
Elasticsearch系列---搜尋執行過程及scroll遊標查詢
概要
本篇主要介紹一下分散式環境中搜索的兩階段執行過程。
兩階段搜尋過程
回顧我們之前的CRUD操作,因為只對單個文件進行處理,文件的唯一性很容易確定,並且很容易知道是此文件在哪個node,哪個shard中。
但搜尋比CRUD複雜,符合搜尋條件的文件,可能散落在各個node、各個shard中,我們需要找到匹配的文件,並且把從各個node,各個shard返回的結果進行彙總、排序,組成一個最終的結果排序列表,才算完成一個搜尋過程。我們將按兩階段的方式對這個過程進行講解。
查詢階段
假定我們的ES叢集有三個node,number_of_primary_shards為3,replica shard為1,我們執行一個這樣的查詢請求:
GET /music/children/_search
{
"from": 980,
"size": 20
}查詢階段的過程示意圖如下:
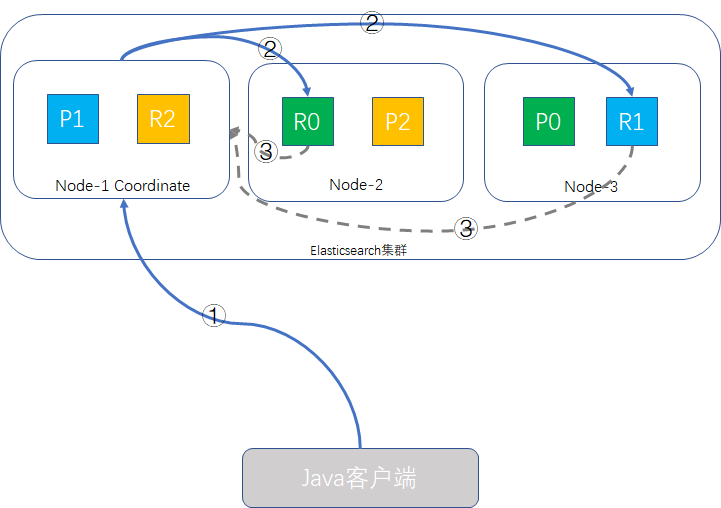
- Java客戶端發起查詢請求,接受請求的node-1成為Coordinate Node(協調者),該node會建立一個priority queue,長度為from + size即1000。
- Coordinate Node將請求分發到所有的primary shard或replica shard中,每個shard在本地建立一個同樣大小的priority queue,長度也為from + size,用於儲存該shard執行查詢的結果。
- 每個shard將各自priority queue的元素返回給Coordinate Node,元素內只包含文件的ID和排序值(如_score),Coordinate Node將合併所有的元素到自己的priority queue中,並完成排序動作,最終根據from、size值對結果進行擷取。
補充說明:
- 哪個node接收客戶端的請求,該node就會成為Coordinate Node。
- Coordinate Node轉發請求時,會根據負載均衡演算法分配到同一分片的primary shard或replica shard上,為什麼說replica值設定得大一些可以增加系統吞吐量的原理就在這裡,Coordinate Node的查詢請求負載均衡演算法會輪詢所有的可用shard,併發場景時就會有更多的硬體資源(CPU、記憶體,IO)會參與其中,系統整體的吞吐量就能提升。
- 此查詢過程Coordinate Node得到是輕量級的元素資訊,只包含文件ID和_score這些資訊,這樣可以減輕網路負載,因為分頁過程中,大部分的資料是會丟棄掉的。
取回階段
在完成了查詢階段後,此時Coordinate Node已經得到查詢的列表,但列表內的元素只有文件ID和_score資訊,並無實際的_source內容,取回階段就是根據文件ID,取到完整的文件物件的過程。如下圖所示:

- Coordinate Node根據from、size資訊擷取要取回文件的ID,如{"from": 980, "size": 20},則取第981到第1000這20條資料,其餘丟棄,from/size為空則預設取前10條,向其他shard發出mget請求。
