
ElasticSearch實戰系列四: ElasticSearch理論知識介紹
前言
在前幾篇關於ElasticSearch的文章中,簡單的講了下有關ElasticSearch的一些使用,這篇文章講一下有關 ElasticSearch的一些理論知識以及自己的一些見解。
雖然本人是一個實戰派,不太喜歡講這些理論知識,因為這塊可以檢視官方文件,那裡會寫得非常詳細,但是在使用了ElasticSearch之後,發現有的知識點需要掌握一定的理論知識才能理解,對於初學者來說有的不好理解,因此寫下該篇文章,希望讀者在看完之後能夠有所幫助。
ElasticSearch 理論知識介紹
ElasticSearch是什麼
Elasticsearch 是一個基於JSON的分散式搜尋和分析引擎。它可以從RESTful Web服務介面訪問,並使用模式少JSON(JavaScript物件符號)文件來儲存資料。它是基於Java程式語言,這使Elasticsearch能夠在不同的平臺上執行。使使用者能夠以非常快的速度來搜尋非常大的資料量。
ElasticSearch可以做什麼
- 分散式的實時檔案儲存,每個欄位都被索引並可被搜尋
- 分散式的實時分析搜尋引擎
- 可以擴充套件到上百臺伺服器,處理PB級結構化或非結構化資料
Lucene是什麼
ApacheLucene將寫入索引的所有資訊組織成一種倒排索引(Inverted Index)的結構之中,該結構是種將詞項對映到文件的資料結構。其工作方式與傳統的關係資料庫不同,大致來說倒排索引是面向詞項而不是面向文件的。且Lucene索引之中還儲存了很多其他的資訊,如詞向量等等,每個Lucene都是由多個段構成的,每個段只會被建立一次但會被查詢多次,段一旦建立就不會再被修改。多個段會在段合併的階段合併在一起,何時合併由Lucene的內在機制決定,段合併後數量會變少,但是相應的段本身會變大。段合併的過程是非常消耗I/O的,且與之同時會有些不再使用的資訊被清理掉。在Lucene中,將資料轉化為倒排索引,將完整串轉化為可用於搜尋的詞項的過程叫做分析。文字分析由分析器(Analyzer)來執行,分析其由分詞器(Tokenizer),過濾器(Filter)和字元對映器(Character Mapper)組成,其各個功能顯而易見。
Elk架構
“ELK”是三個開源專案的首字母縮寫,這三個專案分別是:Elasticsearch、Logstash 和 Kibana。Elasticsearch 是一個搜尋和分析引擎。Logstash 是伺服器端資料處理管道,能夠同時從多個來源採集資料,轉換資料,然後將資料傳送到諸如 Elasticsearch 等“儲存庫”中。Kibana 則可以讓使用者在 Elasticsearch 中使用圖形和圖表對資料進行視覺化。
ElasticSearch名詞
叢集(cluster)
一個叢集由一個或多個共享相同的群集名稱的節點組成。每個群集有一個單獨的主節點,這是由程式自動選擇,如果當前主節點失敗,程式會自動選擇其他節點作為主節點。
節點(node)
一個節點屬於一個叢集。通常情況下一個伺服器有一個節點,但有時候為了測試方便,一臺伺服器也可以有多個節點。在啟動時,一個節點將使用廣播來發現具有相同群集名稱的現有群集,並將嘗試加入該群集。節點屬性根據elasticsearch.yml的一些配置來決定!其中master和datanode是必不可少的,其他的可以按照情況來進行新增!為了防止腦裂以及後續維護,建議將節點屬性分離!
