
Hbase概念原理掃盲
一、Hbase簡介
1、什麼是Hbase
Hbase的原型是google的BigTable論文,收到了該論文思想的啟發,目前作為hadoop的子專案來開發維護,用於支援結構化的資料儲存。
Hbase是一個高可靠性(儲存在hdfs上,有副本機制),高效能,面向列,非關係型的資料庫(類似redis),可伸縮的分散式儲存系統(因為是儲存在hdfs上),利用hbase技術可在廉價PC server上搭建大規模結構化的資料庫儲存叢集。
Hbase的目標是儲存並處理大型的資料,更具體來說僅需使用普通的硬體,就能夠處理由成千上萬行和列所組成的大型資料。
Hbase是基於hdfs構建的分散式儲存框架,但是Hbase在hdfs上實現隨機的讀寫改,解決了hdfs不支援的東西
2、Hbase的特點
A、海量儲存
B、列式儲存
這裡的列式儲存其實說的是列族儲存,Hbase是根據列族來儲存資料的,列族下面可以有非常多的列,列族在建立表的時候必須指定
Hbase中的列和mysql的列不是一個東西,Hbase的列就是他的資料
C、極易擴充套件
Hbase的擴充套件性主要體現在兩個方面,一個是基於上層的梳理能力的擴充套件(RegionServer,相當於datanode,處理讀寫請求),一個是基於儲存的擴充套件(hdfs)
通過橫向新增RegionServer的機器,進行水平擴充套件,提升Hbase上層的處理能力,提升Hbase服務更多的Region的能力。
備註:RegionServer的作用是管理Region)(類似mysql中的表的概念),承接客戶端的讀寫請求的訪問,這個後面會詳細的介紹通過橫向新增datanode的機器,進行儲存層的擴容,提升Bhbase的儲存能力和提升後端儲存的讀寫能力
D、稀疏
稀疏主要是針對於hbase列的靈活性,在列族中,你可以指定任意多的列,在列資料為空的情況下,是不會佔用儲存空間的,這裡和mysql等資料庫不一樣,mysql如果每個欄位沒有值,那這個欄位的值為null,不為空,且會佔用儲存空間
3、Hbase的架構
Hbase的架構示意圖如下

