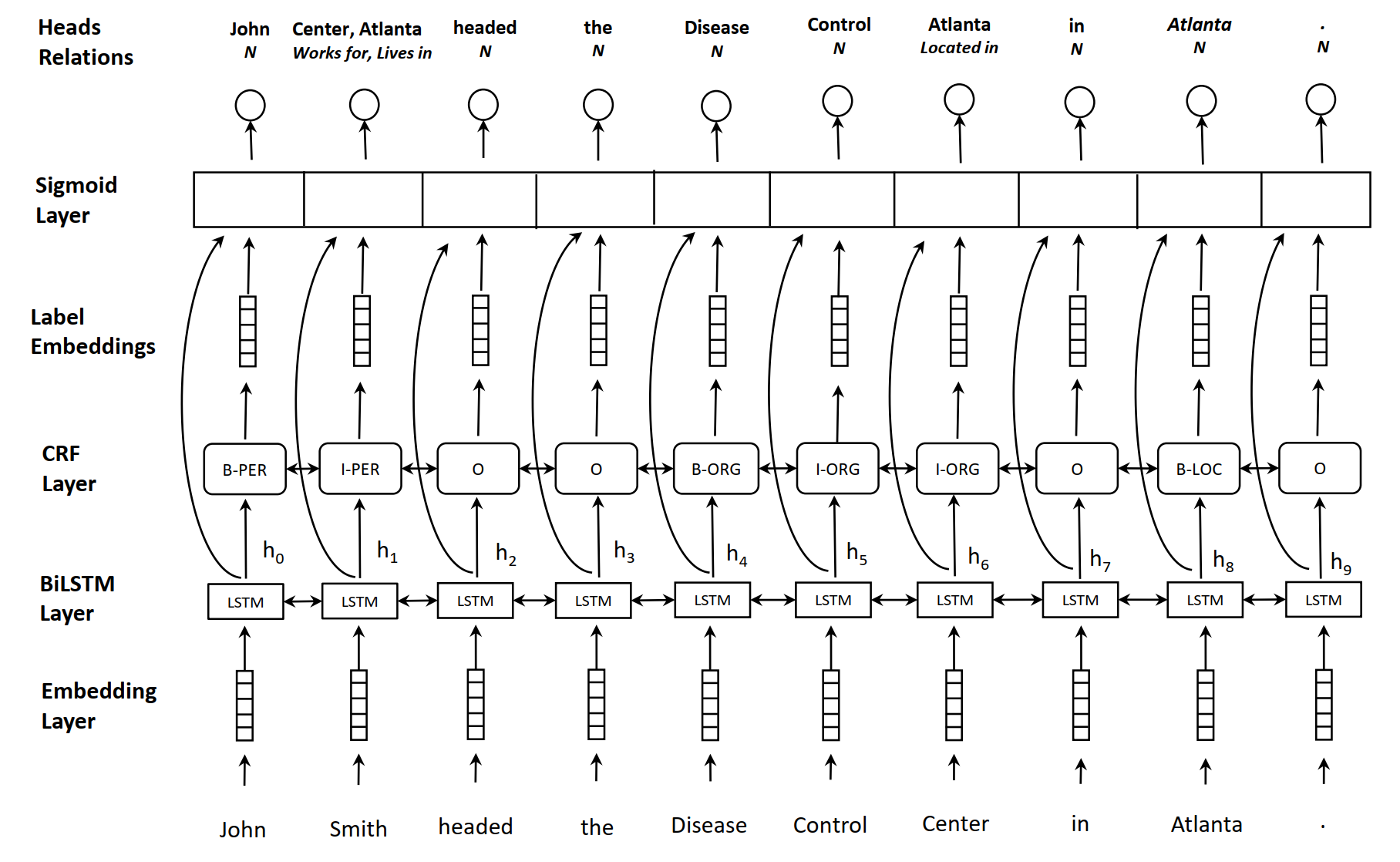
該論文提出的模型如上圖所示,包括以下結構:embedding layer,BiLSTM layer,CRF layer,sigmoid scoring layer。
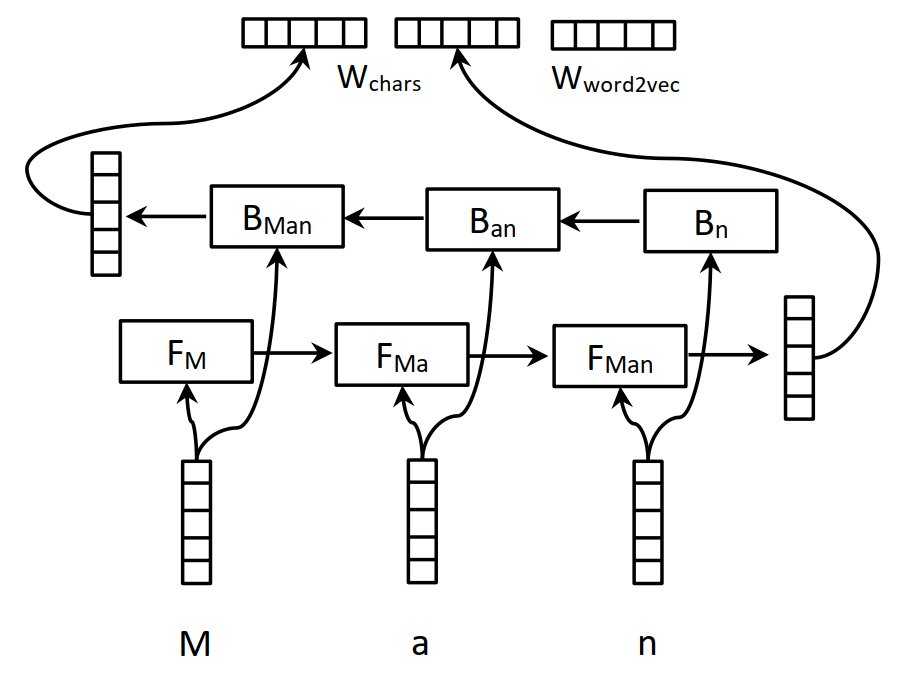
Embedding layer:Embedding layer 主要用於生成詞表徵,包括字元級別的向量和詞級別的向量兩個部分,構造方式如下所示,引入字元級別的向量是因為字元級別的向量可以融入一些形態學特徵
BiLSTM encoding layer:利用 多層的 BiLSTM 來對句子進行編碼,每一個時刻的輸出為兩個方向的向量的拼接:
\[h_i = [\overrightarrow{h}_i; \overleftarrow{h}_i], i = [0, ..., n]\]- CRF layer: 在 BiLSTM 之後接 CRF 來輔助實體識別已經是常規操作了,實體識別部分的標註方式是 BIO,此外在實體位置標註之後還接有實體類別標註,在圖中也有很清楚的表示
Label Embedding:構造一個 Label Embedding 層,用來獲取標籤相應的向量表徵,也是可訓練的,用 \(g_i\) 表示第 \(i\) 個 token 的預測標籤向量
multi-head selection problem:將關係抽取看作一個 multi-head selection problem,multi-head 的含義是每個 實體 與其他所有 實體 都存在關係,在判斷關係的時候,為了避免造成資訊冗餘,只判斷每個實體的最後一個 token 與其他實體的最後一個 token 的關係,而每個實體的最後一個 token 被稱作 head。對於每個 head ,需要預測元組 \((\hat{y}_i, \hat{c}_i)\),其中 \(\hat{y}_i\) 表示當前 token 的關係物件,\(\hat{c}_i\) 表示兩者之間的關係。對於給定的 token 向量 \(w_i\) 和 \(w_j\),其關係為 \(r_k\) 的分數為:
\[s^{(r)}(z_j, z_i, r_k) = V^{(r)}f(U^{(r)}z_j + W^{(r)}z_i + b^{(r)})\]其中,\(z_i = [h_i; g_i]\),\(f(·)\) 為啟用函式,\(U^{(r)}, W^{(r)}\) 相當於先將向量進行降維,\(V^{(r)}\) 是一個一維向量,最後輸出的是一個分數值,之後再將分數對映為概率值
\[Pr(head=w_j, label=r_k|w_i)=\sigma(s^{(r)}(z_i, z_j, r_k))\]關係抽取過程的損失函式定義為:
\[L_{rel} = \sum_{i=0}^{n}\sum_{j=0}^{m}-log\ Pr(head=y_{i,j}, relation=r_{i,j}|w_i)\]整個模型的損失函式即為 \(L_{ner} + L_{rel}\)
在預測階段,可以通過認為輸出的預測概率超過某一個閾值就認為這個關係是有效的。注意,該模型對兩個詞之間過個關係的預測並不是採用的 softmax 函式,而是對每個關係採用了 sigmoid 函式,區別在於 softmax 是將所有類別看作是互斥關係,將所有分數歸一化為和為 1 的形式,而 sigmoid 與 softmax 的區別在於,其獨立的將每個類別的判斷看作是獨立二分類的問題,即各個類別不存在互斥關係,這樣跟有利於判斷出兩個實體之間存在的多種關係的情況。
小結:這篇文章的關鍵創新點在於其將關係抽取任務當作一個 multi-head selection problem 的問題,從而使得每個實體能夠與其他所有實體判斷關係,此外,不再將關係抽取任務當作一個每個關係互斥的多分類任務,而是看作每個關係獨立的多個二分類任務,從而能夠判斷每一對實體是否可能有多個關係存在。此外,該組在同一年還發布了一篇以該論文為 baseline,在訓練過程中加入對抗擾動的論文,分數達到新高,有興趣的同學可以關注一下
Model 4: 基於DGCNN和概率圖的輕量級資訊抽取模型
原文連結:https://kexue.fm/archives/6671
這個模型是蘇神提出的 DGCNN 用於實體關係抽取的模型,一直感覺這個模型設計的挺巧妙的,這裡也記錄下。資料集是百度給出的中文資訊抽取資料集(需要的話可以去蘇神部落格裡找,有下載連結)。
首先,作者發現數據主要有以下幾個特點:
- s和o未必是分詞工具分出來的詞,因此要對query做標註才能抽取出正確的s、o,而考慮到分詞可能切錯邊界,因此應該使用基於字的輸入來標註;
- 樣本中大多數的抽取結果是“一個s、多個(p, o)”的形式,比如“《戰狼》的主演包括吳京和余男”,那麼要抽出“(戰狼, 主演, 吳京)”、“(戰狼, 主演, 余男)”;
- 抽取結果是“多個s、一個(p, o)”甚至是“多個s、多個(p, o)”的樣本也佔有一定比例,比如“《戰狼》、《戰狼2》的主演都是吳京”,那麼要抽出“(戰狼, 主演, 吳京)”、“(戰狼2, 主演, 吳京)”;
- 同一對(s, o)也可能對應多個p,比如“《戰狼》的主演和導演都是吳京”,那麼要抽出“(戰狼, 主演, 吳京)”、“(戰狼, 導演, 吳京)”;
- 極端情況下,s、o之間是可能重疊的,比如“《魯迅自傳》由江蘇文藝出版社出版”,嚴格上來講,除了要抽出“(魯迅自傳, 出版社, 江蘇文藝出版社)”外,還應該抽取出“(魯迅自傳, 作者, 魯迅)”。