- shard接收到請求後,根據_source引數(可選)載入文件資訊,返回給Coordinate Node。
- 一旦所有的shard都返回了結果,Coordinate Node將結果返回給客戶端。
前面幾篇有提到deep paging的問題,我們在這裡又複習一遍,使用from和size進行分頁時,傳遞資訊給Coordinate Node的每個shard,都建立了一個from + size長度的佇列,並且Coordinate Node需要對所有傳過來的資料進行排序,工作量為number_of_shards * (from + size),然後從裡面挑出size數量的文件,如果from值特別大,那麼會帶來極大的硬體資源浪費,鑑於此原因,強烈建議不要使用深分頁。
不過深分頁操作很少符合人的行為,翻幾頁還看不到想要的結果,人的第一反應是換一個搜尋條件,只有機器人或爬蟲才這麼不知疲倦地一直翻頁直到伺服器崩潰。
preference設定
查詢時使用preference引數,可以影響哪些shard可以用來執行搜尋操作,6.1.0版本後,許多引數值已宣告為棄用,我們挑幾個目前還在使用的簡單介紹一下:
- _only_local:只搜尋當前node中的shard
- _local:優先搜尋當前node中的shard,搜不到再去其他的shard
- _prefer_nodes:abc,xyz:優先從指定的abc/xyz節點上搜索,如果兩個節點都有存在資料的shard,隨機從裡面挑一個節點執行搜尋
- _only_nodes:abc,xyz,...:只在符合通配abc、xyz名稱的節點上搜索,如果多個節點都有存在資料的shard,隨機從裡面挑一個節點執行搜尋
- _shards:2,3:指定shard進行搜尋,這個條件如與其他條件搭配使用,此條件要寫在前面,如_shards:2,3|_local
- 自定義字串:一般用sessionid或userid
bouncing results問題
假如兩個文件有相同的欄位值,並且時間戳也一樣,如果按時間戳欄位來排序,由於請求是在所有可用的shard上輪詢的,可能存在一種情況:這兩個文件記錄在不同的shard之間儲存的順序不相同。結果就是同一個條件的查詢,如果執行多次,分配在primary shard得到的是一種順序,分配在replica shard又是另一個順序,這個就是所謂的bouncing results問題。
如何避免:讓同一個使用者始終使用同一個shard,就可以避免這種問題,常見的做法是preference設定為sessionid或userid,如:
GET /music/children/_search?preference=10086
{
"from": 980,
"size": 20
}超時問題
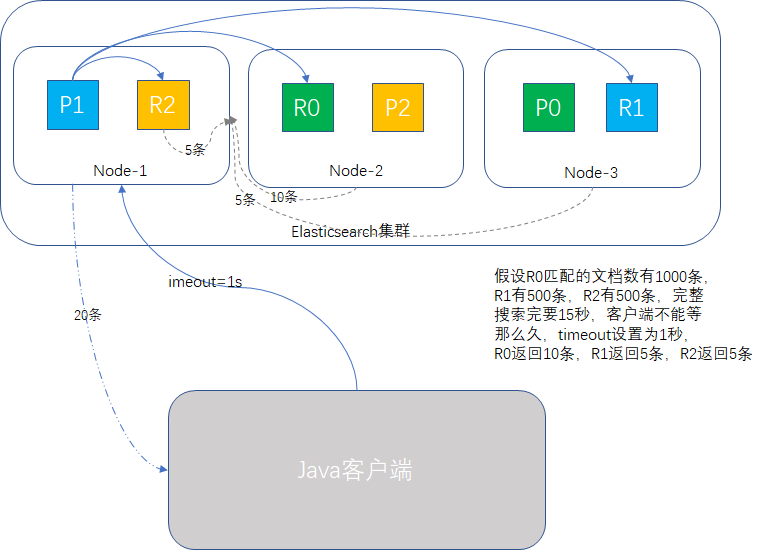
我們回顧查詢階段和取回階段,必須所有的操作都完成了,才給客戶端返回結果,如果中途有shard在執行特別重的任務,導致查詢很慢怎麼辦?會拖慢整個叢集嗎?