Hbase由HMaster和HRegionServer組成,HMaster的高可用也依賴於zk,類似於hdfs中的Namenode;
HRegionServer相當於hdfs中的datanode,實際處理讀寫請求的節點;
a、Zookeeper
HBase通過zk來做Hmaster的高可用,RegionServer的監控,元資料的入口以及叢集配置的維護等工作,具體工作入下
通過zk來保證叢集中只有一個master在執行,如果master異常,會通過競爭機制產生新的master提供服務
通過zk來監控RegionServer的狀態,當RegionServer有異常的時候,通過回撥的形式通知master,RegionServer上下線的資訊
通過zk儲存元資料的統一入口地址;
b、HMaster
為RegionServer分配Region
維護叢集的負載均衡,就是分配Region
維護叢集的元資料資訊
發現失效的Region,並將失效的Region分配到正常的RegionServer上
當RegionServer失效的時候,協調對應的Hlog和hdfs的block進行資料恢復
C、HRegionServer
HRegionServer直接對接使用者的讀寫請求,是真正的幹活的節點,他的功能概括如下
管理master為其分配的Region
處理來自客戶端的讀寫請求
負責和底層hdfs的互動,儲存資料到hdfs中
負責Region變大後的拆分
負責Storefile的合併工作
D、HDFS
Hdfs為hbase提供最終的底層資料儲存服務
提供元資料和表資料的底層分散式儲存服務
資料的多副本,保證高可靠和高可用
E、Hlog
一個HRegionServer中只有一個Hlog,Hlog相當於hdfs中的edits檔案,儲存Hbase的修改記錄,當對Hbase寫資料的時候,資料不是直接寫進磁碟,他會在記憶體中保留一段時間(時間i將資料量的閾值可以設定)。但把資料儲存在記憶體中可能有更高的概率引起資料丟失,為了解決這個問題,資料會先寫在一個叫做Hlog的檔案中,Hlog儲存在磁碟上,也位於hdfs上,然後在寫入記憶體,所以在系統出現故障或者記憶體丟失的時候,資料可以通過這個日誌檔案進行重建
F、Region
Region相當於mysql中的表,一個HRegionServer可以有多個Region,一個HRegionServer會有多個Region;如果表的資料太大,會進行拆分,按照資料量平均切分,所有HBase中的一張表會對應一個或者多個Region,當表的內容很小,一張表就對應一個Region,如果表很大的話,則這個Region會切分,切分Region會同時拆分這個Region的所有Store。
G、Store
Store相當於列族,通俗的講就是列的家族,在hbase中,想建立一個列,必須要指定列族,也就是一個列必須屬於某個列族。一個表中可以有多個列族,一個store對應一個列族,hbase官方不建議多個列族,一個列族就可以搞上百個列,足夠用了。但是如果一個HRegion被切分的話,是切分列族,所以就算一個HRegion只有一個列表,切分後一個Region也會對應多個Store,多個strore會被分配到其他的HRegionServer節點進行儲存
H、MemStore
MemStore就是列族中的資料放在記憶體中,寫資料來了,會寫到記憶體中,只要記憶體寫入成功,則就返回。
I、StoreFile
StoreFile,資料放在記憶體不安全,而且有大小限制,所以需要把記憶體中的資料寫到磁碟中,以Hfile的格式儲存在hdfs上。每次memstore刷一次,形成一個storefile,所以storefile會很多,但是很小,因為記憶體本身就不大,後面storeFile也會合並,但是這個合併也僅僅是一個列族內部的StoreFile進行合併,不會跨列族合併的
J、HFile
這是磁碟上儲存的原始資料的實際的物理檔案,是實際的儲存檔案,storefile是以Hfile的形式儲存在hdfs中
二、Hbase安裝
1、首先要安裝zk
2、 然後要安裝hdfs
3、 最後在安裝hbase
4、 解壓,修改配置檔案
這裡重點說下修改配置檔案,前面的就不說了,因為我在實際使用過程中使用ambari工具來進行安裝
首先修改hbase-env.sh
配置java的環境變數
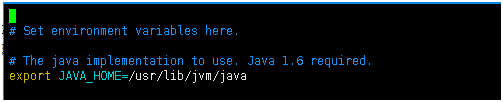
export JAVA_HOME=/usr/lib/jvm/java
配置zk,Hbase也是強依賴於zookeeper的,是否要啟用自己的zookeeper。如果用則為true,如果用外部的zookeeper,則為false

export HBASE_MANAGES_ZK=false
配置hbase-site.xml

<property>
<name>hbase.rootdir</name>
<value>/apps/hbase/data</value>
</property>
配置hbase是否啟用叢集

<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
設定Hbase的服務的埠號,不是 web的埠號,web的埠號是16010

<property>
<name>hbase.master.info.port</name>
<value>16010</value>
</property>
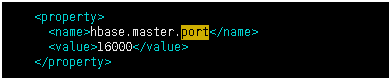
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
配置要連線的zk

<property>
<name>hbase.zookeeper.quorum</name>
<value>abdi1,abdi2,abdi3</value>
</property>
Zk儲存資料的父目錄,主要是為了區分多個hbase叢集

<property>
<name>zookeeper.znode.parent</name>
<value>/hbase-unsecure</value>
</property>
配置regionservers檔案
指定RegionServer的節點

由於hbase是強依賴於hdfs的,需要拷貝hdfs的配置檔案到hbase的conf目錄
我們一般情況會這樣操作,建立一個軟連結,連結到hdfs的core-site.xml和hdfs-site.xml中,就是讓hbase知道我要連線哪個hadoop叢集

但是在ambari安裝的hbase的配置檔案中沒有找到相應的配置,但是在hbase啟動的時候有載入hdfs的環境變數

啟動hbase,可以看到有Hmaster和HRegionServer的java程序
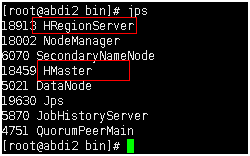
ambari的web頁面顯示效果如下

