
Attention-Based Bidirectional Long Short-Term Memory for Relation Classification雙向lstm實體關係分類
本文章主要內容為關係分類的重大挑戰是一個短文字的重要資訊的位置並不確定提出的attention雙向lstm;attention在許多部落格都有相關解釋,這裡不作說明,雙向lstm是對單向lstm做的改進,要通過上下文資訊對當前lstm神經元做影響;
在引言部分作者介紹了關係分類的重要性,例如資訊提取以及智慧問答,文章舉了一個小例子,實體與目標之間的關係,它是有關於flower和chapel之間的關係 。 <e1>Flowers </e1>are carried into the <e2>chapel</e2>,其中<e1></e1>等四個標記分別代表位置關係指定了“the nominals”的開始與結束。對於整個句子主要資訊再與實體或者主題的提取,表達整個句子意思,可見實體提取非常重要。
在引言最後開始說名大部分傳統方法運用了許多手工特徵/最近深度學習減少了手工特徵,但是仍然運用了大量的高階特徵例如句法分析或者實體識別等第三方方法;(藉助第三方是否句有弊端,本熱認為並不能作為唯一的好壞之分,)作者運用雙向lstm加attention自動提取包含整個句子語義資訊關鍵詞彙或者字元,並且在實驗中在SemEval-2010 Task 8 dataset 獲得
F1-score of84%的分數。文章第二章主要講了相關工作有關於關係分類,第三章主要講了模型,第4張模型評估,第5張總結。
對於第2章不在進行解析,因為差不多就是說別人的缺點,以及在此基礎上的改進,直接進入主題。
第二章有關於關係分類的相關工作
要說明一下相關工作回顧整個發展,
(1)基於傳統的大部分都是模式匹配方法或者利用額外的nlp語義特徵,最典型的是rink用其他預料提取的特徵來對svm訓練分類.
(2)最近許多文獻開始利用深度網路自動提取特徵,最具有代表性的是zeng(2014)運用卷積網路進行分類,然而cnn不適合做長距離語義語義資訊(對於這個說法,本人並不贊同,由於利用卷積核獲取的特徵雖然是區域性特徵,但是對於深層又會對特徵進行組合,)
(3)相關工作是張運用雙向rnn從原始文字中學習模式類別,儘管雙向rnn已經獲取上下文資訊,由於梯度爆炸等原因(具體rnn為什麼會有梯度爆炸https://blog.csdn.net/qq_29340857/article/details/70556307講解的比較好),最後又說了zhang(2015)的利用nlp工具以及特徵pos,切詞,句法等高階特徵,作者的方法就是利用四個位置座標作為一個單詞,轉換所有單詞作為向量,簡單完整,(仍然不贊同,原因是一些句法名詞性是認為設定,本身涵蓋了模型,是人訓練的模型,新增這些特徵,會對模型有更好的效果,小孩之所以不知道詞性,並不代表小孩不會對詞進行分類,只不過他不知道每個詞性叫什麼).
第三章模型解析
模型主要分為五個部分:
1/ 輸入層:input layer:輸入一個句子;
2/編碼層:embedding layer:把每一個單詞對映到低維向量;
(為什麼稱為低維向量,自己理解對於詞,資料非常大,如果用詞袋模型,一個句子的向量長度是無法形容的,嗎例如:“今天你吃飯了嗎” 如果我們的詞袋含有(今天 你 我 吃飯 ,...,) 那麼一個單詞就表示為例如今天標示為【1,0,0,0,0】,首先矩陣比較稀疏,第二不能夠很好的表達詞之間的位置關係,具體介紹請在網上查閱詞向量概念,介紹的比較清除)
3/lstmlayer: 從句子向量(2)獲取高層特徵;
4/attention layer :主要是兩個過程(1)產生一個權重向量,把每一步的單詞級別向量合併成句子級別向量,;(2)把兩者相乘;
5/output layer :最後輸出的是能夠進行分類的向量;
接下來進行解析整個模型每一部分:
3.1 單詞編碼
輸入一般都是一個句子含有T個單詞表示為 S={x1,x2,...,xT},其中沒一個單詞xi轉化為一個向量ei,怎麼做的的其實和普通的編碼是一個過程;我們舉例:
第一步首先對於一個句子S("張傑的看月亮爬起來")把他對映到一個矩陣,其中V表示整個模型的語料詞彙的大小,
對詞彙進行編碼詞向量的大小,
標示需要學習的引數,
是使用者需要設定的超引數,假設我們有的資料語料為(張傑,的,看,月亮,爬起來,吃飯),則
矩陣表示為:
(張傑,的,看,月亮,爬起來,吃飯)
,
每一列表示一個詞彙向量,那麼把單詞xi對映到ei的公式如下:
,其中
表示one hot ,也就是哪個詞出現了在輸入文字中,對於句子“張傑的看月亮爬起來”的張傑對應的就是
,那麼一個句子作為實際模型輸入表示為{e1,e2,...,eT}.這也是lstm的常規embedding編碼過程;
把訓練資料集做成vocabulary,對於每一個詞彙有對應的詞向量,根據下標對應詞向量。
3.2 雙向network
文章開始說了單向lstm沒有考慮未來的資訊對當前的影響,直接運用了 graves的lstm時用了雙向lstm,在這裡對lstm做簡要回顧,整個前向過程比較清晰,反向就是梯度要根據前向輸入,把梯度按照這個順序返回過去;在文章或者csdn對lstm有許多介紹,在graves那篇文章SPEECH RECOGNITION WITH DEEP RECURRENT NEURAL NETWORKS的圖片如下:
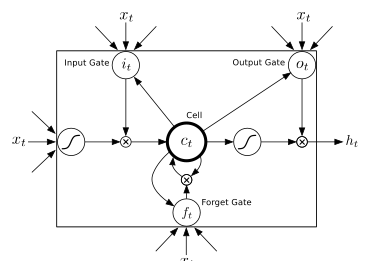
對應的公式如下:
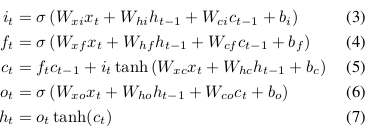
與本論文中的公式有所差別:本論文中公式如下:
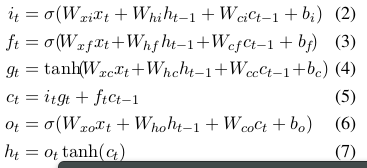
在本論中中
有
的狀態參與,所以說當前狀態及包含了當前輸入資訊以及之前狀態資訊,但是這樣做是否涵蓋重複資訊呢,(疑問來自
和
都有
時刻的狀態資訊,這樣增加應該是增強了之前的狀態資訊影響,在實際試驗,本人用seq2seq進行問答系統實驗,發現過擬合狀態,後來詞的生成幾乎只依賴前一個詞的生成,而與問句完全無關,這個說明運用一個state c狀態來涵蓋之前的所有資訊並不完全可行,實驗應該增加o或者h的輸出來增加上下文相關資訊)。
在此需要把作者的模型結構圖展示出來,對最終雙向lstm的輸出處理進行解釋:
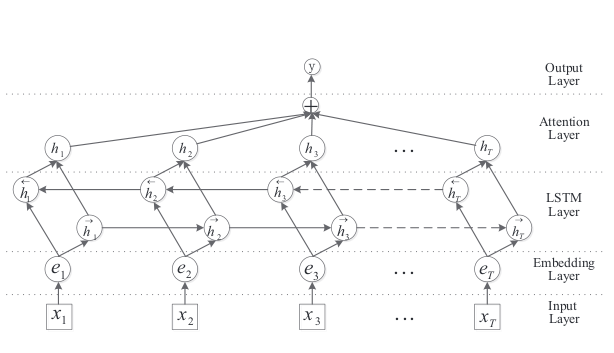
圖 3.2
可以看到對於輸入[x1,x2,...,xt}={"張傑 的 看 月亮 爬出來"} 每一個time step i輸入的詞彙得到的,在作者公式中如下:
就是把每一個單詞的前饋輸出與反饋輸出逐個元素求和得到的向量作為最後的輸出。
3.3 attention 注重層
通過雙向lstm得到了每一個單詞的輸出h_{i},我們得到了輸出向量,其中T為單詞的個數,注意力就是對每一個單詞的最後輸出來得到哪個單詞對關係分類重要程度,因此學習一個權重向量來得到最好的輸出:
因此權重層的結構輸出為:
M=tanh(H)(9)
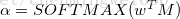
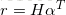
這個過程論文並沒有詳細解釋,為什麼這樣做,公式(9)把向量對映到-1到1的範圍之內,經過公式10,得到權重之後的特徵,至於再乘以原始輸出特徵,可能是為了增加特徵的影響,最後把權重輸出通過tanh對映:
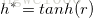
3.4分類
這裡作者直接用softmax分類器求解預測條件概率:
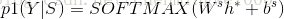
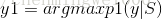

至此整個模型講解完畢,整體運用的增加了attention對真個文字進行資訊側重表示文字資訊的詞彙,可以根據粒度來增加句法的關係,實驗就不做介紹.因為本文的說明是為了對 github的程式碼進行詳細分析原理鋪墊,真個實體抽取,關係抽取在部落格https://mp.csdn.net/postedit/79893868,這裡介紹的只是整個系統的一部分.