如果是高併發場景,那極有可能,因為某一個節點慢,整個查詢請求堆積,拖死叢集都有可能。
為了防止這一情況,我們使用timeout引數,告訴shard允許處理資料的最大時間,時間一到,執行關門動作,能有多少資料返回多少資料,剩下的不要了,這樣可以確保叢集是穩定執行的,如下圖所示:
routing
在設計大規模資料搜尋時,我們為了實現資料集中性,索引時會按一定規則將資料進行儲存,比如訂單資料,我們會按userid為route key,每個userid的訂單資料,都放在同一個shard上,既然儲存時使用了route key,那麼搜尋時同樣使用route key,可以讓查詢只搜尋相關的shard,如:
GET /music/children/_search?routing=10086
{
"from": 980,
"size": 20
}這樣由於精準到具體的shard,可以極大的縮小搜尋範圍,資料量越大,效果越明顯。
搜尋型別
預設的搜尋型別是query_then_fetch,我們還可以選擇dfs_query_then_fetch,這個有預查詢階段,可以從所有相關shard中獲取詞頻來計算全域性詞頻,可以提升revelance sort精準度。
scroll遊標查詢
如果我們要把大批量的資料從ES叢集中取出,用來執行一些計算,一次性取完肯定不合適,IO壓力過大,效能容易出問題,分頁查詢又容易造成deep paging的問題。一般推薦使用scroll查詢,一批一批的查,直到所有資料都查詢完。
原理
- scroll查詢會先做查詢初始化,然後再批量地拉取結果,有點像資料庫的cursor。
- scroll查詢會取某個時間點的快照資料,查詢初始化後索引上的資料發生了變化,快照資料還是原來的,有點像資料庫的索引檢視。
- scroll查詢用欄位_doc排序,去掉了全域性排序,效能比較高。
- scroll查詢要設定過期時間,每次搜尋在這個時間內完成即可。
示例
我們假定每次取10條資料,時間視窗為1秒
請求如下:
GET /music/children/_search?scroll=1s
{
"size": 10
}響應如下(結果有刪減):
{
"_scroll_id": "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAABJQFkExczF1dXM3VHB1RFNpVDR4RkxPb1EAAAAAAAASUhZBMXMxdXVzN1RwdURTaVQ0eEZMT29RAAAAAAAAElMWQTFzMXV1czdUcHVEU2lUNHhGTE9vUQAAAAAAABJUFkExczF1dXM3VHB1RFNpVDR4RkxPb1EAAAAAAAASURZBMXMxdXVzN1RwdURTaVQ0eEZMT29R",
"took": 2,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 4,
"max_score": 1,
"hits": [
{
"_index": "music",
"_type": "children",
"_id": "2",
"_score": 1,
"_source": {
"name": "wake me, shark me",
"content": "don't let me sleep too late, gonna get up brightly early in the morning",
"language": "english",
"length": "55",
"likes": 0,
"author": "John Smith"
}
}
]
}
}注意那個scroll_id,下次再查詢時,只要帶上這個就行了
GET /_search/scroll
{
"scroll": "1s",
"scroll_id" : "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAABJQFkExczF1dXM3VHB1RFNpVDR4RkxPb1EAAAAAAAASUhZBMXMxdXVzN1RwdURTaVQ0eEZMT29RAAAAAAAAElMWQTFzMXV1czdUcHVEU2lUNHhGTE9vUQAAAAAAABJUFkExczF1dXM3VHB1RFNpVDR4RkxPb1EAAAAAAAASURZBMXMxdXVzN1RwdURTaVQ0eEZMT29R"
