
Elasticsearch系列---初識搜尋
概要
本篇主要介紹搜尋的報文結構含義、搜尋超時時間的處理過程,提及了一下多索引搜尋和輕量搜尋,最後將精確搜尋與全文搜尋做了簡單的對比。
空搜尋
搜尋API最簡單的形式是不指定索引和型別的空搜尋,它將返回叢集下所有索引的所有文件(預設顯示10條):
GET /_search
響應的結果示例(有篩選,只取了一條document作為示例):
{ "took": 2, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": 3, "max_score": 1, "hits": [ { "_index": "music", "_type": "children", "_id": "2", "_score": 1, "_source": { "name": "wake me, shark me", "content": "don't let me sleep too late, gonna get up brightly early in the morning", "language": "english", "length": "55", "likes": 9 } } ] } }
針對響應報文的欄位,我們做一些簡單解釋:
- took:整個搜尋請求花費了多少毫秒。
- time_out:查詢是否超時。
- _shards:查詢中參與分片的總數,其中成功的分片數量,失敗的分片數量,以及跳過的分片數量。正常情況下不會有失敗的分片數量,如果發生了災難級別的故障,超過了容錯的最大node數量,可能會同時丟失shard和replica,此時會報告這些分片是失敗的,但還是會繼續返回剩餘可用分片的查詢結果。
- hits:包含total表示匹配到的文件總數,max_score值是所有匹配文件中_score的最大值。
- hits.hits:陣列內包含匹配的文件的完整資訊,預設查詢前10條資料,並且按_score降序排序。
timeout機制
預設不使用timeout引數,如果某些場景下,低響應比搜尋完整結果更重要,可以指定timeout為10ms或1s,在指定的超時時間內,Elasticsearch會把已經成功搜尋到的文件返回。
注意timeout不是停止執行查詢,它只是告訴Coordinate Node返回到指定時間為止收集到的結果,並且關閉連線,在ES後臺,其他node正在進行的查詢並不會中斷,只是結果沒人要了。
