
分庫分表之第三篇
分庫分表之第三篇
- 3. Sharding-JDBC執行原理
- 3.1 基本概念
- 3.2. SQL解析
- 3.3.SQL路由
- 3.4. SQL改寫
- 3.6.結果歸併
- 3.7 總結
3. Sharding-JDBC執行原理
3.1 基本概念
在瞭解Sharding-JDBC的執行原理前,需要了解以下概念 :
邏輯表
水平拆分的資料表的總稱。例 :訂單資料表根據主鍵尾數拆分為1-張表,分別是t_order_0、t_order_1到t_order_9,他們的邏輯表名為t_order。
真實表
在分片的資料庫中真實存在的物理表。即上個例項中的t_order_0到t_order_9。
資料節點
資料分片的最小物理單元。由資料來源名稱和資料表組成,例如 :ds_0.t_order_0。
繫結表
指分片規則一致的主表和子表。例如 :t_order表和t_order_item表,均按照order_id分片,繫結表之間的分割槽鍵完全相同,則此兩張表互為繫結表關係。繫結表之間的多表關聯查詢不會出現笛卡爾積關聯,關聯查詢效率將大大提升。舉例說明,如果SQL為 :
SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
在不配置繫結表關係時,假設分片鍵order_id將數值10路由至第0片,將數值11路由至第1片,那麼路由後的SQL應該為4條,它們呈現為笛卡爾積 :
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11); SELECT i.* FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11); SELECT i.* FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11); SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