注意:Hbase的Master和RegionServer安裝是一樣的,只是看我們是否要啟動master
Hbase的web頁面,採用16010埠

三、Hbase的簡單shell操作
1、進入hbase shell
[root@abdi2 bin]# /usr/hdp/current/hbase-client/bin/hbase shell
2、檢視當前有哪些表:list
hbase(main):003:0> list TABLE 0 row(s) Took 0.2713 seconds => [] hbase(main):004:0>
3、建立表操作。這裡的列族是必須要指定的,就是和mysql的列一樣:create "student","info"
hbase(main):004:0> create "student","info" Created table student Took 1.3445 seconds => Hbase::Table - student hbase(main):005:0> hbase(main):006:0> list TABLE student 1 row(s) Took 0.0055 seconds => ["student"]
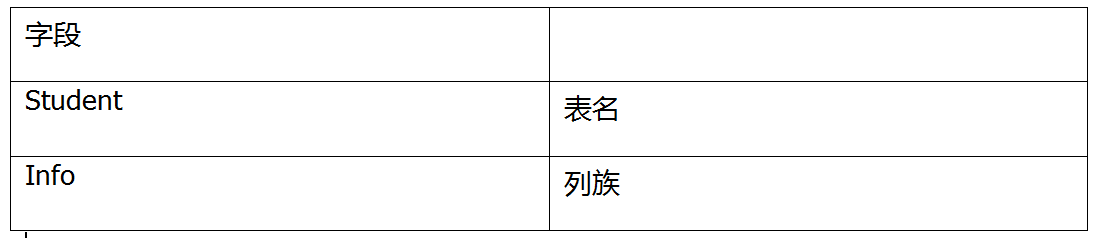

4、插入資料。Hbase中的資料沒有什麼型別,比如字串,hash等,全部是位元組:put "student","1001","info:name","laowang"
hbase(main):007:0> put "student","1001","info:name","laowang" Took 0.1217 seconds hbase(main):008:0> put "student","1001","info:age","18" Took 0.0038 seconds hbase(main):009:0> put "student","1001","info:sex","male" Took 0.0049 seconds hbase(main):010:0> put "student","1002","info:name","laoluo" Took 0.0036 seconds hbase(main):011:0> put "student","1002","info:age","20" Took 0.0035 seconds

5、掃描檢視資料:scan “student”

6、掃描檢視資料,指定起始和截止Rowkey,前閉後開

7、檢視指定Rowkey

8、檢視指定行的指定列

9、更新資料

10、查看錶結構
重點關注列族和版本即可,這裡的版本是個數的意思,就一條資料儲存幾個版本

11、修改列族的版本資訊

多更新幾次資料

可以檢視到有多個版本,這裡的意思檢視3個版本的資料,所以有三條,下面的命令是檢視2個版本的資料,所以有兩條

12、刪除操作
刪除某個Rowkey的指定列,可以看到其他列的資料還在,刪除還可以指定時間戳,該時間戳之前的資料都會被刪除

刪除Rowkey對應的所有資料

13、統計條數
統計條數,Rowkey有幾個,條數就有幾條

14、清空表

15、刪除表

16、名稱空間(namespace)操作
命令空間,相當於資料庫中的database
所有的表都是名稱空間的成員,如果不指定,則預設在default的名稱空間中
名稱空間可以設定許可權,比如定義訪問控制列表,例如建立表,讀取表,刪除,更新操作,許可權用的很少
Shell命令檢視namespace、建立namespace