由上可知,資料集的質量非常高,且情況也十分複雜。作者由此調研了當時主要的資訊抽取模型,發現沒有一個模型能很好地覆蓋這5個特點。於是自行設計了一個基於概率圖思想的抽取方案,然後從效率出發,利用 CNN+Attention 的架構完成了這個模型。
作者設計的抽取方案借鑑了 seq2seq 的概率圖思路。在 seq2seq 解碼器的解碼過程是層次遞迴進行的的,其實際上是在建模
\[P(y_1,y_2,...,y_n|x)=P(y_1|x)P(y_2|x,y_1)...P(y_n|x,y_1,y_2,…,y_{n−1})\]
而對於資訊抽取任務,三元組的抽取過程也能夠轉化為上述層次遞迴的方式進行抽取,對於三元組 (s, o, p),其抽取過程可以建模為:
\[P(s,p,o)=P(s)P(o|s)P(p|s,o)\]
即首先預測 \(s\),然後根據 \(s\) 來預測該 \(s\) 所對應的 \(o\) 及 \(p\)。由於抽取 \(s\) 以及抽取 \(s\) 所對應的 \(o\) 及 \(p\) 的過程均是非唯一性的,因此,作者採用了 MRC 中常用的指標網路的抽取方法,即僅抽取答案的開始和結束位置,且把預測開始和結束位置的任務轉化為了預測每一個位置是否為開始位置或結束位置(將softmx換成sigmoid)。模型的整體結構如下圖所示
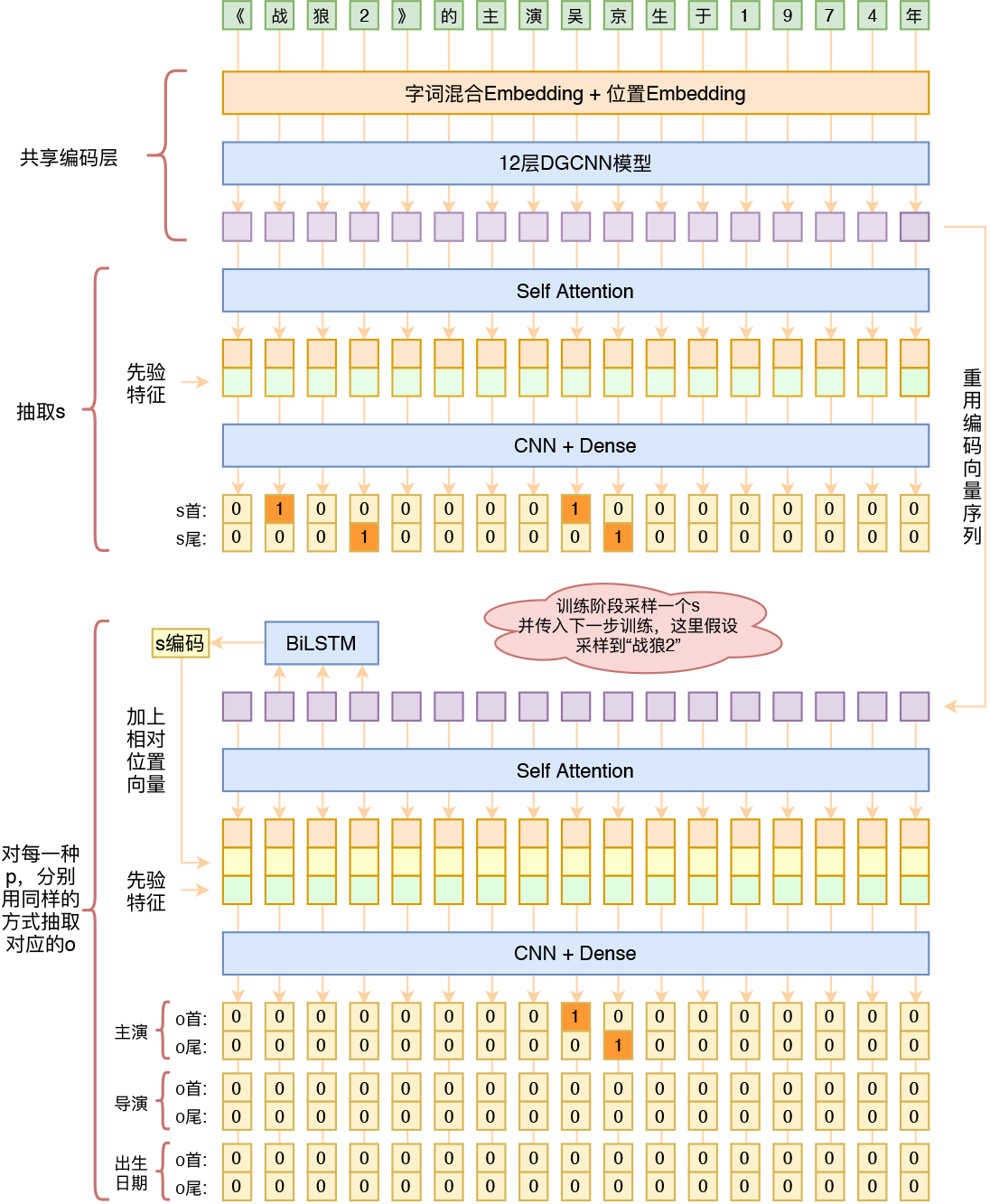
我們這裡只關注作者資訊抽取的思路,更多的模型細節可以去作者的部落格裡瞭解。總的來說,整個模型包括如下幾個部分:
- 字編碼層:得到字表徵
- \(s\) 抽取層:通過 Self-Attention 和 CNN 的結構來對 s 的開始和結束位置進行抽取
- 對於預測到的 \(s\) 將其對應位置的編碼結果通過一個 BiLSTM 進一步比啊媽,然後拼接到 Self-Attention 的輸出中,再通過 CNN 預測每一個 \(p\) 對應的 \(o\) 到開始和結束位置
作者的思路相比於之前的模型很好的解決了關係重疊問題,且主要架構是基於 CNN 和 Self-Attention,因此模型訓練速度非常快。作者在部落格結尾提到了下面要介紹的這篇論文,大致思想與作者的論文相類似,但是是通過將其轉化為一個多輪問答的形式將信從而將抽取過程建模為層次遞迴的。
Model 5: Entity-Relation Extraction as Multi-turn Question Answering
原文連結:https://www.aclweb.org/anthology/P19-1129/
過去大部分論文都將實體關係聯合抽取的任務看作是一個三元組抽取任務,而這樣的處理將存在如下幾個問題