在配置繫結表關係後,路由的SQL應該為2條 :
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in
(10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in
(10, 11);
廣播表
指所有的分片資料來源中都存在的表,表結構和表中的資料在每個資料庫中均完全一致。適用於資料量不大且需要與海量資料的表進行關聯查詢的場景,例如 :字典表。
分片鍵
用於分片的資料庫欄位,是將資料庫(表)水平拆分的關鍵欄位。例如 :將訂單表中的訂單主鍵的尾數取模分片,則訂單主鍵為分片欄位。SQL中如果無分片欄位,將執行全路由,效能較差。除了對單分片欄位的支援,Sharding-JDBC也支援根據多個欄位進行分片。
分片演算法
通過分片演算法將資料分片,支援通過=、BETWZEEN和IN分片。分片演算法需要應用方開發者自行實現,可實現的靈活度非常高。包括 :精確分片演算法、範圍分片演算法、複合分片演算法等。例如 :where order_id = ?將採用精確分片演算法,where order_id in (?,?,?)將採用精確分片演算法,where order_id BETWEEN ?and ?將採用範圍分片演算法,複合分片演算法用於分片鍵有多個複雜情況。
分片策略
包含分片鍵和分片演算法,由於分片演算法的獨立性,將其獨立抽離。真正可用於分片操作的是分片鍵 + 分片演算法,也就是分片策略。內建的分片策略大致可分為尾數取模、雜湊、範圍、標籤、時間等。由使用者方配置的分片策略則更加靈活,常用的使用行表示式配置分片策略,它採用Groovy表示式表示 :如 :t_user_$->{u_id % 8}表示t_user表根據u_id摸8,而分成8張表,表名稱為t_user_0到t_user_7。
自增主鍵生成策略
通過在客戶端生成自增主鍵替換以資料庫原生自增主鍵的方式,做到分散式主鍵無重複。
3.2. SQL解析
當Sharding-JDBC接受到一條SQL語句時,會陸續執行SQL解析 =》查詢優化 =》SQL路由 =》SQL改寫 =》結果歸併,最終返回執行結果。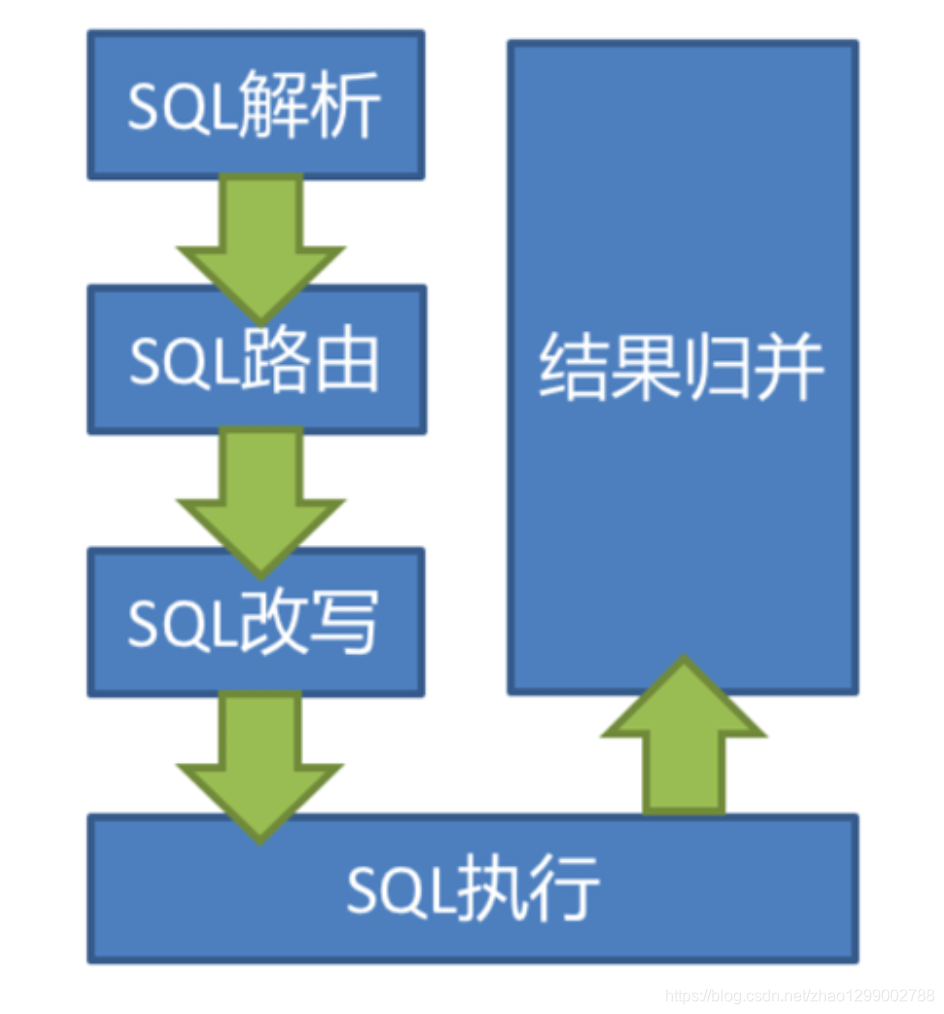
SQL解析過程分為詞法解析和語法解析。詞法解析器用於將SQL拆解為不可再分的院子符號,稱為Token。並根據不同資料庫方言所提供的字典,將其歸類為關鍵字、表示式、字面量和操作符。再使用語法解析器將SQL轉換為抽象語法樹。
例如,以下SQL:
SELECT id, name FROM t_user WHERE status = 'ACTIVE' AND age > 18
解析之後的為抽象語法樹見下圖 :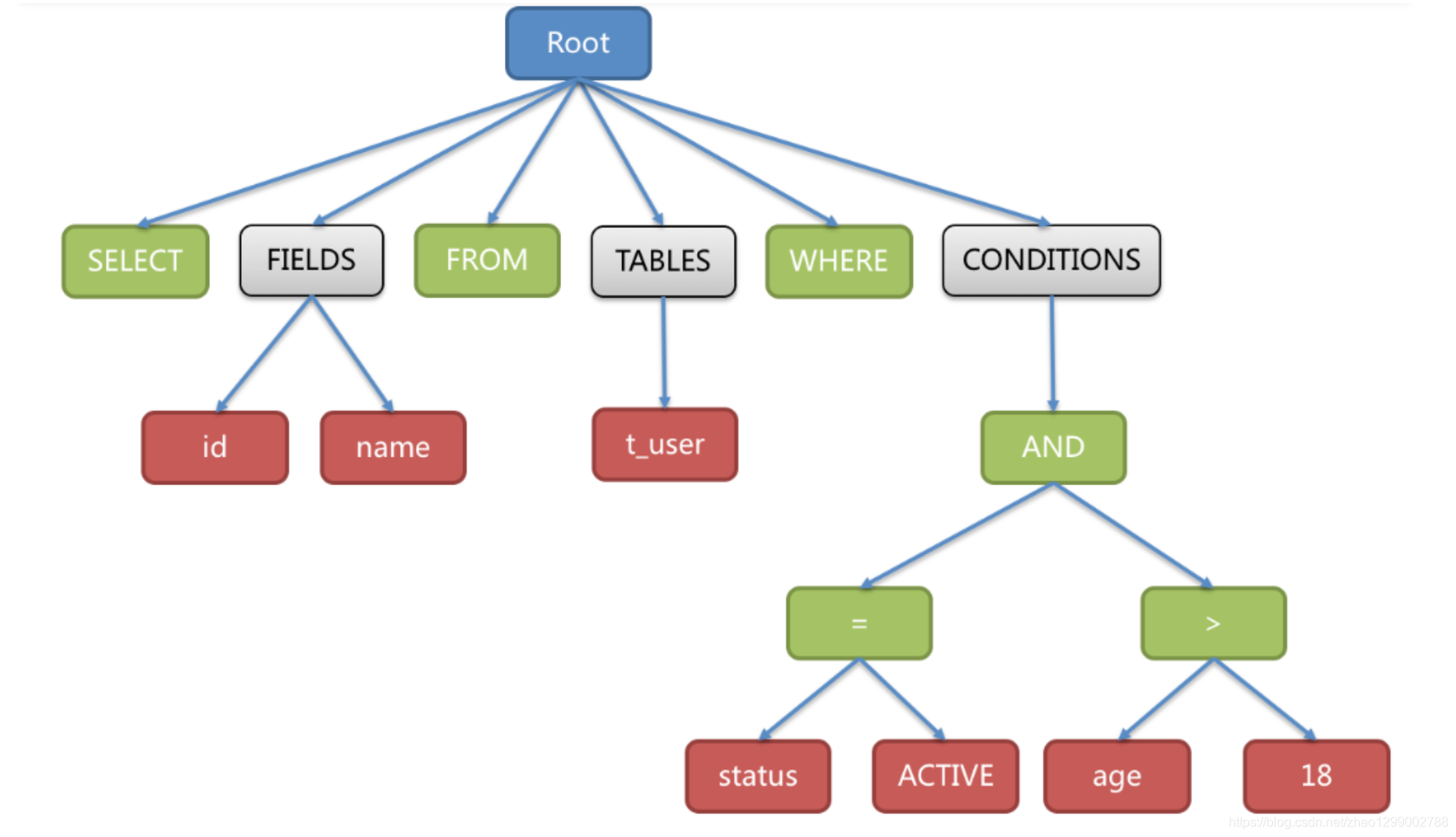
為了便於理解,抽象語法樹中的關鍵字的Token用綠色表示,變數的Token用紅色表示,灰色表示需要進一步拆分。
最後,通過對抽象語法樹的遍歷去提煉分片所需的上下文,並標記有可能需要SQL改寫(後邊介紹)的位置。供分片使用的解析上下文包含查詢選擇項(Select Items)、表資訊(Table)、分片條件(Sharding Condition)、自增主鍵資訊(Auto increment Primary Key)、排序資訊(Order By)、分組資訊(Group By)以及分頁資訊(Limit、Rownum、Top)。