}
每次的查詢,都把最新的scroll_id帶上,直到資料查詢完成為止。
scroll查詢看起來像分頁,但使用場景不一樣,分頁主要是按頁展示資料,主要受眾是人,scroll一批一批的獲取資料,主要受眾一般是資料分析的系統,是給系統用的。
效能也不同,前面我們瞭解後,分頁查詢隨著頁數的加深,壓力越來越大,而scroll是基於_doc排序的資料處理,特別適用於大批量資料的獲取分析。
小結
本篇詳細介紹了查詢的兩階段過程,以及能夠影響查詢行為的一些引數設定,歷經多個版本迭代,有些preference引數已經不用了,瞭解一下就行,另外介紹了bouncing results產生的原理及規避辦法,最後介紹了一下大批量資料查詢利器scroll的簡單用法。
專注Java高併發、分散式架構,更多技術乾貨分享與心得,請關注公眾號:Java架構社群
可以掃左邊二維碼新增好友,邀請你加入Java架構社群微信群共同探討技術

相關推薦
Elasticsearch系列---搜尋執行過程及scroll遊標查詢
概要 本篇主要介紹一下分散式環境中搜索的兩階段執行過程。 兩階段搜尋過程 回顧我們之前的CRUD操作,因為只對單個文件進行處理,文件的唯一性很容易確定,並且很容易知道是此文件在哪個node,哪個shard中。 但搜尋比CRUD複雜,符合搜尋條件的文件,可能散落在各個node、各個shard中,我們需要找到匹配
Mysql查詢語句執行過程及執行原理
Mysql查詢語句執行原理 資料庫查詢語句如何執行? DML語句首先進行語法分析,對使用sql表示的查詢進行語法分析,生成查詢語法分析樹。 語義檢查:檢查sql中所涉及的物件以及是否在資料庫中存在,使用者是否具有操作許可權等 檢視轉換:將語法分析樹轉換成關係代數表示式
ping命令執行過程及返回資訊分析
Ping命令幕後過程及其返回資訊分析 “Ping”的幕後過程 我們以下面一個網路為例:有A、B、C、D四臺機子,一臺路由RA,子網掩碼均為255.255.255.0,預設路由為192.16
SpringMVC執行過程及涉及到的類解析
springmvc框架執行結構圖: 文字描述: 1.瀏覽器發起一個請求:http://localhost:80/ 2.先去指定伺服器上查詢專案 3.載入該專案的web.xml(DispatcherServlet前端控制器) 4.Dispat
python隨筆系列--import執行過程簡單論證
str http 分享圖片 驗證 npr log pack yun package 結論:模塊在一個python解釋器(一次生命周期)中,一個模塊只被引入一次驗證過程 ins01 site-packages]# echo ‘print(11111)‘ > kai.py
動圖+原始碼,演示Java中常用資料結構執行過程及原理
最近在整理資料結構方面的知識, 系統化看了下Java中常用資料結構, 突發奇想用動畫來繪製資料流轉過程. 主要基於jdk8, 可能會有些特性與jdk7之前不相同, 例如LinkedList LinkedHashMap中的雙向列表不再是迴環的. HashMap中的單鏈表是尾插, 而不是頭插入等等, 後文不再贅敘
Java程式執行過程及記憶體機制
本講將介紹Java程式碼是如何一步步執行起來的,其中涉及的編譯器,類載入器,位元組碼校驗器,直譯器和JIT編譯器在整個過程中是發揮著怎樣的作用。此外還會介紹Java程式所佔用的記憶體是被如何管理的:堆、棧和方法區都各自負責儲存哪些內容。最後用一小塊程式碼示例來幫助理解Java程式執行時記憶體的變化。 ##
MySQL語句執行優化及分頁查詢優化,分庫分表(一)
下面是關於在使用SQL時,我們儘量應該遵守的規則,這樣可以避免寫出執行效率低的SQL 1、當只需要一條資料時,使用limit 1 在我們執行查詢時,如果添加了 Limit 1,那麼在查詢的時候,在篩選到一條資料時就會停止繼續查詢,但是如果沒有新增limit 1即
java使用多執行緒及分頁查詢資料量很大的資料
主要的思路就是: 先通過count查出結果集的總條數,設定每個執行緒分頁查詢的條數,通過總條數和單次條數得到執行緒數量,通過改變limit的下標實現分批查詢。 呼叫方法: import org.springframework.beans.factory.annota