elasticsearch.yml配置:
node.master: true 並且 node.data: true
這種組合表示這個節點即有成為主節點的資格,又儲存資料。
如果某個節點被選舉成為了真正的主節點,那麼他還要儲存資料,這樣對於這個節點的壓力就比較大了。ElasticSearch預設每個節點都是這樣的配置,在測試環境下這樣做沒問題。實際工作中建議不要這樣設定,因為這樣相當於主節點和資料節點的角色混合到一塊了。node.master: false 並且 node.data: true
這種組合表示這個節點沒有成為主節點的資格,也就不參與選舉,只會儲存資料。 這個節點我們稱為data(資料)節點。在叢集中需要單獨設定幾個這樣的節點負責儲存資料,後期提供儲存和查詢服務。node.master: true 並且 node.data: false
這種組合表示這個節點不會儲存資料,有成為主節點的資格,可以參與選舉,有可能成為真正的主節點,這個節點我們稱為master節點。node.master: false node.data: false
這種組合表示這個節點即不會成為主節點,也不會儲存資料,這個節點的意義是作為一個client(客戶端)節點,主要是針對海量請求的時候可以進行負載均衡。node.ingest: true
執行預處理管道,不負責資料和叢集相關的事物。
它在索引之前預處理文件,攔截文件的bulk和index請求,然後加以轉換。
將文件傳回給bulk和index API,使用者可以定義一個管道,指定一系列的前處理器。
示例圖:
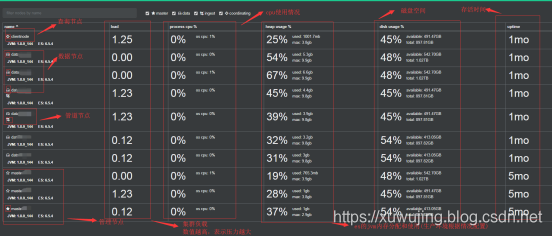
上述的節點屬性可以根據實際的情況來進行配置。如果只有三臺配置一般的伺服器,在測試環境可以將master節點和datanode節點共用,也就是 node.master: true 並且 node.data: true ;在生產環境中,最好將節點分離,特別是masternode和datanode,哪怕是用配置非常差的伺服器安裝masternode。至於clientnode則需要看情況,如果有大量的查詢,並且有很多的聚合分析查詢的話,可以部署;ingestnode這個也是看具體的情況,如果有使用ingest等api的情況,也可以進行部署。至於叢集規劃這個我們在後續的文章中再來講解。
索引(index)
索引是Elasticsearch對邏輯資料的邏輯儲存,所以它可以分為更小的部分。你可以把索引看成關係型資料庫的表。然而,索引的結構是為快速有效的全文索引準備的,特別是它不儲存原始值。如果你知道MongoDB,可以Elasticsearch的索引看成MongoDB裡的一個集合。如果你熟悉CouchDB,可以把索引看成CouchDB資料庫索引。Elasticsearch可以把索引存放在一臺機器或者分散在多臺伺服器上,每個索引有一或多個分片(shard),每個分片可以有多個副本(replica)。
根據
Relational DB -> Databases -> Tables -> Rows -> Columns
Elasticsearch -> Indices -> Types -> Documents -> Fields但是根據最新的ElasticSearch7.x中已經將Types移除了,並且在日常的使用中,我建議最好把一個索引(index)當做資料庫的一張表來使用,型別(type)除了必要的情況,最好無視它,將它和索引庫名設定一樣即可。
這裡順便再來說下建立索引庫的結構。我們知道在關係型資料庫中需要建立表才能新增資料,但是在ElasticSearch中可以直接插入資料,它會根據你的第一條資料來自動建立索引庫的結構, 但是這種在很多情況下是不符合我們要求的。如果我們想自己進行建立的話,那麼就有必要了解一下index的setting和mapping了。
setting
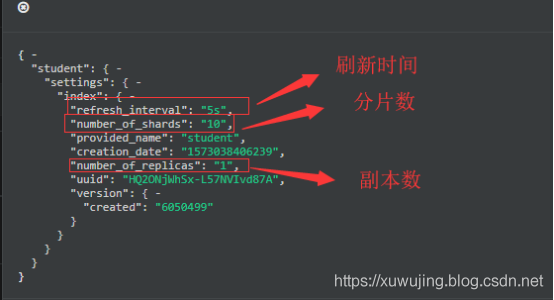
setting可以理解為管理這個index的一些重要屬性的,比如分片(shard)和副本(replica),它決定這個索引庫最終的配置形態。初學者的話,可以只用管這三個配置引數即可:
- number_of_shards: 是設定的分片數,設定之後無法更改!