3.3.SQL路由
SQL路由就是把針對邏輯表的資料操作對映到對資料結點操作的過程。
根據解析上下文匹配資料庫和表的分片策略,並生成路由路徑。對於攜帶分片鍵的SQL,根據分片鍵操作符不同可以劃分為單片路由(分片鍵的操作符是等號)、多片路由(分片鍵的操作符是IN)和範圍路由(分片鍵的操作符是BETWEEN),不攜帶分片鍵的SQL則採用廣播路由。根據分片鍵進行路由的場景可分為直接路由、標準路由、笛卡爾積路由等。
標準路由
標準路由是Sharding-JDBC最為推薦使用的分片方式,它的使用範圍是不包含關聯查詢或僅包含繫結表之間關聯查詢的SQL。當分片運算子是等於號時,路由結果將落入單庫(表),當分片運算子是BETWEEN或IN時,則路由結果不一定落入唯一的庫(表),因此這條邏輯SQL最終可能被拆分為多條用於執行的真實SQL。舉例說明,如果按照order_id的奇數和偶數進行資料分片,一個單表查詢的SQL如下 :
SELECT * FROM t_order WHERE order_id IN (1, 2);
那麼路由的結果應為 :
SELECT * FROM t_order_0 WHERE order_id IN (1, 2);
SELECT * FROM t_order_1 WHERE order_id IN (1, 2);
繫結表的關聯查詢與單表查詢複雜度和效能相當。舉例說明,如果一個包含繫結表的關聯查詢的SQL如下 :
SELECT * FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
那麼路由的結果應為 :
SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
可以看到,SQL拆分的數目與單表是一致的。
笛卡爾路由
笛卡爾路由是最複雜的情況,它無法根據繫結表的關係定位分片規則,因此非繫結表之間的關聯查詢需要拆解為笛卡爾積組合執行。如果上個示例中的SQL並未配置繫結表關係,那麼路由的結果應為 :
SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
SELECT * FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
SELECT * FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
笛卡爾路由查詢效能較低,需謹慎使用。
全庫表路由
對於不攜帶分片鍵的SQL,則採用廣播路由的方式。根據SQL型別又可以劃分為全庫表路由、全庫路由、全例項路由、單播路由和阻斷路由這5種類型。其中全庫表路由用於處理對資料庫中與其邏輯表相關的所有真實表的操作,主要包括不帶分片鍵的DQL(資料查詢)和DML(資料操縱),以及DDL(資料定義)等。例如 :
SELECT * FROM t_order WHERE good_prority IN (1, 10);
則會遍歷所有資料庫中的所有表,逐一匹配邏輯表和真實表名,能夠匹配得上則執行。路由後成為
SELECT * FROM t_order_0 WHERE good_prority IN (1, 10);
SELECT * FROM t_order_1 WHERE good_prority IN (1, 10);
SELECT * FROM t_order_2 WHERE good_prority IN (1, 10);