SqlServer遊標、儲存過程及資料塊執行
資料塊遊標事例如下: begin declare @item_code varchar(32)--定義變數 declare @item_name varchar(32) declare @invest_money_sum float --定義遊標 declare
Servlet的生命周期及執行過程
生命 tro font 接收 -m 方法 dog 服務器 一次 Servlet生命周期分為實例化、初始化、響應請求調用service()方法、消亡階段調用destroy()方法。 執行過程如下: 1)當瀏覽器發送一個請求地址,tomcat會接收這個請求 2)tomcat會讀
多線程系列七:記錄一次學習項目性能優化的過程及心得
安全問題 ota except dex 等等 exception family print 單個 一、項目背景和問題 有一個自適應的考試學習系統,對學員的學習要求經常考試進行檢查,學員的成績出來以後,老師會要求系統根據每個學員的考卷上錯誤的題目從容量為10萬左右的題庫中抽取
(轉)Linux 中/etc/profile、~/.bash_profile 環境變量配置及執行過程
行修改 你在 關系 轉載 登錄用戶 後者 nbsp inux 第一個 環境變量是和Shell緊密相關的,用戶登錄系統後就啟動了一個Shell。對於Linux來說一般是bash,但也可以重新設定或切換到其它的 Shell。對於UNIX,可能是CShelll。環境變量是通過Sh
react-native-cli執行專案及打包apk失敗的解決過程
剛開始學習react native,第一步自然是搭建好開發環境,node及jdk本身就有,Python2、Android studio以及Android sdk的安裝倒是沒什麼大問題,按照官網的教程做就行了,還有Android studio我目前理解的是其實主要作用就是配置對應版本的安卓模擬器或者是安裝sdk
Lvs-nat模式實現負載均衡的配置命令及執行過程
一、實驗環境 三臺伺服器,一臺作為 director,兩臺作為 real server,director 有一個外網網絡卡(10.0.172.190) 和一個內網ip(192.168.0.10),兩個 real server 上只有內網 ip (192.168.0.11) 和 (192.168.
Geomesa-accumulo安裝部署過程及執行測試例項
一、前期準備工作: 1、基礎環境JDK安裝配置 (下載對應JDK包並進行環境變數配置),使用java -version檢視如下顯示,jdk環境配置成功; 2、基礎依賴環境Hadoop及zookeeper安裝配置成功並需要啟動(可參照hadoop叢集環境及zookeeper環境配置說明文
(轉)Linux 中/etc/profile、~/.bash_profile 環境變數配置及執行過程
環境變數是和Shell緊密相關的,使用者登入系統後就啟動了一個Shell。對於Linux來說一般是bash,但也可以重新設定或切換到其它的 Shell。對於UNIX,可能是CShelll。環境變數是通過Shell命令來設定的,設定好的環境變數又可以被所有當前使用者所執行的程式所使用。對於bash這個Shell
MapReduce的原理及執行過程
MapReduce簡介 1.MapReduce是一種分散式計算模型,是Google提出的,主要用於搜尋領域,解決海量資料的計算問題。 2.MR有兩個階段組成:Map和Reduce,使用者只需實現map()和reduce()兩個函式,即可實現分散式計算。 MapReduce執行流程
elasticsearch 筆記十七:基於scroll技術滾動搜尋大量的資料
如果一次性要查出來比如10萬條資料,那麼效能會很差,此時一般會採取用scoll滾動查詢,一批一批的查,直到所有資料都查詢完處理完。使用scoll滾動搜尋,可以先搜尋一批資料,然後下次再搜尋一批資料,以此類推,直到搜尋出全部的資料來 scol
MapReduce的執行原理 MapReduce的原理及執行過程 Combiner
MapReduce的原理及執行過程 MapReduce簡介 MapReduce是一種分散式計算模型,是Google提出的,主要用於搜尋領域,解決海量資料的計算問題。 MR有兩個階段組成:Map和Reduce,使用者只需實現map()和reduce(