- 在形式化層面上:簡單的三元組形式往往不能充分表現文字背後的結構化資訊,因為往往在文字中存在層級性的依賴關係。獨立地考慮兩種實體可能導致依賴關係的間斷。
- 在演算法層面上:對於關係抽取任務,大多數模型都是以標記的 mention 作為輸入,而模型的主要目的是判斷兩個 mention 是否存在某種關係,在這種情況下,模型難以捕捉詞彙、語法以及語義上的關係,特別是在如下幾種情形下:
- 實體相距很遠;
- 一個實體出現在多個三元組中;
- 關係跨度相交
這個篇文章的創新點在於其將實體關係聯合抽取的任務當作一個多輪問答類問題來處理,即每種實體和每種關係都用一個問答模板進行刻畫,從而這些實體和關係可以通過回答這些模板化的問題來從上下文中進行抽取。下面簡單給出一個問答模版:

可見,問題主要有如下幾個特點:
- 首先確定目標實體 \(e1\)
- 之後根據目標實體和候選關係類別進行提問
這樣的處理方法主要有如下幾個優點:
- 能夠很好地捕捉標籤的層次依賴性。即隨著每一輪問答的進行,我們有序的獲得所需要的實體,這與多回合填充式對話系統類似
- 問題的編碼能夠整合對關係分類任務重要的一些先驗資訊,這些資訊可以潛在地解決了現有關係抽取模型難以解決的問題,如遠距離實體對,或是關係重疊問題
- QA任務提供了一種很自然的方式來融合實體抽取和關係抽取任務,因為 QA 任務對於沒有答案的問題可以返回 None,則對於不存在相應關係的問題,如果返回的不是 None,則可以同時確定實體和關係

將實體關係抽取任務轉化為多輪問答任務的演算法如上所示,整個演算法分如下幾個部分:
- 頭實體抽取(line 4 - 9):由於每一輪多輪對話都需要一個頭實體來作為 trigger,因此需要事先抽取句子中所有的頭實體,而抽取實體的過程可以看作一個抽取 entity_question 答案的過程。所有 entity_question 都存放在 EntityQuesTemplates 中,每一種 entity_question 都對應一類實體的抽取
- 關係與尾實體抽取(line 10 - 24):ChainOfRelTemplates 定義了一個關係序列,我們需要根據這個關係序列來進行多輪問答。同時,它也定義了每種關係的模板,為了生成對應的問題(第14行),我們要在模板槽(slot)中插入之前抽取的實體。然後,關係 REL 和尾實體 e 就能通過回答問題同時被抽取出來。如果回答是 None,就說明沒有答案,即只有同時抽出頭實體,以及頭實體存在對應的關係和尾實體被抽出時,才算是成功抽出一個滿足條件的三元組了。
關於問題模版的生成方式可以參考原文中的方法,這裡就不贅述了。