SELECT * FROM t_order_3 WHERE good_prority IN (1, 10);
3.4. SQL改寫
工程師面向邏輯表書寫的SQL,並不能夠直接在真實的資料庫中執行,SQL改寫用於將邏輯SQL改寫為在真實資料庫中可以正確執行的SQL。
如一個簡單的例子,若邏輯SQL為 :
SELECT order_id FROM t_order WHERE order_id=1;
假設該SQL配置分片鍵order_id,並且order_id=1的情況,將路由至分片表1。那麼改寫之後的SQL應該為 :
SELECT order_id FROM t_order_1 WHERE order_id=1;
再比如,Sharding-JDBC需要在結果歸併時獲取相應資料,但該資料並未能通過查詢的SQL返回。這種情況主要是針對GROUP BY和ORDER BY。結果歸併時,需要根據GROUP_BY和ORDER_BY的欄位項進行分組和排序,但如果原始SQL的選擇項中若並未包含分組項或排序項,則需要對原始SQL進行改寫。先看一下原始SQL中帶有結果歸併所需資訊的場景 :
SELECT order_id, user_id FROM t_order ORDER BY user_id;
由於user_id進行排序,在結果歸併中需要能夠獲取到user_id的資料,而上面的SQL是能夠獲取到user_id獲取的,因此無需補列。
如果選擇項中不包含結果歸併時所需的列,則需要進行補列,如以下SQL :
SELECT order_id FROM t_order ORDER BY user_id;
由於原始SQL中並不包含需要在結果歸併中需要獲取的user_id,因此需要對SQL進行補列改寫。補列之後的SQL