舉個例子:某電商平臺商品SKU品類300萬條,輸入某個關鍵字查詢,有2000條記錄匹配,但是要查15秒鐘,一個搜尋要等15秒才出結果,顯得太不專業了,產品有SLA要求,必須1秒內出結果,最快的解決方案是查詢使用引數timeout=1s,前端分頁顯示預設只展示20條,1秒內的查詢結果要填滿這20條還是比較容易的。
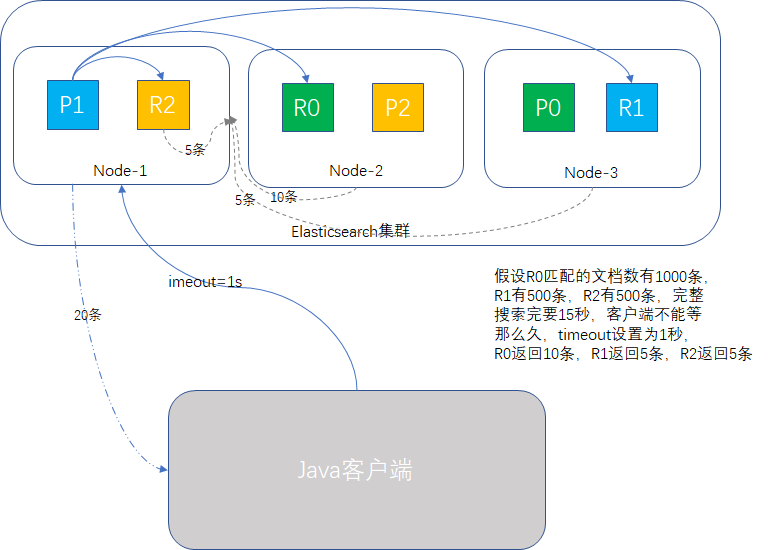
多索引搜尋
一個搜尋請求,可以同時寫多個索引名稱,這叫做multi-index搜尋模式。
/_search:所有索引,所有type下的所有資料都搜尋出來
/index1,index2/_search:同時搜尋兩個index下的資料
/1,2/_search:按照萬用字元去匹配多個索引
單一索引下搜尋時,ES會轉發請求到索引的每個分片中,shard或replica均可,然後收集結果返回。多索引時,原理相同,只是涉及的分片更多。另外搜尋一個索引有5個分片和搜尋5個索引各有一個分片,效能是等價的。
順帶我們看一下搜尋原理示意圖:
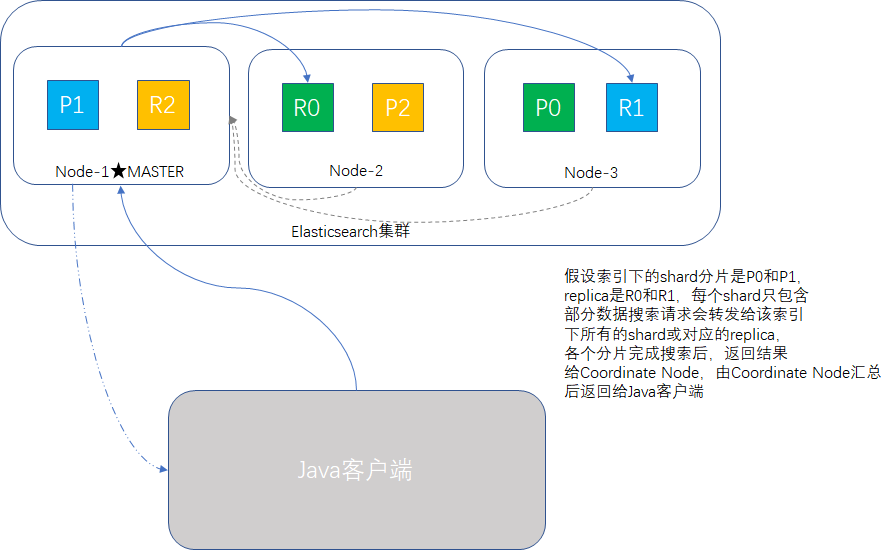
輕量搜尋
有兩種形式的搜尋API,一種是query string search,查詢條件和排序規則寫在request URI裡,也叫輕量搜尋;另一種是query DSL,查詢條件等資訊用JSON格式寫在request body裡。
輕量搜尋的示例:
單個欄位搜尋,"q="後面接的是查詢條件"field:text",field是欄位名,text是搜尋的關鍵詞,有三種字首修飾符:
GET /music/children/_search?q=content:friend
GET /music/children/_search?q=+content:friend
GET /music/children/_search?q=-content:friend- "+"號字首表示必須與查詢條件匹配。
- "-"號字首表示一定不與查詢條件匹配。
- 預設沒寫字首表示條件可選
匹配的條件越多,文件就越相關。
如果多個欄位搜尋,多個條件之間要有空格:
GET /music/children/_search?q=-content:friend +name:wake_all元資料的原理
如果"q="後面沒寫field,直接跟的是搜尋關鍵詞,表示搜尋指定索引下的所有欄位,如下:
GET /music/children/_search?q=friend只要music索引下的document,任何一個欄位包含friend,就能搜尋出來。那_all是怎麼來的?