我們知道現階段常見的 MRC 模型都是通過指標網路的方式,僅預測答案在 Context 中的開始和結束位置,僅適用於單答案的情況。但對於實體識別任務,在一段 Context 中可能有多個答案,所以這種方法並不合適。作者的做法是將其當作以問題為基礎的序列標註問題,或者說將 2 個 N-class 分類任務轉換成 N 個 5-class 分類任務,其中 N 為句子長度。
作者將 BERT 作為 baseline。訓練時,損失函式為兩個子任務的疊加,即:
\[L = (1-\lambda)L(head_entity) + \lambda L(tail_entity, rel)\]
為了進一步優化模型效能,還採用了強化學習的方法來進一步優化,這一塊暫時也不做研究了,感興趣的同學可以去原文參考一下
Model 6: A Novel Hierarchical Binary Tagging Framework for Joint Extraction of Entities and Relations
原文連結:https://arxiv.org/abs/1909.03227
這篇文章在 WebNLG 和 NYT 資料集上取得了 SOTA 的效果,模型的整體思路與蘇神的模型非常類似。該論文指出,當前處理關係重疊的模型仍然存在一系列問題,具體來說,它們都將關係視為要分配給實體對的離散標籤。 這種表述使關係分類成為困難的機器學習問題。 例如,當在相同上下文中的同一實體參與多個(在某些情況下超過五個)有效關係(即重疊的三元組)時,分類器需要大量的監督學習才能確定上下文與關係的對應關係。
作者設計了一種 Hierarchical Binary Tagging 的框架來解決這個問題,這個框架將三元組的抽取任務建模為三個級別的問題,從而能夠更好解決三元組重疊的問題。其核心觀點就是不再將關係抽取的過程看作實體對的離散標籤,而是將其看作兩個實體的對映關係,即\(f(s, o) -> r\),整個三元組的過程可以概括為
- 抽取三元組中的 subject
- 針對每一個 \(f_r(·)\),抽取其對應的 object
實體抽取的方法與上一片論文以及蘇神的做法差不多,即採用 Point Net 的指標形式進行抽取。這樣的建模方式明顯更容易學習。實驗結果表明即便使用隨機初始化的 BERT 作為編碼層,仍然能夠取得 SOTA 的效果。

模型的整體結構如上圖所示,主要包括如下幾個部分:
- BERT Encoder:通過 BERT 得到每個詞的詞表徵,關於 BERT 這裡不做具體介紹了,把 BERT 的輸出當作詞向量用即可
Subject Tagger:該部分用於識別所有可能的 subject 物件。其通過對每一個位置的編碼結果用兩個分類器進行分類,來判斷其是否是實體的開始或結束位置,即