SELECT order_id, user_id AS ORDER_BY_DERIVED_0 FROM t_order ORDER BY user_id;
3.6.結果歸併
將從各個資料節點獲取的多資料結果集,組合成為一個結果集並正確的返回至請求客戶端,稱為結果歸併。
Sharding-JDBC支援的結果歸併從功能上可分為遍歷、排序、分組、分頁和聚合5種類型,它們是組合而非互斥的關係。
歸併引擎的整體結構劃分如下圖 。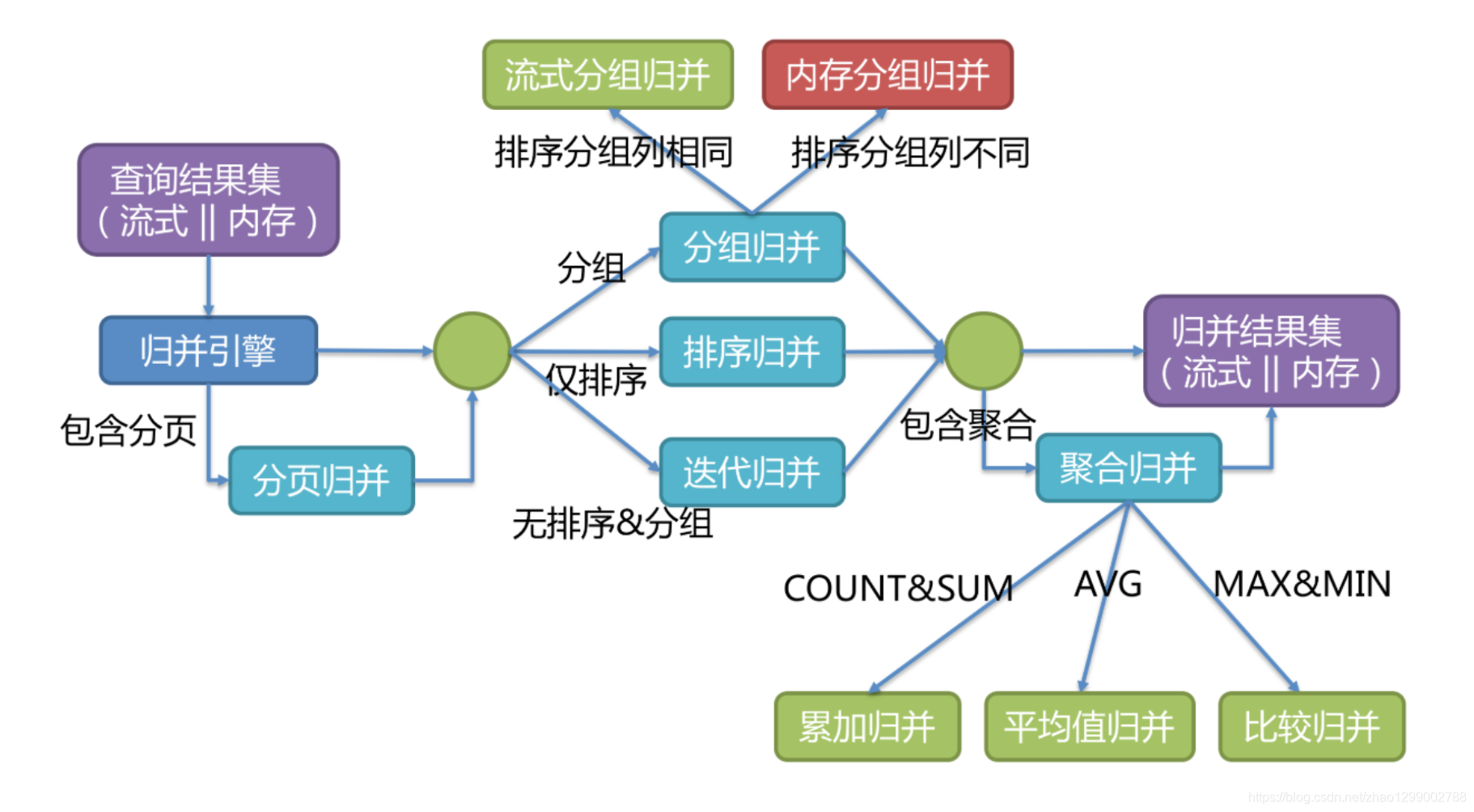
結果歸併從結構劃分可分為流式歸併、記憶體歸併和裝飾者歸併。流式歸併和記憶體歸併是互斥的,裝飾者歸併可以在流式歸併和記憶體歸併之上做進一步的處理。
記憶體歸併很容易理解,他是將所有分片結果集的資料都遍歷並存儲在記憶體中,再通過統一的分組、排序以及聚合等計算之後,再將其封裝成為逐條訪問的資料結果集返回。
流式歸併是指每一次從資料庫結果集中獲取到的資料,都能夠通過遊標逐條獲取的方式返回正確的單條資料,它與資料庫原生的返回結果集的方式最為契合。
下邊舉例說明排序歸併的過程,如下圖是一個通過分數進行排序的示例圖,它採用流式歸併方式。圖中展示列3張表返回的資料結果集,每個資料結果集已經根據分數排序完畢,但是3個數據結果集之間是無序的。將3個數據結果集的當前遊標指向的資料值進行排序,並放入優先順序佇列,t_score_0的第一個資料值最大,t_score_2的第一個資料值次之,t_score_1的第一個資料值最小,因此優先順序佇列根據t_score_0、t_score_2和t_score_1的方式排序佇列。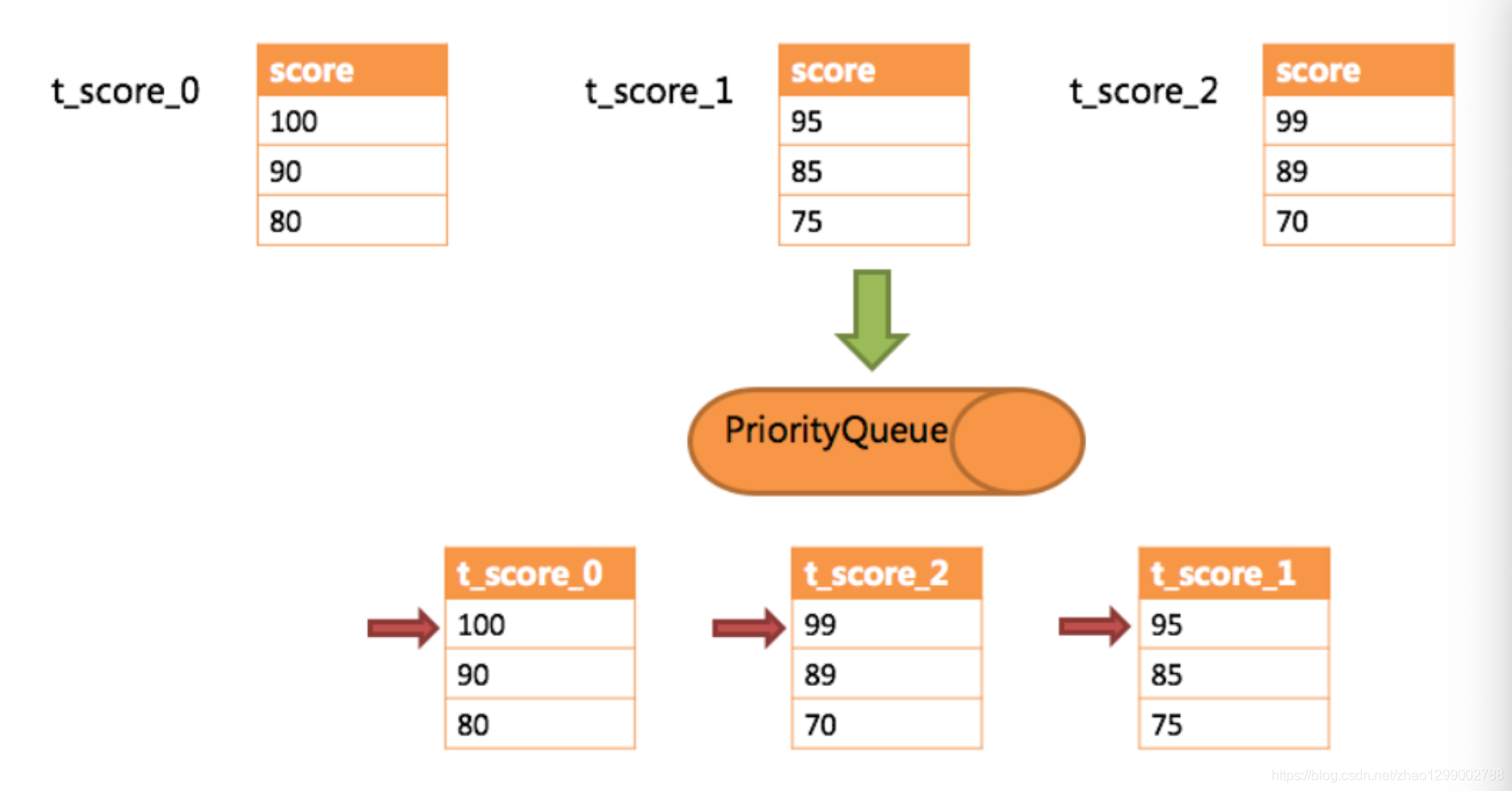