- refresh_interval: 是設定es快取的重新整理時間,如果寫入較為頻繁,但是查詢對實時性要求不那麼高的話,可以設定高一些來提升效能。可以更改
- number_of_replicas : 是設定該索引庫的副本數,建議設定為1以上。
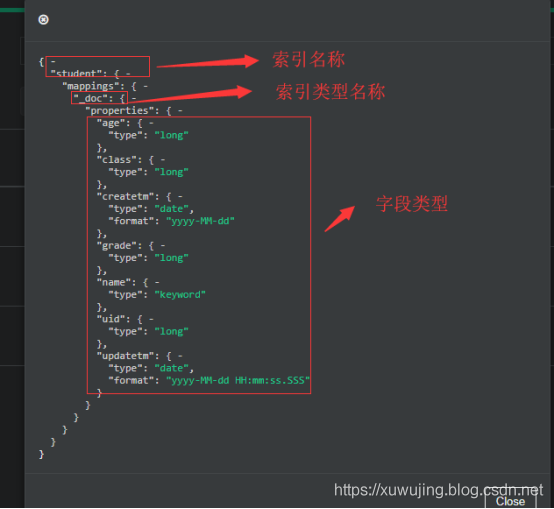
mapping
mapping可以理解為關係型資料庫的表結構,指定欄位的型別。初學者可以先只用關心text、keyword、byte、short、integer、long、float、double、boolean、date這幾個欄位,其中text和keyword都是string型別,選擇區分很簡單,需要進行分詞用text,不需要並且進行排序或聚合的可以用keyword。
分片(shard)
分片是一個單一的Lucene例項。這個是由Elasticsearch管理的比較底層的功能。索引是指向主分片和副本分片的邏輯空間。對於使用,只需要指定分片的數量,其他不需要做過多的事情。在開發使用的過程中,我們對應的物件都是索引,Elasticsearch會自動管理叢集中所有的分片,當發生故障的時候,一個Elasticsearch會把分片移動到不同的節點或者新增新的節點。
主分片(primary shard):每個文件都儲存在一個分片中,當你儲存一個文件的時候,系統會首先儲存在主分片中,然後會複製到不同的副本中。預設情況下,一個索引有5個主分片。你可以在事先制定分片的數量,當分片一旦建立,分片的數量則不能修改。
副本分片(replica shard):每一個分片有零個或多個副本。副本主要是主分片的複製,其中有兩個目的:
1、增加高可用性:當主分片失敗的時候,可以從副本分片中選擇一個作為主分片。
2、提高效能:當查詢的時候可以到主分片或者副本分片中進行查詢。預設情況下,一個主分配有一個副本,但副本的數量可以在後面動態的配置增加。副本必須部署在不同的節點上,不能部署在和主分片相同的節點上。
分片設定很重要!一個index指定了分片之後是無法修改的,因此在設定分片的時候一定要事前做好規劃!
示例圖: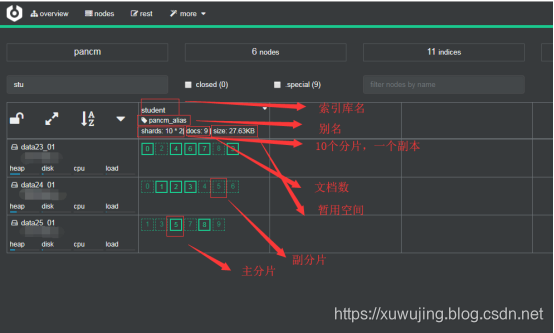
文件
儲存在Elasticsearch中的主要實體叫文件(document)。用關係型資料庫來類比的話,一個文件相當於資料庫表中的一行記錄。當比較Elasticsearch中的文件和MongoDB中的文件,你會發現兩者都可以有不同的結構,但Elasticsearch的文件中,相同欄位必須有相同型別。這意味著,所有包含 title 欄位的文件, title 欄位型別都必須一樣,比如 string 。
文件由多個欄位組成,每個欄位可能多次出現在一個文件裡,這樣的欄位叫多值欄位(multivalued)。每個欄位有型別,如文字、數值、日期等。欄位型別也可以是複雜型別,一個欄位包含其他子文件或者陣列。欄位型別在Elasticsearch中很重要,因為它給出了各種操作(如分析或排序)如何被執行的資訊。幸好,這可以自動確定,然而,我們仍然建議使用對映。與關係型資料庫不同,文件不需要有固定的結構,每個文件可以有不同的欄位,此外,在程式開發期間,不必確定有哪些欄位。當然,可以用模式強行規定文件結構。從客戶端的角度看,文件是一個JSON物件。每個文件儲存在一個索引中並有一個Elasticsearch自動生成的唯一識別符號和文件型別。文件需要有對應文件型別的唯一識別符號,這意味著在一個索引中,兩個不同型別的文件可以有相同的唯一識別符號。
- 文件型別:
在Elasticsearch中,一個索引物件可以儲存很多不同用途的物件。例如,一個部落格應用程式可以儲存文章和評論。文件型別讓我們輕易地區分單個索引中的不同物件。每個文件可以有不同的結構,但在實際部署中,將檔案按型別區分對資料操作有很大幫助。當然,需要記住一個限制,不同的文件型別不能為相同的屬性設定不同的型別。例如,在同一索引中的所有文件型別中,一個叫 title 的欄位必須具有相同的型別。
- 核心資料型別
text 和 keyword- 數值資料型別
long,integer,short,byte,double,float,half_float,scaled_float- 日期資料型別