_all是Elasticsearch中的元資料,在建立索引的時候,新增一個document裡面包含了多個field,此時,es會自動將多個field的值,全部用字串的方式串聯起來,變成一個長的字串,作為_all field的值,同時建立索引。後面如果在搜尋的時候,沒有對某個field指定搜尋,就預設搜尋_all field。
找個document示例:
"name": "wake me, shark me",
"content": "don't let me sleep too late, gonna get up brightly early in the morning",
"language": "english",
"length": "55",
"likes": 9"wake me, shark me don't let me sleep too late, gonna get up brightly early in the morning english 55 9",作為這一條document的_all field的值,同時進行分詞後建立對應的倒排索引
注意事項
輕量搜尋在開發階段會拿這些命令來做一些簡單的查詢,實際生產中用得比較少,語法複雜容易錯,並且可閱讀性低,遇到重量級查詢,還有可能會把ES叢集拖垮。
精確搜尋與全文搜尋
Elasticsearch的資料型別可以分成兩類:精確值和全文。
精確值(exact value)
精確值如日期、ID,數值型別,有些文字型別也可以表示精確值,如郵箱、常用縮寫等等。精確值的一個特點是必須完全相同、大小寫敏感,很容易查詢,hello與Hello是不相等的,日期為2019-11-20的欄位值,輸入2019是搜尋不到的。- 全文(full text)
全文資料就微妙得多,拿英文來說,各種詞根變化、大小寫轉換、同義詞、縮寫,漢字方面各種分詞、詞庫、網路詞等,都希望匹配程度能高一些,能夠理解我們的意圖,舉幾個中文例子: - 南京市長江大橋,有一些分詞器得到的結果:南京/市長/江大橋,完全不是我們想的結果,我們希望是:南京/南京市/長江/大橋/長江大橋。
長春市長春街長春藥店,分詞分得不對,搞成這樣:長春/市長/春/街/長/春藥/店,結果就很尷尬了。
全文搜尋方面,最基本的步驟是先分詞,再索引,然後搜尋時進行匹配,英文相對好辦,中文方面有相像不到的難點要去克服。
小結
本篇介紹搜尋的基礎知識,闡述搜尋結果的含義,多索引搜尋和輕量搜尋的基本使用,最後對比了一下精確搜尋與全文搜尋,以及著名的中文分詞大坑,謝謝。
專注Java高併發、分散式架構,更多技術乾貨分享與心得,請關注公眾號:Java架構社群

相關推薦
Elasticsearch系列---初識搜尋
概要 本篇主要介紹搜尋的報文結構含義、搜尋超時時間的處理過程,提及了一下多索引搜尋和輕量搜尋,最後將精確搜尋與全文搜尋做了簡單的對比。 空搜尋 搜尋API最簡單的形式是不指定索引和型別的空搜尋,它將返回叢集下所有索引的所有文件(預設顯示10條): GET /_search 響應的結果示例(有篩選,只取了一條d
Elasticsearch系列---初識mapping
概要 本篇簡單介紹一下field資料型別mapping的相關知識。 mapping是什麼? 前面幾篇的實戰案例,我們向Elasticsearch索引資料時,只是簡單地把JSON文字放在請求體裡,至於JSON裡的field型別,儲存到ES裡是什麼型別,中間是怎麼做的對映,這個對映過程,就是mapping要解決的
Elasticsearch系列---實戰搜尋語法
概要 本篇介紹Query DSL的語法案例,查詢語句的除錯,以及排序的相關內容。 基本語法 空查詢 最簡單的搜尋命令,不指定索引和型別的空搜尋,它將返回叢集下所有索引的所有文件(預設顯示10條): GET /_search {} 搜尋多個索引 GET /index1,index2/_doc/_search {
elasticsearch系列四:搜尋詳解(搜尋API、Query DSL)
{ "took": 60, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": 1000, "m
Elasticsearch系列---搜尋執行過程及scroll遊標查詢
概要 本篇主要介紹一下分散式環境中搜索的兩階段執行過程。 兩階段搜尋過程 回顧我們之前的CRUD操作,因為只對單個文件進行處理,文件的唯一性很容易確定,並且很容易知道是此文件在哪個node,哪個shard中。 但搜尋比CRUD複雜,符合搜尋條件的文件,可能散落在各個node、各個shard中,我們需要找到匹配
Elasticsearch系列---結構化搜尋
概要 結構化搜尋針對日期、時間、數字等結構化資料的搜尋,它們有自己的格式,我們可以對它們進行範圍,比較大小等邏輯操作,這些邏輯操作得到的結果非黑即白,要麼符合條件在結果集裡,要麼不符合條件在結果集之外,沒有那種相似的概念。 前言 結構化搜尋將會有大量的搜尋例項,我們將"音樂APP"作為主要的案例背景,去開發一
Elasticsearch系列---深入全文搜尋
概要 本篇介紹怎樣在全文欄位中搜索到最相關的文件,包含手動控制搜尋的精準度,搜尋條件權重控制。 手動控制搜尋的精準度 搜尋的兩個重要維度:相關性(Relevance)和分析(Analysis)。 相關性是評價查詢條件與結果的相關程度,並對相關程度進行排序,一般使用TF/IDF方法。 分析是指將索引文件與查詢條
Elasticsearch系列---多欄位搜尋
### 概要 本篇介紹一下multi_match的best_fields、most_fields和cross_fields三種語法的場景和簡單示例。 ### 最佳欄位 bool查詢採取"more-matches-is-better"匹配越多分越高的方式,所以每條match語句的評分結果會被加在一起,從而
elasticsearch系列(四)部署
linux .tar.gz ast 官方 hup bin arc 分享 quest linux環境 centOS6.8 本文采用tar包的方式部署es 準備jdk8的環境 5.4.0的es依賴jdk8及以上版本 下載linux版的jdk jdk-8u121-linux-x6
搜索引擎ElasticSearch系列(四): ElasticSearch2.4.4 sql插件安裝
china code als 插件 技術分享 -s fun nlp 4.0 一:ElasticSearch sql插件簡介 With this plugin you can query elasticsearch using familiar SQL syntax.