\[ p^{start\_s}_i = σ(W_{start}x_i + b_{start}) \\ p^{end\_s}_i = σ(W_{end}x_i + b_{end}) \]其中,\(x_i\) 為第 i 個詞通過 BERT 的編碼輸出,\(W, b\) 為全連線層分類器的引數,啟用函式為 sigmoid。對於句子中存在多個 subject 的情況,開始指標與結束指標通過就近匹配原則進行配對
- Relation-specific Object Taggers:針對每一個 subject,都需要對其進行之後的 object 進行預測。由圖中可知,其與 Subject Tagger 基本一致,主要區別在於
- 每一個關係類別獨享一組 object 分類器
- 這一部分的輸入除了輸入序列的 BERT 編碼結果,還額外加入了 subject 的特徵,subject 特徵為 subject 的每個字元的 BERT 表徵的平均池化
- 主要表示式如下
\[p^{start\_o}_i = \sigma(W^r_{start}(x_i + v^k_{sub}) + b^r_{start}) \\ p^{end\_o}_i = \sigma(W^r_{end}(x_i + v^k_{sub}) + b^r_{end})\]
小結
早期聯合抽取模型的架構主要可分為兩個部分:
- 實體對抽取
- 實體間關係分類
其將關係分類看作兩個實體間的離散標籤多分類問題,這樣的問題學習起來是十分困難的,或者說無法很好的學習到兩個標籤之間的相關性。近年來的模型大多都將其建模為層次遞迴的模型,其直接為每個關係類別構建獨立的模型,用於學習這種關係對映關係,主要可以分為下面兩個部分
- 抽取所有可能的第一個 subject
- 對於每一個 subject,將其輸入到每一個關係類別模型中,抽取每個關係對應的 object
這種將實體關係當作一種函式對映來學習的方式顯然能夠得到更好的效果。
參考連結
https://zhuanlan.zhihu.com/p/74886839
https://mp.weixin.qq.com/s?__biz=MzI2NjkyNDQ3Mw==&mid=2247486614&idx=2&sn=46b8a011a29803fc59f14431e91b8fbd&chksm=ea87f440ddf07d564cb3ce680ea52277c12bce882419428c581b95abbf58d75265fd3fb01942&scene=21#wechat_redirect
https://blog.csdn.net/qq_32782771/article/details/86062586
https://zhuanlan.zhihu.com/p/6587