date- 布林資料型別
boolean- 二進位制資料型別
binary範圍資料型別
integer_range,float_range,long_range,double_range,date_range- 複雜資料型別
- 物件資料型別
object 用於單個JSON物件巢狀資料型別
nested 用於JSON物件陣列- 地理資料型別
- 地理位置資料型別
geo_point 緯度/經度積分地理形狀資料型別
geo_shape 用於多邊形等複雜形狀- 專業資料型別
- IP資料型別
ip 用於IPv4和IPv6地址- 完成資料型別
completion 提供自動完成建議- 令牌計數資料型別
token_count 計算字串中令牌的數量
mapper-murmur3
murmur3 在索引時計算值的雜湊並將其儲存在索引中
mapper-annotated-text
annotated-text 索引包含特殊標記的文字(通常用於標識命名實體)- 滲濾器型別
接受來自query-dsl的查詢- join 資料型別
為同一索引內的文件定義父/子關係別名資料型別
為現有欄位定義別名。多欄位:
為不同的目的以不同的方式對同一欄位建立索引通常很有用。例如,一個string欄位可以對映為text用於全文搜尋的欄位,也可以對映為keyword用於排序或聚合的欄位。或者,您可以使用standard分析儀, english分析儀和 french分析儀索引文字欄位。
這是多領域的目的。大多數資料型別通過fields引數支援多欄位。
對映:
在有關全文搜尋基礎知識部分,我們提到了分析的過程:為建索引和搜尋準備輸入文字。文件中的每個欄位都必須根據不同型別做相應的分析。舉例來說,對數值欄位和從網頁抓取的文字欄位有不同的分析,比如前者的數字不應該按字母順序排序,後者的第一步是忽略HTML標籤,因為它們是無用的資訊噪音。Elasticsearch在對映中儲存有關欄位的資訊。- 路由(routing):
當儲存一個文件的時候,他會儲存在一個唯一的主分片中,具體哪個分片是通過雜湊值的進行選擇。預設情況下,這個值是由文件的id生成。如果文件有一個指定的父文件,從父文件ID中生成,該值可以在儲存文件的時候進行修改。
這個屬性在學習初期可以不必理會,使用預設即可。在有一定了解ElasticSearch之後可以在進行了解學習。 別名(alias):
它是一個或多個索引的一個附加名稱,允許使用這個名稱來查詢索引。一個別名可以對應多個索引,反之亦然,一個索引可以是多個別名的一部分。別名只能用作查詢,不能進行資料操作!
示例圖:
其它
本文主要介紹了ElasticSearch的一些基礎知識,其中ElasticSearch的理論知識遠遠不止這些,但是介紹的太多的話吸收不過來,其實很多的知識最好是邊學邊用中在掌握。學習ElasticSearch知識理論可以去官網學習,那裡有非常詳細的知識。
之後或許會寫一篇關於ElasticSearch的叢集規劃,會從案例中進行講解,包括機器、節點、索引庫、分片副本一些選擇和配置的一些具體知識。
參考:
https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
參考書籍:
《ElasticSearch權威指南》
ElasticSearch實戰系列:
ElasticSearch實戰系列一: ElasticSearch叢集+Kinaba安裝教程
ElasticSearch實戰系列二: ElasticSearch的DSL語句使用教程---圖文詳解
ElasticSearch實戰系列三: ElasticSearch的JAVA API使用教程
音樂推薦
原創不易,如果感覺不錯,希望給個推薦!您的支援是我寫作的最大動力!
版權宣告:
作者:虛無境
部落格園出處:http://www.cnblogs.com/xuwujing
CSDN出處:http://blog.csdn.net/qazwsxpcm
掘金出處:https://juejin.im/user/5ae45d5bf265da0b8a6761e4
個人部落格出處:http://www.panchengming.com