elasticsearch系列(六)備份
indices stat 必須 tor 信息 操作 accepted gui 配置 快照備份 1.創建文件倉庫 1.1 在$ELASTICSEARCH_HOME/config/elasticsearch.yaml中增加配置 #這個路徑elasticsearch必須有權限訪問
elasticsearch系列(七)java定義score
集群 scrip image search 支持 name dsr 計算方法 dynamic 概述 ES支持groovy 和 java兩種語言自定義score的計算方法,groovy甚至可以嵌套在請求的參數中,有點厲害,不過不在本篇討論範圍。 如何用自定義的java代碼來定
【ElasticSearch篇】--ElasticSearch從初識到安裝和應用
sequence ria wan shard 主機 single when please lock 一、前述 ElasticSearch是一個基於Lucene的搜索服務器。它提供了一個分布式多用戶能力的全文搜索引擎,基於RESTful web接口,在企業中全文搜索時,特別常
Linux系列 初識ngnix——ngnix安裝及配置表內容詳解、讓nginx支持並顯示國家及其城市
ngnix安裝 nginx配置表內容Nginx(engine x)是一個高性能的HTTP和反向代理服務器,也是一個IMAP/POP3/SMTP服務器。功能:1.高性能的HTTP Server,解決c10k的問題2.高性能的反向代理服務器,給網站加速3.做為LB集群的前端一個負載均衡器nginx的優勢 IO
ElasticSearch 系列隨筆
www 錯誤 問題 day last del home AI 插入 1.ElasticSearch 常用設置 2.ElasticSearch 從2.2升級到6.2.4後在Kibana註意問題 (Validation Failed: 1: an id must be pro
elasticsearch系列一:elasticsearch(ES簡介、安裝&配置、集成Ikanalyzer)
ins 表示 吞吐量 search 工作 use art tcp傳輸 .net 一、ES簡介 1. ES是什麽? Elasticsearch 是一個開源的搜索引擎,建立在全文搜索引擎庫 Apache Lucene 基礎之上 用 Java 編寫的,它的內部使用 Lucene
elasticsearch系列三:索引詳解(分詞器、文檔管理、路由詳解)
ces com dex 合並 pda ams 最新 case dbi 一、分詞器 1. 認識分詞器 1.1 Analyzer 分析器 在ES中一個Analyzer 由下面三種組件組合而成: character filter :字符過濾器,對文本進行字符過濾處理,
elasticsearch系列八:ES 集群管理(集群規劃、集群搭建、集群管理)
記得 文件 如果 cse init host 網絡隔離 也有 沒有 一、集群規劃 搭建一個集群我們需要考慮如下幾個問題: 1. 我們需要多大規模的集群? 2. 集群中的節點角色如何分配? 3. 如何避免腦裂問題? 4. 索引應該設置多少個分片? 5. 分片應該設置幾個副本?
mybatis 解讀系列-初識
工作 style 檢索 java對象 有一個 cto build resources 模型 mybaits簡單介紹 MyBatis 是支持普通 SQL查詢,存儲過程和高級映射的優秀持久層框架。 MyBatis 消除了幾乎所有的JDBC代碼和參數的手工設置以
ElasticSearch - 輸入即搜尋 edge n-gram
在此之前,ES所有的查詢都是針對整個詞進行操作,也就是說倒排索引存了hello這個詞,一定得輸入hello才能找到這個詞,輸入 h 或是 he 都找不到倒排索引中的hello 然而在現實情況下,使用者已經漸漸習慣在輸入完查詢內容之前,就能為他們展現搜尋結果,這就是所謂的即