Hbase就是儲存元資料的名稱空間,是系統自己用的,不能給使用者使用
在指定名稱空間下建表


四、Hbase的資料結構
1、Rowkey
Rowkey是用來檢索記錄的主鍵,訪問Hbase table中的行,只有三種方式
A、通過單個Rowkey訪問
B、通過Rowkey的range訪問
C、全表掃描
設計Rowkey非常重要也是Hbase裡最重要的一門學問,資料會按照Rowkey的字典序排序進行儲存,所以設計Rowkey要利用這個特性,把經常一起讀取的行儲存在一起,學習Hbase,Rowkey設計是學習的重點
2、Column Family
列族,Hbase表中的每個列,都會屬於某個列族,列族是表的結構的一部分,列族在建表的時候必須要指定。列名都是以列族做為字首。
在建立表的時候需要指定列族,列族可以指定多個
3、Cell
由Rowkey,column Family:column,version唯一確定的單元,cell中的資料是沒有型別的,全部都是位元組的形式儲存
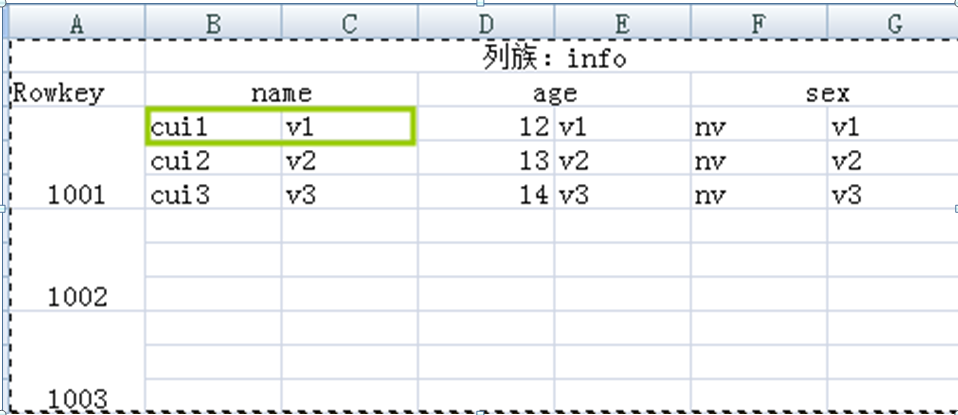
4、Time Stamp
時間戳,每個cell都儲存著同一份資料的多個版本,版本通過時間戳來索引。時間戳可以由系統生成,也可以自己指定。每個cell中,不同版本的資料按照時間倒序排列,即最新的資料在最前面
通過時間戳不同來確定版本的
五、Hbase的原理
Hbase的寫比讀還快
1、讀流程,hmaster沒有關係,hmaster掛掉後,不影響讀流程

a、先獲取meta表的位置,也就元資料這張表儲存的位置
b、去meta表所在位置獲取meta表的資訊,meta表儲存的內容大致入下
Student 0 ----10000 rs1
Student 100001---20000 rs2
Stff 0---10000 rs3
Stff 10000—200000 rs4
c、然後在去對應的regionserver獲取對應的資料
d、獲取資料,先去記憶體中獲取,如果記憶體中沒有,到blockcache中獲取,如果blockcash沒有,則去磁盤獲取,這裡為什麼先去記憶體獲取資料?
e、返回資料的時候,先把資料寫到blockcache中,然後在返回給client
Meta表的位置

Zk上檢視meta表的儲存位置

檢視meta表的內容
2、寫流程,和Hmaster沒有關係
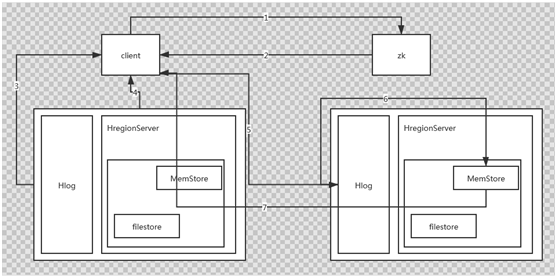
a、client到zk獲取meta表的位置
b、Zk返回meta表的位置
c、Zk去regionserver讀取meta表的內容
d、Regionserver將meta表的內容返回
e、去對應的regionserver開始執行寫操作,先寫Hlog檔案,然後寫到memstore,成功後,立刻返回,寫入流程完成
因為先寫到記憶體中,那麼什麼時候會刷到硬碟中呢
a、Regionserver的使用的總記憶體達到堆記憶體的40%

b、滿足一個小時的條件,會刷memstore到硬碟中

c、單個region裡的所有的Memstore加起來達到128MB,則會刷memstore到硬碟中

這樣就會有很多小檔案刷到hdfs中,但是hdfs不適合儲存很多的小檔案
預設是7天做一次合併

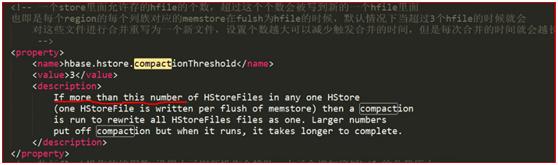
超過7天合併storefile檔案
超過3個storefile檔案,會進行合併
這個是合併一個列族的的storefile,不同列族的storefile檔案不會進行合併的
3、高可用
Hmaster是Active和standby模式
高可用配置

掃描檢視