下圖則展現了進行next呼叫的時候,排序歸併是如何進行的。通過圖中我們可以看到,當進行第一次next呼叫時,排在佇列首位的t_score_0將會被彈出佇列,並且將當前遊標指向的資料值(也就是100)返回至查詢客戶端,並且將遊標下移一位之後,重新放入優先順序佇列。而優先順序佇列也會根據t_score_0的當前資料結果集指向遊標的資料值(這裡是90)進行排序,根據當前數值,t_score_0排列在佇列的最後一位。之前佇列中排名第二的t_score_2的資料結果集則自動排在佇列首位。
在進行第二次next時,只需要將目標排列在佇列首位的t_score_2彈出佇列,並且將其資料結果集遊標指向的值返回至客戶端,並下移遊標,繼續加入佇列排隊,以此類推。當一個結果集中已經沒有資料了,則無需再次加入佇列。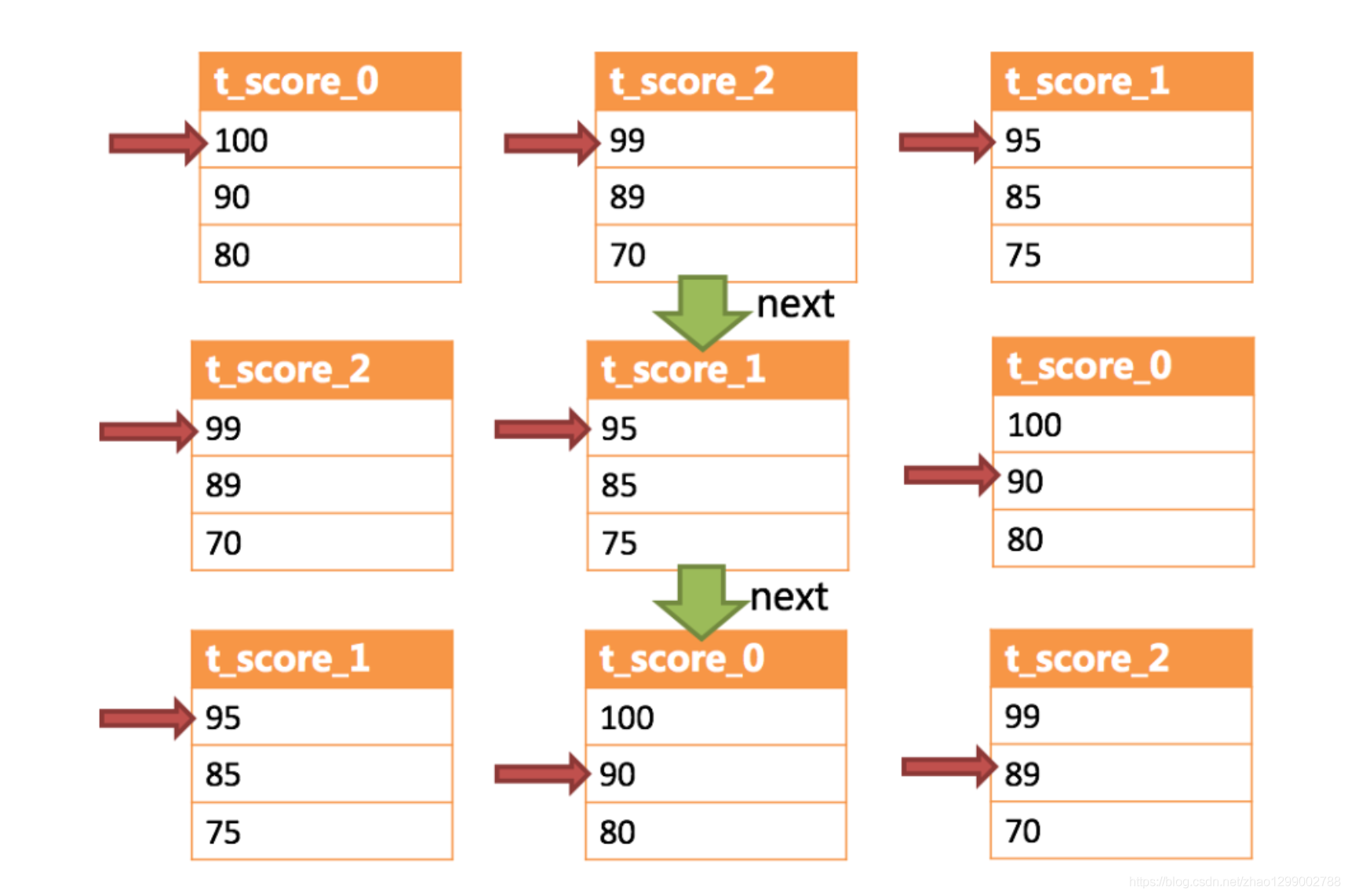
可以看到,對於每個資料結果集中的資料有序,而多資料結果集整體無序的情況下,Sharding-JDBC無需將所有的資料都載入至記憶體即可排序。它使用的是流式歸併的方式,每次next僅獲取唯一正確的一條資料,極大的節省了記憶體的消耗。
裝飾者歸併是對所有的結果集歸併進行統一的功能增強,比如歸併時需要聚合SUM前,在進行聚合計算前,都會通過記憶體歸併或流式歸併查詢出結果集。因此,聚合歸併是在之前介紹的歸併型別之上追加的歸併能力,即裝飾者模式。
3.7 總結
通過以上內容介紹,相信大家已經瞭解到Sharding-JDBC基礎概念、核心功能以及執行原理。
基礎概念 :邏輯表、真實表、資料節點、繫結表、廣播表、分片鍵、分片演算法、分片策略、主鍵生成策略
核心功能 :資料分片、讀寫分離
執行流程 :SQL解析 =》查詢優化 =》SQL路由 =》SQL改寫 =》SQL執行 =》結果歸併